




















基於特征融合的物體跟蹤系統設計與實現
摘要
物體的檢測與跟蹤目前在計算機視覺領域是十分前沿的研究方向,其可廣泛應用於重要會議安保,軍事防御,區域警戒等多種應用場景。目前,在物體檢測與跟蹤領域最具發展前景的研究熱點是基於深度特征的檢測與跟蹤模型的設計,因此本設計基於深度特征和傳統特征相融合的方式,對單目標場景下,改進相關算法,並實現了具有物體檢測、目標跟蹤、兼具性能測試和關鍵測試結果文件保存功能的物體檢測與跟蹤系統。並最終通過跟蹤數據集對相關算法進行評測。
關鍵詞:目標檢測,目標跟蹤,圖像處理,特征融合﹔
1.1 課題研究前言與背景
目標跟蹤在計算機視覺領域,有著重要的地位,是一項多學科交叉技術,融合了機器學習,計算機視覺,模式識別等學科的技術,並在很多領域得到廣泛應用,包括自動駕駛、智能視頻監控、人機的交互等。除此之外,目標跟蹤在一些新興領域,如智能交通系統、精確制導系統、智能醫學診療等,有著十分重要的應用價值,尤其是在視頻監控領域與軍事領域應用最為廣泛,這些場景下都需要對特定目標物體進行建模跟蹤,分析其行為軌跡、制定解決方案等。
一個物體檢測與跟蹤系統, 給出視頻或攝像頭視頻輸入,系統能檢測到視頻中出現的物體,給出檢測框和類別,並能夠根據初始檢測框進行連續的物體跟蹤。跟蹤結束后保存系統運行過程中產生的有用信息。同時系統應當能夠連續使用,即在不重啟系統的情況下繼續進行處理其他輸入,以保障良好的人機交互性。
1.2 目標跟蹤算法概述
目標跟蹤領域近年來在持續發展,算法的性能也在逐漸提升。目標跟蹤的任務是,在給定視頻序列第一幀中目標物體的初始狀態后,對后續視頻幀中目標的位置進行預測,然而一些固有因素依然會影響跟蹤的效果,如遮擋、尺度變化、光照變化、背景干擾等。

圖1-1中列出了幾種影響跟蹤效果的因素,這就要求跟蹤器具有較高的辨別能力。過去幾十年,目標跟蹤算法的研究在計算機視覺領域十分活躍,從最早的粒子濾波框架過渡到相關濾波,跟蹤算法的性能逐漸提升,隨著近年來機器學習算法的引入,跟蹤算法呈現百花齊放的姿態,性能和魯棒性都獲得顯著提升。深度學習技術的引用,使得算法精度提升到新的高度。2015年至今,是深度學習技術高速發展的時期,深度學習技術也被應用到計算機視覺的各個領域。深度學習在目標跟蹤領域的應用,最初形式是將深度神經網絡提取到的特征替換人工提取特征,應用到相關濾波的跟蹤框架中,如deepSDRCT、C-COT、ECO等算法,逐步加深了對深度特征的應用。深度網絡提取出的目標特征,要優於傳統的手工提取的如HOG或SIFT等特征,但是也帶來了計算量的增加。但是深度特征包含更多的語義信息,淺層特征包含更多的邊緣信息,所以採用將深層,淺層特征相融合的深度學習框架進行算法設計,使得算法效果有較大的提升。
1.3 目標檢測算法概述
目標檢測傳統方法方面主要是基於滑動窗口的,其主要的思路為:針對輸入的圖片,設計不同尺度的滑動窗口,對整個圖片進行暴力搜索,由此得出若干個候選區域,對每一個候選區域進行特征提取交付到分類器中,分類器一般採用SVM、AdaBoost和Decision Tree等﹔最終得到物體分類結果和物體在圖像中所處位置坐標。
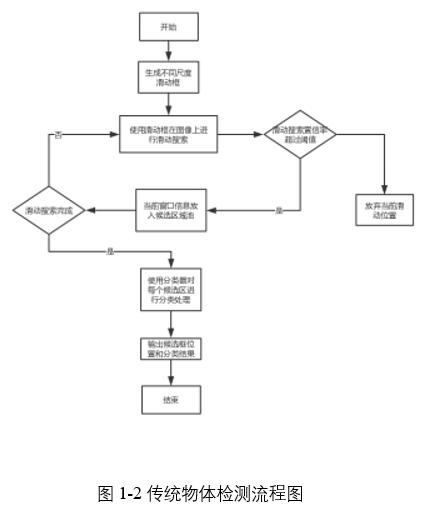
目前基於深度學習的物體檢測方法主要可以分成兩類:即一階段方法和兩階段方法,顧名思義,一階段的主要思想是在需要進行檢測處理的圖片上設置一系列的基本框,隨后直接將這些基本框輸入到神經網絡中進行檢測和分類得到最終結果。而兩階段是在一階段第一次檢測和分類並得到候選框的基礎上,對候選框進行特征提取后再次進行分類和檢測,得到最終結果。其中一階段檢測算法有SSD,YOLO算法族﹔二階段檢測算法有R-CNN,Fast R-CNN,Faster R-CNN等。一階段算法相對於二階段算法速度更快,但二階段多了再檢測和分類的步驟,因而精度更高。
2.1基於特征融合的跟蹤算法設計
2.1.1跟蹤算法主體框架設計
目標跟蹤研究任務中,先驗信息隻有第一幀目標物體真實的bounding box,即對於整個跟蹤序列來說,算法的輸入隻有一個四元組(x, y, w, h),其中,x, y是物體在圖片中的坐標值,w, h是目標物體的寬度與高度。算法的目的是根據此元組對后續視頻幀中的目標物體位置進行估算預測。本系統基於MDNet提出一種深度學習框架,如圖所示。
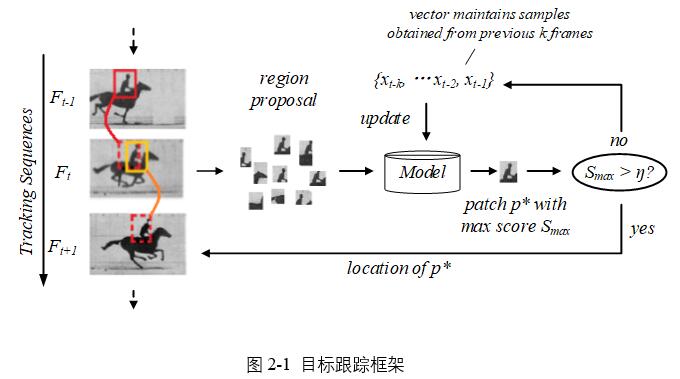
當前視頻幀接受上一幀中目標物體的位置作為輸入,記為P,在P周圍一定范圍內進行樣本的採集即採用模擬高斯分布和區域提議策略進行採樣,採樣一定數量且在一定范圍內坐標、尺度呈高斯分布的圖像塊。將採集的圖像樣本輸入模型得到置信分數,輸出結果表示各個圖像塊的得分即與目標相似的置信度,取其中具有最高置信度的圖像塊位置P*作為候選的預測目標位置。將P*的得分與設定算法閾值η比較,若score>η,則可認為P*即為當前幀中目標的位置,將P*作為下一視頻幀的輸入,迭代進行﹔若score<η,即表明採樣的圖像中不包含目標物體、模型預測失敗,將啟動檢測算法進行修正。
跟蹤過程中要對模型進行自適應更新。採用一定方法將網絡模型參數初始化后,可以接受第一幀的輸入對后續幀中目標物體進行預測定位,然而,跟蹤過程中目標物體不斷在變化,會經歷形變等情況,導致目標物體與初始狀態相差越來越大,最開始的模型對目標物體特征的擬合能力下降,如果不根據目標物體最新狀態採樣來更新模型,會導致目標轉移或丟失的情況。在跟蹤控制中,採用長短時更新的策略,並相應的維護兩個樣本空間,分別是長樣本空間與短樣本空間。長樣本空間中,存儲前200幀採集到的正樣本與負樣本,短樣本空間存儲前50幀提取的正負樣本。長樣本空間每隔一段時間啟動一次,間隔一定周期,經過實驗選定更新周期為20幀一更新。短時更新隻發生在跟蹤失敗的情況下,即網絡輸出的最高正得分小於設定閾值時,實驗過程中設為0.4。
2.1.2多特征融合跟蹤算法設計
在目標跟蹤算法中,目標特征的選取最為重要,能否選擇到合適的目標特征,直接影響到跟蹤效果。算法理想的特征不僅能夠對物體表觀進行建模,而且需要具有較強的判別力,對目標發生的形變、遮擋預計跟蹤背景發生的變化具有較強的魯棒性。傳統的目標跟蹤提取的特征大多為手工設計的特征。
顏色特征
自然圖像都包含豐富的顏色信息,早期的目標跟蹤算法也充分應用了目標顏色的特征。RGB顏色空間具有直觀性、易計算性,廣泛被應用到目標顏色的表示中,其中顏色直方圖是最為常用的顏色特征,採用顏色直方圖,可以計算每種顏色在圖像顏色空間中所佔的比例,從而代替各顏色在圖像中的位置,通過統計顏色的分布作為目標特征,然而,採用顏色分布來代替顏色位置的統計會丟失部分空間信息,對於具有較清晰輪廓的目標物體來說描述性不強。
輪廓特征
關於底層的視覺研究表明,人類視覺對物體的鎖定與跟蹤,是先鎖定物體的輪廓或邊緣,再對物體內部細節進行理解,邊緣信息或輪廓信息對於物體的識別等也是非常重要的特征,通過輪廓信息可以對目標物體進行定位,在跟蹤過程中,可以通過邊緣檢測的方法預測出物體邊緣的變化信息,而且輪廓特征的產生依靠的是目標物體與背景產生的運動邊緣,不依賴於人的主觀認識,相比於顏色特征,具有更高的簡單性和准確定。
紋理特征
紋理特征對於圖像來說是比較抽象且泛化的特征,但是紋理特征可以用來判斷圖像密度的變化,同一張圖像中的不同物體,其紋理特征有很大不同。紋理特征對圖像的平滑度以及規律性進行了量化,不僅對圖像上的顏色信息,而且對光強信息、輪廓信息等進行了描述。紋理特征通常不是直接提取,而是通過對圖像的預處理得到。常用的紋理特征包括:LBP[38]特征、SIFT特征、小波特征等,並且具有光照不變性,在目標場景中發生較強的光照變化使算法具有較強的魯棒性。
結構特征
隨著機器學習和深度學習技術的發展,結構化特征逐漸被運用到目標跟蹤算法中。結構化特征可以認為是由深度神經網絡提取出的目標特征,是一種從簡單到復雜、具有結構性的特征。深度神經網絡與人的視覺皮層具有相似結構,對於視覺信息的處理是分級的,從底層的某些網絡對圖像的小部分進行理解,提取輪廓、顏色等表觀特征,隨著網絡逐漸加深,對於特征的抽象層次越來越高、范圍越來越大、內容也越來越豐富,最后提取出整個目標的特征,是一個由底層到高層的結構性抽象過程。由深度網絡提取出的特征豐富且精確,能大幅提高跟蹤性能,不足之處在於計算量龐大,跟蹤速率降低,。跟蹤過程中,卷積網絡底層提取的表觀信息、如輪廓信息、顏色信息、紋理信息等,可以反映目標物體的形變、遮擋的等情況。課題對網絡模型的第二種優化方法是將淺層卷積提取的表觀特征與深層卷積提取的語義特征進行融合,來對目標物體和背景進行判別。
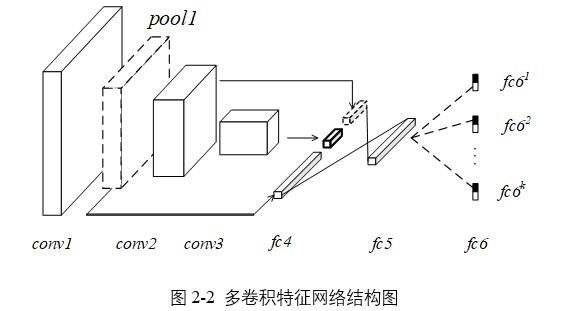
將每層卷積特征拉伸平鋪成一個全連接向量,最后將各個層的向量拼接成總的一維特征向量作為全連接網絡的第一層輸入。融合前,全連接層的輸入大小為4608,若直接將各個卷積層拉伸之后拼接,由網絡結構參數可得全連接輸入的大小為258280,是基本模型輸入的60倍。論文對第一層與第二層卷積下採樣之后的特征圖進行連接操作,全連接層輸入大小為38752,相比於直接對卷積層特征操作減少了6倍的參數量。
2.1.3多特征融合跟蹤算法自適應框改進
對於MDNet缺少可根據跟蹤目標相對幀的大小形態變化而自適應的跟蹤框。
主要流程可以描述如下:接收到傳回的當前框信息后先進行修正邊界操作,這是考慮到可能當前跟蹤框已經發生嚴重漂移現象,如果跟蹤框右邊界坐標小於零說明跟蹤框從幀左側漂移出幀,則應將跟蹤框進行向右調整﹔如果跟蹤框上邊界小於零則說明跟蹤框從幀下側漂移出幀,應當進行跟蹤框向上調整處理。同時如果發現跟蹤框大小已經接近幀的大小,則減小跟蹤框大小。隨后進行跟蹤框大小的具體調整,設計了大小兩種模板,首先對當前幀進行峰值檢測,如果對峰值做增益超過原峰值,則使用較小模板,如果對峰值做減益也超過峰值則更傾向於使用較大的模板。同時進行新的峰值計算。由於跟蹤框大小可能已經發生了改變,所以再次進行邊界調整,獲得到當前最新的框,使用該框進行重新訓練樣本,返回檢測框信息作為跟蹤結果

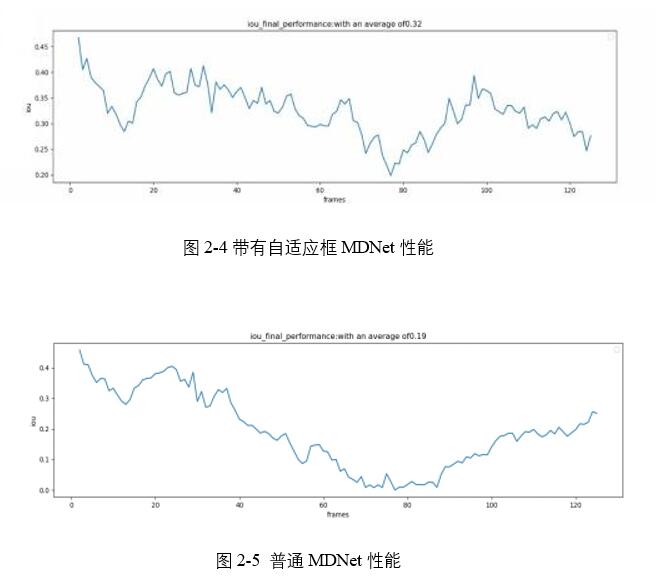
另外對於同一數據集,也測試了兩版算法的相關數據性能,如圖3.5和3.6所示是OTB100-DOG上進行測試得到的IOU跟蹤框交並比的對比結果。可以看見IOU性能發生極大提高。
2.2檢測算法主體框架設計
YOLO算法是一階段物體檢測算法,即直接將圖像輸入到卷積神經網絡中,得到檢測結果。其具體檢測過程可描述如下:首先,將圖片歸一化到統一大小,輸入到卷積神經網絡中,神經網絡先劃分成S*S個網格,其中每個網格負責預測B個框和P個置信分數,這裡需要說明的一點是:框包含五個參數,分別為(x,y,w,h,c),其中參數(x,y)代表框中心坐標,(w,h)代表框的長和寬,而C代表這個框存在的置信度,實際上可以將C描述為IOU,即預測框與實際框的交並比。在此基礎上,隻有當預測的框中心落到了某個網格中,該網格才會對這個框的后續處理負。在檢測過程中,對於每一張圖片會輸出S*S*[B*5+P]=7*7*[2*5+20]個張量,張量經過編碼后經卷積神經網絡輸出得到暫時結果后,經過非極大值抑制(NMS)的方法,確定最終得分最高的檢測框和分類結果。
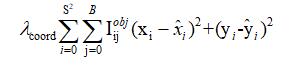
用於計算預測邊界框長高損失的函數如下:
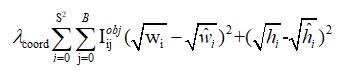
用於計算框的置信度得分損失函數如下所示。其中C是置信度得分, 是預測和真實框的交並比,當IObjij=1時說明,網格中存在目標,Inoobjij代表完全相反的情況。
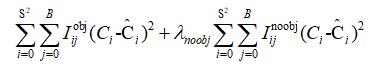
最終用於計算目標分類損失的函數如下所示。
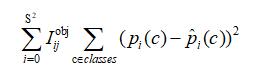
Yolov3的特征提取網絡採用了前20個卷積層,1個avgpooling層和一個全連接層。但是一個方格隻能預測一個物體,對小物體很難檢測,相對於FastRCNN存在著更多的位置錯誤。
3.1跟蹤算法性能對比
OTB數據集是學者吳毅在2013首次發表的集成視頻數據集,統一了目標跟蹤領域的評價標准,OTB-2013整合了2012年以及之前的頂級跟蹤算法,並包含50個不同場景的視頻,涵蓋了遮擋、光照變化與尺度變化等情況。到2015年OTB數據集進行進一步擴充並且新增許多幀數較多的長視頻,適合持續對算法的跟蹤性能進行測試。但是OTB-2015包含25%的灰度視頻序列。
VOT數據庫以競賽為主,與ImageNet相似,VOT-2016維護60個彩色視頻序列。並且VOT評價標准與OTB不同,VOT-2016以短視頻為主,並且每一幀都是精細標注,以第一幀初始化算法運行,在跟蹤失敗時,會運行平台給出的目標檢測算法檢測出目標物體再次運行算法。OTB-2015從隨機幀開始,或矩形框加隨機干擾來初始化跟蹤算法,更加符合實際情況。具體評價指標有如下:
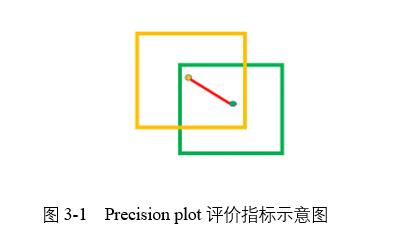
(1) Precision plot:算法估計的目標位置中心點與人工標注的目標中心點,當兩者的距離小於給定閾值,計數器加一,最后統計百分比。不同的閾值,得到的百分比不一樣,因此可以獲得一條曲線。黃色代表算法估計目標位置,綠色代表人工標注目標位置,黃色中心與綠色中心的距離為紅色線,根據距離大小表示跟蹤效果。
(2) Success Plot:算法估計的目標位置記為a,人工標注的目標位置記為b,重合比例記為:
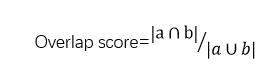
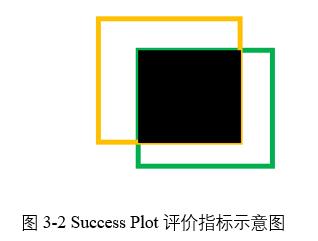
(3) 標志重疊像素比例,設定一個閾值,當像素重疊比例高於閾值,計數器加一,統計計數器佔總視頻幀數的比例,根據不同閾值,可以畫出一條曲線。黃色代表算法估計目標位置,綠色代表人工標注目標位置,黑色區域代表兩者之間的重疊部分,根據重疊比例大小表示跟蹤效果。
(4) TRE: 在一個視頻序列中,每個跟蹤算法從不同的幀作為起始幀,進行追蹤,比如分別從第一幀開始進行跟蹤,從第十幀開始進行跟蹤,從第二十幀開始進行跟蹤等,初始化採用對應幀標注的ground-truth,分別求得到平均值。
(5) SRE: 某些算法對初始位置是比較敏感的,採用人工標注的位置進行跟蹤,為評估算法對人工標注位置的敏感程度,將初始框進行輕微平移和尺度縮放,進而評估。
(6) OPER:算法在工作期間,容易出現跟蹤失敗的情況,此時對下一幀目標進行初始化,其余與OPE一致。
(7) 對於VOT benchmark來說,accuracy (A), robustness (R) and expected average overlap (EAO)是VOT的評價指標。一個好的跟蹤算法,要求有較高的A值,較低的R值和較高的EAO值。
(8) OPE評價方法包括Precision plot和Success Plot,是比較簡單直觀的兩種評價方式,但存在對初始位置比較敏感和沒有重新初始化機制的問題。TRE評價指標通過設置不同起始幀完成對算法是否對初始位置敏感的考察,SRE評價指標通過將初始框進行平移和縮放考察是否對初始位置敏感。當算法出現跟蹤失敗的情況下,OPER評價指標在下一幀重新初始化再跟蹤,解決了算法失敗的問題的考察。我們將基於特征融合的跟蹤算法在相應數據集上進行畢竟和測評。
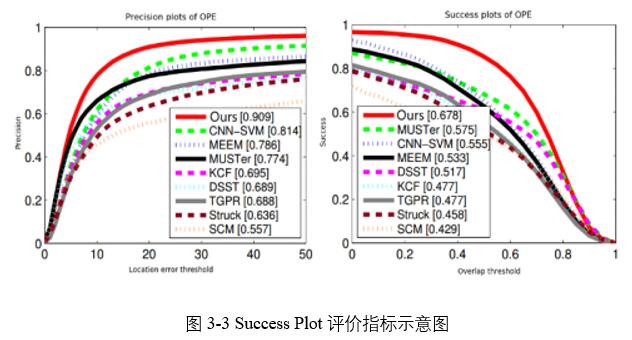
在OTB-2015平台上將這兩種優化方法與其他頂級跟蹤算法的性能作對比,作為補充實驗,實驗結果如圖3-3所示。
4.1系統整體設計與實現
基於系統需求和功能分析的結果,系統應當包括五個主要模塊,分別為:前端交互模塊、中央控制模塊、物體檢測模塊、目標跟蹤模塊和系統復位模塊。
整體的系統功能模塊圖及數據流動如圖4.1所示。
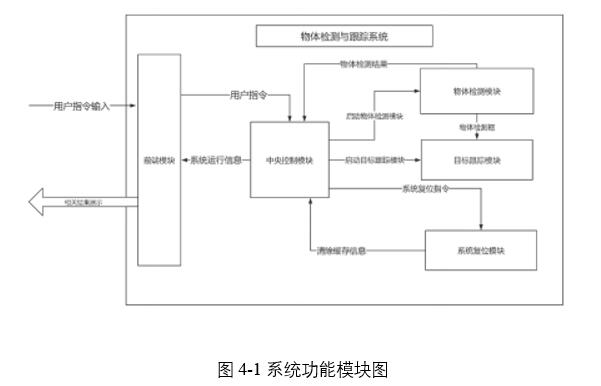
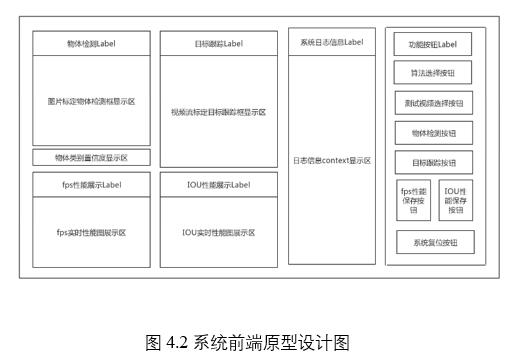
前端模塊用於實時地接受用戶指令並展示物體檢測和目標跟蹤過程的狀態和性能信息,為用戶留出交互接口,具有良好的人機交互性和邏輯正確性,用戶指令轉發給中央控制模塊。前端原型設計圖如圖4-2所示。採用功能按鈕區和展示功能區分別集中布置的布局思路,保証界面的簡潔美觀。
中央控制模塊用於根據前端發回的指令控制系統運行和停止,並實時性的分析系統當前運行的性能、記錄和保存相關數據結果用於算法和系統性能測試。物體檢測模塊用於檢測視頻幀當中出現的物體並給出檢測框位置、物體分類信息以及置信率,並將相關信息交付給目標檢測模塊。目標檢測模塊中嵌入基於檢測的多種跟蹤算法,將檢測算法結果作為輸入,在視頻幀流不斷前進的過程中實現實時的跟蹤,並將跟蹤的情況在反饋給中央控制模塊,最終將圖片跟蹤結果和系統跟蹤性能數據展示在前端界面。系統復位模塊能夠清除系統運行過程中產生的垃圾數據,保障相鄰兩次系統運行流程間互不干擾。
如圖4-3所示點擊執行初幀檢測,經過運算展示初幀圖像中物體檢測框位置和物體類別信息。

如圖4-4所示,點擊執行跟蹤按鈕,系統開始運行跟蹤算法,跟蹤框漂移情況和算法fps、IOU性能分別給予不同形式的展示。
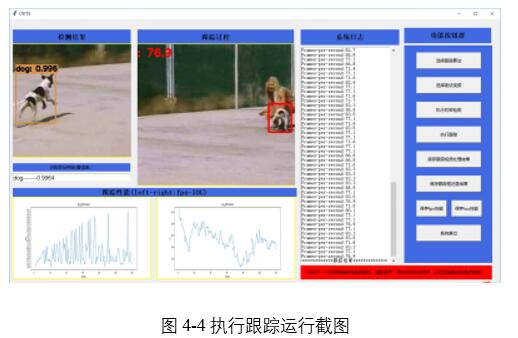
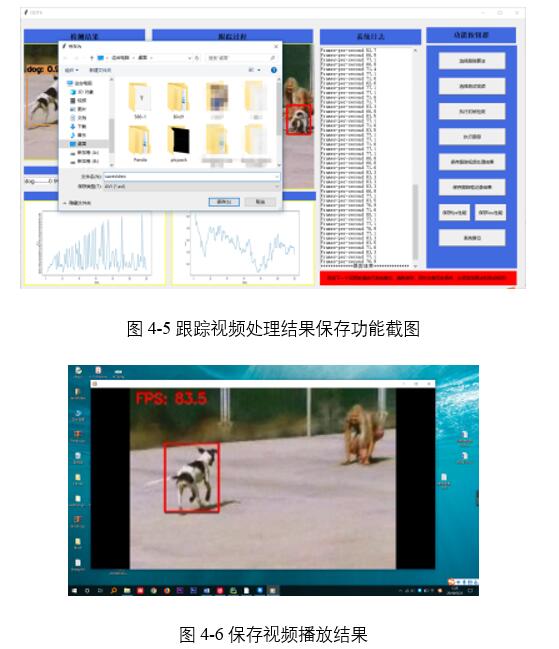
如圖4-5所示,點擊保存跟蹤視頻處理結果,彈出對話框,用戶選擇處理視頻文件保存位置。視頻自動保存。如圖4-6所示是保存的視頻播放結果。
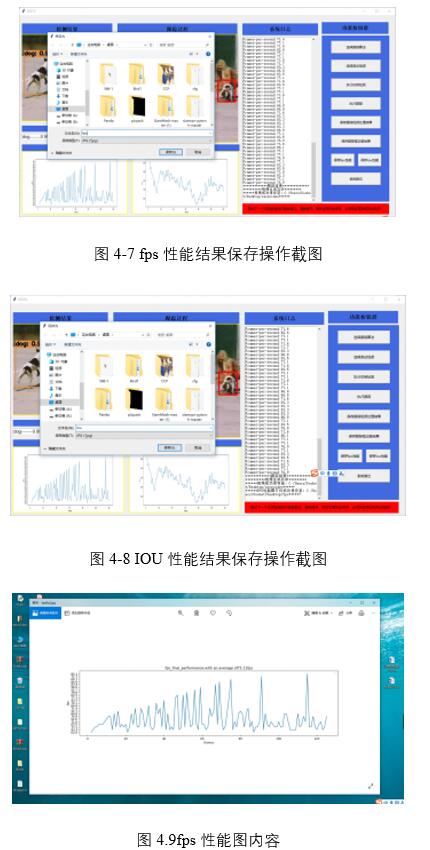
如圖4-7和圖4-8所示分別是保存fps和IOU性能結果在系統中運行的操作截圖。圖4-9和圖4-10分別是保存的fps和IOU性能結果圖內容。
5.1結論
本課題實現了廣泛調研了物體檢測、目標跟蹤和系統構建的算法和理論。首先對目前性能較好的基於深度學習框架的MDNet算法進行改進,主要是融合多層特征以及自適應框的改進,將改進算法在OTB等多個數據集上進行了測試並取得了較好的效果。基於算法完成了基於深度特征的物體檢測和目標跟蹤系統,系統集物體檢測與分類、目標實時性跟蹤、算法性能與系統性能檢測評估、相關數據保存等功能。系統是分模塊實現的,其中物體檢測模塊主要是基於YOLOv3實現,目標跟蹤模塊嵌入了改進的MDNet算法,可供用戶自行選擇對比。總體來說,系統交互邏輯可靠、人機交互性尚可、功能復雜而完備。
分享讓更多人看到 
推薦閱讀
傳媒推薦
 @媒體人,新聞報道別任性
@媒體人,新聞報道別任性 網站運營者 這些"紅線"不能踩!
網站運營者 這些"紅線"不能踩! 一圖縱覽中國網絡視聽行業
一圖縱覽中國網絡視聽行業
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
