




















���ڸ��Ի���ҳ���Ƶ������Ƽ��㷨�о�
ժҪ�����Ż�����ʱ���ĵ���������������ý���Ѿ������˴�ͳ����ý���Ϊ����Ҫ����Ϣ��Դ����������Ϊһ������ý��Ĵ�����ÿ�췢������Ϣ��������Ϣ�ิ�ӣ���Ϊ�û���˵�������˴����Ϣ�����ڶ�ʱ�����������ܵ���������Ȥ��������Ϣ����Ŀǰ������û���趨�û���ҳ���ƵĹ��ܣ���˹����������ĸ��Ի���ҳ���Ƶ��㷨�о��Ƿdz��б�Ҫ�ġ���Ŀǰ����Ҫ�ǵ��Ƽ���Эͬ�����㷨������Эͬ�����㷨��Ҫ�ǿ��ǵ��û�������֮��������ԣ�����������Ϣ���ݷ�����ı�ʱ�����û�Ⱥ�����������ʱ������Эͬ�����㷨�������Ƽ�ģ�͵ľ�ȷ�Ȼᷢ���仯�����㷨��ȱ�������Dz����ھ�����ŵ�����ֲ������û��Ĺ�ע����Ȥ�������Эͬ�����㷨Ч�ʱȽϵ��¡����������Ҫһ�ֻ�����������������Ƽ��㷨�����㷨��Ҫ������LDA�㷨���������ŵ�����ֲ������ù��������㷨�������û�������ֲ�������spark��Ⱥ�Ĵ����ϴ����ݼ���
��һ�� �о���Ŀ��ʵ����
�����������Ż���վ�����������ʱ����ӭ�����罻�����ʱ�������������µ���ս����Ϣ��Ƭ����ʱ����Ƭ�����û�����ĸ��Ի������ն���PCת���ֳ������ն˵ȡ���ữ�������Ƽ�������ͼͨ������Ϊ���ĵ��罻�������ݷ���������ھ�λ�û���ϲ�ã���ע�û�����Ȥ�ص㣬���ս����ʵ�������Ϣ���͵�ָ���û���
���ĵ��о��������ڽ��û���Ϊһ���о�����ͨ���û�����ʷ�������¼�������ڵ���Ӧ�����ݷ����������ھ�ķ�����ʽ��������̽���û�������Ȥ�����ŵ����⣬����ͨ������������õ��û�����Ȥ������������Ӧ��������Ϣ�����Ϣ��

�ڶ��� ��ͳ�����Ƽ�������
��ͳ�������Ƽ��㷨��Ҫ��������Эͬ�����㷨�� ��Ҫ������item-based��used-based���ֹ��˷�ʽ������������Ϣ�����ַ�ʽ��Ҫ˼���������ı�֮�����������ͻ���û�֮��������ԣ�������ʵ�������Ƽ��ϲ����ܵõ��dz�������Ƽ���Ч������Ҫԭ����Ҫ�����£���һ������Эͬ���˵������Ƽ��㷨��Ҫ��ͻ�����ı��������ԣ������������Բ�������ȫ�����û��������ԣ��ڶ�������Эͬ���˵������Ƽ��㷨����û�н��û���Ϊһ���о�������������ھ���ȱȽ�dz���������ھ���û�����Ȥ���á������ĵ��о����壬���û���Ϊһ���о�����ͨ����������ķ�ʽ��̽���û����ص㣬����ͨ��������������������Ի������Ƽ�������ɸ��Ի���ҳ���ơ�
������ �Ƽ�ģ�͵Ľ���
��Ϊ���������������Ҫ��ͨ�����û��������¼����¼�û�����������ţ� ����Щ��������ͨ���ǰ�����Ӧ�����⣬�����Щ�����ظ���γ��֣������϶���Щ�����Ƕ��������ĵ������ȵ㣬������Ϊ�Ƕ�����Ȥ�������ڡ�����ͨ��������������û������ĵ�����������������ʵ������γ��֣�������Ϊ���û���ϲ�����������ţ�ͬʱ���ܴ��½�����ҵ��������ǿ��Դ����������Ƽ����ţ�����ֲ��һЩ���ڸ��û����ƵĹ�棬������ڲ�Ʒ��������Ʒ��档�ڴ˻����ϣ�����ͨ����Ӧ�Ĺ���������̽���û���Ȥ���������������1��Сʱ�������¼���棬�û����ͬʱ�鿴�˹�������������������Ϣ�����ڴ�������������Ϣʱ�����ǿ��Խ���������Ϣͬʱ���͵����������Ҫ�㷨����ͼ������ʾ��
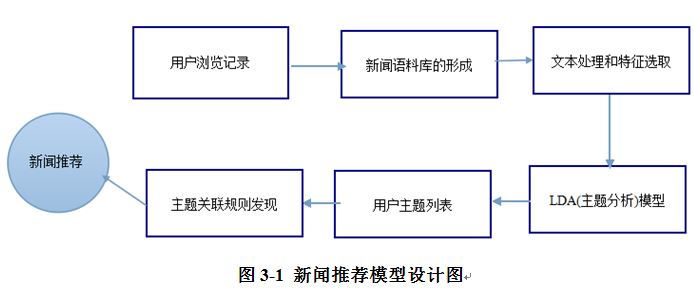
3.1�������Ͽ���γ�
���ڸ��㷨��������Դ���������û���������ţ�����һƪ���µ���Ϣ���࣬���Ǻ��ѽ�һƪ����ֱ�ӵ������ǵ��㷨�У������Ҫ����һЩ��Ϣ���γ��������յ����Ͽ⡣�ı�������ͨ����ͨ���ִ�����ɣ��ִ���Ҫ��Ŀ�������������������������Ҫ�����¼��ַ�ʽ��
�����ַ���ƥ��ķִʷ������˷������ղ�ͬ��ɨ�跽ʽ��������Ҵʿ���зִʡ�����ɨ�跽ʽ��ϸ��Ϊ���������ƥ�䣬�������ƥ�䣬˫�����ƥ�䣬��С�з�(�����·��)����֮���Ǹ��ֲ�ͬ����������
ȫ�зַ������������зֳ���ʿ�ƥ������п��ܵĴʣ�������ͳ������ģ�;������ŵ��зֽ���������ŵ����ڿ��Խ���ִ��е��������⡣��ͼ��һ��ʾ���������ı������Ͼ��г������š������Ƚ��д�������(һ����Trie�洢)���ҵ�ƥ������д������Ͼ����У����������ţ��Ͼ��У��������ţ��г��������ţ������ţ����Դ�����(word lattices)��ʽ��ʾ��������·������������ͳ������ģ��(����n-gram)�ҵ�����·���������ܻ���Ҫ����ʵ��ʶ����ͼ�С��Ͼ��� ���� ���š�������ģ�͵÷֣���P(�Ͼ��У�����������)��ߣ���Ϊ�����з֡�

���ֹ��ʵķִʷ�������������Ϊ�ֵķ������⣬Ҳ������Ȼ���Դ����е�sequence labeling���⣬ͨ������������HMM��MAXENT��MEMM��CRF��Ԥ���ı���ÿ���ֵ�tag��Ʃ��B��E��I��S�����ĸ�tag�ֱ��ʾ��beginning, inside, ending, single��Ҳ����һ���ʵĿ�ʼ���м䣬�������Լ������ֵĴʡ� ���硰�Ͼ��г������š��ı�ע�������Ϊ������(B)��(I)��(E)��(B)��(E)��(B)��(E)��������CRF�ȿ����������ģ��һ���Ӹ�������feature���ֱ�����HMM����������Ʒ���裬���Ի���CRF�ķִ�Ŀǰ��Ч����õġ�
��Ȼ�ֹ��ʵķִʷ����ִ�Ч���ȽϺã����Ǽ��㸴�ӣ��������ݷ��ӵĴʿ�֧�֣���������ʹ��ȫ�зַ����ķ�ʽ���дʣ���Ȼȫ�зִַ�Ч��������ֹ��ʵķִʷ����ִ�Ч����Բ�㣬�����㷨�������ٶȿ죬������ں����ı���˵�����ô��ַ�ʽ����Ѹ�ٵõ����Ͽ⣬�ӿ��㷨����
3.2�ı���������������
��Ȼͨ���ִʿ���һ����ģ���������Ͽ⣬��������������ִ����д����ִ���û�м�ֵ�ģ���Щ�ʱ�����Ϊͣ�ôʣ�����Ϣ�����У�Ϊ��ʡ�洢�ռ���������Ч�ʣ��ڴ�����Ȼ�������ݣ����ı���֮ǰ��֮����Զ����˵�ijЩ�ֻ�ʣ���Щ�ֻ�ʼ�����ΪStop Words��ͣ�ôʣ������缸��ÿƪ���¶��������Ĵʣ����㡱�����ҡ������ġ�������������Ϊ��������Ϊ������Щ�ʲ���������������������Ϣ����˳�ȥ��Щͣ�ô����б�Ҫ�ġ����⣬����ͣ�ôʣ��������´ʣ���������ţ���������쳣�ʡ���ȥ��Щ�DZ�Ҫ�ʣ����ǻ�õ�һ���Ƚϸɾ����ı����Ͽ⡣
��Ȼ���ǿ��Եõ�һ���Ƚϸɾ������Ͽ⣬���ǿ����֪�����ǽ�һƪ����ͨ��N-Gram����ģ�����ִʣ���õ�һ����ά�ȵ����Ͽ⣬����һƬ300�����£����ǿ��ܵ�2000������������ƪ���£������������У�������ǽ������������Ͽ�����ǵ�ģ���У��Ǵ��ڡ�ά�����������⣬����ֱ�ӵ��µ�����������ģ��Ԥ������ȷ�ʺ��ٻ��ʶ��Ƚϵͣ��Ƽ�Ч���������ֹۣ����������Ҫ��Ӧ�ļ����ֶλ������㷨���õ��������������µĴʣ���˵������Ҫ�ҵ���Щ���µĹؼ��ʡ����ҵ����������ı��е������ʣ���Ҫ���㷨��Ҫ�����¼��֣�TF-IDF����Ϣ���棬����Ϣ���ĵ�Ƶ�ʷ�������Ϣ���淽��������Ϣ������CHI���������������صȡ�������Ҫ�����õ����㷨����õ��ı��ھ���TF-IDF��
TF-IDF(term frequency�Cinverse document frequency)��һ����Ϣ�ھ��Լ���Ϣ��������ij��ü�Ȩ���������������������������������й㷺��Ӧ�á�TF-IDF��һ��ͳ�Ʒ���������������Ҫ������ijһ�ִʶ���һ���ļ�����һ�����Ͽ��е�����һ���ļ�����Ҫ�̶ȡ�ͨ����Ϊ���ִʵ���Ҫ���������ļ��г��ֵ�Ƶ�ʳ����ȣ����Ǻ������ļ��������Ͽ��е��ձ��Գɷ��ȣ��������ļ����еij���Ƶ��Խ����Ҫ��Խ�͡���������ͨ��ʹ��TF-IDF��Ȩ�ĸ�����ʽ��Ϊ�ļ����û���ѯ�ؼ���֮����س̶ȵĶ�����
TF-IDF����Ҫ˼���ǣ����ij���ʻ������һƪ�����г��ֵ�Ƶ��TF�ߣ����������������к��ٳ��֣�����Ϊ�˴ʻ��߶�����кܺõ���������������ʺ��������ࡣTF��Ƶ(Term Frequency)��IDF���ĵ�Ƶ��(Inverse Document Frequency)��TF��ʾ�������ĵ�d�г��ֵ�Ƶ�ʡ�IDF�ı���ʽΪ����ͼ��ʾ��
IDF����Ҫ˼���ǣ������������t���ĵ�Խ�٣�Ҳ����nԽС��IDFԽ����˵������t���кܺõ�����������������ijһ���ĵ�C�а�������t���ĵ���Ϊm�������������t���ĵ�����Ϊk����Ȼ���а���t���ĵ���n=m+k����m���ʱ��nҲ����IDF��ʽ�õ���IDF��ֵ��С����˵���ô���t�������������ǿ������IDFҲ�в���֮�������ij��������ijһ����ĵ����ձ���֣���˵���ô����ܹ��ܺô�����һ����ı��������������Ĵ���Ӧ�ø����Ǹ���ϸߵ�Ȩ�ء�
��ʵ��ijƪ�����У�����Ȩ�ص�ʱ�����ÿ���ʷִ������㣬���磺���й�Ů���������ھ�������ʡ����裺�й�Ů��ҳ�������λ2000���������ļ�����Ϊ1000���ɵļ�����Ϊ50000����������ҳ������Ϊ100�ڡ��й�Ů����www.sina.com/xxx.html�����վ��ҳ��(ҳ���ܴ���400)����8�Σ�����������10�Σ����ɳ���16�Ρ�
��ô���ԵĴ�Ƶ��TF(�й�Ů��)=8/400=0.02,TF(������)=10/400=0.025��TF(�ھ�)=20/400=0.04����IDF(�й�Ů��)=LOG(10000000000/20000000)=2.69897,
IDF(������)=LOG(10000000000/10000000)=3,������û�Ҫ�������ǵĹھ���IDF��IDF(�ھ�)=log(10000000000/100000000)=1.69897,��ô������֮���й�Ů���������Ĺھ���Ϊҳ���Ȩ�غ���ضȹ���ֵ�ֱ�:Tf-idf(�й�Ů��)=0.02*2.69897=0.0539794,Tf-dif(������)=0.025*3=0.075,Tf-idf(�ھ�)=0.04*1.69897=0.0679588
��˴ӵõ�TF-IDFֵ���ǿ���Ԥ����ƪ���������ע��������������Ϣ�����ǿ����趨һ���ķ�ֵ����TF-IDFֵС�����ֵ��ʱ�����ǿ��Խ���Щ�ʹ��˵����������ǾͿ��Լ��������������⡰ά��������
3.3 LDA(�������)�㷨
��Ȼ���ǿ���ͨ��TF-IDF���õ����µĹؼ��ʣ�����TF-IDF������ȥ������µ��������⣬�ٸ����ӣ����������ӷֱ����£����Dz�˹�����Ƕ�ȥ�ˡ�������ƻ���۸��ή���������Կ�����������������û�й�ͬ���ֵĵ��ʣ������������������Ƶģ��������ͳ�ķ����ж����������ӿ϶������ƣ��������ж��ĵ�����Ե�ʱ����Ҫ���ǵ��ĵ������壬�������ھ������������ģ�ͣ�LDA��������һ�ֱȽ���Ч��ģ�͡�
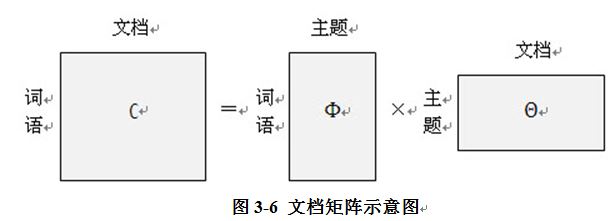
�����������ֲ���Latent Dirichlet Allocation�����LDA��,���㷨�ĺ��ĵ�˼�������ȣ�����������ģ�������ĵ��������������¡���ν����ģ�ͣ�����˵��������Ϊһƪ���µ�ÿ���ʶ���ͨ������һ������ѡ����ij�����⣬���������������һ������ѡ��ij���������һ�����̵õ��ġ���ô���������Ҫ����һƪ�ĵ����������ÿ��������ֵĸ���Ϊ������ʾ��ͼ����ͼ��ʾ��

������ʹ�ʽ�����þ����ʾ,����ͼ��ʾ��
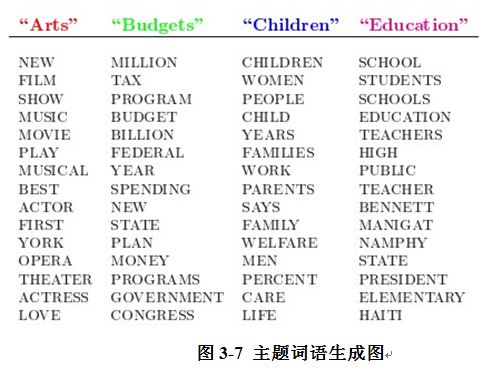
LDA������λ������ԭʼ�����и���һ�������ӡ�����������ȸ������⼸�����⣺Arts��Budgets��Children��Education��Ȼ��ͨ��ѧϰ�ķ�ʽ����ȡÿ������Topic��Ӧ�Ĵ������ͼ��ʾ��
Ȼ����һ���ĸ���ѡȡ����ij�����⣬����һ���ĸ���ѡȡ�Ǹ������µ�ij�����ʣ����ϵ��ظ���������������������ͼ��ʾ��һƪ���£����в�ͬ��ɫ�Ĵ���ֱ��Ӧ��ͼ�в�ͬ�����µĴʣ���

����LDA�㷨���漰�˴�����ͳ��ѧ�ĺ����۵�֪ʶ����Ҫ�漰�Ķ���ʽ�ֲ�������ʽ�ֲ���beta�ֲ����������ֲ���Dirichlet�ֲ���������������ʷֲ���ȡ�����㷨�dz����ӣ�������Ҫ��˼·����ͨ�������ĵ��Ŵ���ķֲ����յõ��ĵ�������ķֲ������ͨ������ɸѡ�����Ͽ⣬�������Ͽ�����ǵ�ģ���У����տ��Եõ����ǵ�����ֲ��������
3.4 ��������ķ���
��LDAģ�������ǿ��Եõ�������������⣬��������֮���д���ģ�������ij10�����ڣ�һ���û����������������������ź���������ƾ������ο����ע�����е�����������е��������⣬�����֪�����ǿ��Զ��û������ϰ�߽���Ԥ�⣬���������ھ��û�����Ȥ���á�
��ν��������ӳ����һ���¼��������¼�֮�������������֪ʶ�������Dz���Ӣ������ʱ���Է���������Ӣ�Ĵʶ������ݹ����ĺ��塣��һ���������relevance���ڶ����ǹ�����association�����߶��������������¼�֮��Ĺ����̶ȡ������õĹ��������㷨��FP-Growth�㷨��Apriori�㷨���������㷨���ܺܺ���ɹ�������ķ��֡��ڹ��������㷨����Ҫ�����ָ���Ҫֵ��ע�⣬һ�������Ŷȣ�һ��֧�ֶȡ�ֻ��һ��������������ŶȺ�֧�ֶ�ͬʱ������С��ֵ��ʱ������Ͽ�֮��Ĺ�������������һ��ʵ��������������ķ��֡��±���ijһ��ʱ�䣬��������������ë��Ĺ�����ϵ����
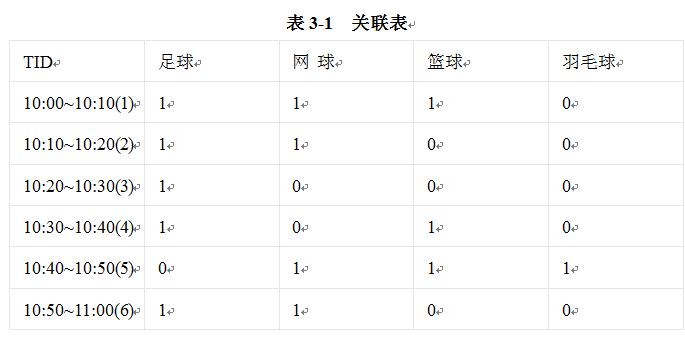
�ϱ���ijһλ�û���10:00~11:00��ҳ���������ֲ����������������зֱ�����˹�����������������ë����������ҳ������6�������I={����,����,������,��ë��}�����ǹ�������Ƶ�����������������������1,2,3,4,6������������1,2,6ͬʱ�������������X^Y=3, D=6��֧�ֶ�(X^Y)/D=0.5��X=5, ���Ŷ�(X^Y)/X=0.6����������С֧�ֶȦ� = 0.5����С���ŶȦ� = 0.6����Ϊ�����������������֮����ڹ�����������Ϊ���ã�ϲ��ͬʱ�Ķ���������������������Ϣ��������ǿ���ͬʱ�����ߵ��������͵��û�����ȥ��
3.5 �㷨�Ա�
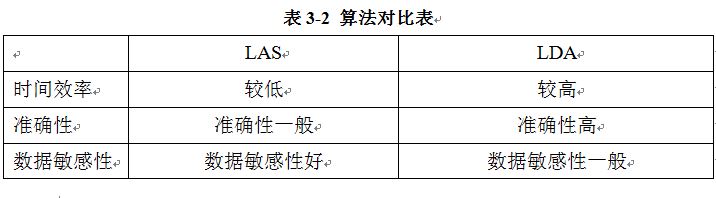
���ڸ��㷨����ͨ��LAS�㷨���ڵIJ�ͬ�����ʵ��Ƽ��㷨�����㷨��ģ�͵�ij���������Ǻ��ѽ��н��к�����бȽϵģ�������Ȼ���ǿ��ԱȽϳ������㷨����ȱ�㣺1������ʱ��Ч���ϣ�LAS�㷨��Ҫ����user��item�������Խ��бȽϣ���Ȼ�Ƽ�Ч����ԽϺã�������ȱ����Item����������չʱ������LAS�Ƽ�ģ��Ҫ���½���ѵ�����ݣ�����Ϊ�������������������ʱ��Ч�ʽϵͣ�������LDA���Ƽ�ģ����Ϊ���û������кܺõĸ����ԣ���ʹItem�������չʱ��ģ�ͼ��㲻�ᱶ������ʱ��Ч���ϱȽ������ơ�2�������ģ�͵�ȷ����˵������LDA��Ҫ�ǻ���item֮������Ƶģ����Ƕ��������Ƽ���˵���û����������Ų�һ����ϲ�����������⣬���Ǿ�Ҫ����LDA���Ƽ��㷨��Ҫ�Ƕ���������ھ��û��ĸ���Ȥ�������ڶ�ʱ���������Ըı�ģ�������Ƽ�ȷ���û���LDA���Ƽ�ģ��ȷ�Ը��ߡ�3���������������ԣ����û�����Ȥ���÷����ı��ʱ����LAS�㷨��˵��LAS�㷨�����Ϸ����û�������ı仯�����Ƕ���LDA�㷨��˵�����������Բ�ǿ�������Ҳ�ǻ���LDA�Ƽ�ģ�͵�ȱ�㡣����ĶԱ����3-2��ʾ��
3.6 ���Ի�����
����������ģ��һ���Ƚ���Ҫ�IJ��࣬Ҳ�غ���ģ�͵�ȷ�ԡ�������һЩ�����Ǹ��Ի���ҳ���Ƶ���Ҫ��������һ���û���ѡ��Ȥ���⡣����LDA�㷨ģ����˵�����Խ��û�ģ������Ȥȡ��ϸ�»���ȷ�������Ǵ���������£��û��Ƕ��Լ�����Ȥ��һ�����˽⣬�������Ӧ�ý��û���ѡ����������û��������б��У������������û��ĸ��Ի�ѡ�����ģ�͵�ȷ�ԡ��ڶ���N-gram����ģ�͵�ȡֵ������N-gram����ģ����˵��N��ѡ���Ӱ�쵽LDAģ�͵��������������ģ�͵ļ�����Ҳ�����ӣ����N��ȡֵ�Ƚ���Ҫ�����ǵ�����ķֲ������ǻ���������Nȡֵ������N��ȡֵ��1~3֮�䡣����������ķֲ��ȽϹ�ʱ�����ǻ���������N��ȡֵ�������������������������⣬����������������������NBA��NBA����ijһЩ������ǣ��������������ֲ��Ƚϣ��㣬���Nȡֵ���Կ������ô�һЩ��������TD-IDF����ѡ������TF-IDF���Ӵ�С��ѡ���Ӱ�������ѡ�����TF-IDF����������ķֲ���Χ�����ͬʱҲ������ģ�͵�ѵ����ʱ�䡣��������ģ�͵�ѵ����spark��Ⱥ��MLLibʹ�ã�������ǵĵ�ʱ��Ч����Ի�ϸߣ���˿���ѡ���С��TF-IDF������������������ķ�Χ�����ģ����������Ƶ��������������������Ƶ�������������ϵ��ù����������������������Dz���Ҫ�����Ƽ�ϵͳ�������������ޣ�ҲҪ���ǵ��û����Ի�ѡ��������������Ž϶�ͻ������Ƽ�ϵͳ�ĸ��أ���������Ҫ�����û���ѡ������û�ϣ���Ƽ��Ĺ������Ž϶࣬��ôƵ����������������ô�һ�㣬����Ҫ�����û��ĸ��Ի�ѡ��
������ �Ƽ�ϵͳ�ܹ�
���ǵ�����ϵͳ�ļܹ����������ǵ�ģ�͵�������õ��˸����ԱȽϸߵ��㷨������LDA�㷨��FP-Growth�㷨����ģ��ѵ��������ҩ��ε������У��Ҹ�ϵͳ��ʵʩ����ϵͳ���������������ı��������ǵ��Ƽ���ϵͳ��ʱ��������ʵʱ�Ľ����¸��Ի����Ƽ����ǵ��û��Ŀͻ��ˣ�������ǵ�����������Ҫ�õ���֤���������ǽ���ʹ���ʺϵ��������spark�ķֲ�ʽ���㼯Ⱥ������spark��̬�������������Ļ���ѧϰ�⣬������Ǻ����Ŀ��Խ���ģ�Ͳ���spark��Ⱥ�С�Spark�ļ�Ⱥ�������¡�
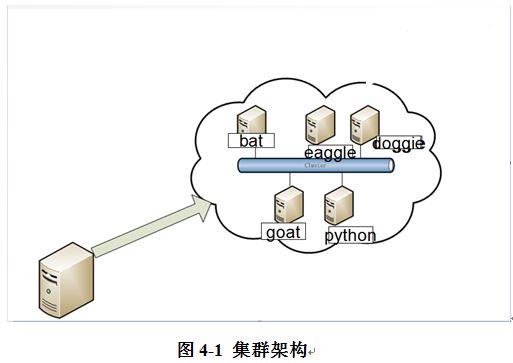
ϵͳ������IJ������£����ȣ�����ͨ��Spark��Ⱥ���û�ԭʼ�������¼����ҳ���д�����������������ݵ������ǵ�LDAģ���У��õ������û������ĵ������б������л�Ҫ�������б�����һЩ���˲����������Ǹ���ʱ�������������������ǵĹ�������ģ���У������������ǵ������б������б�����������Ϣ�洢��������Σ����д�������Ϣ�������ǵ�ϵͳ�����Ƚ������ı���Ϣ���д������������ǵ�LDA�������ģ�ͻ��ܣ��õ�ÿƪ�¼������µ����⡣������������õ�����Ϣ�������ǵ�����ϵͳ�У�����ϵͳ��Ҫ��Ŀ���Ǹ��������û��ĸ���Ȥ�������б������б�ˢѡ����������������ţ��������û���Ȥ�������������η��ʹ��û��Ŀͻ����У�Ϊ�û����Ƹ��Ի���ҳ��

�����
[1] ���.���Ի��Ƽ�ϵͳӦ�ü��о�[C].�������, 2009.6
[2] ����.���Ի��Ƽ�ϵͳӦ�ü��о�[C].2008.1
[3] ���.Web�ı��ھ����о�[M].������о��뷢չ, 2000.11
[4] �����,�̵���.�ı��ھ�ԭ��[C].Ȫ��ʦ��ѧԺѧ��, 2003.04
[5] Arindam Banerjee and Sugato Basu. Topic Models over Text Streams: A Study of Batch and Online Unsupervised Learning. InSDM. SIAM, 2007.
[6] Arindam Banerjee and Sugato Basu. Topic Models over Text Streams: A Study of Batch and Online Unsupervised Learning. InSDM. SIAM, 2007.
[7] Feng Yan, Ningyi Xu, and Yuan Qi. Parallel inference for latent dirichlet allocation on graphics processing units. InNIPS, 2009.
[8] Arthur Asuncion, Padhraic Smyth, and Max Welling. Asynchronous distributed learning of topic models. In NIPS, pages 81�C88, 2008.
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
- ���ƣ��ñ�ҵ�θ������뷨��
- ��ˮ�����ϸ�������3D��ӡ ���Ƹ��Ի�����Ӧ��Ѵ�ڻ�ˮ����
- �����������������ˣ������й���
- ���������������ҵն������ȫ���һ
- ����������չ���Ի����Ƶ��ٴ��ֶ� ������ǿ����ҽԺ
- ���˻����Ƴ�����ն��Ʒ���
- �����Σ����ȶȺ����ŷ���
- �������������������ڵģ�
- ���ô����ݽ�������ͨ�㷨ģ�͡�������2020�����й����´��������������������ÿ���
- ��ֹ�������������� AI��������������㷨
��������
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
