




















基於動賓短語和主題模型的相似缺陷報告識別方法
摘要:近年來,隨著軟件技術的蓬勃發展,軟件系統及開發團隊的規模也隨之迅速增長。若能識別出與新的待修復缺陷報告相似的缺陷報告集合,則對修復缺陷的方法以及修復者指派具有指導性意見﹔識別相似的代碼文件對修復相似的缺陷也有著重要意義,另外對於大型的軟件項目,從投入使用到維護階段,其歷史缺陷報告及歷史代碼文件也會越來越多,其中可用的信息也會越來越多。
本文提出一種基於動賓短語和主題模型的相似缺陷報告識別方法。除了利用通常使用的向量空間模型方法表示文本信息外,通過句法分析提取缺陷報告的結構化信息作為衡量報告間相似度的重要依據。
關鍵字:相似缺陷﹔缺陷報告﹔句法分析
0 引言
隨著軟件系統的發展,代碼數量與日俱增,系統規模及開發人員數量也隨之增加。因此,在軟件開發及測試的過程中,開發人員會得到大量的缺陷報告。這些缺陷報告中,也會存在更多的重復或相似的缺陷報告。當開發人員處理這樣的缺陷報告時,必然會降低其工作效率,甚至引入一些不必要的錯誤﹔而相似的缺陷報告往往可通過相同或相似的方法予以解決,因此,相似缺陷報告的出現從某種程度上可為開發人員處理新的待修復缺陷報告提供部分解決思路和方法。
1 背景
缺陷報告中的缺陷信息是用自然語言描述的,因此,需要將缺陷報告中的摘要及描述等文字信息轉換成計算機能夠識別的信息。目前使用最廣泛且較適合於提取缺陷報告文本信息的方法是G Salton等人提出的向量空間模型(VSM:Vector Space Model),且目前較為流行也是效果較好的兩種表示方式為TF-IDF以及word2vec兩種方法,這兩種方法也廣泛用於很多其他的自然語言處理的問題上,並取得了較好效果[1,2,3]。
但僅依據以上兩種方法構建的向量空間模型僅是將缺陷報告中的文本轉化為向量,而沒有考慮到結構化信息以及語序對向量模型的影響。若要對缺陷報告文本進行客觀、准確的相似度評價,還要參考實驗文本中語句的詞序、語句結構、文本結構等因素對實驗結果的影響。
因此,本文結合缺陷報告的文本特點,在計算詞匯間相似度的基礎上加入文本的結構化信息從而構建出每份缺陷報告的特征向量,之后將三部分特征向量拼接在一起得到用來表征每份缺陷報告的特征向量,最后使用目前常用的幾種機器學習分類算法對缺陷報告集合分類。該部分相似缺陷報告提取方法如圖所示。
得到每份缺陷報告的特征向量后,可以基於每個特征向量間的歐氏距離、皮爾森相關系數、余弦相似度等方法衡量其相似度。

2 基於白名單的特征向量構建
本文採用的數據集均為基於Java語言的軟件工程及項目,而每種高級程序語言均由其獨有的詞匯表示。這些詞匯在不同類型的缺陷報告中出現的頻率不盡相同,也就是說,在某種類型的缺陷報告集合中某個詞或某幾個詞出現的概率較大、次數較多,而其他詞語出現的概率較小、次數較少。因此,每一份缺陷報告都可以基於其文本中特定的某些詞出現的頻率分布預測該缺陷報告的類別。
本文基於Java語言的特點,預先找出其相關的專業詞匯列表(即白名單),對每一份缺陷報告統計列表中詞語在該缺陷報告的摘要及描述信息中出現的次數,即用one-hot的形式對每一份缺陷報告統計某些詞出現的次數以構建該部分特征向量。
另外,由於每份缺陷報告中文本的長度不同,每個文本中包含的詞匯量有時差異會很大,因此每個詞出現的次數差別較大,為避免該因素對實驗結果的影響,對每份缺陷報告得到的特征向量均作歸一化處理。也就是說,特征向量的每一維都轉化為表示該詞匯在該缺陷報告中的頻率,即該詞在這份缺陷報告中的重要程度,這其實更符合本文要求。
3 基於結構化信息的特征向量構建
對於每一份缺陷報告,並不是文本中的每一個詞語對文本來說都非常重要,如果將這些詞也考慮進去勢必會影響預測結果的准確性。因此,需要利用某種方法提取出文本中最重要的那些詞語。
在本文使用的數據集中,缺陷報告均由英文書寫。基於英文特殊的表述方式,可以觀察到,當用戶或測試人員編寫缺陷報告時,需要依托於動賓短語的表述形式描述軟件的缺陷現象以及該缺陷的重現方法等等。因此,本文對每份缺陷報告的摘要及描述信息文本句法分析並提取其中的動賓短語,找到該缺陷報告文本中最能表征缺陷內容的文本片段,再基於這些文本片段構建其對應的特征向量。
3.1句法分析
句法分析(parsing)是指對文本中語句的詞語進行語法功能分析。句法分析在自然語言處理(natural language processing,NLP)領域中佔有重要地位,是其關鍵底層技術之一,其主要應用是確定文本中語句的句法結構以及語句中每個詞匯間的依存關系。
針對本文中的缺陷報告,需要提取其中的動賓短語結構,因此,本文對相應的缺陷報告文本使用句法結構分析。本文使用斯坦福自然語言句法解析器(Stanford NLP Parser)對自然語言語句進行句法分析,建立句法結構樹。該解析器基於一個經過訓練優化的概率上下文無關文法(PCFG)對語句的句法樹進行分析構造。
圖2分別為缺陷報告(編號239120)描述信息中的語句“I will take a look at this today. Can you tell me what version of AspectJ you are on, is it the release candidate for 1.6.1rc1?”的句法結構示意圖。
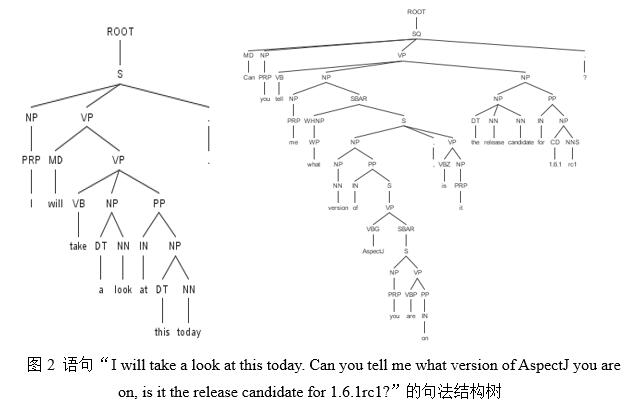
其中,常見標注信息有: S:完整語句﹔VP:動詞性短語﹔VB.*:不同形式的動詞(VB.*表示以 VB 開頭的所有標注信息)﹔NP:名詞性短語等。句法結構樹中動賓短語被標注為VP,因此,需要提取出句法結構樹中所有標注為VP的文本片段。

3.2啟發式過濾規則
僅僅依靠句法分析中提取出來的動賓短語(VP)文本片段,其中還會保留一部分無關信息。有些動賓短語文本片段由於代詞、虛詞等成分的詞語出現等原因導致該文本片段信息不完整或與該缺陷的實際信息有些偏差。因此,還需要將這種文本片段過濾掉。
本文基於一種啟發式規則對篩選出來的候選動賓短語進行過濾[4]。設定某一閾值,並保留通過該啟發式規則過濾器后高於該閾值的候選動賓短語。即預先設定一組啟發式規則,並對句法分析得到的所有動賓短語文本片段進行篩選。當某個動賓短語片段匹配到某一條規則時,若符合該條規則,則加上既定的分數,同理若不符合該條規則,則減掉既定的分數。當通過所有的啟發式規則后,過濾掉所有得分低於閾值的候選動賓短語片段,既而得到缺陷特征的候選集合。本文在[4]的基礎上綜合考慮缺陷報告文本的特點,最終選取了兩類啟發式規則:基於短語結構特征的過濾規則,以及基於停止詞的過濾規則。
(a)基於短語結構特征的過濾規則
在動賓短語中,如果不包含動詞(VB.*)或名詞(NP)成分,則將其判定為無效的動賓短語,即為保証該動賓短語描述信息的完整性,候選動賓短語中必須包含動詞成分及名詞成分。因此,在動賓短語的句法結構樹中,如果某一棵子樹的根節點第一層中不包含動詞成分(VB.*)或名詞成分(NP),則將其判定為無效的動賓短語結構,並將該短語的置信度評分設為最低分,結束過濾過程。
(b)基於停用詞的過濾規則
在自然語言處理領域,文本預處理中有一種常見操作是刪除停用詞。停用詞是由英文單詞stop words翻譯過來的。英文中有很多使用頻率很高的單詞(如a、the、或or)對文本的語義理解並沒有幫助,這些單詞的存在反而影響計算的效率和准確性,因此通常在處理文本前,會先將文本中的停止詞刪除掉。
同理,對於缺陷報告的文本集合,有些詞在文本的某些位置上也不應該出現,也就是說候選動賓短語中的某些詞不應該出現在某些位置上。因此,可以針對缺陷報告集合設定專用的停用詞表,當某個候選動賓短語中出現這些停用詞時,直接將其移除候選動賓短語集合或減掉一定的分數。本文選用了兩種停用詞:
助動詞(例如be、do、have等)和情態動詞(例如can、may、must等)作為句子的基本組成結構,經常出現在動賓短語中,但由於英文特殊的語法結構,當助動詞或情態動詞出現時,並不是在准確描述該缺陷報告想要描述的缺陷特征。因此,應設定一定規則減少助動詞及情態動詞對缺陷描述結果的影響。具體規則如下:
1)當助動詞或情態動詞出現在候選動賓短語的動詞位置時,將該短語的置信度評分設為最低分,直接結束過濾過程﹔
2)當助動詞或情態動詞出現在候選動賓短語的其他位置時,將該短語的置信度評分減1。
當代詞(例如it、me等)出現在候選動賓短語中時,代詞在某一單一語句中會因指代不明而使得表達的語意不准確或不完整,因此,應將其作為負面規則減掉一定分數或直接判定為無效的候選動賓短語。另外,若某個代詞帶有一定的實際意義,其指代的詞語也通常在上文出現過,因此,過濾掉該代詞所在的候選動賓短語不會影響候選動賓短語集合表述缺陷語義的完整性。具體規則如下:
1)當代詞出現在候選動賓短語的名詞位置,並且是最后的核心名詞時,將該短語的置信度評分設為最低分,直接結束過濾過程﹔
2)當代詞出現在候選動賓短語的名詞位置,但不是核心名詞時,將該短語的置信度評分減2﹔
3)當代詞出現在候選動賓短語的其他位置時,將該短語的置信度評分減1。
上述語句“I will take a look at this today. Can you tell me what version of AspectJ you are on, is it the release candidate for 1.6.1rc1?”依上述規則篩選后得到兩個文本片段,分別為“take a look”以及“release candidate for 1.6.1”。當對該缺陷報告中的所有文本信息提取候選動賓短語並依據以上的啟發式規則過濾后,則會得到表述該缺陷報告語義的所有候選動賓短語。
3.3領域術語自動抽取
過濾每份缺陷報告的候選動賓短語集合,得到表征的文本片段后,還需建立每份缺陷報告與類別之間的聯系。
在自然語言處理領域,自動抽取語料庫中各領域對應的領域術語是其中的一項重要任務。領域術語自動抽取是指從一定規模的語料庫中提取出能夠表示該語料庫中各領域文本特征的詞語。目前,針對領域術語的自動抽取已有大量的研究,這些研究大多採用基於統計或基於規則的方法。
本文借鑒Liu等人提供的方法[5],該方法基於以下的假定:
1)不同領域的術語在不同領域的文本中分布應該是不均勻的﹔
2)相同領域的術語在與其相關領域的文本內應該是均勻分布的。
在給定了分類語料中每個領域的前提下,該算法既考慮了每個領域術語在不同領域文本集合中分布的不均勻性,以及在某些領域文本集合內分布的均勻性。而如果在某個領域內,其語料越多, 則某個詞語在該類語料中出現的可能性會越大。因此,該算法使用正規化方法用以減少語料規模對詞語的出現帶來的影響。算法中的符號定義見表1:

詞語在領域類別間的分布,是利用信息熵來定義的,記作corpus distribution(CD),定義如式(1)所示。
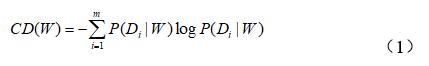
針對語料的不平衡性,對詞語的類間分布進行正規化定義,記作NCD,定義如式(2)所示.
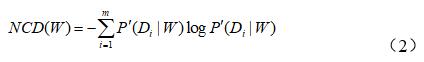
其中:
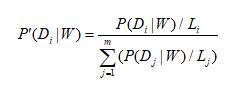
考慮到語料的不平衡性,對詞語的類內分布進行正規化定義,記作NDD,定義式(3)所示。
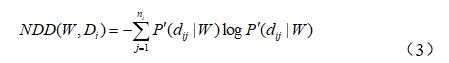
其中
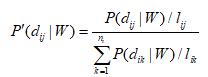
若NCD(W)的值越小,則該文本中的詞語W越有可能成為某個或某幾個類別的表征術語﹔而相反的,若NDD(W,Di)的值越大,則詞語W越有可能成為用於表征某個類別Di的領域術語。也就是說,式(2)是選擇NCD值小的詞語作為候選的領域術語,而式(3)則認為領域術語應該在與其相關領域內盡可能均勻的分布。
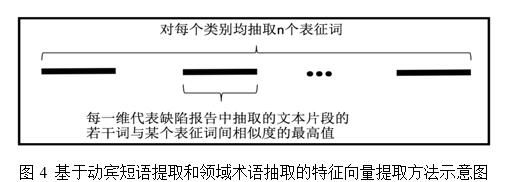
基於以上方法,可得到缺陷報告集合中每個類別的表征詞語,依據NDD值的大小,選擇每個類別排名前20的詞語。因此,在Eclipse項目的5個優先級類別中,共得到100個表征詞語。
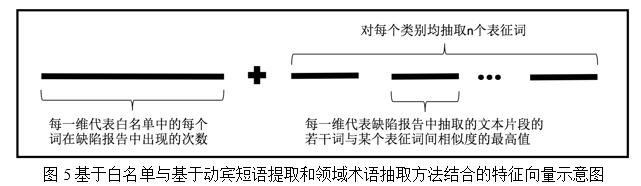
對於每份缺陷報告,分別計算這100個表征詞語與篩選出的候選動賓短語文本片段中的每個詞語的相似度,並取其中的最大值作為特征向量中的某一維,以此得到一個100維的特征向量,如圖4所示。與基於白名單構建特征向量的方法類似,對該部分特征向量值也需做歸一化處理。
因此,將基於白名單方法得到的特征向量與基於動賓短語提取和領域術語的特征向量拼接在一起,如圖5所示。
4 基於LDA主題模型的特征向量構建
主題模型(Topic Model)是一種用於在一組文本集合中查找出抽象主題的統計模型。簡單來說,每個文本都有其中心思想,圍繞著該中心思想一些特定的詞語會更加頻繁的出現。主題模型就是統計這組文本中每個詞語出現的次數,根據統計信息判斷這組文本當中有哪些主題以及每個主題所佔的比重是多少。
LDA主題模型是一種非監督的機器學習算法,主要被用於自動生成文檔主題,特別是對於文本數量很多的文檔數據集合,常用LDA主題模型挖掘數據集中潛在的主題信息。LDA中主題個數的確定是一個比較困難的問題,依經驗一般設置為50到500之間。因此,本文基於以上研究經驗以及第2節和第3節中得到的兩部分特征向量維數,選取100個主題,並將得到的結果與第3節中得到的特征向量(圖5所示)拼接在一起,即完整的特征向量如圖6所示。
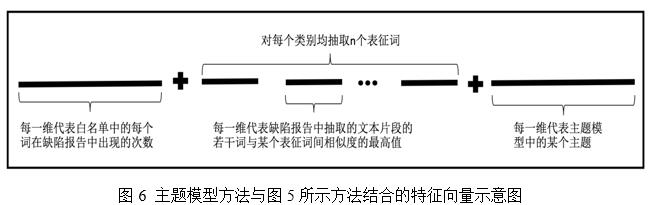
5 基於句法結構的相似缺陷報告識別方法的實驗結果與分析
得到每份缺陷報告的特征向量后,基於目前較為成熟的支持向量機、隨機森林等機器學習分類算法對缺陷報告分類,計算幾種分類算法的准確率並比較幾種算法在缺陷報告集合中的適用性。
本文隨機選取開源項目Eclipse中的5000份缺陷報告作為實驗對象。由於目前沒有完備的缺陷報告分類數據集,而缺陷報告的優先級可以看作對缺陷報告的粗分類,因此選用缺陷報告的優先級評估實驗結果。
得到每份缺陷報告的特征向量后,對每個類別的缺陷報告,隨機選取十分之一,即100份作為測試集,剩余900份缺陷報告作為訓練集,並通過K近鄰、支持向量機、隨機森林、GBDT等機器學習算法實現分類,以探究這幾種分類算法在缺陷報告集合中的實用性。
本文對第3節及第4節提出的方法進行了比較,圖5及圖6分別表示的兩種特征向量提取方法的缺陷報告分類准確率如表1所示。其中第一行為基於白名單方法與基於動賓短語提取和領域術語抽取方法結合(圖5所示)的實驗結果,第二行為白名單方法、基於動賓短語提取和領域術語抽取方法及基於主題模型方法三者結合(圖6所示)的實驗結果。
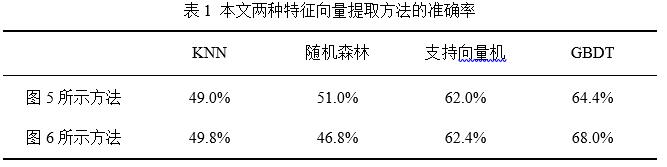
從表1中可以看出,白名單方法、基於動賓短語提取和領域術語抽取方法及基於主題模型方法三者結合的方法(圖6所示)的實驗效果在KNN、支持向量機及GBDT三種分類算法上略有提升,並且GBDT的提升效果較明顯,為3.6%。GBDT作為近年來應用較為廣泛的機器學習算法,在缺陷報告分類方面也有較好的實驗結果。
目前本文在上述幾個模型中均使用默認參數,對實驗結果也有一定影響,還需嘗試找到更合適的模型參數。另外,更多的算法和模型也有待於研究和嘗試。
6 結束語
本文首先介紹了相似缺陷報告集合提取方法的基本流程以及缺陷報告的各部分特征組成。第2節介紹了基於白名單的特征向量構建方法,第3節介紹了基於結構化信息的特征向量構建方法以及基於LDA主題模型的特征向量構建方法,本文將文本信息的結構化信息提取以及基於啟發式規則的文本片段篩選方法應用到缺陷報告文本中,並利用領域術語抽取的方法建立缺陷報告與其類別之間的聯系。
參考文獻
[1] Runeson P, Alexandersson M, Nyholm O. Detection of Duplicate Defect Reports Using Natural Language Processing. Proceedings of 29th International Conference on Software Engineering, 2007, 499-510.
[2] Wang X Y ,Zhang L, Xie T, Anvik J, Sun J. An Approach to Detecting Duplicate Bug Reports Using Natural Language and Execution Information. Proceedings of the 30th International Conference on Software Engineering, 2008, 461-470.
[3] Jalbert N, Weimer W. Automated Duplicate Detection for Bug Tracking System. Proceedings of the International Conference on Dependable Systems and Networks, 2008, 1-10.
[4] 朱子驍,鄒艷珍,華晨彥,沈琦,趙俊峰.基於StackOverflow數據的軟件功能特征挖掘組織方法.軟件學報 ISSN 1000-9825
[5] 劉桃,劉秉權,徐志明,王曉龍.領域術語自動抽取及其在文本分類中的應用.電子學報 2007.
分享讓更多人看到 
推薦閱讀
傳媒推薦
 @媒體人,新聞報道別任性
@媒體人,新聞報道別任性 網站運營者 這些"紅線"不能踩!
網站運營者 這些"紅線"不能踩! 一圖縱覽中國網絡視聽行業
一圖縱覽中國網絡視聽行業
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
