




















新闻事件层次话题模板构建
摘要:随着信息化发展,人们急切需要有效的新闻文章组织方式,让日常的新闻阅读变得轻松便捷。已有的研究方法如话题模型能够将新闻文章按照不同话题进行聚类,然而这类无监督的模型得到的话题类语义不明确,准确率低。本文提出了一种对特定类的新闻事件构建高质量层次话题模板的方法,为新闻的层次分类提供依据,也方便了人们对这类新闻事件的总体认识。具体来说,本文利用了新闻事件对应的维基百科的目录结构(蕴含话题层次),通过对一类事件的维基页面的目录进行融合,得到这类新闻事件的层次话题模板结构。实验证明,与基线方法对比,我们方法在话题层次构建准确度上有7%-25%的提高。
关键词:层次话题;维基百科;目录结构
1. 介绍
随着国家信息化的飞速发展,在线新闻阅读已经变成人们获取信息的重要来源之一。然而当一个事件发生时,来自不同媒体的新闻蜂拥而至,人们迫切需要一种有效的新闻组织方式,方便自己找到感兴趣的新闻内容。已有的研究主要利用话题模型如LDA(Latent Dirichlet Allocation)挖掘新闻的话题,并将新闻按照话题进行聚类。然而,这类模型是无监督的,得到的新闻话题没有明确的语义,新闻聚类的准确度不高。本文提出了一种利用维基百科构建新闻事件话题层次模板的方法,为新闻层次分类提供了依据,也为用户提供了关于这类事件的概览。
维基百科作为一种自由开放并由世界各地的人们通过互联网合作编写的百科全书,提供了大量的高质量的信息:数以千万计的维基页面涵盖了各种事物和概念。如今,中文维基百科、百度百科和互动百科作为最流行的中文在线知识库,收录了累计将近3000万条中文条目 。除了被用以获取人们所需知识外,它还被广泛地应用在知识获取研究中。维基百科页面的信息框包含了结构化的属性-属性值信息,被用于属性抽取和知识图谱构建[1][2]。

然而,除了信息框,维基页面的目录表也提供了不同粒度的层次话题知识。如图1所示,“2010海地地震”维基页面“目录”中每个标签代表了一个话题,其对应的文本描述就是对话题的相关描述。目录的层级关系代表了话题之间的层次关系。维基百科中有大量的包含这些高质量的话题信息的新闻事件页面,我们可以利用相似新闻事件的维基页面构建这类新闻事件的层次话题模板。这样的层次话题模板不仅对这一类事件(如地震事件)的所有话题及话题之间的关系进行了总结,而且对于搜索与浏览、信息组织和检索等应用也有很大帮助[6]。虽然维基百科中也有类别(如地震)对应的维基页面,但是该页面的目录所蕴含的层次话题是粗糙的并且不完整的。利用大量不同的具体事件(如2010海地地震,2010智利地震等)对应的维基页面构建关于该类事件(地震类事件)的层次话题使得信息相互补充,能够得到更高质量更全面的层次话题模板。
融合多个维基页面的目录结构构建层次话题模板是非常具有挑战的。首先,不同的维基页面目录的话题标签可能表示相同的话题,如:“国外援助”和“来自其他国家的援助”。其次,不同维基页面目录的话题-子话题的关系可能存在冲突。如“灾后情况”->“响应”和“响应->灾后情况”。最后如何同时利用已有的话题标签之间的结构信息和话题标签的描述文本信息?
本文,我们提出了一个新的构建高质量层次话题模板的方法。我们用贝叶斯网络对层次话题进行建模,将构建层次话题的问题转变为结构学习问题。通过同时考虑结构信息和文本信息,提高了层次话题的精度。实验证明我们的方法比基线方法在层次话题模板的精度上提高了7%-25%。
2.问题定义
本节给出层次话题模板构建的问题的相关概念定义,并对给出问题的形式化描述:
定义 1. 类别。根据维基百科中的定义1,类别c是用于聚集相似主题的维基页面A_c={a_i }_(i=1)^N。例如,“地震”、“选举”等都可以称为类别。
定义 2. 层次话题。对于维基页面a_i,其目录对应了一个层次话题结构H_i=(T_i,R_i),其中T_i是页面包含的话题标签所表示的话题集合,R_i表示这些话题之间的层次关系。注意标题也属于T_i,是H_i的根节点。
定义 3.层次话题模板。对于类别c,融合其包含的所有维基页面对应的层次话题得到的最终层次话题结构为该类别的层次话题模板H_c=(T_c,R_c),其中T_c={t}是话题集合,R_c表示这些话题之间的层次关系。注意,由于维基百科是众包的,话题t可能对应不同维基页面的多个话题标签。层次话题模板以c为根节点。
问题定义:层次话题模板构建是指给定类别c以及其对应的维基页面A_c={a_i }_(i=1)^N,我们需要融合这些页面的目录对应的层次话题结构H_i=(T_i,R_i),得到一个综合全面的层次话题模板H_c=(T_c,R_c)。
3. 层次话题模板构建
给定类别c,建立层次话题模板H_c=(T_c,R_c)的框架可以描述为:
话题标签聚类:对于两个话题标签g_i,g_j,我们可以根据计算其相似度sim(g_i,g_j),然后对标签进行聚类,一个类对应一个话题t。所有标题聚成一类,以根节点c替代。
层次话题模板构建:从上一步得到的话题集{t}中推导出话题之间的层次关系,从而得到层次话题模板。
3.1 约束增量聚类算法
本小节介绍了将不同维基页面的话题标签聚类得到最终层次话题模板中的话题的方法。考虑到同一个维基页面的话题标签通常是被人们用来表示不同的话题,因此我们采用了一种带约束的增量聚类算法(CIC, Constrained Incremental Clustering),只将不同页面的话题标签进行聚类。当然,很多已有的其他聚类算法如kmeans等也可以用来做话题标签聚类,由于我们的重点是后面一步得到话题层次关系,因此我们对此不过多讨论。
增量聚类算法主要基于相似度,通过计算话题标签和已有标签类的相似度,将标签放到相似度最大(并且大于一定阈值δ)的标签类,否则该标签单独成为一个新的类。计算两个话题标签的相似度可以考虑以下几个因素:
词汇相似度。每一个话题标签g是由一些单词构成的序列所组成的短语,我们可以将g堪称是单词集合,通过如下方法来计算两个标签g和g^'的词汇相似度:
![]() ,即,两个标签的匹配词数除以两个标签的平均词长度[16][16]。
,即,两个标签的匹配词数除以两个标签的平均词长度[16][16]。
上下文相似度。对于每一个标签g计算它的描述文本d_g上的所有单词词频分布?_g。然后使用两个标签的词频分布来计算余弦相似度作为上下文相关度。
Wordnet相似度[6]。计算两个话题标签在wordnet中的距离。
综上,考虑所有因素,我们对所有相似度加权平均得到两个标签的最终的相似度值。基于标签相似度的计算,计算话题标签g和一个话题标签类t之间的相似度sim(g,t)有三种不同的方式:1)最近距离:取标签g与t中所有话题标签相似度最小的值作为两者相似度;2)最远距离:取标签g与t中所有话题标签相似度最大的作为两者相似度;3)平均距离:取取标签g与t中所有话题标签的相似度平均值的作为两者相似度。通过实验,我们发现取最远距离方式能取得最好的聚类效果。
3.2 层次话题模板构建
根据上一步中得到的话题集T_c,下面根据结构信息去构建层次话题结构![]() 。
。
3.2.1基本方法
一个基本的方法是构建一个有向完全图,图中的每个节点代表一个话题,话题之间的有向边(如t_i→t_j)表示子话题关系(t_j是t_i的自话题),每条边赋予权值。基本的权值计算方法是将每个维基页面的话题标签用其所属话题替代,将包含该边所蕴含子话题关系的维基页面数量当成该边的权重。
最后利用基于图的最大生成树算法 Chu-liu/Edmonds [3]构建最大生成树,最后得到的树形结构即为我们最终的层次话题模板H_c=(T_c,R_c)。Chu-liu/Edmonds是一个贪心算法,主要有两步:第一步是选择入边,第二步是打破环状结构。我们维护了一个最大权重入边集M,一开始M为空。Chu-liu/Edmonds算法选择任意一个在入边集中没有入边的节点,找到该节点的最大权重入边,并加入到M。重复该步骤直到M中出现环,然后将环看成是一个伪节点,继续往M中加入最大权重入边,直到没有点剩下,通过移除环中的最小权重边打破环。具体算法可以参考文献[3]。
然而上述这种方法有一个问题。考虑以下情况:如果1->3在维基文章中出现5次,2->3出现2次,而1总共出现50次,而2总共只出现2次,那么我们更倾向于2->3(置信度: 2/2=1)而不是基本方法得到的最终得到的结果1->3(置信度: 5/50=0.1)。在下一节中我们将用一个概率的方法来解决这个问题。
3.2.2 基于贝叶斯网络的方法
我们考虑将一个层次话题结构看成是一个贝叶斯网络,话题是网络中的节点变量,那么给定层次结构H,该网络的联合概率分布可以写成:
![]()
其中,P(n│par_H (n) )是在给定父节点par_H (n)下的条件概率。公式(1)实际上是层次结构H的似然函数,最大化该似然函数可以得到最优的层次结构H^*:
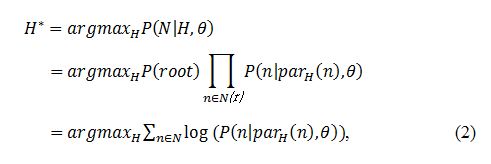
考虑结构信息:如果t_i→t_j,t_j是t_i的子话题,我们可以定义条件概率:

其中n(t_i→t_j)是包含关系t_i→t_j的维基页面数,而n(t_i )是包含话题t_i的维基页面数。α是平滑系数,防止分母为0。
考虑文本信息:考虑到每个话题包含的话题标签都有一段文本描述,把所有标签的文本描述聚集到一起是该话题对应的文本描述。我们可以把每个话题的文本描述当成一个词袋,这样每个话题可以表示成在词上的分布,φ_t=〖{φ_(t,w)}〗_(w∈V), s.t. ∑_(w∈V)?〖φ_(t,w)=1〗。为了捕获子话题关系,我们期望子话题的分布的期望等于父亲话题的分布,即E(φ_(t_j ) )=φ_(t_i )。这就自然地导致了层次狄利克雷分布,即φ_(t_j ) |φ_(t_i )~Dir(βφ_(t_i )), 其中β是聚集参数。这样,我们能够得到:

其中Z是归一化因子。
同时考虑结构和文本信息:如果直接将公式(3)带入公式(2),我们可以得到只考虑结构信息获得的权重![]() 。这样能够解决基本方法存在的问题,然而却没有考虑重要的话题文本描述信息。因此,我们将公式(4)带入公式(2)可以计算基于文本的权重
。这样能够解决基本方法存在的问题,然而却没有考虑重要的话题文本描述信息。因此,我们将公式(4)带入公式(2)可以计算基于文本的权重![]() 。
。
同时考虑两种因素,我们对两种情况获得的权重进行加权平均,得到最终的权重:
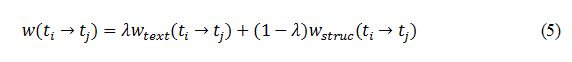
注意,两种情况获得的权重在加权平均之前都要进行归一化。在得到所有边上的权重之后,我们就可以采用最大生成树算法Chu-liu/Edmonds算法得到最后的层次话题模板。
4. 实验结果与分析
本文通过和人工构建的标准集进行对比来检验所提出的层次话题模板构建方法。我们首先测试本文提出的话题标签聚类算法CIC,然后测试层次话题模板的准确度。实验代码已经公开在GitHub上:https://github.com/Observerspy/CH_Topic_Hierarchy。
4.1 实验数据
我们在三个真实数据集上评估了我们的方法。这三个数据集分别是英文维基类别“地震”和“选举”,中文维基类别“地震”。三个数据集包含了293,60和48篇相关维基页面。去掉噪音话题标签如“参考文献”、“引用”、“相关链接”等,三个数据集分别包含463,426和79个话题标签。我们首先评估CIC的聚类效果,之后我们评估层次话题模板的准确度。
4.2 话题标签聚类评估
这一部分里,本文对3.1中提出的CIC聚类算法进行评估。通过人工标注构建了标准的话题标签集。
实验使用Adjusted Rand Index (ARI)和Adjusted mutual information (AMI)这两个指标来评估聚类结果。ARI是Rand Index的一种变形[18], AMI同样也是mutual information的变形。这两个值越大,说明聚类效果越好。
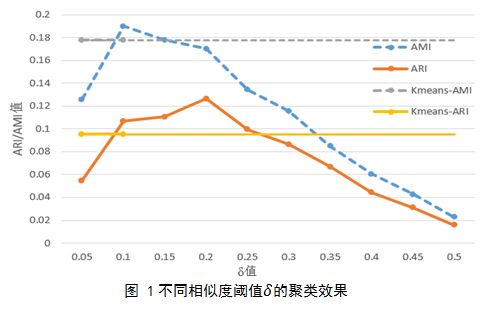
实验采取加权平均的方式对词法、上下文语义以及wordnet相似度三种相似度特征进行加权平均。实验发现权重分别取0.2,0.7和0.1时,采用最远距离方式计算一个话题标签到一个话题标签类的距离能够得到最优的聚类结果。在这些参数设置下,实验在图1中给出了对于不同的阈值δ数据集一(英文地震数据集)的聚类评价。当δ=0.1时AMI最大,当δ=0.2时ARI值最大,然而在δ=0.1时两个值都要超过K-means算法取得的结果。因此我们可以去取阈值为0.1,对于另外两个数据集,我们用相同的方法可以确定为阈值分别取0.2和0.25。聚类之后,三个数据集分别有176, 112和57个话题。实验证明了我们提出的CIC聚类方法的有效性,并且优越于K-means算法。
4.3 评估基于贝叶斯网络的层次话题归纳
同样地,我们通过人工标注构建了标准层次话题模板。我们找了三个大学生进行标注,每个子话题关系必须两个人确定才被采用。一个简单的标注方法是,给定我们生成的层次话题模板,让三个标注者独立进行修改得到最终的层次话题模板。本节从准确率、召回率两方面对基于贝叶斯网络的层次话题模板进行评估。
本文使用R_c和R_S来分别表示实验结果的子话题关系集合和标准的层次话题模板的子话题关系集合。由于|R|=|R_s |,因此准确率=召回率=F1=|R_c 〖∩R〗_s |/|R| 。
我们对比三种方法,一种是基本方法Basic,一种是我们提出的只考虑结构信息的贝叶斯网络方法Baye+S,最后一种既考虑结构信息和文本信息的贝叶斯网络方法Baye+ST。
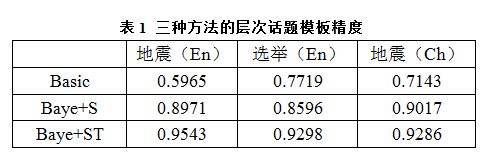
表1中给出了三个方法构建得到的层次话题模板的准确度,我们发现基于贝叶斯网络,既考虑结构信息又考虑文本信息的方法Baye+ST(取最好的λ值)显著好于只考虑结构信息的贝叶斯方法Baye+S(+24.3%,p<0.025,t-test)和基本方法Basic (+5.1% p<0.025,t-test)。对结构信息进行归一化的方法Baye+S也比直接利用结构信息的方法Basic显著提高了层次话题模板的精度(+19.2%,p<0.025)。
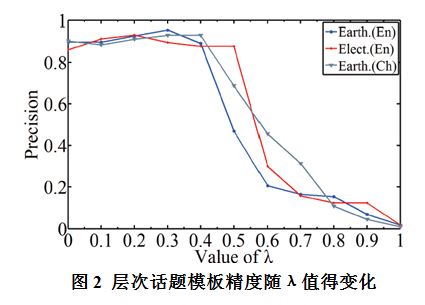
我们进一步研究了我们的方法Baye+ST受λ值的影响。可以看到,在0.2≤λ≤0.3区间,我们的方法总能够获最好的结果。当λ 趋近1, 精度降低很快,接近0,原因是有一些噪音的topic标签没有描述文本信息。如果我们多依赖结构信息,以文本信息为辅,我们可以有效提高层次话题模板的精度。
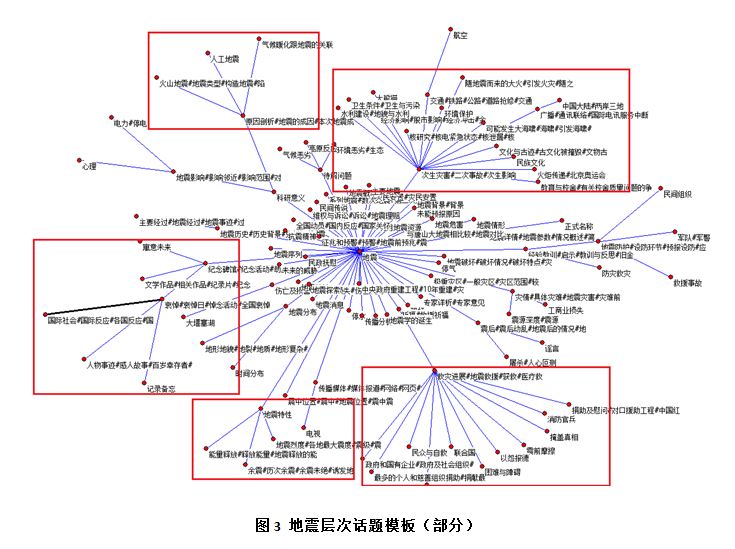
最后,我们在图3中展示了中文地震数据集上的层次话题模板。从中可以看到,根结点 “地震” 包含“次生灾害”、“救灾进展”、“地震特性”等子话题。话题“地震特性”的子话题“地震烈度”、“能量释放”等,“救灾进展”包含“民众与自救”、“困难与障碍”、“捐助及慰问”等。本文将这些提及的关系在图中用红线表示。总体而言,该地震层次话题模板符合人们的常识。
5. 相关工作
据我们所知,我们的研究问题是新的,还没有工作研究如何利用维基页面的目录结构来构建层次话题模板。已有的工作主要集中在如何从文本档中自动构建层次话题[8-12],主要基于层次聚类方法[7]和层次话题模型如HLDA[10], HPAM[11], hHDP[12]。和这些工作不一样,我们利用了维基页面的目录以及目录中标签的文本描述信息。
我们的工作还和已经被大量研究的本体构建[4-5][13-15]不一样。本体构建主要是构建概念层次,是is-a关系,而不是话题上的层次关系。举例来说,给定“动物” 这个类别,他们是构建“猫”和“狗”这样的子类。而我们是构建“动物保护”和 “动物灭绝” 等这样的子话题。我们的工作对于人们了解一个不熟悉的类别有重要的意义,同时我们的工作还有助于提高信息检索等重要应用。
6. 结论
本文提出一个新的问题,即层次话题模板的构建,该问题旨在充分利用维基知识库,构建高质量层次话题模板。我们提出了一个新的方法既考虑了已有的结构关系和话题的文本信息来推导出最优层次话题结构。实验结果表明了方法的有效性。在今后的研究中,我们将研究如何随着新的维基页面的建立,自动得逐步更新层次话题模板。
参考文献
Fei Wu and Daniel S Weld. Automatically refining the wikipedia infobox ontology. In Proceedings of the 17th international conference on World Wide Web, pages 635–644. ACM, 2008.
Fei Wu, Raphael Hoffmann, and Daniel S Weld. Information extraction from wikipedia: Movingdown the long tail. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 731–739. ACM, 2008.
Jack Edmonds. 1967. Optimum branchings. Journal of Research of the National Bureau of Standards B, 71(4):233–240.
Rui Li, Shenghua Bao, Yong Yu, Ben Fei, and Zhong Su. Towards effective browsing of large scale social annotations. In Proceedings of the 16th international conference on World Wide Web, pages 943–952. ACM, 2007.
Vivi Nastase and Michael Strube. Decoding wikipedia categories for knowledge acquisition. In AAAI, pages 1219–1224, 2008.
Ted Pedersen, Siddharth Patwardhan, and Jason Michelizzi. Wordnet: Similarity: measuring the relatedness of concepts. In Demonstration Papers at HLT-NAACL 2004, pages 38–41. Association for Computational Linguistics, 2004.
Shui-Lung Chuang and Lee-Feng Chien. A practical web-based approach to generating topic hierarchy for text segments. In Proceedings of the thirteenth ACM international conference on Information and knowledge management, pages 127–136. ACM, 2004.
David M Blei, Thomas L Griffiths, and Michael I Jordan. The nested Chinese restaurant process and Bayesian nonparametric inference of topic hierarchies. Journal of the ACM (JACM), 57(2):7, 2010.
Chi Wang, Marina Danilevsky, Nihit Desai, Yinan Zhang, Phuong Nguyen, Thrivikrama Taula,and Jiawei Han. A phrase mining framework for recursive construction of a topical hierarchy. In Proceedings of the 19th ACM SIGKDD, pages 437–445. ACM, 2013.
DMBTL Griffiths and MIJJB Tenenbaum. Hierarchical topic models and the nested chinese restaurant process. Advances in neural information processing systems, 16:17, 2004.
David Mimno,Wei Li, and Andrew McCallum. Mixtures of hierarchical topics with pachinko allocation. In Proceedings of the 24th ICML, pages 633–640. ACM, 2007.
Elias Zavitsanos, Georgios Paliouras, and George A Vouros. Non-parametric estimation of topic hierarchies from texts with hierarchical dirichlet processes. The Journal of Machine Learning Research, 12:2749–2775, 2011.
Shui-Lung Chuang and Lee-Feng Chien. A practical web-based approach to generating topic hierarchy for text segments. In Proceedings of the thirteenth ACM international conference on Information and knowledge management, pages 127–136. ACM, 2004.
Xingwei Zhu, Zhao-Yan Ming, Xiaoyan Zhu, and Tat-Seng Chua. Topic hierarchy construction for the organization of multi-source user generated contents.In Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval, pages 233–242. ACM, 2013.
Roberto Navigli, Paola Velardi, and Stefano Faralli. A graph-based algorithm for inducing lexical taxonomies from scratch. In IJCAI, pages 1872–1877,2011.
Alvaro E Monge, Charles Elkan, et al. The field matching problem: Algorithms and applications. In Proceedings of the 2nd ACM SIGKDD, pages 267–270, 1996.
Yoeng-Jin Chu and Tseng-Hong Liu. On shortest arborescence of a directed graph. Scientia Sinica, 14(10):1396, 1965.
Nguyen Xuan Vinh, Julien Epps, and James Bailey. Information theoretic measures for clusterings comparison: is a correction for chance necessary? In Proceedings of the 26th Annual International Conference on Machine Learning, pages 1073–1080. ACM, 2009.
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
