




















������ʱ���������������ݴ�������Ӧ��
ժ Ҫ��Web2.0��������Ϣ�����ĸ����Ա���Ϣ�����������������˼�ʱ�ԡ������Ե��ص㡣������Ϣ�����ա����������ã������ı��ھ������������۵���Ϣ��ȡ������˵�ǽ��������ȵ��������ص�̽�����������о��н�ǿӦ���Ե����ַ������������ȡ����������������������Լ����ǿ�ȷ����������ַ��������Լ�����ı��ھ�Ϊ����֧�֣�������ѧ������ѧ��Ӫ��ѧ�Լ����ѧ�о��о��н�ǿӦ���Ե�����
�ؼ��ʣ��������ۣ��ı��ھؼ�����ȡ������������������
һ���ı��ھ�ĸſ�
1.�����
�������Բ��������������ǿ��Ĺ��ܣ������������������ļ�������ʮ�������ƶ�������������dz���ָ����������[1]����Web2.0���»����£����ڻ�����������ƽ̨������̳�������š�QQ�����繺����ҵƽ̨�����п���ƽ̨��Ϊ�����Ϣ������Щ��Ϣ���������ݴ洢���Ѿ���TB��������PB���𣩣����������˼�ʱ�ԡ������ԡ������Ե����ԣ���ͳ�������ռ�����Ҫָ�ṹ�����ݣ�����������������������dz����ޣ�ҲӰ������Ч�����������۵�Ч�����м��ڴˣ��ӷ����ӵĺ����ǽṹ�������У��ھ���ȡ�м�ֵ����Ϣ��÷dz���Ҫ��������Web2.0���ı��ھ�������Ӫ���������������ϣ����ھ��ߺ�δ�����Ƶ�Ԥ�����ܹ��ṩ�������ͷḻ����Ϣ���ı��ھ����ڴ����ݷ�֧����ʮ�����ڼ䣬������Ӧ�ø����ᵽ�ˡ�������ҵ����ת�ͺ�����������¡��ĸ߶�[2]��Ŀǰ���ǿ��������״����ڼ����������ѧ�о���ͬ�㷨��ԭ��������������㷨�����Ż�ԭ���㷨���ھ�ȷ���ϲ��ϸĽ�������ҵ���������ϣ�����ͻ���Ʒ����Ӫ���ϣ����������������ƽ̨�����Ŷ��������ݷ����������ھ��Ѿ��Ƚϳ��졣��������ѧ�����У����紫��ѧ������ѧ�����ѧ���������ͳ�ij������飬���Ӧ���µ���ᷢչ��̬���Ż��������ģʽ�������ı��ھ���������չ�о�������о�������������Ҫ�����塣���������ڻ�������Ϣ��ֱ�������û�����̬�ȡ���У���Щ��Ϣ��������ô�����������������ģ������ı��ھ����Իش���Щ���⡣
2.�ı��ھ���ص�ͷ���
�������������ı���Ϣ���ı��ھ�Ҳ��Ϊ�ı����ݿ��е�֪ʶ���֣��ǴӴ����ı��ļ��ϻ������Ͽ�����ȡ����δ֪�ģ������������DZ��ʵ�ü�ֵ��ģʽ��֪ʶ[3]���ڴ�����Ӧ����ҵ������������棬���Ǹ����ص��Ǿ�Ԥ�⡣�����������ڷǽṹ�����ݣ���������ھ���Ҫ��Է���ʵ�������ı�����֮��������ص㣬�����������������ı��ھ���Ѷȣ������ı��ھ����������㷨�;�ȷ�ȷ��滹�ڲ���̽�����������ԣ��ı��ھ�ķ�����Ҫ�������ĸ����棺��1���ִʼ��������ķִ�ʱ������Ϣ�����Ļ����������п�Ժ��ICTCLAS�ִ�ϵͳ�����ṩ���Ա�ע���´�ʶ���û��ʵ�ȣ��ǿ�Դ�ִ�ϵͳ����2����Ϣ��ȡ������������Ϣ��ȡ��Ŀ���dz�ȡ��ָ�����¼�����ʵ����Ϣ���û���ѯʹ�á������ű����е�ʱ�䡢�ص㡢�����ϵ���¼������������Ƿ������������������ϵı���ȡֵ֮�����ij�ֹ�����ʱ������������������3������������ҳ����������ݷ����ģ�ͣ��Ա��ܹ�ʹ��ģ��Ԥ��������ݶ��������������ࡣ���磬�ƾ����š�������ŵ����Ź鵵��Ӧ�ã�������ģ�ͣ������������ٽ��ĵ�ͨ����������Ϊij����𣻣�4�������������������������ļ��Ϸ����Ϊ�����ƵĶ�����ɵĶ���������̡�����Ŀ����������ƵĻ������ռ����������ࡣ����ͼ�������г�ȡ�á�һ�㡢�Ƚϲ�ȡ�
�����ı��ھ�ļ���ʵ��
�ı��ھ������ڼ��������ѧ��ѧ�ƣ��о���Ҫ�������о��������棬���н����ִʷ������㷨����ʮ���֡�Ŀǰ���ı��ھ�����ڲ�ͬ�����е�Ӧ�ã�����������������ҵ�������������С�Խ��Խ������Ի��������Ŀ�Դϵͳ�ͽ����Ѻõ������ھ���������KNIME���Լ�������վ��ɭ��ֻ��Ҫ���ϡ�����ק���Ϳ���ʵ�ֲ��ֵ������ھ�����Խ��Խ�����ҵ���������������ʹ���ı��ھ�����Ҫ�������ı��ؼ�����ȡ����������������������Ӧ�÷����Լ��û�������������������Ӧ��ͨ���ı��ھ����ʵ�֣��������£�
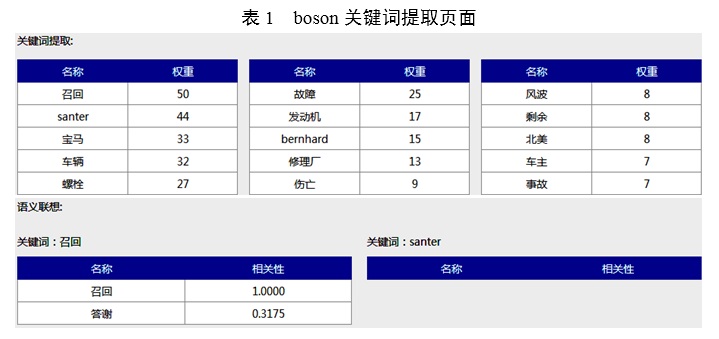
1.�ı��ؼ�����ȡ������ѧ�еı����������иſ����ܽ�Ĺ��ܣ���Ҫ���Ŵ�ҵ���߶��߿���ȫƪ�ٹ���������������ժҪ����ô�ں����������У���ȫ��������µ�����˼��Ļ����ϣ�Ѹ�٣�ÿСʱ���ٴ���50��ƪ���£���ȡ�����ɸ����������������ݵĴʻ������ؽ�������ھ����Ķ�����������2015�����ǿ�����������������棬���ݷִʼ��������Ƶ��������ȡ���г������ĸ�ȹؼ��ʡ���Щ�ؼ��������ܷ�ӳ����������������������������������ھ�KNIME������Orange�����⣬�������������ھ���վ��ɭ�������忪��ƽ̨��http��//bosonnlp.com/demo�����Խ��зִʴ������ؼ�����ȡ���γ�����ժҪ����1��Boson���ݱ������ٻ������γɵĹؼ�����ȡҳ��[4]��
2.�������Ӧ�á��ں�����������Ϣ�����£��������ٵ����ⲻ����Ϣ�ѷ���������Ϣ���غ���Ϣ�������������ǹ�ע�������Ѵ������ɼ�����Ϣ��Ϊ����Ϊ������Ϣת����������Ϣ��ȡ���ٶȺ���������������ϵͳ��������������ϵͳ����Ҫ��������Ϣ�����Զ��ɼ����ı��Զ�������Զ����ࡢ��������١�Ŀǰ���������Ҫ��������Ϣ�ɼ����ȵ����ⷢ�ֺ��ȵ�����[5]����Ϣ�ɼ���Ҫ������Python�Լ�Heritrix��web�����͡��ʼ������Ȳɼ����ݣ��洢��PostgreSQL���ݿ��У��ٽ���������ȡ�ȡ��ȵ����ⷢ�ּ�����Ҫʹ���ı���������İ취�������������ȵ㡣�ȵ��¼���ȡ������Ҫ�����ȶ������ݽ���Ԥ������ȥ��������������Ϣ���ı������кܶ��㷨����Դ�ͳ��Single-pass��K-means����Ƚ�����[6]�����鴦�������������ľ���ͷ��ദ�����ؼ�����Ҫ�õ��ִ�ϵͳ��Python���Ե����jieba�ʰ����ٽ�ϸ�������Ĵʿ����ʵ�֡�
3.���������������Ľ���Ӧ����������������������������ʵ��KOL��Key Opinion Leade�����������ң�KOL����Ϊ��������ߵ�ʶ����Ӱ�����ϴ���û�������������ڶ�ʱ���ڶ������ڶ���û�����ֱ�ӻ��ӵ�Ӱ�졣��ˣ��ھ���������Ϊ�˽���罻����������ʵ������Ĺؼ��㣬����������е������������ر��Ǵ���ѧ�����е���������о�����ͼ1��ʾ�����ر��ǽ���������ҵ�ϱȽ����ŵĹ��Ͷ�ź��̿�չ�������û����Է����������������ھ���Ҫ���ݹ�ע�ȡ���˿�����������Լ��Ƿ���֤���û���Ҫ�Խ������֣��Թ�ϵΪ������λ�������������������������ʶ����Ӧ��Խ��Խ�ࡣ����������˷dz�������۳ɹ��������������ߣ�������������硢�������硢С�������۵ȣ�Ucinet����Ҫ�������ݵĹ��������������������Ŀ��ӻ���������Netdraw��������չ�֣������������������˻������������Ƚϼ�
4.��������Է�������Ҫָ�����û����۷�������Ҫ��̬�ȡ����۵ȼ��IJ������������£�ץȡ������ϣ��乤����Ҫ��Python�������棬���Ƿdz��Ӵ�ĺ������ݣ���ԭʼ���ݴ洢��PostgreSQL���ݿ��С�������ԭʼ�������кܶ�������Ϣ���ظ����۵���Щ����������Ч��Ϣ������Ҫ��������Ԥ��������PostgreSQL���ݿ�ת�����ı���ʽ��txt����ʽ�ļ�������ͣ�ôʱ����й���������Ԥ����֮��ʼ���зִʴ�����ֻ�н��зִʼ���������ҵ��ؼ��ʺ������ʣ��ִʼ����ͷִʷ����Ѿ��Ƚϳ��죬ҵ��ʹ�ñȽ϶�����ķִʹ�����ICTCLAS���ķִ�ϵͳ[8]���ִʹ��߳��õ���jieba��Ansj�������ǽ�����������ͨ���ִ��ҵ�����ʣ����繺��ƽ̨�ϵķ�װ���ۣ������п�ʽ��������������������ʣ��������������ʹ��Word2Vec���д�����࣬�������������Ĵʹ�Ϊһ�࣬������Ԥ������Ŀ������Ͽ��а�ʱ�С����еȹ�Ϊ��ʽһ�࣬����Ʒ������ɫ�ȷ�������һ�࣬�ѿ顢��ʱ��������һ�ࡣ֮��ֱ����HowNet��дʵ乹���ͳ̶ȼ���ʵ乹���Լ��ʵ乹�����ٽ�������ʷ��࣬����ó�������������û�����������ֱ�ó����������ݡ��������������ͼ1��ʾ����
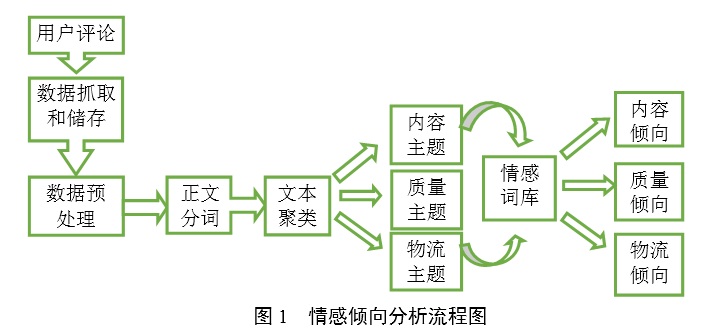
������Ҫ˵���������ı��ھ���Խ���ʹ�ã�����������������۵�����Է���������ͨ�����������ֲ���ʵ�֡����������ַ�����������������ȡ���洢���ִʡ�
����̽�ֺ��ܽ�
���������ھ����ڸ�������IJ�����չ�����룬ʵ�������У��ı��ھ�����չ���������Ӧ�ã����������ڱ����оٵ����֡������ݱ�����������е�˼ά��ʶ�벻�������ھ��������ʹ�ã����ı��ھ����һ���̶���ʵ�ָ����˵ļ������ܣ�����Ҫ������ŶӺ���������Ҫ�����и����רҵ���棬��������Ӧ�ú����ѧ������ѧרҵ��������ѧ�Ľ��档
�ο����ף�
[1] �й�����������Ϣ���ģ�CNNIC��������37�Ρ��й��������緢չ״��ͳ�Ʊ��桷:����2015��12��,�й������ģ�ﵽ6.88��,�������ռ��ʴﵽ50.3%,�ֻ������ģ��6.20��,��90.1%������ͨ���ֻ�����.
[2] ����2016.3�¡����ú���ᷢչ��ʮ��������滮��Ҫ���ڶ�ʮ����:�����Ҵ�����ս�ԡ�
[3] �Ѷ�����.�ı��ھ�[M].����:�����ʵ��ѧ������,2009.
[4] http://www.chinadaily.com.cn/hqgj/jryw/2014-04-15/content_11593048.html.
[5] ������,�ž�,���D.�������Ļ������ȵ��о�����[J].����ѧ��,2012,9(6):874-879.
[6] ����.�����ݻ������������[J].�ִ��鱨,2014,34(3):3-6.
[7] ����,������,������.ͨ�����������������ھ��о�[J].�鱨������ʵ��,2012,35(4):103-108.
[8] ��־��,��³.���ڻ���ѧϰ����������з���ʵ֤�о�[J].�����������Ӧ��,20112,48(1)1-4.
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
��������
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
