




















ЛљгкЛњЦїбЇЯАЕФЯрЙиаТЮХЪТМўЭкОђ
еЊ вЊЃКЭјТчаТЮХЕФЗЂеЙЕМжТаТЮХИхМўЪ§СПЕФМЋПьЩЯеЧЃЌШчКЮдкДѓСПЕФаТЮХЪ§ОнжаПьЫйзМШЗЕФевЕНЯывЊЗжЮіЕФаТЮХЪТМўЕФЫљгааТЮХЮФБООЭГЩСЫвЛИіМБашНтОіЕФЮЪЬтЁЃГЃМћЕФЗНЗЈЪЧЫбЫїЙиМќзжжЎКѓдйНјааШЫЙЄЫбМЏЃЌаЇТЪЕЭЯТЁЃБОЮФвдаТЮХСьгђЕФРэТлЮЊЛљДЁЬсГіаТЮХЪТМўЯрЙиЮФБОЕФЭкОђЗНЗЈЁЃЪзЯШвдаТЮХЭјеОЕФаТЮХЮФБОзїЮЊбаОПЖдЯѓЃЌЭЈЙ§TextCNNФЃаЭЖдаТЮХНјааСьгђЗжРрЃЌШЛКѓЪЙгУWord2vecЕУЕНДЪЯђСПЁЂTF-IDFзїЮЊДЪгяЕФШЈживдМАаТЮХСьгђЕФОбщЯрНсКЯРДВщевЯрЙиаТЮХЮФБОЁЃЪЕбщНсЙћБэУїЃЌЯджјЬсИпСЫЪЖБ№аЇТЪЁЃ
ЙиМќДЪЃКаТЮХЪТМўЗЂОђЃЛTextCNNЃЛWord2vecЃЛTF-IDF
News event related news mining based on machine learning
Ma Zheng , Zhang Shuai , Zhao Peng-Ya
(School of Software Engineering, Beijing University of Posts and Telecommunications, Beijing 100876)
Abstract: The development of online news has led to an extremely rapid increase in the number of news articles. How to quickly and accurately find all the news texts of news events that you want to analyze in a large amount of news data has become an urgent problem to be solved. A common method is to search for keywords and then manually collect them, which is inefficient. Based on the theory of the news field, this paper proposes a method for mining news related texts. Firstly, the news text of the news website is used as the research object, and the news is classified by the TextCNN model. Then, We use Word2vec get the word vector, TF-IDF to get the weight of the word and the experience in the news field to find the relevant news text. The experimental results show that the recognition efficiency is significantly improved.
Key words: News events mining; TextCNNЃЛWord2vecЃЛTF-IDF
1в§бд
ЫцзХЭјТчЕФЗЂеЙЃЌЭјТчаТЮХЕФЪ§СПвВМЋДѓдіМгЃЌЕБНёЪБДњЪЧвЛИіаХЯЂБЌеЈЕФЪБДњЃЌШчКЮдкКЃСПЕФаТЮХЪ§ОнжаПьЫйзМШЗЕФевЕНЯывЊЗжЮіЕФаТЮХЪТМўЕФЫљгааТЮХЮФБООЭГЩСЫвЛИіМБашНтОіЕФЮЪЬтЁЃОпЬхбаОПЮЪЬтЮЊЃКЖдгкФГвЛаТЮХЪТМўЃЌШчКЮЪЙгУЛњЦїбЇЯАЕФЗНЗЈдкЪ§ОнМЏжаЭкОђЦфШЋВПЯрЙиаТЮХЮФБОЁЃЕїВщЙњФкЭтбаОПЗЂЯжЃЌЯждкУЛгавЛИіаЇЙћГіЩЋЕФЯЕЭГРДНјааетЗНУцЕФЙЄзїЁЃФПЧАГ§СЫШЫЙЄЩИбЁжЎЭтжївЊгаЛљгкФЃЪНЦЅХфЕФаТЮХЮФБОЪЖБ№ЗНЗЈЃЌЦфаЇЙћНЯМбЃЌЕЋЪЧашвЊаТЮХзЈвЕШЫдБВйзїЃЌЖјЧвСщЛюадБШНЯВюЁЃЛЙгаеХЫЩ[1]ЪЙгУДЪДќФЃаЭЖдЮФБОНјааЯђСПЛЏжЎКѓМЦЫуЯрЫЦЖШЃЌЕЋИУФЃаЭЛсЕМжТЖЊЪЇДѓВПЗжЮФБОаХЯЂЃЌЫљвдЕМжТаЇЙћВЛМбЁЃЫљвдБОЮФЬсГіСЫетбљЕФвЛжжаТЕФНтОіЗНАИЁЃЪЙгУTextCNNФЃаЭЖдаТЮХНјааСьгђЗжРрЃЌШЛКѓЪЙгУWord2vecЕУЕНДЪЯђСПЁЂTF-IDFзїЮЊДЪгяЕФШЈживдМАаТЮХСьгђЕФОбщЯрНсКЯРДВщевЯрЙиаТЮХЮФБОЃЌдкЙВ38ЭђаТЮХЮФБОЕФЪ§ОнМЏжаДяЕНСЫвЛИіВЛДэЕФаЇЙћЃЌзМШЗТЪЮЊ81%ЃЌейЛиТЪЮЊ79%ЁЃ
етЖдгкаТЮХДгвЕепЖјбдЃЌетФмЙЛАяжњЫћУЧИќМгзМШЗЕФЭГМЦКЭМЦЫуаТЮХСьгђЕФИїЯюжИБъЪ§ОнЁЃОпгаЪЎЗжживЊЕФЯжЪЕвтвхЁЃећЬхСїГЬШчЯТЭМвЛЫљЪОЃК
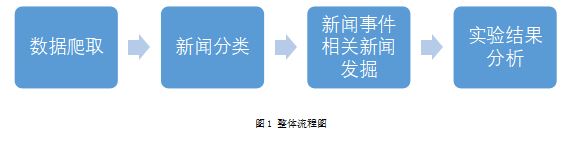
2 ЙЙНЈЪ§ОнМЏ
вЊНјааЪЕбщЃЌЪзЯШашвЊЛёШЁЪЕбщЪ§ОнЃЌЙЙНЈЪ§ОнМЏЁЃБОЪЕбщЪЙгУpythonдкЬкбЖаТЮХЃЈhttps://news.qq.com/ЃЉЁЂаТРЫаТЮХЃЈhttps://news.sina.com.cn/ЃЉЁЂжаЙњаТЮХЭјЃЈhttps://www.chinanews.com/ЃЉШ§ИіЭјеОХРШЁСЫ2017Фъ6дТжС12дТЕФШЋВПаТЮХЁЃВЩМЏЪ§ОнФкШнАќРЈаТЮХБъЬтЁЂаТЮХЗЂВМЪБМфЁЂаТЮХзїепЁЂаТЮХЗЂВМдДЭјеОЁЂаТЮХЫљдкЭјеОЁЂаТЮХЦРТлЪ§ЁЂаТЮХе§ЮФЕШЁЃОЙ§ШЅГ§дрЪ§ОнКЭЬюГфШБЪЇжЕЕШВйзїжЎКѓзмЙВ387431ЬѕаТЮХЁЃ
ХРШЁЪ§ОнжЎКѓЖдаТЮХЮФБОНјаадЄДІРэЃЌЯШЪЙгУАйЖШдЦЕФДЪЗЈЗжЮіЕФЙІФмНјааЗжДЪЃЌвђЮЊАйЖШдЦдкУќУћЪЕЬхЪЖБ№ЗНУцзіЕФаЇЙћЯджјИпгкЦфЫћЗНЗЈЃЌШЛКѓИљОнЭЃгУДЪБэЖдЭЃгУДЪНјааШЅГ§ЁЃзюжеЕУЕНПЩвдгУРДЪдбщЕФЪ§ОнМЏЁЃ
3 аТЮХЗжРр
ЗжРрФЃаЭЪЙгУЕФTextCNN ЃЌTextCNN ЪЧРћгУОэЛ§ЩёОЭјТчЖдЮФБОНјааЗжРрЕФЫуЗЈЃЌгЩ Yoon KimЬсГіЃЌЦфЗжРраЇЙћЪЎЗжГіЩЋЃЌдквдЭљЕФЪЕбщжавбОЕУЕНбщжЄ[2]ЁЃгЩЖржжВЛЭЌРраЭЕФОэЛ§КЫзщГЩЕФОэЛ§ВуЁЂГиЛЏВуКЭШЋСЌНгВуЙВЭЌМЦЫуЕУЕНЗжРрНсЙћЁЃОпЬхЗжЮЊЪЎжжРрБ№ЃЌЬхг§ЁЂВЦОЁЂЗПВњЁЂМвОгЁЂНЬг§ЁЂПЦММЁЂЪБЩаЁЂЪБеўЁЂгЮЯЗЁЂгщРжЁЃ
бЕСЗМЏЮЊЪЎИіРрБ№УПИіРрБ№5000ЬѕЃЌзмЙВ50000ЬѕаТЮХЮФБОзщГЩЁЃбщжЄМЏЮЊУПРр1000ЬѕзмЙВ10000ЬѕЮФБОзщГЩЃЌВтЪдМЏгУУПРр2000ЬѕЃЌзмЙВ20000ЬѕаТЮХЮФБОзщГЩЁЃетРябаОПЖдЯѓЮЊаТЮХЮФБОЕФе§ЮФЃЌЮФБОГЄЖШЮЊ400ЃЌЖдгкЮФБОВЛзу300ДЪЕФНјааЬюГф0ДІРэЃЌГЌЙ§300ЕФНјааНиШЁЁЃУПДЮФЃаЭЕїгХЪЙгУmini-batchДѓаЁЮЊ50.ЁЃ
ДЪЕФЯђСПЛЏЪЙгУЕФЪЧWord2vecДЪЯђСПЃЌЮЌЖШЮЊ200ЮЌЁЃОэЛ§КЫГпДчЮЊ3ЁЂ4ЁЂ5Ш§жжЃЌУПжжга100ИіОэЛ§КЫЁЃбЕСЗЦкМфЪЙгУdropoutРДЗРжЙФЃаЭЙ§ФтКЯЃЌdropoutжЕЮЊ0.5.ЁЃФЃаЭНјааЕїгХжЎКѓУПДЮЖМдкбщжЄМЏЩЯМЦЫуНсЙћЃЌжЛгааЇЙћЬсЩ§ЕФВХЛсБЛВЩФЩЁЃдкОЙ§1500Иіmini-batchдкбщжЄМЏЩЯУЛгаЬсЩ§жЎКѓЃЌФЃаЭЭЃжЙбЕСЗЁЃ
зюжеЕУЕНЕФФЃаЭдкВтЪдМЏЩЯЃЌзюжезМШЗТЪКЭейЛиТЪЮЊ96.8%КЭ97.1%ЁЃНсЙћШчБэ1ЫљЪОЁЃ

4 аТЮХЪТМўЯрЙиаТЮХЗЂОђ
дкЗжРржЎКѓЕФЮФБОжаНјаааТЮХЪТМўЕФЯрЙиаТЮХЗЂОђЁЃР§Шч2017ФъЯТАыФъЁАКьЛЦРЖгзЖљдАХАЭЏЪТМўЁБЃЌвЊЗЂОђГіЦфЫљгаЯрЙиаТЮХЁЃжївЊСїГЬШчЯТЃКбЕСЗДЪЯђСПФЃаЭЁЂбЕСЗTF-IDFФЃаЭЁЂаТЮХЮФБОЯђСПЕФМЦЫуЁЂВЛЭЌаТЮХЮФБОЯрЫЦЖШЕФМЦЫуЁЃ
4.1ДЪЯђСПМЦЫу
етРяЪЙгУЕФWord2vecЯђСПРДБэЪОДЪЯђСПЁЃздДг Google ЕФ Tomas Mikolov[3]ЬсГі Word2vecЃЌОЭГЩЮЊСЫЩюЖШбЇЯАдкздШЛгябдДІРэжаЕФЛљДЁВПМўЁЃWord2vecЕФЛљБОЫМЯыЪЧАбздШЛгябджаЕФУПвЛИіДЪЃЌБэЪОГЩвЛИіЭГвЛвтвхЭГвЛЮЌЖШЕФЖЬЯђСПЁЃWord2vecЭЈЙ§бЕСЗЃЌПЩвдАбЖдЮФБОФкШнЕФДІРэМђЛЏЮЊ K ЮЌЯђСППеМфжаЕФЯђСПдЫЫуЃЌЖјЯђСППеМфЩЯЕФЯрЫЦЖШПЩвдгУРДБэЪОЮФБОгявхЩЯЕФЯрЫЦЖШЁЃвђДЫЃЌ Word2vecЪфГіЕФДЪЯђСППЩвдБЛгУРДзіКмЖр NLP ЯрЙиЕФЙЄзїЃЌБШШчОлРрЁЂевЭЌвхДЪЁЂДЪадЗжЮіЕШЕШЁЃЪЙгУWord2vecДІРэКѓЕФДЪПЩвдЖдЫќУЧзіЯђСПЕФМгМѕГЫГ§ВйзїЕШЁЃетбљНЋДЪЕФБэЪОНјааСПЛЏЃЌИќвзМЦЫуЫќУЧжЎМфЕФЯрЫЦЖШЁЃ
ЪзЯШЖдгкЗжДЪЭъЕФЪ§ОнЖСШЁЃЌетРяЖСШЁЕФЪЧШЋВПаТЮХЮФБОЙВ38ЭђЬѕЃЌШЛКѓЖСШЁжЎКѓЕФгяСЯПтЗХШыWord2vecФЃаЭжаШЅбЕСЗЃЌЩшжУИїИіВЮЪ§ЃЌЪЙгУCBOWФЃЪНбЕСЗФЃаЭЃЌДЪЯђСПЮЌЖШЮЊ200ЮЌЃЌЩЯЯТЮФДАПкЮЊ4ЕШЃЌЪЙгУNegative SamplingММЪѕМгЫйбЕСЗЁЃШЛКѓПЊЪМбЕСЗЁЃзюжеЕУЕНаЇЙћШчЯТЫљЪОЁЃВщевгыЁАББОЉЁБЯрЫЦЖШзюИпЕФДЪгяЁЃ
print(model.most_similar(positive=['ББОЉ']) )
[('ББОЉЪа', 0.6418594717979431), ('ЩЯКЃ', 0.6290482878684998), ('ФЯОЉ', 0.6218650341033936), ('ЬьНђ', 0.6215558648109436), ('ББЦН', 0.5777425765991211), ('Щђбє', 0.5712735652923584), ('ЮфКК', 0.5640500783920288), ('брОЉ', 0.5502774715423584), ('КМжн', 0.5484658479690552), ('жаЙњ', 0.5257613062858582)]
4.2бЕСЗTF-IDFФЃаЭ
TF-IDFЪЧвЛжжЭГМЦЗНЗЈЃЌгУвдЦРЙРвЛзжДЪЖдгквЛИіЮФМўМЏЛђвЛИігяСЯПтжаЕФЦфжавЛЗнЮФМўЕФживЊГЬЖШЁЃзжДЪЕФживЊадЫцзХЫќдкЮФМўжаГіЯжЕФДЮЪ§ГЩе§БШдіМгЃЌЕЋЭЌЪБЛсЫцзХЫќдкгяСЯПтжаГіЯжЕФЦЕТЪГЩЗДБШЯТНЕЁЃ
дквЛЗнИјЖЈЕФЮФМўРяЃЌДЪЦЕ (term frequency, TF) жИЕФЪЧФГвЛИіИјЖЈЕФДЪгядкИУЮФМўжаГіЯжЕФДЮЪ§ЁЃетИіЪ§зжЭЈГЃЛсБЛЙщвЛЛЏЃЈЗжзгвЛАуаЁгкЗжФИ ЧјБ№гкIDFЃЉЃЌвдЗРжЙЫќЦЋЯђГЄЕФЮФМўЁЃЃЈЭЌвЛИіДЪгядкГЄЮФМўРяПЩФмЛсБШЖЬЮФМўгаИќИпЕФДЪЦЕЃЌЖјВЛЙмИУДЪгяживЊгыЗёЁЃЃЉ
ФцЯђЮФМўЦЕТЪ (inverse document frequency, IDF) ЪЧвЛИіДЪгяЦеБщживЊадЕФЖШСПЁЃФГвЛЬиЖЈДЪгяЕФIDFЃЌПЩвдгЩзмЮФМўЪ§ФПГ§вдАќКЌИУДЪгяжЎЮФМўЕФЪ§ФПЃЌдйНЋЕУЕНЕФЩЬШЁЖдЪ§ЕУЕНЁЃ
ФГвЛЬиЖЈЮФМўФкЕФИпДЪгяЦЕТЪЃЌвдМАИУДЪгядкећИіЮФМўМЏКЯжаЕФЕЭЮФМўЦЕТЪЃЌПЩвдВњЩњГіИпШЈжиЕФTF-IDFЁЃвђДЫЃЌTF-IDFЧуЯђгкЙ§ТЫЕєГЃМћЕФДЪгяЃЌБЃСєживЊЕФДЪгяЁЃ
ОпЬхСїГЬЮЊЃЌАбаТЮХгяСЯПтжаАДРрБ№ЖСШыЗжДЪЭъЕФаТЮХЮФБОЃЌЪ§ОнИёЪНЮЊ[ЁЎword1 word2 word3ЁЏ , ЁЎword4 word5 word6ЁЏ]ЃЌУПИіаТЮХЮФБОжаЕФДЪгУПеИёИєПЊЃЌШЛКѓЫљгааТЮХЮФБОЗХШывЛИіlistжаЃЌбЕСЗTF-IDFФЃаЭЕУЕНTF-IDFШЈжижЕЃЌЖдгкВЛЭЌЕФаТЮХЮФБОжаЕФВЛЭЌДЪОљгаВЛЭЌЕФШЈжиЁЃР§ШчЃК
ЮФБОвЛЃК
ЯыЯѓ 0.0414187845264
еНТд 0.0704195017334
ЫљгУ 0.0414187845264
ЮФБОЖўЃК
ЪжЖЮ 0.0352097508667
ДђЭЈ 0.0616087427535
Дђдь 0.0222347726757
4.3аТЮХЮФБОЯђСПЕФМЦЫу
аТЮХЮФБОЕФИёЪНОљБШНЯЙЬЖЈЃЌГіЯждке§ЮФЪзВПЕФЮФзжОЭФмИХРЈећИіаТЮХЫљУшЪіЕФЪТМўЁЃЫљвдБОЪЕбщШЁаТЮХЧА30ИіДЪРДЖдаТЮХЮФБОЯђСПНјааМЦЫуЁЃ
аТЮХЕФСљвЊЫиЪЧ5ИіЁАWЁБКЭ1ИіЁАHЁБ, МДWho ,What ,When ,Where ,WhyКЭHowЃЛМДЃКЪБМфЁЂЕиЕуЁЂШЫЮяЁЂЪТМўЕФЦ№вђЁЂОЙ§ЁЂНсЙћЁЃетРяЬєбЁГіПЩвдРћгУЕФЙиМќДЪЃЌМДЪБМфЁЂЕиЕуЁЂШЫЮяРДХаЖЈЮЊЙиМќДЪЃЌдкМЦЫуЯђСПЪБИГгшИќИпЕФШЈжиЁЃетРяРћгУЕНжЎЧАЗжДЪЪБШЗЖЈЕФУќУћЪЕЬхЁЃЖдгкВЛЪЧЙиМќДЪЕФЦеЭЈДЪгяЃЌШЈжиЮЊ1ЁЃ
вђЮЊаТЮХжЎжаЕФЪБМфЙиМќДЪЛсгаЦчвхЁЃР§ШчЁАзђЭэЁБетИіДЪГіЯждкВЛЭЌЪБМфЕФаТЮХИхМўжаЫљжИДњЕФЪЕМЪЪБМфПЯЖЈЪЧВЛЭЌЕФЃЌЫљвдБОЪЕбщжаРћгУЙцдђЖдетаЉЪБМфЙиМќДЪНјааСЫзЊЛЛЁЃЭГвЛИёЪНЮЊЃКYYYYФъMMдТDDШеЃЌвдЗНБуКѓајЕФМЦЫуЁЃ


БОДЮЪдбщЙВБъзЂСЫ3000ЬѕЪ§ОнЃЌБъГіЕФВПЗжаТЮХЪТМўжїЬтШчЯТЫљЪОЁЃ
вЛДјвЛТЗЁЂЙІЪиЕРЁЂеНРЧЁЂжаЙњгаЮћЙўЁЂНћОЦСю ЁЂЦнМЬЙтНЂГіЙњЗУЮЪЁЂСЩФўНЂЯуИлЁЂНЈОќ90жмФъжьШеКЭдФБјЁЂжагЁЖджХЁЂЪРНчЛњЦїШЫДѓЛсЁЂЭѕепШйвЋЗРГСУдЁЂЦЛЙћЕчГиУХЁЂЪЎОХДѓЁЂКьЛЦРЖХАЭЏЁЂКЃЕзРЬЮРЩњЪѓЛМ,
ЪдбщЪЧдкВЛЭЌЕФаТЮХРрБ№ЯТЗжБ№ЪЖБ№ЩЯЪіаТЮХЪТМўЕФЯрЙиаТЮХЮФБОЃЌзмЙВЫбЫїЕФЪ§ОнЙцФЃЮЊ38ЭђЬѕЁЃЪфШывЊВщбЏЕФаТЮХЪТМўЕФЯрЙидЪМЮФБОЃЌШЛКѓОЭЛсевбАЯрЫЦЖШДѓгкуажЕЕФЦфЫћаТЮХЮФБОЁЃР§ШчЫбЫїЁАЭѕепШйвЋЗРГСУдЁБНсЙћШчЯТЫљЪОЃЌЩЯЗНЪ§жЕЮЊУПЬѕЮФБОЖдгІЕФгыдЪМЮФБОЕФЯрЫЦЖШЃЌЯТЗНЮФзжЪЧУПЬѕЮФБОЖдгІЕФаТЮХБъЬтЁЃ
0.955816560253
ЭѕепШйвЋЕФЩчНЛЃКЪБМфЁЂН№ЧЎЁЂЩБШЫгЮЯЗ
0.97403353679
МЧепЧзВтЭѕепШйвЋЮЊКЮШУФузХУдЃКЛЈЧЎОЭГЩДѓЯРЃП
0.967141859087
аТЛЊЩч:ЁАШйвЋЁБЛЙЪЧЁАХЉвЉЁБ?НЁПЕгЮЯЗВЛжЙгкЗРГСУд
0.95819191127
ЪЧЗёБШТщНЋИќШнвзЩЯёЋ ЭѕепШйвЋЮЊКЮШУШЫзХУдЃП
0.96172696944
ЭЈЯђЭѕепШйвЋЕФХЋвлжЎТЗЃКЮоЗЈЯТЯпЕФЁАЭѕепЁБ
0.955020467616
ЭѕепШйвЋЩюЯнгпТлЗчБЉ ОоЭЗШчКЮШЈКтРћвцгыд№ШЮЃП
0.966630783757
ЮхСљвкШЫУПЬьЁАЭцЕєЁБЪ§аЁЪБ ЭјгЮдкКЭЮвУЧељЪБМфЃП
ВПЗжШШЕуаТЮХЪТМўЕФаЇЙћШчБэ2ЫљЪОЃК
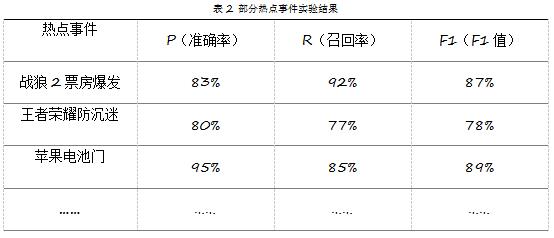
зюжеЕїЪдЭъжЎКѓЪдбщНсЙћШчБэ3ЫљЪОЃК

ЪдбщНсЙћЯдЪОзмЬхзМШЗТЪЮЊ81%ЃЌейЛиТЪЮЊ79%ЃЌF1жЕЮЊ80%ЁЃМДдкЫбЫїаТЮХЪТМўЪБЃЌдЄВтбљБОжаФмга81%ЪЧе§ШЗЪЖБ№ЕФЃЌЖдгкИУЪТМўжаЕФЫљгабљБОЃЌФмЙЛЪЖБ№Гі79%ЃЌЫЕУїЪдбщдкбљБОжаШЁЕУСЫНЯКУЕФаЇЙћЃЌБШЦ№ЧАШЫЕФбаОПШЁЕУСЫвЛЖЈЕФНјВНЁЃ
5.2змНсгыеЙЭћ
БОЮФеыЖдаТУНЬхДЋВЅЛЗОГЯТЕФЬиЕуЃЌЪдбщСЫЖдгкаТЮХЪТМўЯрЙиаТЮХЮФБОЕФЭкОђЃЌетЖдгкаТЮХДгвЕепЛђепШЫУЧдкДѓСПЪ§ОнжаПьЫйзМШЗЕФевЕНвЛИіЪТМўЕФШЋВПаТЮХЬсЙЉСЫВЮПМЁЃЕЋЪЧвђЮЊЪБМфЁЂЫЎЦНЕШЯожЦЃЌБОЪЕбщЕФЙЄзїЛЙгаВЛзужЎДІЁЃУЛгаЛёШЁЕНзуЙЛДѓЪ§СПЕФаТЮХЃЌНіНіжЛЪЧШ§МвЭјеОАыФъЕФаТЮХЪ§ОнЃЌЪ§ОнСПЕФВЛзуЕМжТСЫаЇЙћПЩФмВЛЪЧзюгХЁЃвдМАВЮЪ§ЕФбЁдёЮЪЬтЃЌЯждкжЛЪЧЪдбщжаЗЂЯжЕФзюгХХфКЯЃЌЕЋПЯЖЈВЛЪЧзюжеЕФзюгХНтЃЌШчКЮВХФмевЕНзюгХЕФИїИіВЮЪ§ЕФЮЪЬтЁЃетаЉЖМЪЧКѓајжЕЕУЩюШыбаОПЕФЮЪЬтЁЃ
ЗжЯэШУИќЖрШЫПДЕН 
ЭЦМідФЖС
ДЋУНЭЦМі
 @УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад
@УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ
ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
ЯрЙиаТЮХ
ПЭЛЇЖЫЯТди
ШЫУёШеБЈЩчИХПі | ЙигкШЫУёЭј | БЈЩчеаЦИ | еаЦИгЂВХ | ЙуИцЗўЮё | КЯзїМгУЫ | ЙЉИхЗўЮё | Ъ§ОнЗўЮё | ЭјеОЩљУї | ЭјеОТЩЪІ | аХЯЂБЃЛЄ | СЊЯЕЮвУЧ
ЗўЮёгЪЯфЃКkf@people.cn ЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-65363263 ОйБЈгЪЯфЃКjubao@people.cn
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170001 | діжЕЕчаХвЕЮёОгЊаэПЩжЄB1-20060139
ЙуВЅЕчЪгНкФПжЦзїОгЊаэПЩжЄЃЈЙуУНЃЉзжЕк172КХ | ЛЅСЊЭјвЉЦЗаХЯЂЗўЮёзЪИёжЄЪщЃЈОЉЃЉ-ЗЧОгЊад-2016-0098
аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0104065 | ЭјТчЮФЛЏОгЊаэПЩжЄ ОЉЭјЮФ[2020]5494-1075КХ | ЭјТчГіАцЗўЮёаэПЩжЄЃЈОЉЃЉзж121КХ | ОЉICPжЄ000006КХ | ОЉЙЋЭјАВБИ11000002000008КХ
ШЫ Уё Эј Ац ШЈ Ыљ га ЃЌЮД О Ъщ Уц Ък ШЈ Нћ жЙ ЪЙ гУ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЦРТл

-
ЙизЂ
ЮЂаХЮЂВЉПьЪж
 ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
 БЈЕРШЋЧђ ДЋВЅжаЙњ
БЈЕРШЋЧђ ДЋВЅжаЙњ
 ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
