




















基于K-Means算法的新闻文本内容过滤
【摘 要】:
随着计算机信息技术的不断发展,如何快速有效地在庞大的文本数据中挖掘有用信息与知识并为研究所用,成为了当下研究者的热点话题。本文针对新闻文本数据,提出一种基于K-means算法的新闻文本内容过滤技术,对文本聚类过程中文本表示部分进行改进,引入LDA概率主题模型,深层次挖掘文本语义信息。该技术能够挖掘文本隐藏结构和潜在信息,更有效的筛选出与用户历史浏览行为相似的文本数据,同时过滤掉有害信息。本文旨在为用户快速而精确地推荐新闻、文章等信息,提升检索精确度与缩短检索时间,最大程度改善用户体验,创造经济与社会价值。
【关键词】:K-Means算法;文本内容过滤;文本聚类;文本表示
1 概述
1.1 研究背景和意义
近年来,互联网成为新闻转播的重要载体,层出不穷的网络新闻发布平台,积累了海量的电子新闻文本数据。这些文本信息在给人们带来极大便利的同时,也包含很多低俗有害,或与用户关注不相关的信息,急需要利用计算机针对这些大规模且结构复杂的文本数据进行有效的处理和剖析,挖掘文本间潜在结构,寻找到有用信息进而为决策提供服务。
本文提出一种基于K-means算法的新闻文本内容过滤技术。该技术能够挖掘文本隐藏结构和潜在信息,更有效的筛选出与用户历史浏览行为相似的文本数据,同时过滤掉有害信息。本文重点研究了经典聚类算法K-Means,引入LDA概率主题模型,深层次挖掘文本语义信息。将新闻文本进行内容划分和归类,可以帮助人民网用户快速精准地搜索出和自己所需内容相似的文本,提升检索精确度与缩短检索时间,最大程度改善用户体验。
1.2 研究现状
文本过滤是指计算机根据用户对信息的需求,从大量的文本流中寻找对应信息或剔除不相关信息的过程。将该技术应用于新闻文本内容过滤方面,从海量文本信息中精准高效找出用户感兴趣的内容,可以有效地为用户个性化推荐新闻。文本聚类是文本过滤中的关键技术,采用无监督学习的方法,自动依据文本内容进行分类,进而达到筛选相关文本过滤不相关文本的目的。1958年Luhn H P[1]首次将词频统计的思想应用到了文本聚类的领域,至此开启了基于词频的文本聚类方法的研究。此后,Maron在验证了概率索引和信息检索的相关性,提出了概率模型[2],为之后的文本聚类研究奠定了理论基础。20世纪70年代Salton提出了向量空间模型[3],向量空间模型的诞生成为了文本聚类历史上重大的突破,此后的很多研究全部都基于向量空间模型展开。20世纪90年代之后,开始进入机器学习时代,计算机的性能有了大幅度的提高,利用计算机处理自然语言引起了广泛的关注。
随着文本量增大,在文本过滤的过程中,对于文本语义的挖掘要求更高,传统向量空间模型无法满足要求,因此引入概率主题模型,通过对文本相关主题的挖掘,挖掘了文本特征关键词。J.B.MacQueen[4]在1967年提出的K-Means算法,是一种基于划分的算法,由于其算法复杂度低、收敛速度快、易解释以及适用于大规模的文本数据聚类问题得到了关注。而文本表示模型的发展过程在不断改进,20世70年代Salton等人提出向量空间模型,但向量空间模型无法对文本的深层次语义进行发掘。同向量空间模型相比,Blei提出的隐含狄利克雷分配(Latent Dirichlet Indexing,LDA)[5]模型则是一个完全的贝叶斯概率主题模型。LDA在词袋假设基础上,定义了文本是由潜在主题分布所构成,主题是由词汇的分布所构成,且这两组分布都满足参数Dirichlet 先验分布,对于主题、词汇的估计更加精确,生成了文本的“潜在主题”,使主题之间产生相关性,挖掘了文本的深层语义信息。
2 文本表示模型
为使计算机能快速有效地对文本进行处理,需要将文本数据进行数学建模,将半结构化的文本数据转化为计算机可以处理的结构化形式,一方面能保留文本内在结构,真实地反映文本的语义内容,另一方面对不同文本也具有一定程度上的区分能力。
2.1 空间向量模型
20世纪60年代末Salton提出了向量空间模型(Vector Space Model, VSM)[3],成为了目前应用最为广泛的文本表示模型。向量空间模型就是要将文本表示为一个向量空间下的向量,数学表达式如下:
![]() (2-1)
(2-1)
其中,![]() 代表文本集中的某一文本,
代表文本集中的某一文本,![]() 表示文本中的一个特征项,
表示文本中的一个特征项,![]() 代表特征项
代表特征项![]() 在文本
在文本![]() 中的权值。
中的权值。
在向量空间模型中,需要通过特征项所在维度上的权值大小来反映该特征项对文本内容的贡献程度大小,即对不同文本的区分能力,因此特征权值的计算对于文本表示有着很重要的影响。当下特征权值计算的方法主要有:布尔函数、词频函数、词频-逆文件频率(TF-IDF)函数等,其中最为常用的是TF-IDF函数[7]。
TF-IDF权重计算函数重点考虑以下两个因素:
(1)词频TF(Term Frequency):特征词在该文本中出现的次数,它反映的是该特征词对于文本内容的贡献程度的大小。
(2)逆文件频率IDF(Inverse Document Frequency):特征词在文本数据集中出现情况。IDF越大,说明文本数据集中出现该特征词的文档总数越少,说明该特征词对文档集有越出色的区分能力。计算公式如下:
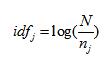 (2-2)
(2-2)
N为文本数据集中所有的文本数目,![]() 为整个文本数据集中出现过特征词
为整个文本数据集中出现过特征词![]() 的文档的总数,
的文档的总数,![]() 当越小,就说明该特征词的文档区分能力越好。
当越小,就说明该特征词的文档区分能力越好。
综上所述,TF-IDF特征的权重计算公式为:
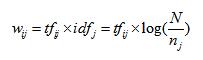 (2-3)
(2-3)
![]() 为特征词
为特征词![]() 的词频。
的词频。
一方面TF-IDF增大了小范围文本中高频特征词的权重,而另一方面也降低了那些对文本内容贡献很小的极高频词,使用TF-IDF方法进行权重计算可以提高文本表示的精确度。向量空间模型的提出,可以很好地将文本聚类问题映射为向量之间的数学运算处理问题来解决。
2.2 概率主题模型
概率主题模型是在“词袋”假设基础上,通过概率过程发现隐藏主题的一种文本主题生成模型。隐含狄利克雷分布 (Latent Dirichlet Allocation,LDA)[5]模型,是概率主题模型中最具有代表性也是最基础的模型。LDA模型引入“潜在主题”的概念,主题表示一个范畴,在主题范畴当中表现为一组与该主题相关性较强的特征词,这个主题以一定的概率属于这篇文章,其中文章和主题之间、主题和词汇之间符合多项式分布。
LDA模型包括文档,主题,词汇三层结构。“词汇”作为文本数据的基本单位,构成了文本数据的特征,定义为词汇表![]() 上的一项,使用一个单位向量来表示,即这个词在词汇表上的索引;“文档”为N个词的序列,记作
上的一项,使用一个单位向量来表示,即这个词在词汇表上的索引;“文档”为N个词的序列,记作![]() ,其中
,其中![]() 表示文档中的第N个词;“语料库”是M个文档的数据集合,记作
表示文档中的第N个词;“语料库”是M个文档的数据集合,记作 ![]() 。
。
具体一篇文章的生成步骤如下所示:
(1)针对文本数据集中的每一篇文档,从主题分布当中随机选择一个主题z;
(2)被选择的主题对应着词袋中的词语的概率分布,在词语分布中对词语进行选择;
(3)重复上面(1)(2),直到文档中的所有单词都被遍历,N个单词被全部选择。
定义![]() 为一个主题向量,主题向量矩阵的每一列表示文本数据集中的文档以一定的概率分布选择了这个主题, 其中这个主题向量
为一个主题向量,主题向量矩阵的每一列表示文本数据集中的文档以一定的概率分布选择了这个主题, 其中这个主题向量![]() 是非负归一化向量;
是非负归一化向量; ![]() 是
是![]() 的分布,具体表现为Dirichlet分布;N代表文本数据集中词的数量,
的分布,具体表现为Dirichlet分布;N代表文本数据集中词的数量,![]() 表示选择的主题,而
表示选择的主题,而![]() 表示词汇表中第n个词汇,
表示词汇表中第n个词汇,![]() 表示给定
表示给定![]() 条件下,对应主题
条件下,对应主题![]() 的概率分布;
的概率分布; ![]() 表示在给定主题条件下,对应的词汇的概率分布。
表示在给定主题条件下,对应的词汇的概率分布。
LDA模型中主题的混合向量![]() 、主题Z和词语
、主题Z和词语![]() 的联合概率为:
的联合概率为:
![]() (2-5)
(2-5)
那么,其模型可以用下图来进行表示:
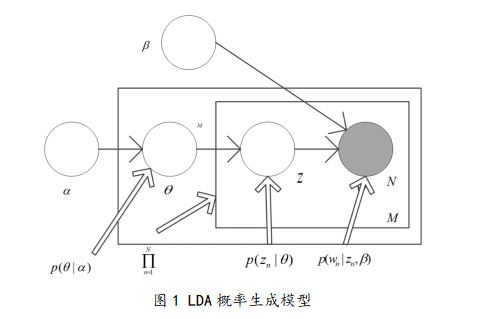
其中, ![]() 是参数
是参数![]() 为 的Dirichlet分布,其分布为:
为 的Dirichlet分布,其分布为:
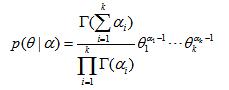 (2-6)
(2-6)
那么,可以从之前对于LDA生成过程的讨论看出,LDA模型共有三个层次,![]() 和
和 ![]() 属于“语料”层的参数,所以对于每一个文章来说,和都是一样的,对整个语料库采样,只采样一次,
属于“语料”层的参数,所以对于每一个文章来说,和都是一样的,对整个语料库采样,只采样一次,![]() 是“文档”层的变量,每一篇文档对应一个
是“文档”层的变量,每一篇文档对应一个![]() ,也就是说不同文章在生成过程选择各个主题Z的概率是不相同的,每一篇文章需对
,也就是说不同文章在生成过程选择各个主题Z的概率是不相同的,每一篇文章需对![]() 采样一次,Z和
采样一次,Z和![]() 是“词汇”层的变量,词汇层一共有n个变量,Z由
是“词汇”层的变量,词汇层一共有n个变量,Z由![]() 生成,而
生成,而![]() 由Z和
由Z和![]() 共同生成,每个词汇只采样一次。
共同生成,每个词汇只采样一次。
LDA模型其实是通过输入的文本语料库,对两个控制参数![]() 和
和![]() 进行学习和训练,通过学习出这两个控制参数确定模型,从而用来生成文档。其中
进行学习和训练,通过学习出这两个控制参数确定模型,从而用来生成文档。其中![]() 和
和![]() 分别满足以下条件:
分别满足以下条件:
![]() :分布
:分布 ![]() 需要一个向量参数用于生成一个主题 向量,该控制参数也就是Dirichlet分布的参数;
需要一个向量参数用于生成一个主题 向量,该控制参数也就是Dirichlet分布的参数;
![]() :相应的各个主题分布下的词汇的概率分布矩阵
:相应的各个主题分布下的词汇的概率分布矩阵![]() 。
。
在LDA中,估计![]() 和
和![]() 这两个参数可以使用EM算法或者吉布斯采样(Gibbs Sampling)算法。Gibbs采样法的中心思想是贝叶斯估计,是把待估计的参数看作是服从先验分布的随机变量,这样的优点是不会陷入局部最优值,结果较基于最大后验估计MAP的EM算法更为准确,但算法的收敛速度会比较慢。
这两个参数可以使用EM算法或者吉布斯采样(Gibbs Sampling)算法。Gibbs采样法的中心思想是贝叶斯估计,是把待估计的参数看作是服从先验分布的随机变量,这样的优点是不会陷入局部最优值,结果较基于最大后验估计MAP的EM算法更为准确,但算法的收敛速度会比较慢。
3 文本聚类算法
文本聚类是把抽象或具体的对象或数据以非监督的方式根据文本对象间的相似度自动划分到不同类簇当中去的过程。聚类算法的选择对于最后的聚类结果好坏至关重要。目前应用比较广泛的聚类算法包括: BIRCH算法,DBSCAN算法以及K-Means 算法。
3.1 BRICH算法
BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)算法即利用层次方法的平衡迭代规约和聚类。首先,BIRCH是一种聚类算法,它最大的特点是能利用有限的内存资源完成对大数据集的高质量的聚类,同时通过单遍扫描数据集能最小化I/O代价。整个算法过程分为三个阶段:
(1)扫描所有数据,把稠密数据分成簇,稀疏数据作为孤立点对待;
(2)补救由于输入顺序和页面大小带来的分裂;
(3)把中心点作为种子,保证重复数据分到同一个簇中,同时添加簇标签。
BIRCH算法的主要优点在于节约内存,聚类速度快,可以识别噪音点,还可以对数据集进行初步分类的预处理。但是缺点也十分显著,聚类的结果可能和真实的类别分布不同,对高维特征的数据聚类效果不好,如果数据集的分布簇不是类似于超球体,或者说不是凸的,则聚类效果不好。
3.2 DBSCAN算法
DBSCAN算法核心思想就是先发现密度较高的点,然后把相近的高密度点逐步都连成一片,进而生成各种簇。具体实现步骤:
(1)首先确定半径r和minPoints. 从一个没有被访问过的任意数据点开始,以这个点为中心,r为半径的圆内包含的点的数量是否大于或等于minPoints,如果大于或等于minPoints则改点被标记为central point,反之则会被标记为noise point;
(2)重复(1)的步骤,如果一个noise point存在于某个central point为半径的圆内,则这个点被标记为边缘点,反之仍为noise point。重复步骤1,知道所有的点都被访问过。
DESCAN算法的结果中任何簇当中的数据点都不包括噪声点和离群点,对噪声不明显,但也存在着需要调参且参数组合对于最后的聚类结果影响较大,确定距离r和minPoints ,当数据集的密度不均匀、聚类的间距相差很大时聚类质量差的问题。
3.3 K-Means算法
K-Means算法是目前比较简单易解释而且被普遍使用的聚类算法,原理是首先确定最终的聚类类簇数k,随机选取k个文本数据作为初始的聚类中心,以这k个中心为基准,对剩余的对象以不同点间欧式距离作为衡量相似度的指标,计算剩余对象距离中心点的欧式距离,将其划分到距离最近的点所在的类簇当中去;重新计算类簇平均值,将每个簇的平均值定义为新的簇中心,重新计算各个对象到新的簇中心的距离,继续划分;这个过程不断进行迭代,直到簇中心与簇中数据对象的均值吻合,不发生明显变化为止。假设要将文本数据集划分为k个簇,划分算法的主要内容为随机对文本数据集进行粗略的划分,然后通过不断迭代,文本数据来回移动重新定位改进划分,类簇不断更新,其中划分的标准是要求同一个类簇之间的文本数据尽量靠近,相似度较高,而不同簇之间的对象尽可能远离,相似度较低。
K-Means 算法的流程如下:
(1)随机选取k个数据作为此次聚类的初始聚类中心,此时迭代次数为0;
(2)对剩余的数据对象计算其与质心之间的文本相似度,把每个数据对象分配到相似度最高的簇当中去;
(3)计算每个簇中所有数据的均值,形成新的质心;
(4)重复(2)、(3),直至算法收敛,得到k个类簇,算法得以结束。
K-Means算法是目前最为常见的解决聚类问题的经典的聚类算法,很多文本聚类问题都是在K-Means算法的改进或者结合过程中解决的。K-Means算法运行流程简单,易于解释和实现,算法收敛快,可收缩性强,可以用于处理大数据集,当不同类簇对象之间具有较大的差异性且结果簇内部较为密集时,聚类性能较好。相比DBSCAN算法和BIRCH算法,仍然在文本过滤技术方面存在较大优势,因此本文重点研究K-Means算法在新闻文本内容过滤中的实际应用。
4 基于K-Means算法的新闻文本内容过滤
本节将针对中文新闻文本数据集,重点研究文本内容过滤过程中的关键聚类技术,采用经典聚类算法―K-Means,采用向量空间模型,对中文新闻文本进行内容过滤,从海量信息中快速有效地为找到用户感兴趣的新闻类别,挖掘用户兴趣点,有效地为用户进行新闻内容的个性化推荐,推进社会主义新时代新闻理论创新,弘扬时代精神。在原有K-Means聚类算法的基础上,针对传统向量空间模型中假设词与词之间独立,割裂了文本中词之间可能存在的语义关系的缺点进行改进,使用概率主题模型进行文本生成,概率主题模型的使用能够挖掘文本更深层次语义。通过引入LDA模型, 挖掘文本主题即“关键词”,提高文本聚类的性能,进而提升了文本内容过滤的准确性。
4.1 文本数据集的获取
本实验采用搜狗实验室的搜狐新闻数据集(SogouCS),受训练时间和机器硬件所限,采用精简版数据(347MB),该数据集包括搜狐新闻2012年6月―7月期间财经、健康、教育、文化等15个频道的新闻数据,提供URL和正文信息。数据格式如下图所示:

图 4-1 数据格式
在文本聚类和对聚类结果进行评估时需要带有类别标签的新闻数据,因此需要对以上数据集进行预处理。新闻数据使用<content></content>标签中的内容,类别通过<URL></URL>标签提取。示例数据的URL为“http://sports.sohu.com...”,通过搜狗实验室提供的《URL 到类别的映射文档》,可以标记该新闻类别为“体育”。
样本打标的代码逻辑为:先逐个读入原始数据集中的.txt文件,然后正则表达匹配出URL(新闻类别)和content(新闻内容),创建以新闻类别命名的文件,然后将content存入不同文件中。此外,本文还去除了字符数小于30的新闻数据,以减少过短文本对结果的影响。
4.2 文本内容聚类模块设计
本实验共分为四个模块来进行,第一个模块是文本预处理模块,将中文文本进行分词和去停用词处理。第二个模块是文本表示模块,把文本表示成计算机可以处理的结构,其中包括使用文本表示模型进行文本表示,并进行特征降维和权重计算。第三个模块是聚类模块,对文本向量使用K-Means算法进行文本聚类。第四个模块是将改进前后的K-Means算法聚类结果使用聚类评价指标进行性能对比。
具体流程如下图所示:
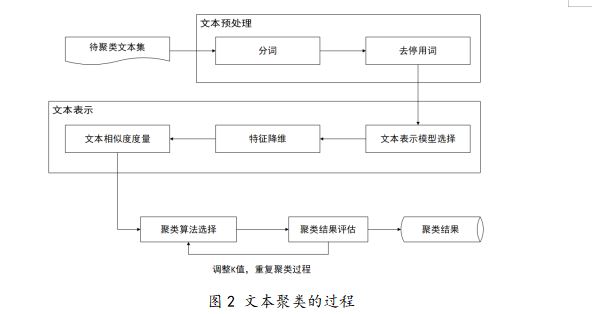
4.2.1 文本预处理
文本数据是一种非结构化或者半结构化数据,必须对文本进行处理,将其转换为成为计算机可以处理的结构化形式。文本预处理作为其中的关键步骤,主要包括分词和去停用词两个部分。通过中文分词系统将句子最精确地按照词性、语义分开,体现出来词与词之间的间隔,继而通过去除文本中那些本身不具备太多语义,对文本语义区分能力较弱但出现频率很高的词汇,例如中文中的“可以”、“了”、“的”、“如果”等,得到初步的特征词集合。
本文主要采用结巴系统的精确模式分词处理将文本字符串分割为分散的有独立意义的多个词序列,之后过滤掉停用词,减小噪声和离群点,有效地降低特征空间的维度,提高文本聚类的效率和质量。
4.2.2 文本表示
通过文本表示部分,可以将半结构化的文本数据转化为结构化数据供计算机处理。本文主要针对这一部分进行了文本聚类的改进研究,一方面是传统向量空间模型进行文本表示,将每一个文本表示为向量空间中的一个向量,并使用TF-IDF函数进行特征权值的计算,权重的大小表示了该特征项对于文本的贡献程度。另外,实验采用了主成分分析(PCA)的办法进行特征降维,在尽可能保留文本关键词信息的前提下,避免维度灾难,去除相关性大的特征项的多余部分,达到去除特征项中的无关噪声和冗余特征的目的。
针对传统向量空间模型采用词与词之间互相独立的“贝叶斯假设”,割裂了文本词之间可能存在的语义关系,无法发掘文本深层次语义,发现文本潜在“关键词”的缺点,对实验的文本表示部分进行了改进,使用LDA经典概率主题模型进行文本表示,生成了文本的“关键词”挖掘了文本的深层次语义信息。通过这样的偏好挖掘,提高了文本内容过滤,用户个性化推荐的准确度。
4.2.3 文本聚类
本文利用K-Means算法进行文本聚类,得出文本聚类结果。值得注意的是,在使用K-Means算法聚类的过程中,可能会由于K值的设定不合理,使得原本属于同一个类别的文本数据被强行划分到了不同类别当中去,或者是原本不属于同一个类别的数据对象被强行归类到一个类别中。类簇的个数即k值的确定对于聚类结果有着相当重要的影响。因此,通过枚举的方法,使k从11增加到18,在每个k值上重复运行数次K-Means(避免局部最优解),并计算当前k的同质性,完整性和V-measure这三个性能评估指标,最后选取在同质性,完整性和V-measure评价标准下聚类质量最好的情况下所对应的K作为最终的类簇数目。
4.2.4 聚类结果评价对比
在文本聚类结束后,我们要对聚类结果的好坏进行评估,从而判断文本聚类的改进是否有效。本文中重点使用了同质性(Homogeneity)、完整性(Completeness)、V-measure、调整互信息(AMI)、F值这5个聚类质量评价指标进行聚类性能的评估。这五个指标均为值越高,聚类性能越好,与事先人工标注的类别越发吻合。
本文将传统向量空间模型下的文本聚类结果与LDA模型下的文本聚类结果使用聚类质量评价指标进行性能对比,说明使用LDA模型后的文本聚类性能更优。
4.3 聚类结果与分析
4.3.1 K-Means文本聚类中类簇个数的确定
前面提到,在K-Means聚类算法中,类簇个数k值的确定十分重要。在实验中,将K固定于11到18,在每个k值上重复运行5次K-Means(避免陷入局部最优),并计算当前k值下的同质性,完整性和V-measure,取5次运算过程中的平均值,并进行画图,最终结果如下图所示:

图3 向量空间模型下类簇个数与聚类结果评价指标的关系图
从实验结果可以看出,在传统向量空间模型下进行K-Means文本聚类,同质性随着K值的增加而趋于平稳,而完整性随着K值的增加而趋于平稳,且在K=14之后趋于收敛,而V-measure是同质性和完整性的调和平均。在K=14时,V-measure出现峰值,此后趋于稳定,并且此时同质性和完整性的值也相对较大。综合评价此时聚类效果最好,故选择K=14作为向量空间模型下K-Means聚类的类簇个数。
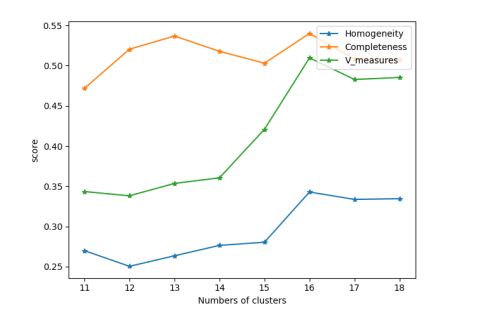
图4 LDA模型下类簇个数与聚类结果评价指标的关系图
从实验结果可以看出,同质性随着K值的增加而逐渐增大,而完整性随着K值的增加而逐渐减少,且在K=16之后趋于下降,而V-measure是同质性和完整性的调和平均。在K=16时,V-measure出现峰值,此后趋于下降,并且此时同质性和完整性的值也相对较大。综合评价此时聚类效果最好,故选择K=16作为LDA模型下K-Means聚类的类簇个数。
4.3.2 基于K-Means算法的文本聚类改进前后的聚类效果评价及对比
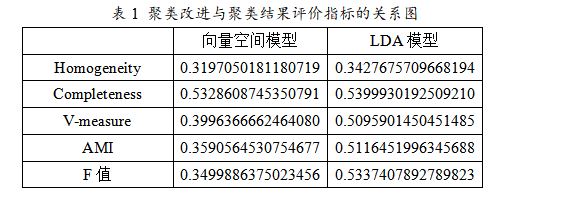
本文基于传统向量空间模型下的K-Means文本聚类过程,对文本表示模型进行了改进,使用了经典概率主题模型LDA,在此基础上使用K-Means算法进行文本聚类。本文用于评价聚类结果的指标分别为F值,同质性,完整性,V-measure以及调整互信息AMI。根据之前讨论的实验一和实验二的结论,向量空间模型选择类簇个数为14,LDA模型选择类簇个数为16,特征降维的维数为2000,使用K-Means进行文本聚类,迭代次数为5,计算上述文本聚类性能指标平均值,结果如下表所示:
5 总结
为实现文本内容过滤,我们采用了K-Means经典文本聚类算法,以无监督学习的方式将新闻文本数据集依据具体的文本内容自动进行归类。此外,针对传统向量空间模型割裂文本语义关系的缺点,引入LDA概率主题模型,对文本“关键词”进行挖掘,实验表明LDA模型确能提升聚类性能,进而提高了文本内容的过滤性能。
本文基于经典聚类算法K-Means,对新闻文本数据集进行了文本聚类,从而达到文本内容过滤的目的。并针对向量空间模型的缺点,对文本聚类过程中文本表示部分进行改进,引入LDA概率主题模型,深层次挖掘文本语义信息,发现潜在“关键词”挖掘了文本隐藏结构和潜在信息,并通过实验证明改进后的文本过滤性能更佳。可以更有效的筛选出与用户历史浏览行为相似的文本数据,并过滤掉有害信息,最大程度上为用户推荐其感兴趣的新闻内容,具有非常的现实意义。
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
