




















�ڰ�����Ԥ����Ϣ�������ϵͳ�о�
ժҪ��������Ϣ��Դ��ͬ��������ʽ�����ԭ�����Բ�ͬ����̨������Ԥ����Ϣ��������ֲ�һ�µ������������Ҫ֪��ȷδ���������˲������š�����ּ��ͨ������ѧϰ����Ϣ�����ķ������Ѽ����Բ�ͬ����̨��������Ϣ��Ȼ��ʹ���������Ʒ�ģ�͡��ڰ�ģ�͡��Իع�ģ�͵ȷ������Բ�һ�µ�����Ԥ���������ϡ�ͨ�����ͳһ��MO-HMMģ����һ�����Ӿ�ȷ�����Ŷȸ��ߵ�����Ԥ�������ݱ�����������㷨�����Ǵ��һ���ڰ������������Ԥ��ϵͳ����һϵͳҲ�ṩ��ͨ��ǰ��������Ԥ��δ������������Ԥ���ķ����������ڱ���ʵ�ֵ�ϵͳ�У�Ҳ�ṩ����ʷ������ѯ�ȷḻ�Ĺ��ܡ�
1�������
�������У����������ǰ����г̻�����ò����ǵ�һ�����أ���������Ԥ�����Ǻܶ�������ֵ�����ϰ�ߡ��������Ԥ���ڶ������꣬����Ҫ��ǰ������ɡ��������ڶ�����£������ǰҪ���ú��·��������ǰ֪���������ļ��춼�ʺ������������������һ�����Ļ����ó̡�����Щ�����У���δ��������Ծ�ȷ�ذ��տ���˵��������Ҫ�ġ�

Ŀǰ��������������ֻ����ռ������ǻ�ȡ����Ԥ����;���õ��˺ܴ����չ����ͬ����վ����ͬ����Ϣ��������Ϊ�����ṩ�ḻ��������Ϣ����������״����������£�������£����٣������ȵȣ��ܶ���վ���ṩ�˰���PM2.5������ָ���ȵȷḻ����Ϣ������˵��һ���̶������������ǵ�����Ȼ������Ϣ�ľ�ȷ�̶��ϣ��е���Ϣ��Դȴ����֤��������ͼ�г��ֵ����������ͬ����Ԥ��ڶ������������һ��������ԴԤ���ڶ���Ϊ��ת���ƣ����ڶ���������Դ��Ԥ��Ϊ�����꣬�������������£�������µ���ϢҲ�����ԵIJ�һ�¡�����������£���Ȼ��һ��������Դ�ṩ����Ϣ����ȷ������������ṩ����Ϣ���д���
�۲쵽��һ����֮����������һЩ���ڵĵ��й�����ͨ����ѯһЩ���������Ϣ�����Ƿ��ֲ�ͬ��Դ�ṩ��������Ϣ��һ������ʮ���ձ飬������ͬһ������ͬһ�������Ԥ�������������������һ�µ�ֵ����ʱ�����ǻ㱨��ȫ�෴�Ľ�����������µĺ��������Ҫ֪��δ��ȷ���������������ʴӣ���֪���������ȡ��Ϣ��
����������Ԥ���г��ֵIJ�һ������ʵ�����ںܶ������г��֣������ڰ����������һ�������űȽ�������о�������ʱ����������������ʼ��Ӱ�쵽�������ķ������棬�����ճ������еĹ����ҽ�������ȴ�����������ڼ���������ͻ�������Ӱ���µõ��˴�����Ż����ơ����ͬʱ���������ı��Ҳʹ�����ݵ������ߴ�ר�ұ�Ϊ����ͨ���������ŵ���վΪ������ͳ�Ļ�������վ����רҵ�ı༭��д���ţ�Ȼ��ͨ����˺����淢�������������Ľ�����ͨ����������ȡ������Ϣ��ֱ��BBS����Ϣ��������վ��������������������Ϸ�����Ϣ�Ļ��ᣬ�������������罻ý��Ŀ��ٷ�չ��������������ͨ�������ɵ��������Ѿ����˳�Խרҵ���ݵ����ơ��������ķ�չΪ��ͨ�����ṩ�˷����ݷ����Լ��۵�Ļ��ᣬ���κ�ʱ�䡢�κεص㶼����ͨ�����ԡ��ֻ��Ȼ������ն˻�ȡ�ͷ�����Ϣ���������˶��ɲ������ʽҲʹ��ͨ�����������������ǻ۽�����������ÿ��ܡ����ڰ�����Crowdsourcing����������һ�����²�����һ��������ҵģʽ��
��ͳ����µ�����˾��������ٸ���������Ҫ���ʱ��ͨ����ҪƸ����������ר�������������������������Ҫ���Ѵ������ʽ�ͬʱ��������ʱ������Ҳ�Ƚϳ���Ȼ������ͨ�����ڰ�����վ���������ⷢ�����������ϣ�������������ظ���������˽����о���� [1]�����ܴ�����˲����߱���������רҵ֪ʶ��Ȼ�������ǰ����Ǹ����Ľ��ͨ��ij�ַ�ʽ�������Ϻ�ʱ���ܹ��ۺϸ����ϺõĽ��������ֻ��Ҫ������Խ��ٵ��ʽ�Ͷ��ͽ϶̵�����������ڡ����ڰ�����һ����������Howe��Mark Robinson [2] ��2006�������������ߡ����������������������������������һ�ֻ����������ҵģʽ����˾����֯�����ذ��Լ����������ⷢ����һ���ֲ�ʽ���������У�ʹ����������ĸ����������Э���Ľ�����⡣��һ��ʽ�ڻ��������ռ��Ľ�������ڴ�ͳ�����ʽ�кܴ�����ơ�Ŀǰ��Amazon Mechanical Turk�ȡ��ڰ�����վ�Ѿ��õ��˹㷺��Ӧ�ã����ڹ��ڣ�ͳ��Ϊ���͵��롰�ڰ����������Ƶ���վҲ�ڲ��Ϸ�չ���кܴ�Ӱ������
������Ǿ�������Ԥ�������������������ϣ���ܹ�ͨ�������ڰ����ݵ�˼�룬ͨ��һ���ȽϹ�����ģ���Լ���������Ԥ�����ݵ�֧�֣����������Բ�ͬ������Դ������Ԥ�������ո���һ���ȽϺ�����Ԥ������
2�����������������
Ϊ�˺ܺõĽ��������Ϣ���ϵ����⣬����������Ҫ��������Ԥ�������ԭ������Ԥ��Դ�Ը��������۲����ݣ���Щ���������ڷֲ�ȫ���������۲�վ�����ǡ��״�ͼ�����е����ݣ�ʹ��������ѧģ���ּ����������Ԥ�������ڵ�����Ȼ�������ӣ����ڴ��������ݲɼ�������������Ȼ����Ԥ�����㷨��ģ��Ҳ��������������ͬ���ҵ�����֣�ʹ�ò�һ�µ�Ԥ���㷨�����Ԥ�������ȻҲ���в��졣����Ԥ���Ľ��������Ϊ����ѹ���¶ȡ���ˮ����һ��������ͼ�ϵķֲ������ܸ�ǿ���ij�������������Բ����߷ֱ��ʵġ�Ԥ������ͼ�����ijһ�����е�Ԥ��������ܸ�ȷ������̨Ҳ��ȫ������۲�վ�����ר�õļ������Ϣϵͳ��ȡ���ݣ��������ǵ�����ģ�ͺ����ݣ��ó��Լ���Ԥ����
��������Ԥ���������Ԥ��Ա�ľ����Լ�������ν�������ģʽҲ�й�ϵ������һЩģ���ر��ʺϽ���ij���������ͣ�����쫷硢��ѩ����һЩģ����Ҫ�����г���Ԥ��������һЩģ�͵ľ�ȷ�Ƚϲ����Ԥ��Ա��ְ��֮һ�������˽��������Ԥ��ģ������ҵ������֪�����ӣ���Ԥ��������е�����
�ܵ���˵������Ϊ����Ԥ����Ϣ�����������Ҫԭ�������¼��㣺
1.��ͬ����վʹ�ò�ͬ������Ԥ��ģ�ͣ����ǿ����ʺϲ�ͬ�����Ρ�
2.��ͬ����վԤ������ʱ��ʱ��Ϳռ��ϵ����Ȳ�ͬ������������仯�Ƚ�Ѹ�ٵ�����º����ײ������졣
3.����Ԥ��Ա������һ���ij������ʣ�������ض�����Ԥ�����
��˵�����ϣ����һ��ͳһ��ģ����������Щ������Դʱ����Ҫ����������Щ����ԭ����һģ�ͽ���������ڴ����ڰ���ע�����������õ���˼�룬��������н����ȶ��ڰ���ע����������н��ܡ�
3���ڰ���ע��������
������ϣ��ͨ�����ڰ����ķ�ʽ��������ʱ��������Ҫ��������봫ͳ����ģʽ��ͬ�����ѡ��ڴ�ͳģʽ�£�����Ƹ���������ר�����������⣬�����������Ľ�������Ǻ�ֵ�������ģ����仰˵����ר�Ҹ���ȷ���Ľ������������Ҫ�ٶ���һ�������������������ֻ��Ҫ�ڴ˻���������һ���������ɡ����һλר���������϶��Ĵ𰸣�Ҳ����ͨ������ר�����ֺ����һ�����յĴ𰸣�Ȼ���ڡ��ڰ�����ģʽ����һǰ��ٳ�����
��ͨ�����š��ֲ�ʽ�ķ�ʽ�Ӵ�����Ⱥ�л�ȡ���ʱ������������Щ����������ϸ��ɸѡ�������ж������Ƿ���н������ı���֪ʶ�����������������ȷ��������Ҫ��֪�ģ��������������ض������߸����Ľ���������ۣ�������֪����ȷ���Ϊ�˿˷����ֲ�ȷ���Ե�Ӱ�죬ͨ�����ڰ�����������ʱһ������¶���ѡ������ͬ����Ϊͬһ��������𰸣���������¶����ͬ�˸����Ľ��һ�����ʾ��ij��һ�µ�����ͨ����һ���������п��ܵõ�һ���ϺõĹ��ƽ�� [1]��
��Ϊһ�����������ǰѹ�ע��Χ���ڻ���ѧϰ����ʹ�á��ڰ����Դ������ݼ�����ע��һ�ض������ϡ�һ�����ݼ���N�����ݼ�¼���������������Ŀ����ɣ�ÿһ�����������ֻ���ͼƬ��������ʹ��һ����������xi����ʾ�����ǵ�����Ŀ����Ƕ�ÿһ�����ݼ�¼xi��������ʵ��עyi������һ��ͼ�����ע������ͼƬ���������ʵ����������������¼����ע������������Ӧ���ı���Ϣ��Ҳ�������������к��ж��ٸ���ʾϲ�õĴ���ȵȡ�Ϊ��ͨ�����ڰ����ķ�ʽ������ݵ���ʵ��ע����ÿһ�����ݣ����Ƕ���Ҫͨ�������ͬ�ı�ע��ȡ���ı�ע����������ÿ�����ݼ�¼xi��������Tiλ��ע�߶��������˱�ע�����Ǿͻ���wi1��wi2��wi3��һֱ��wiTi����ͬһ���ݵı�ע����Щ��ע������ͬҲ���ܲ�ͬ����˽�����Ҫ���ľ��Ƕ�������Щ����ͨ���ض������������ϣ����ո���һ������ʵ���ݵĽϺù��ơ���һ�����ϸ�Ķ������£�

Dawid��Skene��1979�������һ����ֵ�����������ģ�� [5]�����Ǽٶ�ÿһ����ע�߳����ض��������ĸ�����ȷ���ģ������Ϳ�����һ��ͳһ�Ļ�����������������������ֵĸ��ʣ�����ͨ�������Ȼ���ƾͿ��Եõ����в���ֵ������ÿ��ͼƬ����ʵ��ע��
�ڶ�ֵ�����£��������ǿ�����һ����ֵ ����ʾ��nλ��ע�߰ѱ����ڵ�d����ͼƬ��עΪ��l���ĸ��ʣ����ǰ�����{
����ʾ��nλ��ע�߰ѱ����ڵ�d����ͼƬ��עΪ��l���ĸ��ʣ����ǰ�����{ }��֮Ϊ��nλ��ע�ߵĸ��˴����ʣ�Ҳ�������Ļ���������һ�����������⣬һ����ע�ߵĻ���������ܾ������±�1�е���ʽ��
}��֮Ϊ��nλ��ע�ߵĸ��˴����ʣ�Ҳ�������Ļ���������һ�����������⣬һ����ע�ߵĻ���������ܾ������±�1�е���ʽ��
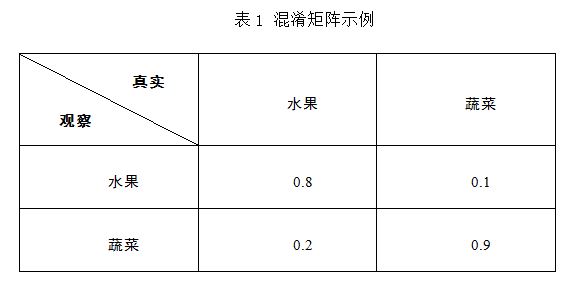
����ʵ��������Ϊÿһ����ͼ�������乫���������������������֮�䶼����ȷ�������Ƴ̶ȣ�������ϼٶ�һ������¶�������Ϊ���Ʒ��ϡ��������һ���˶��ԣ��������ע�����а�Ѽ�����Ϊ��ĸ���һ���ȴ���Ϊ����ĸ���Ҫ���������֮��ĸ��ʲ�������������ĸ������Ҳ���ںܴ�̶ȵõ����֡�������һ���裬�����֪ÿһ��Ŀ����ʵ��ע�����Ĺ�ֵ����ͨ��һ����ʽ�ӵõ���
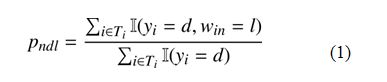
��ʽ(1)��ʾ�������б���nλ��ע�߱���������ڵ�d�����Ŀ�У�����עΪl����Ŀ��ռ�ı��������ڼ������ǿ�֪�����б�ע���ڱ�ע�����еı��������������ͬһ��ע���ڲ�ͬ�ı�ע�����еı���Ҳ��������������ǾͿ���ͨ�����Ϲ�ʽ������һ�ٶ��²���ȡֵ����Ȼ�������£�
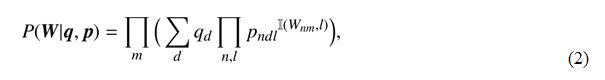
��ʽ�� ��ʾ��d����ע���ֵ�������ʡ���������������У�Dawid��Skene���õ�����������㷨����EM�㷨����һ�㷨��Ҫ��Ϊ������������������֡���Ӧ���ڱ��㷨�е�Ӧ�ã����������ģ�E�������Ӧ����ͨ��һ�������ĵ�ǰ����Ԥ��ֵ
��ʾ��d����ע���ֵ�������ʡ���������������У�Dawid��Skene���õ�����������㷨����EM�㷨����һ�㷨��Ҫ��Ϊ������������������֡���Ӧ���ڱ��㷨�е�Ӧ�ã����������ģ�E�������Ӧ����ͨ��һ�������ĵ�ǰ����Ԥ��ֵ ����������������������q�Լ�p�ı���ʽ�������M������������ʹ�ü���õ���q�Լ�p�ĵ�ǰֵ�����������п��ܵ�ȡֵ��
����������������������q�Լ�p�ı���ʽ�������M������������ʹ�ü���õ���q�Լ�p�ĵ�ǰֵ�����������п��ܵ�ȡֵ��
��������㷨�������ڲ����϶������£����������ʱ���ʽ���ֵ��һ�����⣬�ֱ��������ֵ������������⼫ֵ�㣬������ε������ջ��ȫ�����ŵ㣬��һ�㷨����ͨ�������ϸ�֤���������ԣ�ÿ����һ�ֵ������������ֵ�����ӽӽ����Ž⣬ѡ����ʵĽ�ֹ�����Ϳ��Ը�Ч�����ÿ��ͼƬ�Ĺ��Ʊ�ע�Լ�ÿ����ע�ߵĻ�������
��һ�㷨����ڶ���ͶƱģ������������ϸ�ڣ����Ա�ע�߳�������Դ����һ�������ļ��裬����ͨ�����ʵķ���������һ����Ϊ�Ͻ���������������ջ������ͨ����������㷨�������ķ������ܵ���˵��һ�ױȽ�������˼·������������֤����Ч���ڴ��������¶��ȶ������ڶ���ͶƱģ�ͣ��ر�ע��ƫ��ϴ�ʱ������ͶƱģ�͵�Ч��Ѹ���½��������ڻ��������ģ����Ȼ������ԽϺõı��֡��������ǽ�����ν���һ�㷨Ӧ����������������֮�С�
4����������MO-HMM�㷨
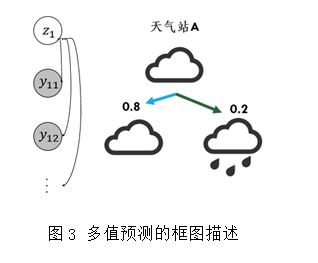
Ϊ�˸���ȷ��Ԥ������Ԥ���Լ�δ�����������Dz�����һ�����ƶ�۲�ֵ���������Ʒ�ģ�ͣ�MO-HMM����������������õ�������Ϣ���������Ʒ�����������ɢ�ռ�ʱ����Ϣ�ĺ���ģ�ͣ�������Ԥ���ij������ͬ���������ö�Ӧ��ͬ����״̬�����۲�ֵ���Ӧ����̨��Ԥ����Ϣ��
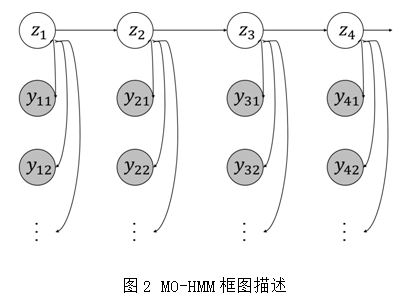
��Ӧ����һģ��ʱ����Ҫ��Ϊ�����֣���һ�ǻ����ڰ���������Ϣ���ϣ��ڶ������ǻ��������ɷ�����δ������Ԥ�⣬���潫�������������ֱ�չ����
4.1�ڰ�˼�������Ԥ������
�ڰ���Ӧ�������ǻ�����������һ��˼�룬��������Ԥ����Ӧ���У�����ͨ���������̨����Ϣ����ȡ����������Ϣ������һģ���У��ٶ�ÿһ������̨�����ض��������ĸ�����ȷ���ģ������Ϳ�����һ��ͳһ�Ļ�����������������������ֵĸ��ʣ�����ͨ�������Ȼ���ƾͿ��Եõ����в���ֵ������ÿ��ͼƬ����ʵ��ע��
�������ǿ�����һ����ֵ ����ʾ��
����ʾ�� ������̨���������
������̨��������� Ԥ��Ϊ�������
Ԥ��Ϊ������� �ĸ��ʣ���Ϊÿһ������������ض������ԣ��������������֮�䶼����ȷ�������Ƴ̶ȣ�������ϼٶ�һ������¶�������Ϊ���Ʒ��ϡ������������վ���ԣ����������Ϊ����ĸ���һ���ȴ���Ϊ��ѩ�ĸ���Ҫ���������֮��ĸ��ʲ�������������ĸ������Ҳ���ںܴ�̶ȵõ����֡�������һ���裬���Ĺ�ֵ����ͨ��һ����ʽ�ӵõ���
�ĸ��ʣ���Ϊÿһ������������ض������ԣ��������������֮�䶼����ȷ�������Ƴ̶ȣ�������ϼٶ�һ������¶�������Ϊ���Ʒ��ϡ������������վ���ԣ����������Ϊ����ĸ���һ���ȴ���Ϊ��ѩ�ĸ���Ҫ���������֮��ĸ��ʲ�������������ĸ������Ҳ���ںܴ�̶ȵõ����֡�������һ���裬���Ĺ�ֵ����ͨ��һ����ʽ�ӵõ���

ʽ�� ��ʾ����ȡֵ������������ֵ�ĸ�����ʽ��2-3����ʾ�������б���������̨��Ϊ�����������У���������������ռ�ı�������˶��ڵ�������̨���������ض�Ԥ��
��ʾ����ȡֵ������������ֵ�ĸ�����ʽ��2-3����ʾ�������б���������̨��Ϊ�����������У���������������ռ�ı�������˶��ڵ�������̨���������ض�Ԥ�� ��
�� �ĸ��ʿ���������ʾ,���幫ʽ����:
�ĸ��ʿ���������ʾ,���幫ʽ����:

���ڼ������ǿ�֪����������̨��Ԥ������еı�����������������ǾͿ���ͨ�����Ϲ�ʽ������һ�ٶ��²���ȡֵ����Ȼ�������£�
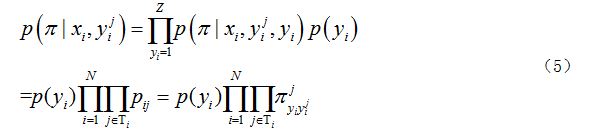
��ʽ�� ��ʾ����̨���ܸ������������������ƶϵIJ��������ǰ�ÿ�����ʵ����
��ʾ����̨���ܸ������������������ƶϵIJ��������ǰ�ÿ�����ʵ���� ���˳�����������������ʵ�����ǰ�ÿ�����ʵ��������ֵ���ֵĸ����ڹ��ƹ����е�������֪����������ͨ�������Ȼ�ķ�������Ժ�
���˳�����������������ʵ�����ǰ�ÿ�����ʵ��������ֵ���ֵĸ����ڹ��ƹ����е�������֪����������ͨ�������Ȼ�ķ�������Ժ� Ҳ����ͨ����������ʾ���������ʽ���£�
Ҳ����ͨ����������ʾ���������ʽ���£�
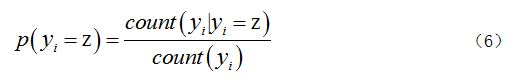
��õ� �Լ�
�Լ� �ı���ʽ��ʹ������Ȼ���ʺ���ȡ�����ֵ����������ȡֵ��ʹ�ø��ʵ��Kֵ�㣬�������տ��Եõ�ÿ����ʵ������Ԥ��ֵ��
�ı���ʽ��ʹ������Ȼ���ʺ���ȡ�����ֵ����������ȡֵ��ʹ�ø��ʵ��Kֵ�㣬�������տ��Եõ�ÿ����ʵ������Ԥ��ֵ��
4.2�����ɷ���Ԥ��δ������
�ڵõ�ÿ��������Ԥ��ֵ֮�����ǿ���ʹ�������ɷ�����Ԥ��δ��������������������ʱ��仯��Ϣ���ڵõ���ǰ���������֮��һ�������������ͨ��һ�����ʷֲ�����ʾ�������ʾ����ͼʾ�⣺
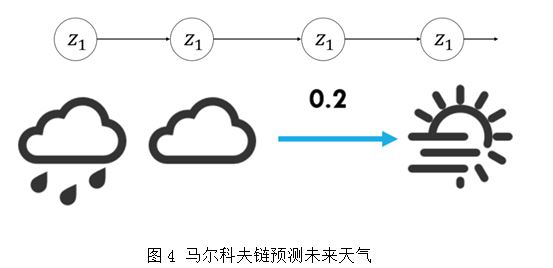
�����Ԥ������У����ǿ��Է��֣���һ�����������������ʽ����ʾ��
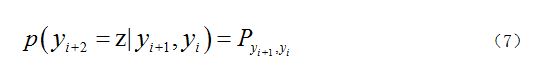
������ʾ��P����Ϊת�Ƹ��ʾ�������ֵ����ֱ��ͨ��ͳ������ת�������������Ӧ�������ɵõ���
4.3.�Իع�ģ��Ԥ��δ������
��Ԥ��δ���Լ���������ʱ�����������Ѿ������һ���ܺõؽ��������Ȼ������Ԥ���У����¡���ѹ��ʪ�ȵ���Ϣ�������������������ֱ��ͨ��ǰ����ɢ������������������������������ʹ�����Իع�ģ����Ԥ��δ����������Ϣ������Ϊ��һ�������Ϊǰ�������µ�������ϣ�һ������£���һ����������Ԥ��������һ����������˿��Եõ�Ӧ�á�
5. ϵͳ��������

��������������Ԥ����Ϣ�������ϵͳ�У���Ҫʵ������������ݣ�
1.�Ѽ���������Դ������Ϣ�㼯������������ʷ����Ԥ�����������Լ�����ͬ������Ϣ��Դ������Ԥ��ͳһ��ʽ��������ʾ���Թ۲�����֮��IJ��죬�����û��Լ�ѡ������ӿ��ŵ���Ϣ��Դ����ʷ����������Ϊ������һЩ���������ͨ���ƶ����к��ض�����ʷ��Ϣ�����Ƕ����Ը�����������������
2.���ϡ���������Ϣ������ϣ�����ͬ������Դ�㱨������ͬʱ���������Ͻ����ͨ�����ǵ��ڰ��㷨���Բ�ͬ��Դ��������Ϣ���ճ����������������ϣ����ո���һ���㷨Ԥ��Ľ����
3.Ԥ�⡪��Ԥ��δ��������������������������Ԥ����Ϣ����Ԥ���������棬ʹ�������ɷ������������������б仯���ɣ��Ӷ�Ԥ��δ���������������µ����������Եı仯�ϣ�����ʹ�����Իع�ģ�������������ڹ��ɡ�
�����ڱ�2���������˺�̨ʵ�ֵ���Ҫ���ܡ�

5.1.������
Ϊ��ʹϵͳ���������У�ǰ�˺�˿��Բ��п���������ҲΪ��ϵͳ������չ�ԣ�Ӧ�ú�̨������������Ҫ����Web Service��˼�롣��ǰ�˺ͺ����Ը��룬����ṩWeb API��ǰ��ͨ���ض���ʽ��Get�����������Ϣ��Ȼ������ҳ���Ͻ���չʾ��
��̨����ʱʹ����Python���ԣ�����Ҫ����ΪPython��Web���ʮ�ַ��㡣Ϊ��ʵ�����繦�ܣ�����ʹ����Djangoƽ̨���к�̨����罻������ز�����
������̨API�ı�д����WSGI API�Ĺ淶����˿��Ա����㷺�ĵ��ã�Ҳ�����ٺ����ĸ�����Ӧ���з������ã����ظ�ǰ̨����Ϣ����JSON��ʽ���䣬���ڽ�����
5.2.��̨�ӿ�
��̨�ṩ��ǰ̨�Ľӿڽṹʮ�ּ���Ҫ�������ֹ��ɡ�
���е�һ����areanameΪ��Ҫ��ѯ�ij������ƣ��������ĸ�ʽ���뼴�ɡ�Date������Ҫ��ѯ���������ڣ���Ҫ��ȷ�����ӣ�������Ϊ�ڲ�ѯ��ǰ����ʱ���е�����վ�����������㱨������
Type������������͡�������Ϊforecast3dʱ�������ؼ�������վ����δ��3�������Ԥ����������Ҫ�����˰ٶ�������open weather������Ϣ��Դ���Լ��������ṩ����ʷ������Ϣ��������Ϊcforecast3dʱ�����ṩδ����������Ԥ���������������hmmforecast5d���صĽ������ͨ����ѯ������Ϣ���������Ʒ�ģ��Ԥ��ĵ��ĺ͵���������Ԥ����
�����ṩһ�������IJ�ѯ��ַ�����ο���
![]()
�����ַ�������������2015��9��15�յ�����Ԥ�������صĽ����ͨ������ѧϰģ�����ϵõ���������Ϣ��
5.3.�����ʽ
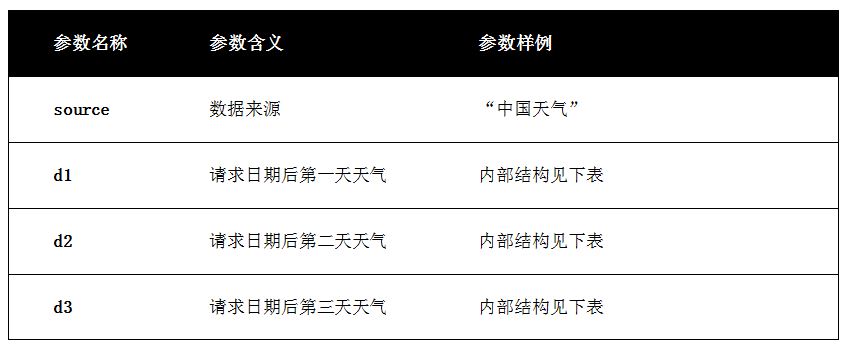
���ڲ�ͬ��������ֵ����ͨ��JSON�ĸ�ʽ�ṩ�����ڷ������ݽ϶࣬�����ڱ�3��ֻ������δ��3�������ķ���ֵ������ϸ���͡�


ͨ���˱����Կ��������ǵķ��ؽ��ʮ�ַḻ�������˷��������٣��¶ȣ�ʪ�ȣ���ѹ�ȵȣ���������ǰ��չʾ�ռ�����ƣ��ܶ���Ϣ��û��չʾ��
6. ������
�ܵ���˵���������ǵIJ��ԣ�����Ԥ������ϵͳ�����ﵽ�����������ij��ԡ�ʵ�������ǰ�����Ϣ����չʾ����Ϣ������ϡ�δ������Ԥ�����������ݣ����Һ�̨�Ļ���ѧϰ�㷨Ҳ�õ���������ʵ�֣���������Է���Ԥ�ڵĽ����
���ǽ�ϵͳ����ط�������Sina App Engine�ϣ���һ����Ŀǰ���ߣ�����ͨ����ַhttp://tianweather.sinaapp.com/static/iisstart.htm�������鿴Ч���������Թ�ȥһ���µ��������лز⣬���ǿ�����������Ԥ���㷨��ȷ�̶ȡ�Ȼ�����������Ƚϴ������ڵ������ԣ�������ͨ����ֵ�ķ���������ǵ��㷨��ȷ���ϵ����ȳ̶ȡ�Ϊ�����һ���ѣ�����ֻͳ�����ǵ��ڰ������㷨������������Ԥ���������������˹���֤�����ǵ��㷨�ڹ�ȥ30���У�����20����Ա�Open Weather �Ͱٶ������ṩ��ȷ������Ԥ������һ�����֤�������㷨����Ч�ԡ�

�����
[1] A. P. Dawid and A. M. Skene. Maximum likelihood estimation of observer error-rates using the em algorithm. J. Roy. Statistical Society, Series C, 28(1):20�C28, 1979. 1, 2, 5, 6
[2] D.M. Green and J.M. Swets. Signal detection theory and psychophysics. John Wiley and Sons Inc, New York, 1966. 5
[3] V.C. Raykar, S. Yu, L.H. Zhao, A. Jerebko, C. Florin, G.H. Valadez, L. Bogoni, and L. Moy. Supervised Learning from Multiple Experts: Whom to trust when everyone lies a bit. In ICML,2009. 1, 2
[4] V.S. Sheng, F. Provost, and P.G. Ipeirotis. Get another label? improving data quality and data mining using multiple, noisy labelers. In KDD, 2008. 1, 2
[5] P. Smyth, U. Fayyad, M. Burl, P. Perona, and P. Baldi. Inferring ground truth from subjective labelling of Venus images. NIPS, 1995. 1, 2
[6] M. Spain and P. Perona. Some objects are more equal than others: measuring and predicting importance. In ECCV, 2008. 1, 2
[7] L. von Ahn, B. Maurer, C. McMillen, D. Abraham, and M. Blum. reCAPTCHA: Human-based character recognition via web security measures. Science, 321(5895):1465�C1468, 2008. 2
[8] PeterWelinder and Pietro Perona. Online crowdsourcing: rating annotators and obtaining costeffective labels. In IEEE Conference on Computer Vision and Pattern Recognition Workshops (ACVHL), 2010. 1, 2, 3
[9] T. D. Wickens. Elementary signal detection theory. Oxford University Press, United States,2002. 5
[10] Neal, Radford M. "Markov Chain Sampling Methods for Dirichlet Process Mixture Models." Journal of Computational & Graphical Statistics9.2(2012):249-265.
[11] Zhou, Dengyong, et al. "Aggregating Ordinal Labels from Crowds by Minimax Conditional Entropy." Proceedings of International Conference on Machine Learning (2014).
[12] Zhou, Dengyong, John Platt, Sumit Basu, and Yi Mao. "Learning from the wisdom of crowds by minimax entropy." In Advances in Neural Information Processing Systems 25, pp. 2204-2212. 2012.
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
- �߽��츮������������۲�վ ����۲��γ���������
- �й��ɹ������������E�� ������������Ԥ��������
- ���������ȫӦ�ǵ�һλ�ġ�����������̸ԽҰ��
- ��������������ů �������½����30��
- ����������������ôԤ��������
- ����ʡ���ǻ�������������ũ����չ
- ɽ��ʡ�ٰ�����������ϵ�п��ջ
- �߽��������̨���˽��������������������֪�Ⱦ���
- ���ܽ���������� 24�ճ�������Ȼ����
- �½��չֿܾչ������������Ļ���Ӧ�Դ�ѩ����
��������
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
