




















基于seq2seq模型的中文纠错任务
摘要
用户通过键盘或者语音输入文字的时候,会遇到大量的错误,这些错误给用 户的使用带来了不便。而随着智能手机的普及,用户越来越多的使用触屏来进行 文字的输入,这使得问题进一步严重。深度学习近来在自然语言处理领域获得了 广泛运用,seq2seq 模型在诸多自然语言处理任务,如词性标注、语义依存分析、 机器翻译等,均取得了显著的成绩。本文首先对中文纠错任务进行详细的梳理, 包括错误的来源、目前的处理方法、相关的公开竞赛、数据源等;第二,由于缺 少大规模公开的数据集,本文涉及显示人工构造大规模纠错数据集的算法;第三, 本文将深度学子中的 seq2seq 模型引入,处理中文纠错任务,在基本的模型基础 上引入 attention 机制(包括诸多变种)以及多任务学习的理念,尝试多种组合, 并最终在构造数据集上 GLEU 评分达到了 0.75。
关键词
语义识别;大数据;深度学习;中文纠错;sequence to sequence learning;多任务学习
一、问题定义
用户输入一个中文句子,模型自动发现并改正句子中存在的问题。如“实现 供应与发展”句子中的“供应”改为“共赢”。
二、项目背景
根据目标用户、错误来源的不同,纠错系统可以分为多种类型,下面进行详 细的阐述。
1. 目标用户
纠错有两个主要的目标用户群体:非母语学习者以及母语使用者。 所谓非母语学习者,指的是……。针对非母语学习者,有两个代表性的公开比赛,分别是 CoNLL 以及 SIGHAN Bake-off。CoNLL 比赛任务在 2013[1]以及 2014[2] 年的时候针对英文的语法纠错任务展开。CoNLL 2013 限定了错误的类型,包括 冠词、介词、名词单复数、动词形式以及主谓一致等;CoNLL 2014 则直接处理所 有的错误。SIGHAN Bake-off 2014[3]、2015[4]均针对母语非汉语的学习者,但是 一个问题在于并没有涉及到语序问题,只考虑了拼写错误。
针对母语使用者,英文的比赛有一些,而中文则较少,SIGHAN 2013[5]比赛是 其中一个。该比赛使用的数据来源于台湾中学生的作文文本,过滤其他类型的错 误而只保留拼写错误,拼写错误具体而言有两种:读音相似导致的错误以及字型 相似导致的错误。本文认为,这样的过滤处理是合理的。根据调研报告[6],中文 母语使用者写作所犯错误中,76%的错误由读音相似而引起的,46%的错误由于字 型相似引起的(两种错误有重叠)。在用户手写的文章中,也发现了类似的现象。
2. 错误来源
根据错误的来源,可以将纠错划分为两大类:输入法端的纠错以及文本端的纠错。当然这两类并没有非常严格的界限。 输入方法主要包含手写输入、拼音输入、字型输入以及语音输入。由于手写输入同本项目关联不大,故而并未专门针对此进行调研;拼音输入法端的纠错做了 很多,比较代表性的有 CHIME[9],该方法可以自动发现并改正用户输入的“错误 拼音”,使用的主要方法是信道模型以及基于 trie 树的相似拼音匹配;字型输入 法端的纠错同拼音比较类似,因为字型输入也是有一套编码的,如仓颉编码、五 笔编码,拼音本身也是可以理解为一种编码的;基于语音的纠错,目前并没有成熟的方法,而语音输入具备的很多优点使得其有更大的可能性成为未来的主流输入法,但是如何系统性的处理语音输入纠错则需要进一步开展研究。 输入法端纠错难以使用完整的上下文信息,因为用户可能同时在几个任务上进行输入,如聊天的同时写文档。文本纠错则可以获得更全的上下文信息,故而 语言模型、统计机器翻译模型等等均可以获得更好的使用。
根据 SIGHAN Bake-off 2013 比赛的报告,参赛者使用了包括语言模型、分类模型(逻辑回归以及 SVM)、统计机器翻译模型、基于拼音字型的纠错模型、规则等。
3. 可用资源
除了各个比赛提供的少量数据以及个参赛者根据自己模型选择使用的数据外,
如下数据也可以应用于文本纠错。非常遗憾的是这些数据都是非中文的。
a) Cambridge Learner Corpus (CLC)[10]。该数据集包含了将近 200 万句对,是 非英语母语使用者参加英语考试的资料。数据的价值极高,然而该数据并不 对外开放。
b) FCE 。该数据集主要属于 CLC 的一部分,包含了 30,995 句对语言学家人工标 注的 80 类错误,该数据可公开下载,但是数据规模较小。
c) Lang-8 Learner Corpora[11]。该数据包含了 59,455 个用户撰写的 334,379 个 多语言页面,并经过校对,该数据可经过申请后获取。
三、项目思考
相对于英文纠错任务,中文纠错有自己的特性。比如中文不存在“错字”,无 论是拼音输入、字型输入、语音输入、手写输入均返回正确的字。
根据调研结果,中文的母语使用者的错误集中在由于拼音导致的拼写错误以 及由于字型导致的拼写错误,而语序等其他错误类型则很少出现。研表究明,汉 字序顺并不定一影响阅读。比如,读者在阅读前一句话的时候并不一定可以注意 到其中存在的语序问题。故本项目应最先处理拼写错误。
根据艾媒咨询发布《2015-2016 年中国手机输入法年度研究报告》,72.5%的 手机用户使用拼音输入法,仅有 8.3%的手机用户使用字型输入法。
综上,本项目优先处理由于拼音导致的拼写错误。
相比较于输入法端的纠错,基于文本的纠错可以更为方便的获取上下文信息,这为文本纠错提供了更大的空间;此外,文本是用户通过输入法输入的,故而文本端的纠错不应同输入法端的纠错重叠太多,毕竟许多错误已经在输入法端经过处理了。故而文本端的纠错应更多的基于上下文信息,而不是简单的字音字形。 在如何利用上下文信息上,SIGHAN Bake-off 2013 参赛队伍提供了很好的范例,我们发现,基于统计机器翻译模型的方法取得了不错的效果,一些队伍的具 体做法是先通过语言模型等判断出出错词语的位置,再利用统计机器翻译模型来 做词语的“翻译”,这样做并没有充分使用句子的语意信息。获取上下文语意信 息的一种比较好的方式是通过 RNN 来学习,故而本项目选用 seq2seq 框架(两组 RNN 分别构成 encoder 和 decoder,作为 encoder 的 RNN 学习句子语意表示)来 进行处理。此外,项目缺少可靠的数据来源,中文领域可利用的纠错数据有限,如何有 效的构造大量训练数据也成了本项目的一个关注点。
四、项目实验
本节主要从三个部分来进行阐述,实验数据准备、实验模型以及实验结果与 分析。
1. 实验数据准备
实验缺少大量的中文纠错数据,故而只能通过构造的方式来获取。 基于之前的分析,在构造数据的时候只引入因拼音相似导致的拼写错误。而考虑到输入法端(如 CHIME)已经处理了比较明显的拼音错误,故而在数据构造 的时候主要考虑同音替换和模糊音替换两种类型的错误。此外,考虑到拼音输入 往往按照词语来输入的特点,所有的替换均基于词语来进行。具体的构造步骤如下:
1) 基于哈工大社会计算与信息检索研究中心研发的语言技术平台(LTP)对 规范文本,如新华社新闻语料进行分词,此外将语料中的数字串统一替 换为“<DIGIT>”且将不常见词语替换为“_UNK”;
2) 基于逗号和句号将句子切割为更短的句子,切割后词语个数超过 30 的句 子将会被丢弃;这样做是因为真实环境中子句长度很少会超过 30 个词 语,且句子长度过长对于 RNN 的性能会产生影响。
3) 对句子中每个词语随机执行同音替换和模糊音替换,确保每个词语可能 被替换的概率相同,且每个句子最多有 4 处被替换;
如此获得 20,000,000 句对的训练语料,5,000,000 句对的开发语料以及 6,000句对的测试语料。
2. 实验模型
RNN 由一系列相同的网络构成(图 1 中的长方形表示一个网络),上一个词语的向量表示作为计算下一个网络的输入,如此循环。整个句子每个词军计算完成, 便得到了一个句子的语意向量。
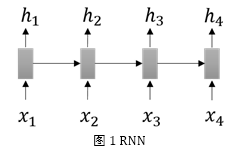
Seq2seq 模型使用 RNN(此时被称为 encoder)将输入句子表示为一个向量, 再使用另一个 RNN(此时被称为 decoder)解码这个向量获取输出。如在英汉机 器翻译任务中,先使用 encoder RNN 处理英文句子获取语意向量,将该向量作为 decoder RNN 的初始输入,按顺序解码每个英文单词获取中文。
为了充分获取上下文的语意信息,初始模型在基本 seq2seq 模型的基础上增 加了 bi-direction 以及 attention 机制。初始模型见图 2。
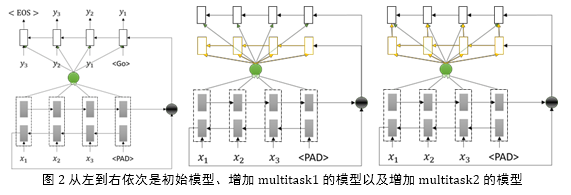
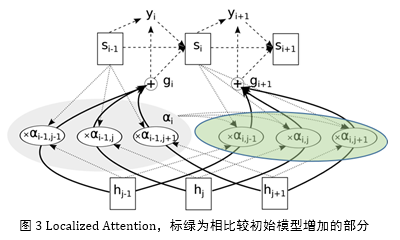
在初始模型的基础上,考虑到纠错任务中前后两个词语的 attention 值之间存 在比较强的关联。如 decoder 中第一个词语 attend 到 encoder 中第一个词语,则 decoder 中第二个词语“应该”attend 到 encoder 中的第二个词语。基于此,借鉴 Jan Chorowski[7]的工作,引入 localized attention 的做法,详细见图 3。
分析具体的数据,我们发现在许多情况下原先正确的词语经过 decoder 的操 作生成错误的词语,于是我们考虑引入一个新的任务来帮助判断某个词语是否需 要进行 decode,即 multitask。在具体的做法上有两种,分别为 multitask1 和 multitask2,模型见图一。Multitask1 中新增的任务与原先的模型公用一个 encoder, 在 decoder 端并无直接关联;在 multitask2 中,新任务的 decoder 结果作为初始 任务 decoder 输入的一部分。
3. 实验结果与分析
为了合理的评价模型的性能,需要有一套评价标准。除了基本的 F1 值之外,我们还计算了 F0.5 值,此外,结合基于翻译模型的纠错任务,进过调研,采用 GLUE[8] score 来作为模型的性能指标。GLUE 标准在 BLUE 标准的基础上增加对纠 错任务的针对性处理,实验结果表明 GLUE 标准最接近人的判断。
共进行六组实验,实验基于 google 公司发布的 TensorFlow[12]开发,实验结果 见表 1:
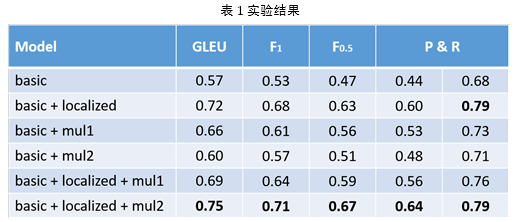
实验结果表明,localized attention 以及 multitask 机制均有助于系统性能的提升,而二者结合起来可以进一步提升系统的性能。目前去的最优性能的模型是在初始模型的基础上增加 localized attention 机制以及 multitask2 机制。 下面是一些典型的输出结果,每组数据第一句为正确的句子,第二句为输入的句子,第三句为模型输出的句子。
1) 两 国 不仅 边界 线 长 。
两 国 不进 辩结 线 长 。
两 国 不仅 边界 线 长 。
2) 由于 塔利班 扬言 要 破坏 此 次 选举 。
游寓 塔利班 狼烟 要 破坏 此 次 选举 。
由于 塔利班 _UNK 要 破坏 此 次 选举 。
3) 由于 中国 上海 和 香港 等 亚洲 地区 其他 主要 股市 走低 。 游寓 忠国 上海 和 香港 等 亚洲 地区 其他 主窑 故史 走低 。 由于 中国 上海 和 香港 等 亚洲 地区 其他 主要 股市 走低 。
4) 在 与 韩国队 的 金牌 争夺战 中 。 在 与 韩国队 的 金牌 争夺战 中 。 在 与 韩国队 的 金牌 金牌 中 。
注意到在第四组的数据中,模型将“金牌 争夺战”输出成了“金牌 金牌”, 这是由于 localized attention 机制导致的。
五、参考文献
1. Kao, Ting-Hui, Yu-Wei Chang, Hsun-Wen Chiu, Tzu-Hsi Yen, Joanne Boisson, Jian-Cheng Wu, and Jason S. Chang. "CoNLL-2013 Shared Task: Grammatical Error Correction NTHU System Description." In CoNLL Shared Task, pp. 20-25. 2013.
2. Ng, Hwee Tou, Siew Mei Wu, Ted Briscoe, Christian Hadiwinoto, Raymond Hendy Susanto, and Christopher Bryant. "The CoNLL-2014 Shared Task on Grammatical Error Correction." In CoNLL Shared Task, pp. 1-14. 2014.
3. Yu, Liang-Chih, Lung-Hao Lee, Yuen-Hsien Tseng, and Hsin-Hsi Chen. "Overview of SIGHAN
2014 Bake-off for Chinese spelling check." In Proceedings of the 3rd CIPSSIGHAN Joint
Conference on Chinese Language Processing (CLP’14), pp. 126-132. 2014.
4. Tseng, Yuen-Hsien, Lung-Hao Lee, Li-Ping Chang, and Hsin-Hsi Chen. "Introduction to SIGHAN
2015 Bake-off for Chinese Spelling Check." ACL-IJCNLP 2015 (2015): 32.
5. Wu, Shih-Hung, Chao-Lin Liu, and Lung-Hao Lee. "Chinese spelling check evaluation at SIGHAN Bake-off 2013." In Proceedings of the 7th SIGHAN Workshop on Chinese Language Processing, pp. 35-42. 2013.
6. Liu, C-L., M-H. Lai, K-W. Tien, Y-H. Chuang, S-H. Wu, and C-Y. Lee. "Visually and phonologically
similar characters in incorrect Chinese words: Analyses, identification, and applications." ACM Transactions on Asian Language Information Processing (TALIP) 10, no. 2 (2011): 10.
7. Chorowski, Jan K., Dzmitry Bahdanau, Dmitriy Serdyuk, Kyunghyun Cho, and Yoshua Bengio.
"Attention-based models for speech recognition." In Advances in Neural Information
Processing Systems, pp. 577-585. 2015.
8. Mutton, Andrew, Mark Dras, Stephen Wan, and Robert Dale. "GLEU: Automatic evaluation of sentence-level fluency." In ACL, vol. 7, pp. 344-351. 2007.
9. Zheng, Yabin, Chen Li, and Maosong Sun. "Chime: An efficient error-tolerant chinese pinyin input method." In IJCAI, vol. 11, pp. 2551-2556. 2011.
10. Nicholls, Diane. "The Cambridge Learner Corpus: Error coding and analysis for lexicography and ELT." In Proceedings of the Corpus Linguistics 2003 conference, vol. 16, pp. 572-581. 2003.
11. Mizumoto, Tomoya, Mamoru Komachi, Masaaki Nagata, and Yuji Matsumoto. "Mining Revision
Log of Language Learning SNS for Automated Japanese Error Correction of Second Language
Learners." In IJCNLP, pp. 147-155. 2011.
12. Abadi, Mart?n, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S.
Corrado et al. "Tensorflow: Large-scale machine learning on heterogeneous distributed systems." arXiv preprint arXiv:1603.04467 (2016).
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
