




















大數據時代的網絡評論數據處理技術應用
摘 要:Web2.0帶來了信息傳播的根本性變革,信息不僅僅總量大,更體現了及時性、流動性的特點。對於信息的掌握、分析和運用,利用文本挖掘技術對網絡評論的信息提取,可以說是近年來的熱點領域。本文重點探討網絡評論中具有較強應用性的四種分析:主題詞提取、社會網絡分析、輿情分析以及情感強度分析,這四種分析都是以計算機文本挖掘為技術支持,是新聞學、傳播學、營銷學以及社會學研究中具有較強應用性的領域。
關鍵詞:網絡評論﹔文本挖掘﹔關鍵詞提取﹔網絡分析﹔情感傾向
一、文本挖掘的概況
1.研究意義
互聯網自產生那天起就有著強大的功能,隨著世界網民數量的激增,近十年來,移動互聯網網民更是呈現指數級的增長[1]。在Web2.0的新環境下,基於互聯網的輿論平台包括論壇、微博、微信、QQ、網絡購物商業平台等所有開放平台成為巨大的信息場,這些信息不僅巨大(數據存儲量已經從TB級別升至PB級別),而且體現了及時性、互動性、流動性等屬性,傳統的數據收集(主要指結構性數據)和輿情分析方法處理能力非常有限,也影響了有效分析網絡評論的效果。有鑒於此,從紛繁龐雜的海量非結構性數據中,挖掘提取有價值的信息變得非常重要。而基於Web2.0的文本挖掘在網絡營銷和輿情追蹤領域上,對於決策和未來趨勢的預測上能夠提供更加深層和豐富的信息。文本挖掘屬於大數據分支領域,十三五期間,大數據應用更是提到了“助力產業升級轉型和社會治理創新”的高度[2]。目前我們看到的文獻大多基於計算機軟件科學研究不同算法和原理,比如提出新算法或者優化原有算法,在精確度上不斷改進。在商業智能研判上,比如客戶產品需求、精准營銷上,各個大的網絡銷售平台均由團隊做大數據分析,數據挖掘已經比較成熟。而在社會科學領域中,比如傳播學、新聞學、社會學大多依賴傳統的抽樣調查,如何應對新的社會發展形態,優化社會治理模式,借助文本挖掘技術對於拓展研究領域,深化研究方法均具有重要的意義。網絡評論在互聯網信息中直接體現用戶個人態度、情感,這些信息特征是怎麼樣的又是怎樣關聯的,運用文本挖掘方法可以回答這些問題。
2.文本挖掘的特點和方法
網絡評論屬於文本信息,文本挖掘也稱為文本數據庫中的知識發現,是從大量文本的集合或者語料庫中提取事先未知的,可以理解的有潛在實用價值的模式和知識[3]。在大數據應用商業和社會治理層面,人們更看重的是精准預測。網絡評論屬於非結構性數據,其中意見挖掘主要針對非事實性主觀文本,加之中文語法的特點,這三個因素增加了文本挖掘的難度,中文文本挖掘技術至今在算法和精確度方面還在不斷探索。概括而言,文本挖掘的方法主要有以下四個方面:(1)分詞技術。中文分詞時中文信息處理的基礎,比如中科院的ICTCLAS分詞系統可以提供詞性標注、新詞識別、用戶詞典等,是開源分詞系統﹔(2)信息提取和關聯分析。信息抽取的目的是抽取出指定的事件、事實等信息供用戶查詢使用。如新聞報道中的時間、地點、人物、關系、事件。關聯分析是發現兩個或者兩個以上的變量取值之間存在某種規則,比如時序關聯、因果關聯﹔(3)分類分析。找出並區分數據分類的模型,以便能夠使用模型預測給定數據對象所屬的數據類。比如,財經新聞、社會新聞等新聞歸檔的應用,建立先模型(分類器),再將文檔通過分類器歸為某種類別﹔(4)聚類分析。將物理或抽象對象的集合分組成為由類似的對象組成的多個分析過程。它的目標就是在相似的基礎上收集數據來分類。比如圖書評論中抽取好、一般、比較差等。
二、文本挖掘的技術實現
文本挖掘技術屬於計算機、數學等學科,研究主要側重在研究技術層面,其中僅僅分詞方法和算法就有十幾種。目前的文本挖掘側重在不同領域中的應用,比如在輿情領域,商業智能研判領域中。越來越多的語言或者軟件的開源系統和界面友好的數據挖掘軟件比如KNIME,以及在線網站玻森,隻需要“拖、拉、拽”就可以實現部分的數據挖掘,所以越來越多的商業領域和社會領域可以使用文本挖掘。本文主要介紹在文本關鍵詞提取、網絡輿情分析、社會網絡應用分析以及用戶情感傾向分析。這四種應用通過文本挖掘可以實現,具體如下:
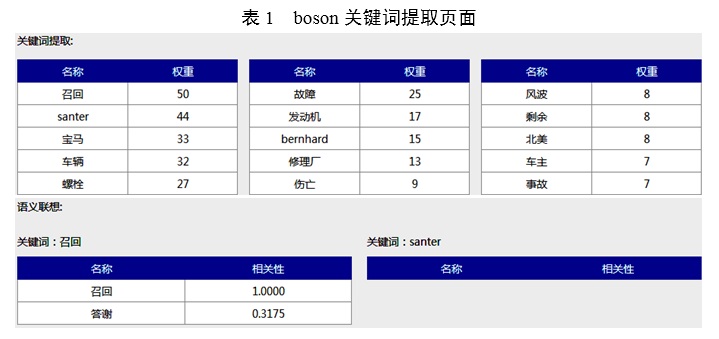
1.文本關鍵詞提取。新聞學中的標題往往具有概況、總結的功能,需要新聞從業者或者讀者看完全篇再歸納整理出來新聞摘要。那麼在海量的文章中,在全面把握文章的中心思想的基礎上,迅速(每小時至少處理50萬篇文章)提取出若干個代表文章語義內容的詞匯或短語,相關結果可用於精化閱讀、精准排序。比如2015年李克強總理的政府工作報告,依據分詞技術計算詞頻,可以提取出市場化、改革等關鍵詞。這些關鍵詞往往能反映出政府工作報告的主干特征。比如數據挖掘工具KNIME軟件和Orange。另外,在線中文數據挖掘網站玻森中文語義開放平台(http://bosonnlp.com/demo)可以進行分詞處理,關鍵詞提取,形成新聞摘要。表1是Boson根據寶馬車召回新聞形成的關鍵詞提取頁面[4]。
2.輿情分析應用。在海量的網絡信息環境下,人們面臨的問題不是信息匱乏,而是信息過載和信息噪音,所以人們關注的重心已從搜索採集的信息序化變為分析為主的信息轉化。輿情信息獲取的速度和質量依賴於輿情系統技術。網絡輿情系統的主要功能有信息數據自動採集、文本自動聚類和自動分類、話題與跟蹤。目前輿情分析主要集中在信息採集、熱點問題發現和熱點評估[5]。信息採集主要用爬虫Python以及Heritrix從web、博客、郵件、微博等採集數據,存儲在PostgreSQL數據庫中,再進行主題提取等。熱點問題發現技術主要使用文本聚類分析的辦法發現網絡輿情熱點。熱點事件抽取方面主要是首先對微博數據進行預處理,去除數據中噪聲信息﹔文本聚類有很多算法,相對傳統的Single-pass和K-means規則簡單比較易用[6]。輿情處理本質上是中文聚類和分類處理,關鍵是主要用到分詞系統,Python語言調入的jieba詞包,再結合各個領域的詞庫可以實現。
3.社會網絡分析。本文介紹應用社會網絡分析(關聯分析)技術實現KOL(Key Opinion Leade)意見領袖查找,KOL被稱為意見持有者的識別,是影響力較大的用戶。意見領袖能在短時間內對數量眾多的用戶產生直接或間接的影響。因此,挖掘意見領袖成為了解決社交網絡中許多實際問題的關鍵點,社會治理當中的輿論引導,特別是傳播學領域中的社會網絡研究(如圖1所示),特別是近年來的商業上比較熱門的廣告投放和微商開展。比如用戶屬性分類方法進行意見領袖挖掘,主要依據關注度、粉絲數、發帖數以及是否認証對用戶重要性進行評分,以關系為處理單位的社會網絡分析方法在意見領袖識別當中應用越來越多。網絡分析有了非常多的理論成果和軟件分析工具,方法有隨機網絡、規整網絡、小世界理論等,Ucinet是主要處理數據的關聯規律軟件,結合網絡的可視化技術,用Netdraw軟件進行展現,這兩款軟件均可以人機互動,操作比較簡單。
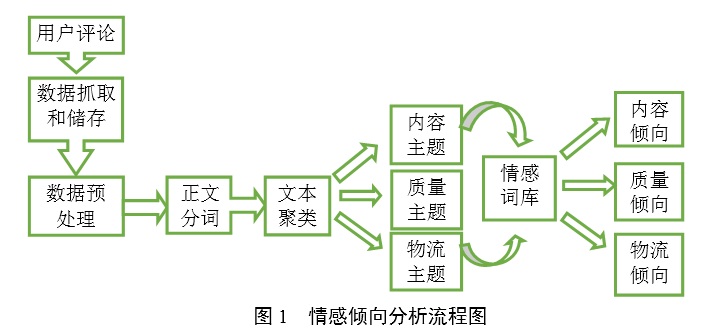
4.情感傾向性分析。主要指的是用戶評價分析,主要是態度、評價等級的測量。過程如下:抓取獲得語料,其工具主要是Python網絡爬虫,這是非常龐大的海量數據,將原始數據存儲在PostgreSQL數據庫中。不過,原始數據中有很多無用信息、重復評論等這些都是屬於無效信息,所以要進行語料預處理,將PostgreSQL數據庫轉換成文本格式(txt)格式文件,再用停用詞表進行過濾垃圾。預處理之后,開始進行分詞處理,隻有進行分詞計算機才能找到關鍵詞和特征詞,分詞技術和分詞方法已經比較成熟,業界使用比較多的中文分詞工具是ICTCLAS中文分詞系統[8],分詞工具常用的有jieba和Ansj。首先是將海量的數據通過分詞找到主題詞,比如購物平台上的服裝評論,其中有款式、質量、物流三個主題詞,按照三個主題詞使用Word2Vec進行詞語聚類,把語義距離相近的詞歸為一類,比如在預處理后的可用語料庫中把時尚、休閑等歸為款式一類,把正品、不掉色等放在質量一類,把塊、及時放在物流一類。之后分別進行HowNet情感詞典構建和程度級別詞典構建以及否定詞典構建,再進行主題詞分類,計算得出句子情感傾向,用戶情感傾向,最后分別得出質量、內容、物流情感傾向(如圖1所示)。
這裡需要說明,四種文本挖掘可以交叉使用,比如輿情分析中評論的情感性分析,可以通過上述第四種操作實現。不管是哪種分析,都包含數據爬取、存儲、分詞。
三、探討和總結
隨著數據挖掘技術在各個領域的不斷擴展和深入,實際生活中,文本挖掘還可以拓展更寬更深的應用,不僅僅限於本文列舉的四種。大數據變成人們生活中的思維意識離不開數據挖掘技術更多的使用,而文本挖掘可以一定程度上實現更多人的技術可能,這需要更多的團隊合作,更重要的是有更多的專業交叉,比如計算機應用和社會學、傳播學專業、漢語言學的交叉。
參考文獻:
[1] 中國互聯網絡信息中心(CNNIC)發布第37次《中國互聯網絡發展狀況統計報告》:截至2015年12月,中國網民規模達到6.88億,互聯網普及率達到50.3%,手機網民規模達6.20億,有90.1%的網民通過手機上網.
[2] 出自2016.3月《國民經濟和社會發展第十三個五年規劃綱要》第二十七章:“國家大數據戰略”
[3] 費爾德曼.文本挖掘[M].北京:人民郵電大學出版社,2009.
[4] http://www.chinadaily.com.cn/hqgj/jryw/2014-04-15/content_11593048.html.
[5] 蔡淑琴,張靜,王旸.基於中心化的微博熱點研究方法[J].管理學報,2012,9(6):874-879.
[6] 唐濤.大數據環境下輿情分析[J].現代情報,2014,34(3):3-6.
[7] 張莉,蘇新寧,王東波.通用領域的中文意見的挖掘研究[J].情報理論與實踐,2012,35(4):103-108.
[8] 劉志明,劉魯.基於機器學習的中文微博情感分類實証研究[J].計算機工程與應用,20112,48(1)1-4.
分享讓更多人看到 
推薦閱讀
傳媒推薦
 @媒體人,新聞報道別任性
@媒體人,新聞報道別任性 網站運營者 這些"紅線"不能踩!
網站運營者 這些"紅線"不能踩! 一圖縱覽中國網絡視聽行業
一圖縱覽中國網絡視聽行業
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
