




















基于目标实体的用户生成内容推荐
摘要:目标实体是指属于同一领域的一系列实体,例如所有股票名称和汽车品牌等。本文通过研究对用户生成内容(微博、评论等)中目标实体的排歧问题,实现特定领域用户生成内容的推荐。具体的,我们提出一种图方法TremenRank可以同时对所有文档针对领域进行过滤而不使用额外信息。它的主要思想是利用属于同一领域的目标实体应具有相似的上下文,而领域之外的歧义则不然这一特点,通过将文档表示为一个多层有向图,并在其上进行信任度传播,得到每篇文档属于该领域的信任度,从而确定信任度较高的文档应更可能属于目标领域,推荐给领域关注者。进一步,我们设计使用倒排索引技术优化该方法在大规模数据上的效率。实验表明,与现有算法相比,所提出的TremenRank方法性能具有明显提升,在三个不同领域的数据集上平均提升24.8%的精确度和15.2%的F1值。
关键词:用户生成内容;推荐;实体;排歧;图方法
研究内容和意义
研究背景
近来,越来越多的人们习惯在网上发表他们的观点和评论。这些信息以每天数百万条的速度增长,已经成为不可忽视的潜在信息来源。从这些海量数据中,实体的排歧问题显然是许多应用的关键步骤,比如评论推荐、趋势分析以及知识获取。例如,一个企业显然对自身和竞争者产品的用户评论很感兴趣,但是这些产品的名称常常很有歧义,“阳光”是一个汽车品牌的同时还指太阳光或者积极乐观的生活态度,那么传统的基于关键字的评论抽取显然不能满足要求,因此如何从海量的用户评论中抽出真正讨论这些产品的文档并推荐给领域关注者具有很重要的现实意义。
这些产品名称就构成了一系列需要被识别的实体。我们定义这样的属于同一个领域的一系列实体为目标实体,识别过程即目标实体排歧。所有的目标实体共享同一个领域,我们称之为目标领域。目标领域是对目标实体的唯一限制,这意味着所有的目标实体在一个特定领域中,而不是泛泛的事物。用户生成内容的特点是常常字数受到限制,因此排歧的过程可以在文档的级别而不是词级别。这样,给定若干个至少含有一个目标实体的文档集,我们的目标即是找出哪些文档真正与目标领域相关,从而对感兴趣的用户推荐。即将用户生成内容推荐看作基于目标实体的候选文档在目标领域下的排其问题。
相关工作与挑战
与传统的实体排歧任务相比,用户生成内容的目标实体排歧(TED)通常能够利用的信息更少,甚至仅仅具有实体的名称。论文[1]中认为主要有三类信息可以被命名实体排歧相关任务利用:外部知识源、实体出现的上下文以及统计信息。然而,前两类信息的缺少使得这个问题更为具有挑战性:
知识稀缺:针对命名实体排歧任务,许多方法倾向于使用如Wikipedia和YAGO等外部知识库中实体的相关信息来增加可利用的特征[2],[3],[4],[5],[6],[7],[8](外链和内链等)。这些方法通常通过比较实体在文档中出现的上下文和知识库中的认证页面的相似度来决定实体的实际指代对象。然而,我们测试了32个通用汽车品牌名称,只有4个出现在Wikipedia中。这并不是例外。在另一个具有2468个股票名称的数据集上,我们只能找到360个认证页面。因此,这些依靠外部知识库的方法并不适用。
文本短小:显然,实体在文本中的上下文信息在排歧任务中具有重要意义。论文[9],[10]利用潜在的话题连贯性信息去进行实体连接任务;在论文[11]中,mentionRank也使用了一些额外的特征如多个实体的共同提及信息加强排歧效果。然而,用户生成内容通常很简短,即并不足以提供这些特征。我们统计了分别摘自新浪微博、Twitter和Google搜索结果的350,498条微博、37,379 tweet和34,018描述(包含中英文),经过预处理之后的平均长度是16,5和11个词。为了减轻短文本的问题,研究者使用了额外的信息扩充上下文,如用户兴趣[12],以及相关文档[13]。不幸的是,这类信息依旧很难在日常的应用中获得,所以以上的方法并不能取得很好的效果。
数据量大:社交平台是抽取用户生成内容的重要来源,据统计Twitter每天更新数以百万计的微博[14]。随着数据量的增大,实体的歧义程度也随之增加,即排歧任务更为重要[15]。MentionRank11是TED当前唯一的前沿方法,它只能同时处理几十个实体和几千篇文档。然而,随着文档数量的增加,它们的关系图规模呈二次方增长,这就限制了该方法的使用环境。在我们的实验中,金融领域的数据集包含2,468个目标实体和35万篇文档,由此生成的关系图具有数十亿条边,单单存储这张图(即使使用稀疏矩阵技术),就对机器的性能提出了挑战。因此,方法的扩展性仍然需要考虑。
研究内容
为了解决以上问题,本文提出了一种创新的图方法可以同时对所有目标实体排歧,称为TremenRank。通过观察大量的文本,我们发现目标实体在目标领域的文档中上下文是相似的,而其歧义属于不同的领域,故具有不同的上下文信息。利用这一属性,我们首先将文档及其之间的相似度关系表示为图,然后在图上做信任度传播,信任度越高的文档更可能属于目标领域。特别的,我们结合倒排索引技术和Jaccard相似度度量局部的建立文档关系图,从而TremenRank可以处理任意数量的目标实体和文档。最后,我们结合特定领域的特点,设计了多层有向图。该图中不同的文档具有不同的信任等级,从而大大提升了TremenRank性能。本文的贡献主要有以下几点:
提出了一个创新的图方法可以利用文档间共同的信息对所有目标实体进行排歧,叫做TremenRank。该方法可以局部的构造文档相似度关系图从而避免存储整张图在内存中,使得在处理目标实体和文档的规模上具有线性扩展能力。
设计了多层有向图对不同文档建模不同的信任等级,该方法大大提高了模型的性能。
构造了三个不同领域的数据集进行实验。结果表明TremenRank与前沿方法MentionRank具有相似的性能,但是可以处理更大规模的数据,并且多层有向图的使用大大提升了模型的性能。
问题定义
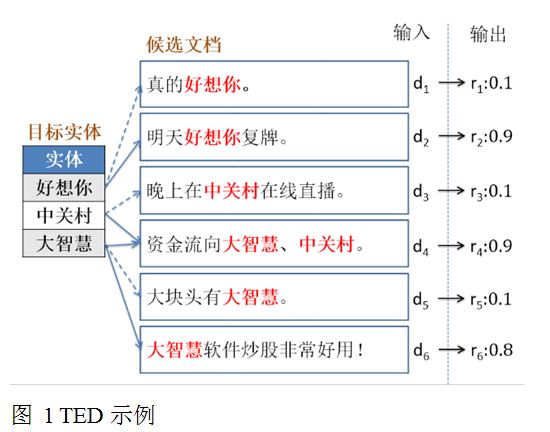
例子:假设某一证券公司想收集关于沪深股市股票的微博。如图 1所示,我们以(i)一列股票名称(目标实体),及(ii)一系列微博(候选文档)集作为输入。“股票”即为目标领域,股票“好想你”出现在d1和d2中,我们称这两个文档为候选文档,其中d1显然不属于目标领域,叫做假提及;d2属于目标领域,称为真提及。
TremenRank对所有文档建模,构造文档相似度关系图,然后通过信任度传播为每篇文档输出一个信任值。信任值指示了该文档含有一个真提及的可能性。另外,信任值在0和1之间,并且是全局可比的。这样我们可以通过选取合适的阈值平衡准确率和召回率。
正式的,目标实体排歧问题可以被定义如下:给定一列目标实体E={e_i |i=1,…,m},以及它们的候选文档D={d_i |i=1,…,n},E^(d_j )={e_1^j,…,e_k^j}是包含在文档d_i中的目标实体。目标是为每篇文档d_j∈D输出一个信任值r_j∈[0,1]。所有在E^(d_j )中的目标实体共享同一信任值r_j。
候选文档中的所有提及具有相同的信任值是因为它们具有相同的上下文。这种假设也很合理,这是因为此处考虑的文档为用户生成内容,通常字数受到限制,而在这么短的文字里,用户基本上不会改变谈论的话题。事实上,当几个目标实体同时出现在一个文档中,该文档包含真提及的概率更大(如d4)。
TremenRank
TremenRank是一个可以利用所有目标实体信息的图方法。图中每个顶点代表一个文档,每条边代表文档之间的相似度关系。考虑到数据量大的问题,我们通过查询两个倒排索引表局部的获得一个顶点的所有邻居节点,这就避免了存储整个图在内存中,从而可以处理任意多的文档和目标实体。进一步,我们设计了一种多层有向图,通过将为不同文档分配不同的信任等级大大提高了模型的性能。
假设
真提及属于同一个目标领域,因此具有相似的上下文信息。而假提及由于分属不同领域,故它们之间的上下文文本各不相同。我们观察了2468个股票名称并手工标注301个,统计结果如图 2所示: 除了股票,它们分别还代表科技、食物、地点及房屋等。
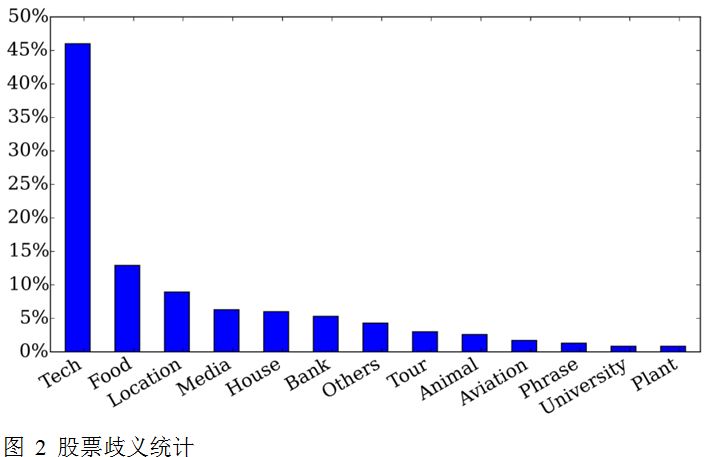
由以上统计结果,我们可做如下假设:
真提及的上下文文本均相似;
假提及的上下文文本与任何真提及均不相似;
假提及之间的上下文文本互不相似。
通过以上假设可以得出,利用文档集的共同信息应该比单独进行排歧取得更好的效果,这是因为对于每个目标实体使用来自多个“协同者”的更为广泛的信息[16],5,[17],[18],[19],[20],[21],[22],[23],[24]。
图方法
基于以上假设,我们构架一个文档相似关系图表示文档及之间的关系,并且在图上使用类似Trust Rank算法。假设给定一个图G=(V,E),其中V为N篇文档集合,E为有向边集合,每条有向边(d_i,d_j)∈E代表文档/节点d_i指向d_j,并且o(d_i )={d_j |(d_i,d_j)∈E}定义为d_i的指向邻居节点集合。
相似度度量
我们根据文档的相似度构造边,事实上,大多数相似度度量[25],[26]都可以使用在这里。经过我们反复尝试,Jaccard相似度度量取得更好的效果。它可以经过简单的集合操作进行计算:


倒排索引
本文使用两种倒排索引表:文档-词表和词-文档表。前者记录每个文档的单词集合,后者记录每个词出现过文档D^(w_k )={d_j |w_k∈W},其中W={w_1,…,w_N}为文档集的词表。结合这两种索引表,一篇文档所有指向邻居可以在常数内获得:
通过检索第一个索引表,获得文档d_i的所有词W^(d_i );
查找W^(d_i )中每个词在第二个索引表中文档集合,构成新的文档集合D^(d_i )={d_j |∪_(w_t∈W^(d_i ) ) D^(w_t )}。每个d_j∈D^(d_i )至少与d_i有一个相同词;
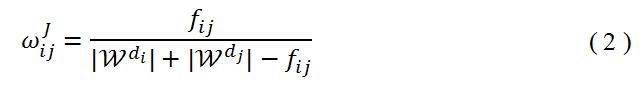
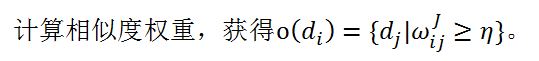
信任度传播
因此最终的信任值由两部分构成:来自邻居信任以及自身的先验估计。那么,TremenRank按照如下规则迭代更新:
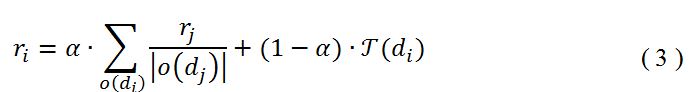
其中T(d_i)是文档d_i的先验估计,在迭代过程中保持不变。这里我们首先简单的假设其服从均匀分布,在后面会进行进一步讨论。
在传播开始时,我们为所有文档初始化先验估计作为其信任值。然后这些信任值迭代更新直至收敛[1]。具体地,真提及更可能与更多的信任值高的文档连接,因此通过公式( 3 )中的第一项收到更多的信任度;而假提及因为与多数文档均不相同,通过第二项逐步衰减其信任值。
多层有向图
在传播中,所有文档被初始化为相同的信任值并且具有相同的衰减速度。然而,不同的文档应该被不同对待。例如,“我驾驶一辆小型阳光轿车”由于具有明显的领域文本特征“车”,显然应该比“今天阳光很明媚”更加值得信任。在本小节中,主要如何利用目标实体的领域特征做出更精确的先验估计。更进一步的,在此基础之上,引入多层有向图(MLD)为文档分配不同信任等级。
先验估计
理想情况下,真提及只与真提及相似。为了利用这一同质性,首先抽取一些真提及用来启动传播。包含这些真提及的候选文档被称为种子。
正式地,整个文档集D被划分为两组:(i)种子集D^s={d_1,…,d_s},和(ii)剩余子集D^*={d_(s+1),…,d_n}。使用以下分布为每个分档分配先验估计:
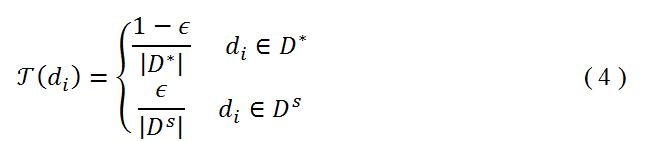
其中|D^* |,|D^s |是两个集合的大小,用来正规化。?∈(0,1]是平滑系数,取值为抽取种子文档集准确率和召回率的加权平均。
有许多方法可以预先抽取种子节点,比如手工标注和基于模板的方法。手工标注准确率高,但是需要耗费大量的人力,而且种子集的大小也常常受到限制。所以这里我们采用基于模板的方法。模板可以是简单的目标领域特征,比如领域名称、产品型号或者产品id。唯一要注意的是模板的歧义性要求越低越好。选取好的模板后,通常可以达到很高的准确率,但是召回率很低。事实上,我们的方法可以看作以这些种子为基础,通过共同性的方法在损失一定准确率的代价下,尽可能的提高召回率。
图的构建
相似度度量并不考虑方向,因而此时的文档关系图相当于双向图。本小结着重介绍如何在关系图中构建不同的层次,每个层次代笔不同的信任等级。这样,传播方向总是从信任度高的等级到低的等级。
图 3是MLD图的一个示例。在顶层的蓝色顶点是信任度最高的种子,白色节点代表的文档与种子越相似就安排在越高的信任等级上。也就是说,随着我们远离种子,信任值逐层递减。注意,同层之间的节点也可能相互连接。
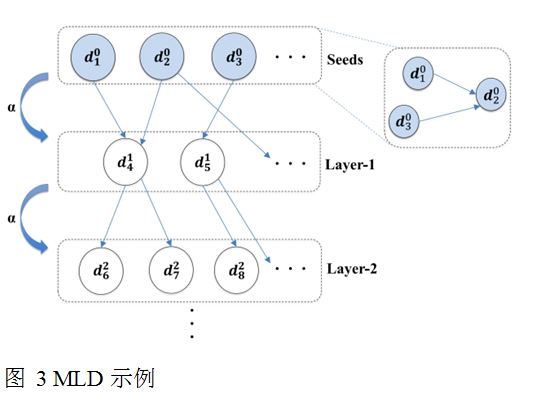
MLD的构建也很简单,如算法 1所示:

其中D^l={d_i^l |l≥0}是第l层节点的集合,D ?={(d_j ) ?|(d_j ) ??D^l,l≥0}。为方便起见,默认种子在第0层。注意(?_(l≥0) D^l )?D ?=D。
TremenRank与标准的Trust Rank及MentionRank在多个方便均有不同。第一,TremenRank针对大规模的短文本进行排歧推荐。第二,MLD图的使用增加了文档的层次性,使其不在是单一的均匀分布,而是在传播中具有不同的信任等级。第三,Trust Rank抽取种子时,使用的方法是随机抽取后手工标注,这大大限制了种子的数量,稍后的实验会证明种子的规模对模型效果的影响至关重要,而TemenRank自动抽取种子,并且通过平滑系数增加了对种子质量的鲁棒性。最后,TremenRank在文档级别上排歧,只判断该文档是否属于目标领域,并将该文档推荐给领域关注者。
实验
数据集
由于没有标准数据集,所以我们构造了分属三个不同领域的数据集:股票、汽车以及中药。所有的数据集都来自实际的项目需求:
股票:从上海及深圳证券交易所收集了2468个股票名称,并且通过关键字搜索新浪微博的结果作为候选文档。每个股票对应一个独一无二的六位数字id,实验中使用该模板作为正则表达式抽取种子;
汽车:从通用汽车官网上收集了32个旗下汽车品牌,并且通过API获得关于它们在Twitter的候选文档,该数据集为英文数据集。在种子抽取阶段,我们使用目标领域名称“车”作为模板。
中药:随机选择1119个中草药名称,作为关键字在Google进行搜索,将每个中药名称的搜索结果中前40个简要描述作为候选文档。其中,文档中含有目标领域名称“中药”的作为种子。
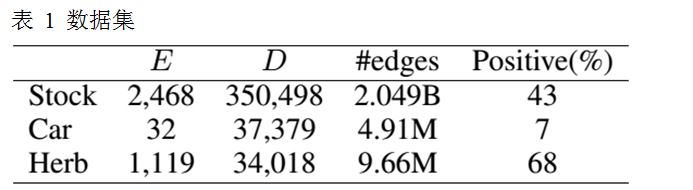
表 1展示了数据集的统计信息。在实验前,我们首先进行了必要的预处理:分词、停用词及低频词过滤。
对比方法
因为TED是个比较新的问题,所以很少有专门针对它的算法。为了验证TremenRank的有效性以及MLD图带来的提升效果,我们从以下三个方面选择对比方法:
基于上下文的方法:挖掘真提及上下文中的频繁项,使用频繁项做特征,识别包含真提及的候选文档;
支持向量机(SVM):将候选文档分为是否属于目标领域两类。实验中使用上下文单词作为特征,在标注集上进行训练和10折的交叉验证;
MentionRank:一种对提及进行排歧的图方法。由于很难应用在整个数据集上,我们将其运行在小一些的标注集上。
结果与分析
全部结果如表 2所示,由此我们可以看出:
TremenRank+MLD的效果比所有其他对比方法好,这是因为它不仅利用了文档间的信息,而且以更加准确的先验估计为基础,在传播中为每个文档分配了更加精确的信任等级。
利用文档间信息的方法普遍比文档独立排歧的方法效果好。虽然在汽车领域的数据集中,SVM取得了仅次于TremenRank+MLD的F-score,这是因为如表 1中所示,该数据集中假提及占据了很大的比例,即为传播增加了太多的噪音,影响了传播的准确率。相反,有监督或者基于种子的方法可以大大降低噪音的影响,从而取得更优异的成绩。
对比MentionRank,TremenRank在更大的数据集上取得了相似的效果。并且在结合了MLD图之后,平均提升了24.8%的精确率和15.2%的召回率。
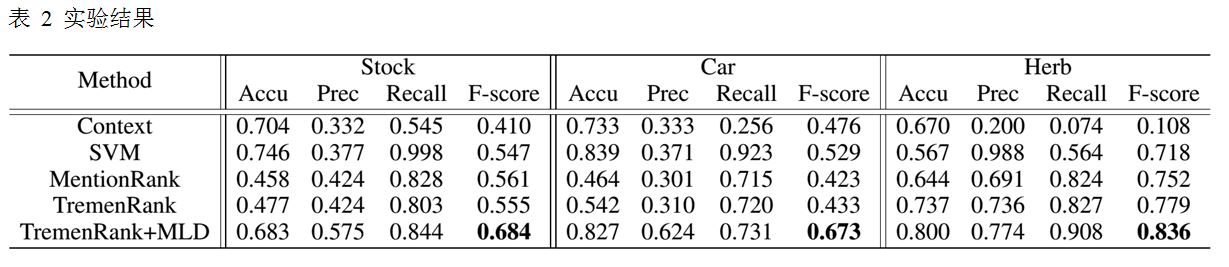
种子规模的影响
作为先验估计的基础,种子无疑对最终的性能有很重要的影响。在实验中,我们将种子集均分成十份,每次增加一份并重新计算模型的效果。结果如图 4所示,随着种子数量的增加,模型的效果也成上升趋势,直至趋于平稳。这是因为随着种子的增加,传播中可以利用的潜在种子文本特征也得到了增加,但是当到达某一规模后,文本特征基本已覆盖领域的各个方面,模型效果不在得到提升。例如,“Cadilac Uber airport is classy”在使用50%种子是仅仅得到了0.013[2]的信任值,但是当使用全部种子时,它的信任值提升到了0.588,这是因为类似“Uber”和“airport”的不明显文本特征随着种子的增加而被引入。因此,种子的增加可以提高模型的效果,这对公司的分析极为有用,因为鲜有公司更改其商业领域,所以可以不断地提高种子的规模,从而提升模型的效果。
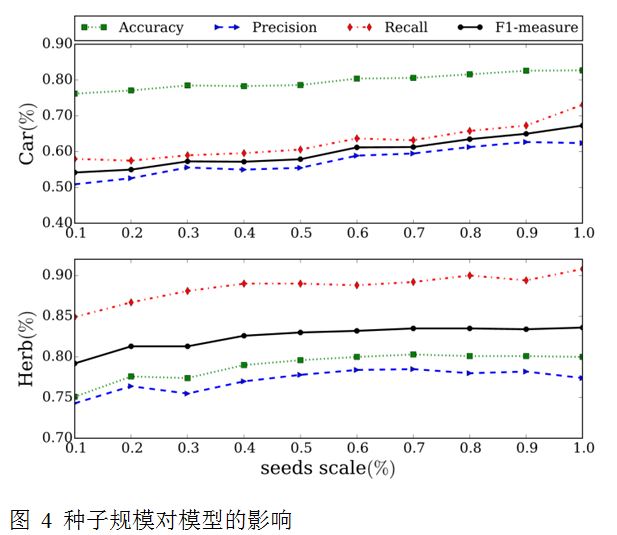
种子质量的影响
实验中在种子集外随机采样种子集规模的20%的候选文档作为噪音替换相应数量的种子。注意候选文档也可能包含真提及,故我们将噪音比例提高到20%,而不是模拟基于模板的抽取方法的准确率10%。
实验结果如图 5所示。噪音的引入只带来了有限的性能的下降,这种下降是可以接受的,并且增加噪音之后的模型效果仍要远远高于只使用TremenRank方法的效果。注意,人工噪音的引入偶尔会带来召回率的上升(股票数据集),这也是因为未知的真提及随着噪音增加到了种子集,从而变相扩大了种子的规模。
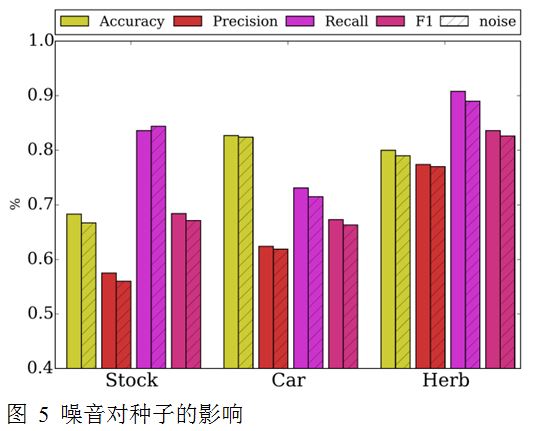
阈值的选取
经过排歧之后,每篇候选文档都有一个信任值,根据这些信任值,我们可以将所有目标实体的候选文档按照其信任值的高低进行排序。也可以对每个目标实体的所有候选文档单独排序。然后通过选择不同的阈值,可以满足不同的推荐需求。比如如图 6所示,在阈值取30%时,可以得到高于90%的准确的推荐结果;或者取60%的阈值,在准确率可以接受的情况下(80%+),得到更多的该领域的推荐文档。
模型效率
文中实验使用Java进行编程,运行在Windows8.1 64bit的个人电脑上。该电脑的核心硬件配置为Intel? Core? i3-3240(3.40GHz) CPU 和4GB的内存。TremenRank+MLD在5次迭代后基本收敛,运行时间分别为12小时、5分钟和8分钟。由此可见效率随着数据规模呈指数级增长,这是因为在查倒排索引表时花费了很多的冗余时间,在未来的工作中可以进行优化。
总结与展望
本文主要考虑用户生成内容推荐问题,该问题可以转化为基于目标实体的排歧问题。这个问题比较新颖,当前的研究还不多,但是在社交平台飞速发展的今天,显然具有越来越重要的研究意义。针对这个问题,我们提出了一个创新的图方法,它只使用目标实体名称本身,利用其同质性对所有目标实体同时排歧。该方法可以处理任意数量的目标实体及其候选文档,并且结合MLD图之后,效果得到大幅提升。实验证明了该方法在不同领域不同语言具有令人满意的性能。
在未来的工作中,我们拟使用使用本体知识库提高先验估计,以及扩展当前工作使其在排歧的同时可以识别出未在列表中的目标实体。
参考文献
[1] Navigli, Roberto. "Word sense disambiguation: A survey." ACM Computing Surveys (CSUR) 41.2 (2009): 10.
[2] Hoffart, Johannes, et al. "Robust disambiguation of named entities in text." Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011.
[3] Bunescu, Razvan C., and Marius Pasca. "Using Encyclopedic Knowledge for Named entity Disambiguation." EACL. Vol. 6. 2006.
[4] Milne, David, and Ian H. Witten. "Learning to link with wikipedia." Proceedings of the 17th ACM conference on Information and knowledge management. ACM, 2008.
[5] Kulkarni, Sayali, et al. "Collective annotation of Wikipedia entities in web text." Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2009.
[6] Han, Xianpei, and Le Sun. "A generative entity-mention model for linking entities with knowledge base." Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, 2011.
[7] Mihalcea, Rada, and Andras Csomai. "Wikify!: linking documents to encyclopedic knowledge." Proceedings of the sixteenth ACM conference on Conference on information and knowledge management. ACM, 2007.
[8] Shen, Wei, et al. "Linden: linking named entities with knowledge base via semantic knowledge." Proceedings of the 21st international conference on World Wide Web. ACM, 2012.
[9] Cassidy, Taylor, et al. "Analysis and Enhancement of Wikification for Microblogs with Context Expansion." COLING. Vol. 12. 2012.
[10] Li, Yang, et al. "Mining evidences for named entity disambiguation." Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2013.
[11] Wang, Chi, et al. "Targeted disambiguation of ad-hoc, homogeneous sets of named entities." Proceedings of the 21st international conference on World Wide Web. ACM, 2012.
[12] Shen, Wei, et al. "Linking named entities in tweets with knowledge base via user interest modeling." Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2013.
[13] Guo, Weiwei, et al. "Linking Tweets to News: A Framework to Enrich Short Text Data in Social Media." ACL (1). 2013.
[14] Liu, Xiaohua, et al. "Entity Linking for Tweets." ACL (1). 2013.
[15] Cucerzan, Silviu. "Large-Scale Named Entity Disambiguation Based on Wikipedia Data." EMNLP-CoNLL. Vol. 7. 2007.
[16] Chen, Zheng, and Heng Ji. "Collaborative ranking: A case study on entity linking." Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011.
[17] Pennacchiotti, Marco, and Patrick Pantel. "Entity extraction via ensemble semantics." Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1-Volume 1. Association for Computational Linguistics, 2009.
[18] Fernandez, Norberto, et al. "WebTLab: A Cooccurencebased Approach to KBP 2010 Entity-Linking Task." Proc. TAC 2010 Workshop. 2010.
[19] Radford Will, Hachey Ben, Nothman Joel, Honnibal Matthew, and R.Curran James. 2010. Cmcrc at tac10: Document-level entity linking with graphbased re-ranking. In In Proc. Text Analysis Conference (TAC 2010).
[20] Cucerzan, Silviu. "TAC entity linking by performing full-document entity extraction and disambiguation." Proceedings of the Text Analysis Conference. Vol. 2011. 2011.
[21] Guo, Yuhang, et al. "A Graph-based Method for Entity Linking." IJCNLP. 2011.
[22] Ratinov, Lev, et al. "Local and global algorithms for disambiguation to wikipedia." Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, 2011.
[23] Han, Xianpei, Le Sun, and Jun Zhao. "Collective entity linking in web text: a graph-based method." Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. ACM, 2011.
[24] Kozareva, Zornitsa, Konstantin Voevodski, and Shang-Hua Teng. "Class label enhancement via related instances." Proceedings of the conference on empirical methods in natural language processing. Association for Computational Linguistics, 2011.
[25] Artiles, Javier, et al. "WePS-3 Evaluation Campaign: Overview of the Web People Search Clustering and Attribute Extraction Tasks." CLEF (Notebook Papers/LABs/Workshops). 2010.
[26] Miller, George A. "WordNet: a lexical database for English." Communications of the ACM 38.11 (1995): 39-41.
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
