




















HLBPR:一种混合的基于局部相似度的BPR算法
摘 要:随着电子商务的迅速发展,了解消费者在购物网站上的购买意向是一个十分重要且具有挑战性的任务,迄今为止针对这个问题已经提出了许多的模型。在这些模型之中,贝叶斯个性化排序算法是第一个引入了对排序进行优化的著名算法。然而这个算法通常存在着数据稀疏性的问题。在这篇文章中,我们介绍一种混合的基于局部相似度的贝叶斯个性化排序(简称HLBPR)算法来解决数据稀疏性的问题。我们的主要思路是通过用户消费记录的局部相似性来发掘用户感兴趣的潜在商品,然后使用这些扩充的数据来优化物品排序。最后,我们通过在两个实际数据集上的实验来证明我们模型的有效性。
关键词:推荐系统;稀疏;贝叶斯个性化排序(BPR)
引 言
近些年来,随着电子商务这个新兴产业的迅速发展,如何有效地捕捉消费者潜在兴趣成为学术界争相关注的热点之一,围绕着这个问题,研究者们提出了很多的方法。在这些方法之中,贝叶斯个性化排序(BPR)算法是一个公认的效果拔群的方法[6]。然而实际应用中数据往往存在着稀疏性的问题,用户实际购买的物品通常只占总体商品的一小部分。以Ta-Feng数据集为例,平均而言,每个用户只购买了总共商品的0.4%。数据的稀疏将直接导致BPR算法的推荐精度上的低效性。现有的方法(例如SBPR等)通常要引入附加的信息(如社交信息等)来解决这类问题。但是,这类信息是在某些应用场景中本身就是相当稀少,甚至根本不存在的。为了缓解BPR算法数据稀疏性问题,并且尽可能的不引入可能不存在的额外信息,在本文中,我们介绍了一种混合的基于局部相似度的贝叶斯个性化排序(简称HLBPR)算法。与其他的现有方法相比,我们的方法有着以下的优点:
1)我们通过用户购买历史的局部相似性计算出用户未来可能会购买的潜在商品,然后我们将这商品标记为已经购买过,通过这种方法我们扩充了用户的购买历史以避免稀疏性问题。
2)我们设计了两种模式:一般模式和序列模式来计算用户之间的相似度。
3)通过将(2)中的两种模式混合,我们可以在商品推荐中获得更好的性能。
我们在两个实际交易的数据集上进行了大量的实验,结果表明与传统的BPR方法相比,我们的方法是相当有效的。
1、相关工作
推荐系统获取用户反馈的方式包括显式反馈和隐式反馈。显式反馈要求用户对推荐的内容给出明确的评分或者通过填写调查问卷的方式向系统提供自己的兴趣,这虽然能更准确地表达用户的兴趣,但是需要用户的额外操作,这种方式对用户不是很友好。因此,可用的评分会很少,会出现数据稀疏问题,从而导致推荐质量不高。
相比之下,隐式反馈的收集要容易得多,隐式反馈包括用户的点击、浏览、收藏、购买等。一般网站的后台服务器会记录用户的在网站上的行为,并保存在日志文件中。通过分析这些日志文件,可以得到很多用户对于商品的隐式反馈。
但是,隐式反馈的缺点是只能得到正反馈,也就是说,从隐式反馈一般只能推断出用户喜欢某个物品,而那些没有观察到的用户-物品对,就可能包含两种情况,一种是真的不喜欢,还有一种是用户可能不知道这个商品。例如,通过用户的购买记录,可以推断用户对购买过的这些商品是感兴趣的,而对于那些用户没有购买过的商品,并不一定就代表用户不喜欢,也很有可能该用户还没有发现该商品,未来他知道后可能会购买。这种基于隐式反馈数据进行的推荐也被称作one-class协同过滤。解决这类问题,一般有两种方法:(1)基于评分的方法;(2)基于排序的方法。
基于评分的方法 基于评分的方法将隐式反馈当作绝对分数值来处理,例如一般将有反馈的项当作1,无反馈的项当作0。然后通过最小化平方损失去学习模型。[4]就是典型的利用这种思路解决推荐问题的方法。它利用不同的采样策略来扩展观察到的正反馈,然后利用现有的矩阵因子分解算法来学习一个推荐器。
基于排序的方法 基于排序的方法都相对较新。它们将隐式反馈当作相对偏好而不是绝对分数来处理。贝叶斯个性化排序(Bayesian personalized ranking,BPR)是其中最著名的方法。它直接优化一个类似AUC的排序目标。由于基于排序的方法取得了不错的效果,有很多由BPR扩展而来的的新算法被提出来。在论文[11]中,社交信息被用来生成更多的商品偏好对,进而引导BPR算法在一个比较稠密的用户-商品矩阵上进行采样。在论文[5]中,作者提出一种可选采样策略用来自适应地决定包含最多信息的商品偏好对。在论文[2]中,作者通过交互的频繁程度,对有反馈数据集进行了更细致的划分,从而构造了更多的商品偏好对。
和上面这些工作相比,我们提出的混合的基于局部相似度的贝叶斯个性化排序(Hybrid Local Bayesian personalized ranking,HLBPR)算法在解决one-class协同过滤问题时的主要优势是:
1)HLBPR能够在无反馈商品之间建立更多的商品偏好对,进而帮助传统的BPR算法在一定程度上缓解数据稀疏问题。
2)在HLBPR的整过推演过程中,不需要引入额外的任何信息。
2 问题定义
2.1 隐式反馈
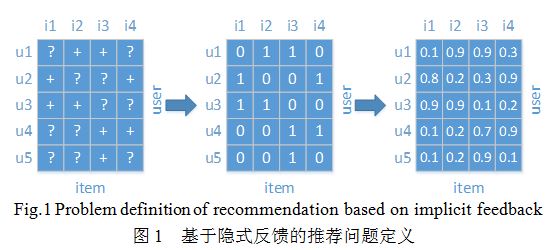
我们首先形式化地定义基于隐式反馈的推荐问题。推荐系统的任务就是根据已知的用户-物品交互行为来推测用户对其余物品的偏好。如图1中最左边的矩阵所示,加号表示观察到该用户对该物品有过交互行为,问号表示没有观察到该用户对该物品有过交互行为。
传统的解决隐式反馈的方法是,将其当作显示评分预测问题来处理。具体处理方法如图1所示,就是把加号当作1,把问号当作0,然后根据这些数据来训练模型,最后预测出每个用户对每个物品的评分,从而对用户进行推荐。
使用这种简单的处理办法,推荐结果肯定不会太好。可以看到,通过这种方式训练出来的模型,会使问号的值尽可能地接近0,而加号的值尽可能地接近1。这意味着,如果模型的表达能力足够强,或者说模型够复杂,那么它最后的预测结果会总是0。而唯一能够解决该问题的方法就是避免模型过拟合,例如正则化。
2.2 BPR的解决方案
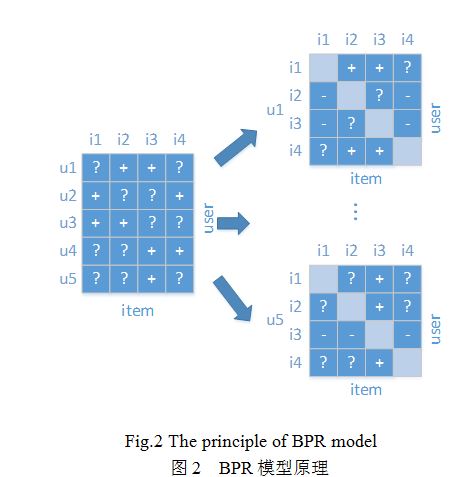
正是由于将隐式反馈当作评分问题来处理会有诸多问题,因此Rendle等人提出了BPR模型。该模型不再以预测用户对物品的评分为目标,而是通过最大化正例排在负例前面的概率。从而将评分问题转化为排序问题来处理。具体思路如图2所示,将左侧的用户-物品的大表分解为很多个右侧的物品-物品的小表,而每个用户对应一个。表中的每一项表示该用户对任意两个物品之间的相对偏好程度的大小。
BPR算法依据这样两个假设:1. 相比于没有反馈的物品,用户更喜欢有过反馈的物品;2. 对于都没有反馈的任意两个物品或者都有过反馈的任意两个物品,用户的偏好程度相同。依据以上的假设,可以构造出图1中右侧的表。然后利用已知的项去预测问号的内容,从而得到用户对任意两个物品间的偏好程度的相对大小,进而进行推荐。
2.3 HLBPR的解决方案
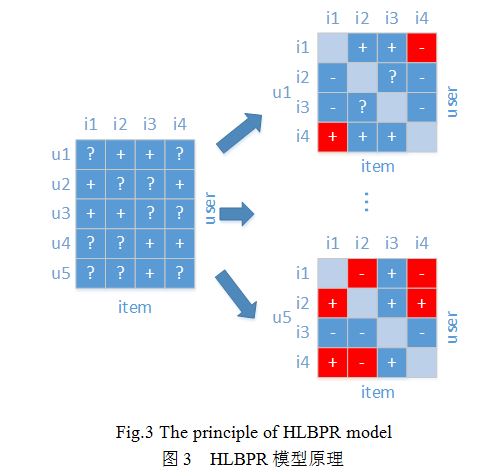
BPR模型虽然在一定程度上解决了基于隐式反馈的推荐问题,但是其还面临数据稀疏的问题。也就是说,相比与巨大的物品总数,用户有过反馈行为的物品是极少的,也就是说图2中的矩阵的大部分内容都是问号,只有极少的项为加号。这极大地影响了推荐算法的准确率。
我们提出的HLBPR模型的主要思路是,对没有反馈的物品集进行更进一步的细分,从而在不增加额外信息的情况下,挖掘出更多的用户-物品对,以此解决BPR模型的数据稀疏问题。具体思路如图3所示,图中右侧的表格中,标记为红色的方格,在BPR模型中是问号。而通过我们在本文中提出的三种模型对无反馈数据集进行进一步细分,可以确定它们的值,从而解决数据稀疏问题。
3 我们的模型:HLBPR
为了解决传统BPR算法中存在的数据稀疏问题,我们的模型主要关注于如何在用户没买的商品中区分用户对于不同商品的喜好程度,进而构建出更多的商品偏好对。本章首先从两种不同的模式出发考虑用户可能购买的商品,然后将两种模式有机的结合以达到更好的推荐精度。
在具体阐述模型之前,我们希望通过一个例子来说明我们构建模型时考虑的因素和动机,如图1。假设李明是一个旅行爱好者,他在某个电子商务网站上的购买列表中有帐篷,冲锋衣,登山鞋等,同时他在昨天在该网站上买了一个手机。根据前一个行为,我们可以推断李明很可能在下一次的购买中买关于旅行的商品,例如登山裤,墨镜,防晒霜等。但是根据后一个行为,我们可能会推断李明可能下一次购买的是手机电池或者手机壳等。因此根据这两种不同的推荐行为,我们首先采用两种不同的模式来构建推荐系统。
我们假设U代表用户的集合,I代表商品的集合。给定一个用户-商品矩阵R∈〖{0,1}〗^(|U|×|I|), 其中R_ui=1表示用户u∈U购买过商品i∈I。R_ui=1表示u未买过商品i。
3.1 基于非时间序列的BPR模型
在这一节中,我们直接利用用户的购买信息来构建模型。我们把构建商品偏好对这个任务分成三部分:1. 计算用户的相似度;2.根据用户相似度计算用户对于自己未买过的商品的喜好得分;3. 根据阈值来构建pair。
1)计算用户的相似度
首先我们根据用户的购买信息来构建用户的表示向量,例如一个用户u的购买记录是{(a,b),(a,d),(c)},这代表u进行了三次购买,在第一次购买中买了商品a和b,第二次买了商品a和d,第三次买了c。我们直接把u表示成R_u={a:2,b:1,c:1,d:1 }(Fig4)。对于两个用户u,v ∈U ,我们采用cosin距离来表示用户的相似度,公式如下:
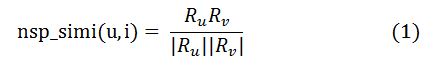
计算用户对不同商品的喜好得分:
我们取和指定用户最接近的K个用户,然后统计他们中有哪些购买了指定物品。具体来说,我们用nsp_score(u,i)来表示用户u对商品i的喜好得分,我们根据和用户u购买记录相似的用户对商品i的行为记录来推断出用户u对商品i的喜好,公式如下:
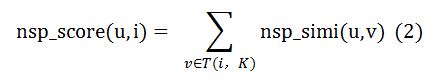
这里T(i,K)代表和用户u最接近的K个用户中,购买过商品i的用户集合。

2)构建商品偏好对
根据用户对于物品的得分,我们对用户未买过的物品进行划分,进而构建商品偏好对。显然,这里构建商品偏好对的方式有很多,例如根据用户u对不同商品i和j的得分差,或者可以先根据某一固定的阈值th来直接把用户划分成两部分,然后在两部分之间构造商品偏好对。经过大量的实验我们发现后一种方法效果比前者好很多。我们可以将这一方法形式化表示成:

3.2 基于时间序列的BPR模型
目前,已经有大量的工作[1,9,7]证明,用户的潜在兴趣可以从海量的的用户行为序列中推理得来。直观来说,例如,如果已经存在大量的用户在先买了手机后就买了手机壳,那么如果当前有一个用户购买了手机,那么我们就有理由预测这个用户在下一时刻可能会购买手机壳。因此在这一章节中,我们利用时间序列这一模式来捕获用户的潜在兴趣。
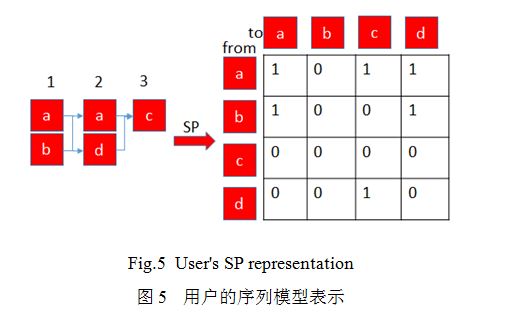
构建商品偏好对的过程和基于非时间序列的BPR模型一样,首先我们用[7]中的方法表示用户向量,例如,上面提到的用户u,其向量可以表示为S_u={a→a:1,a→d:1,b→a:1,b→d:1,a→c:1,d→c:1}(Fig5)。我们同样使用cosin距离来计算用户u和v的相似度sp_simi(u,i)。
根据[9],用户u对商品i的喜好程度可以通过下面的公式计算:

这里〖last〗_u表示用户u的最后一次消费记录,S(〖last〗_u,i)表示{v|v包含序列对(k,i),k∈〖last〗_u}。得到用户u对商品i的喜好得分后,商品偏好对的构造方式和上面的方法相似。
3.3 混合的BPR模型
为了同时获得基于时间序列和基于非时间序列模型各自的优势,本节把上面的两个模型结合起来建模(fig6)。令hybrid_score(u,i)表示混合模型中用户u对商品i的喜好得分。显然,这里利用nsp_score(u,i)和sp_score(u,i)生成hybrid_score(u,i)的方式有很多,我们深入研究了两种方式,即最大值池化方法和均值池化方法。
1)最大值池化
hybrid_score(u,i)由nsp_score(u,i)和sp_score(u,i)中的最大值确定,公式如下:
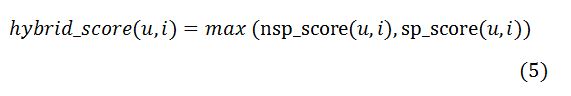
2)均值池化
hybrid_score(u,i)由nsp_score(u,i)和sp_score(u,i)的加权平均值确定,公式如下:

其中参数a是用来平衡nsp_score(u,i)和sp_score(u,i)两部分的权重。

3.4 模型的学习方法
在构建了更多的商品偏好对之后,我们采用与传统的BPR学习算法类似的方法,在扩展后的商品偏好对上采用随机梯度下降算法来求解HLBPR的参数。我们假设传统的BPR模型中用户商品偏好对集合为D={(u,i,j)|i∈I/I^-,j∈I^-}, 这里I表示所有的物品集合,I^-表示用户未购买过的商品集合。算法的伪代码如图7所示。

4 实验结果与分析
在本章中,为了说明我们算法的有效性,我们设计并实现了大量的测试实验。首先,我们介绍用来验证推荐算法的数据集,基准算法和评价指标。然后,我们对实验结果进行了和分析。
4.1 数据集
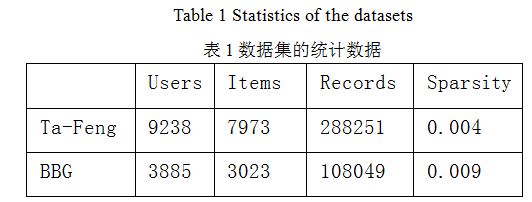
Ta-Feng: 本数据集是Recsys大会公开的真实的用户消费记录数据集,产品种类囊括食品,水果,办公用品等。
BBG:本数据集是真实的大型电子商务网站云猴网(http://www.yunhou.com/)上的采样数据。
在我们的试验中我们过滤掉消费次数小于10次的用户和被消费次数小于10次的商品,并且将数据集按照70/30的原则构建训练/测试集合。我们在表1中列出了这两个数据集的统计信息。
4.2 基准算法
TOP-POP:这是一种非个性化的静态推荐算法,对于每一个用户,该算法都推荐给他最受欢迎(购买次数最多)的商品。
NMF:非负矩阵分解(Non-negative matrix factorization)是一种效果突出的矩阵分解算法,该算法同时要求用户矩阵,商品矩阵都满足所有元素都不为负的性质,元素的非负性使得分解结果更容易解释。在具体实现这个算法的时候,我们采用的是公认度比较高的公开代码(http://cogsys.imm.dtu.dk/toolbox/nmf)进行的实验。
BPR:传统的贝叶斯个性化排序(Bayesian personalized ranking)模型。其主要思想是利用贝叶斯最大后验估计求出物品对之间的全序关系,从而获得用户对物品的个性化排序。在实现的过程中,我们利用尝试了不同的参数,并且在学习率α=0.05, 规则化系数λ_w=0.002, λ_(H^+ )=λ_(H^- )=0.0001时得到了最好的结果。
NSP-BPR:基于非时间序列的BPR模型。在这个模型中我们的用户相似度的计算方法是直接考虑用户购买的商品数目,而未考虑购买商品的前后顺序。
SP-BPR: 基于时间序列的BPR模型。在这个模型中,我们计算用户相似度时考虑了用户购买商品的先后顺序。
HLBPR:混合BPR模型。在实现这个模型的过程中我们通过大量的尝试和反复的实验最终在α=0.45, th_upper= th_lower=0.001时得到了最好的结果,同时我们已经将我们模型的代码公开到了https://github.com/gearsuccess上。
4.3 评价指标
准确率:Precision,也叫查准率。在推荐系统中,准确率指的是正确推荐的商品数与推荐商品总数的比率。
召回率:Recall,也叫查全率。在推荐系统中,召回率指的是正确推荐的商品数与总商品数的比率。
F1值:F1-Score,又称平衡F分数(balanced F Score),它被定义为准确率和召回率的调和平均数。
命中率:Hit-Ratio,指的是正确推荐的商品数与用户总数的比率。
NDCG:Normalized Discounted Cumulative Gain,是一种用来衡量排序质量的指标,其主要依据以下两个假设:1. 强相关的文档出现在结果列表越靠前越有用;2. 强相关文档比弱相关文档有用,同样弱相关文档比不相关文档有用。通常用在衡量搜索引擎或推荐系统的结果列表的质量。
4.4 结果分析
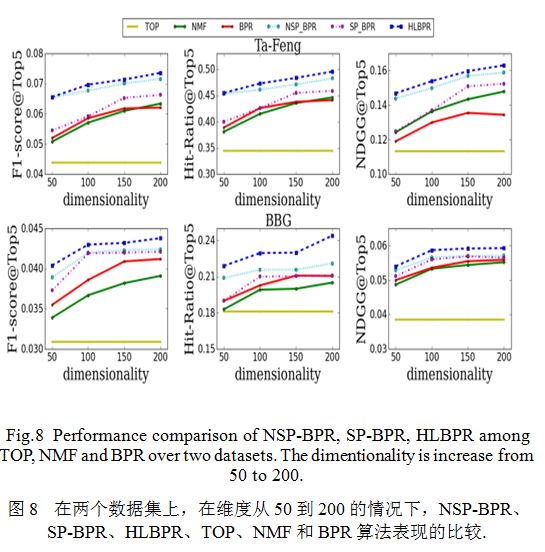
我们在图8中展现了在数据集Ta-Feng 和BBG的实验结果。我们对实验结果简要分析如下:
(1)TOP-POP方法由于对不同的用户推荐同样的物品,而根本没有考虑到不同用户的不同兴趣,因此在各项指标的表现上都是最差的。
(2)传统的BPR算法由于直接优化用户对不同商品的排序,因此其效果优于矩阵分解NMF算法。
(3)我们的模型NSP-BPR,SP-BPR,HLBPR在各项指标上均超过传统的BPR算法。其中NSP-BPR在两个数据集上的表现均好于SP-BPR,这说明我们的数据集表现出的时间序列特征没有非时间序列特征明显。由于同时考虑了两种特征,因此我们的混合模型HLBPR表现的比前面的两种模型都好。
(4)和传统的BPR相比,我们最终的混合模型HLBPR在Ta-Feng和BBG两个数据集上的F1值分别提升了19.79%和9.2%。
5 结论
本文为了解决传统BPR中数据稀疏的问题,首先利用时间序列和非时间序列模型来构建额外的pair,然后我们将这两种模型进行混合以提升最终的推荐精度。在未来的工作中,我们将主要关注于两个方面,一方面是利用更多的方法来构建更多的商品偏好对。从而进一步缓解数据稀疏的问题。另一方面,探索更加有效的结合不同模型的方式。
参考文献:
C. Chand, A. Thakkar, and A. Ganatra. Sequential pattern mining: Survey and current research challenges. International Journal of Soft Computing and Engineering, 2(1):185-193, 2012.
L. Lerche and D. Jannach. Using graded implicit feedback for bayesian personalized ranking. In Proceedings of the 8th ACM Conference on Recommender systems, pages 353-356. ACM, 2014.
C.-b. Lin. Projected gradient methods for nonnegative matrix factorization. Neural computation, 19(10):2756-2779, 2007.
R. Pan, Y. Zhou, B. Cao, N. N. Liu, R. Lukose, M. Scholz, and Q. Yang. One-class collaborative filtering. In Data Mining, 2008. ICDM'08. Eighth IEEE International Conference on, pages 502-511. IEEE, 2008.
S. Rendle and C. Freudenthaler. Improving pairwise learning for item recommendation from implicit feedback. In Proceedings of the 7th ACM international conference on Web search and data mining, pages 273-282. ACM, 2014.
S. Rendle, C. Freudenthaler, Z. Gantner, and L. Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, pages 452-461. AUAI Press, 2009.
S. Rendle, C. Freudenthaler, and L. Schmidt-Thieme. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th international conference on World wide web, pages 811-820. ACM, 2010.
P. Wang, J. Guo, Y. Lan, J. Xu, S. Wan, and X. Cheng. Learning hierarchical representation model for next basket recommendation. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 403-412. ACM, 2015.
G.-E. Yap, X.-L. Li, and S. Y. Philip. Effiective next-items recommendation via personalized sequential pattern mining. In Database Systems for Advanced Applications, pages 48-64. Springer, 2012.
Y. Zhang, M. Zhang, Y. Zhang, Y. Liu, and S. Ma. Understanding the sparsity: Augmented matrix factorization with sampled constraints on unobservables. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, pages 1189-1198. ACM, 2014.
T. Zhao, J. McAuley, and I. King. Leveraging social connections to improve personalized ranking for collaborative filtering. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, pages 261-270. ACM, 2014.
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
