




















Т»ЦЦ»щУЪRDMAµДФЖґжґўПµНіЙијЖДЈКЅ
ХЄ ТЄЈє±ѕВЫОДМбіцБЛТ»ЦЦРВРНµДRDMAЙијЖДЈКЅЈ¬Йжј°ФЖґжґўПµНіµДФ¶іМКэѕЭ»сИЎЙијЖДЈКЅЈ¬НЁ№эёГЙијЖДЈКЅУЕ»ЇФЖКэѕЭЦРРДµД·юОс¶ЛЈ¬ЧоЦХјУЛЩПµНіФЖґжґўПµНіЈ¬МбёЯНшВзУ¦УГіМРтРФДЬЎЈ
№ШјьґКЈєФЖґжґўЈ»ґуКэѕЭЈ»RDMAЈ»
Abstract: This paper provides a different approach, called RF-RPC (Remote Fetching RPC Paradigm). Different from server-reply, RF-RPC makes client fetch the results from server using one-sided RDMA instead of waiting the results pushed by server. Different from server-bypass, RF-RPC demands server to process clientЎЇs requests for supporting programming paradigm like RPC. Thus, RF-RPC can achieve high performance without abandoning traditional programming models. ?
Keywords: Cloud Storage; Big Data; RDMA;
ТэСФ
RDMAКЗТ»ЦЦЦ±ЅУґжИЎФ¶іМДЪґжµДјјКхЎЈRDMA ІЩЧчѕЯУРЕФВ·МШРФЈ¬ФКРнДіМЁ»ъЖчµДCPU ДЬ№»Ц±ЅУ¶БРґЖдЛыФ¶іМ»ъЖчµДДЪґжКэѕЭЈ¬¶шІ»РиТЄёГФ¶іМ»ъЖчCPU ТФј°ІЩЧчПµНіµДИОєОІОУлЎЈН¬К±Ј¬RDMA ІЩЧч»№ѕЯУРКэѕЭБгїЅ±ґМШРФЈ¬ФЪ·ўЛНЗлЗуєНЅУКХЗлЗуµД»ъЖчЙПЈ¬RDMA ІЩЧчДЬ№»±ЬГвКэѕЭФЪУГ»§М¬їХјдєНДЪєЛМ¬їХјдЦ®јдµДПФКЅїЅ±ґЎЈУЙУЪѕЯУРЕФВ·МШРФЎўКэѕЭБгїЅ±ґМШРФТФј°ёьјУјтµҐµДРТйХ»Ј¬RDMA Па±ИИнјюІгГжКµПЦµДTCP/IP РТйѕЯУРёьёЯµДРФДЬЎЈ
1ФЖКэѕЭЦРРДRPCНЁРЕ»ъЦЖУл№ЫІв
1.1RPC
RPC їЙТФОЄЙПІгПµНіТюІШПыПўНЁРЕµДёґФУРФЈ¬ёшПµНіїЄ·ўХЯМṩБјєГµДїЙ±аіМРФЎЈјёєхЛщУРµДRPC »ъЦЖ¶јІЙУГН¬Т»ЦЦјЬ№№ЎЈѕЯМе¶шСФЈ¬ФЪRPC »ъЦЖЦРЈ¬Т»ёцRPCµчУГ°ьАЁТФПВИэёцІЅЦиЈЁИзНј5Ј©ЈєЈЁ1Ј©ЗлЗу·ўЛНЈєїН»§¶ЛЅ«µчУГєЇКэТФј°Па№ШµДµчУГІОКэ·ўЛНёш·юОсЖчЈ»ЈЁ2Ј©ЗлЗуґ¦АнЈєїН»§¶Л·ўЛНµДЗлЗуµГµЅґ¦АнЈ¬ІўІъЙъПаУ¦µДЅб№ыЈ»ЈЁ3Ј©Ѕб№ы·µ»ШЈєЗлЗуґ¦АнµГµЅµДЅб№ыНЁ№эНшВзґ«КдµЅїН»§¶ЛЎЈ
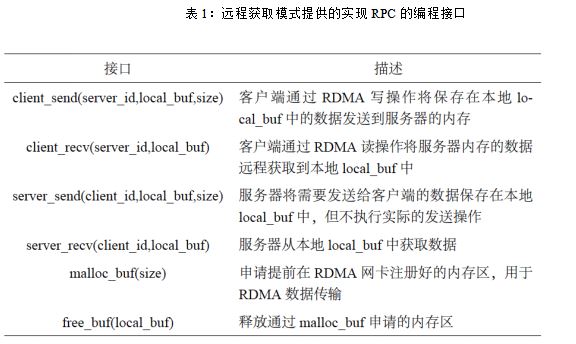
ДїЗ°ґжФЪБЅЦЦЅ«RDMA У¦УГµЅФЖґжґўПµНіµДЙијЖДЈКЅЈє·юОсЖч»ШёґДЈКЅєН·юОсЖчЕФВ·ДЈКЅЎЈ·юОсЖч»ШёґДЈКЅТЄЗу·юОсЖчёєФрґ¦АнїН»§¶ЛµДЗлЗуЈ¬ІўЅ«ґ¦АнЅб№ы·ўЛНёшїН»§¶ЛЎЈёГЙијЖДЈКЅУГRDMA Мж»»БЛґ«НіµДTCP/IPЈ¬µ«КЗІ»ёД±д¶ФЙПІгПµНіМṩµДRPC ЅУїЪЎЈТтґЛЈ¬·юОсЖч»ШёґДЈКЅѕЯУРєЬєГµДїЙ±аіМРФЎЈµ«КЗЈ¬УЙУЪГ»УРід·ЦАыУГRDMA µДМШРФЈ¬·юОсЖч»ШёґДЈКЅЛщДЬМṩµДРФДЬКЗ·ЗіЈУРПЮµДЎЈ·юОсЖчЕФВ·ДЈКЅТЄЗуїН»§¶ЛНЁ№эRDMA Ф¶іМІЩЧч·юОсЖчДЪґжµДКэѕЭЈ¬Ц±ЅУНкіЙЗлЗ󣬶ш·юОсЖчІ»ІОУлЗлЗуµДґ¦АнЎЈУЙУЪАыУГRDMA µДЕФВ·МШРФЅµµНБЛ·юОсЖчCPU µДїЄПъЈ¬·юОсЖчЕФВ·ДЈКЅПа±И·юОсЖч»ШёґДЈКЅ»бґшАґЅ«ЅьТ»±¶µДРФДЬМбЙэЎЈµ«КЗЈ¬·юОсЖчЕФВ·ДЈКЅИґЛрК§БЛїЙ±аіМРФЈ¬Ль±ШРлТААµПµНіїЄ·ўХЯЙијЖМШКвµДКэѕЭЅб№№єНЛг·ЁЈ¬Іў¶ФФУРПµНіЅшРРЅПґу·¶О§µДёД¶ЇЎЈТтґЛЈ¬·юОсЖч»ШёґДЈКЅєН·юОсЖчЕФВ·ДЈКЅёшФЖґжґўПµНіїЄ·ўХЯґшАґБЛТ»ёцЙијЖДСМвЈ¬ИГЖдІ»µГІ»ФЪїЙ±аіМРФєНРФДЬЦ®јдЧцСЎФсЎЈ
1.2»щУЪКэѕЭЦРРДµДИэёц№ЫІв
·ўПЦ1: RDMA НшїЁµДРФДЬ·З¶ФіЖРФЎЈРФДЬ·З¶ФіЖРФІъЙъµДФТтКЗФЪУІјюЙијЖЙПЈ¬RDMAНшїЁ·ўЛНRDMA ІЩЧчЈЁRDMA КдіцІЩЧчЈ©ІъЙъµДїЄПъєНЅУКХRDMA ІЩЧчЈЁRDMA КдИлІЩЧчЈ©ІъЙъµДїЄПъКЗІ»Т»СщµДЈ¬З°ХЯТЄФ¶Ф¶ґуУЪєуХЯЎЈ·юОсЖч»ШёґДЈКЅТААµ·юОсЖчНЁ№эRDMA КдіцРґІЩЧчЅ«Ѕб№ы·µ»ШёшїН»§¶ЛЈ¬ХвµјЦВ·юОсЖчєЬїмѕНУГВъБЛRDMA КдіцІЩЧчµДIOPSЈ¬¶шґЛК±RDMA КдИлІЩЧчµДIOPS »№Ф¶Ф¶ОґґпµЅРФДЬЖїѕ±ЎЈ
·ўПЦ2: RDMA НшїЁµДРФДЬ·З¶ФіЖРФЎЈ·юОсЖчЕФВ·ДЈКЅФЪЖЪНы»сµГµДРФДЬєНКµјК»сµГµДРФДЬЦ®јдґжФЪІоѕаЎЈУЙУЪ·юОсЖчµДCPU ФЪґ¦АнЗлЗуµД№эіМЦР±»ЕФВ·БЛЈ¬їН»§¶Л±ШРлК№УГёь¶аКэДїµДRDMA ІЩЧчАґЅвѕцКэѕЭіеН»ЎЈХв»бµјЦВПµНіКµјКРФДЬµДЅµµНЈ¬УИЖдКЗФЪіеН»ёьјУСПЦШµДРґГЬјЇКэѕЭјЇЦРЎЈ
·ўПЦ3: RDMA НшїЁµДРФДЬПаЛЖРФЎЈУІјюЙијЖФФтѕц¶ЁБЛRDMA НшїЁѕЯУРРФДЬПаЛЖРФЈ¬¶шЗТРФДЬПаЛЖРФЦчТЄМеПЦФЪRDMA КдИлІЩЧчЙПЈєФЪДіёцРФДЬПаЛЖЗшјдДЪЈ¬RDMA НшїЁµДRDMA КдИлІЩЧчРФДЬІ»ИЎѕцУЪКэѕЭµДґуРЎЈ¬¶шКЗіКПЦіц±ИЅПОИ¶ЁµДКэЦµЎЈ
2ПµНіЙијЖУлКµПЦ
2.1ПµНіЙијЖёЕїц
±ѕВЫОДМбіцБЛФ¶іМ»сИЎДЈКЅЎЈЧчОЄТ»ЦЦРВРНµДRDMA ЙијЖДЈКЅЈ¬ЖдІ»ЅцДЬЦ§іЦґ«НіµДRPC ЅУїЪИГПµНіІ»РиТЄѕ№эґу№жДЈРЮёДѕНДЬК№УГЈ¬¶шЗТїЙТФМṩ±И·юОсЖч»ШёґДЈКЅєН·юОсЖчЕФВ·ДЈКЅёьєГµДРФДЬЎЈ
Ф¶іМ»сИЎДЈКЅІЙУГБЛБЅёц№ШјьµДЙијЖСЎФсЈєµЪТ»ёцЙијЖСЎФсКЗ·юОсЖчУ¦ёГёєФрґ¦АнїН»§¶ЛµДЗлЗуЈ¬ХвСщІ»ЅцїЙТФМṩєЬєГµДїЙ±аіМРФЈ¬·Ѕ±гЙПІгПµНіјтµҐµШК№УГЈ¬¶шЗТїЙТФ±ЬГвїН»§¶Л¶ФіеН»µДґ¦АнЈ»µЪ¶юёцЙијЖСЎФсКЗЗлЗуґ¦АнЅб№ыУ¦ёГУЙїН»§¶ЛНЁ№эRDMA ¶БІЩЧчАґФ¶іМ»сИЎЈ¬¶шІ»КЗУЙ·юОсЖчНЁ№эRDMA РґІЩЧчАґ·ўЛНЎЈ
2.2ПµНіФЛРРБчіМ
ИзНјТ»ЛщКѕЈ¬Ф¶іМ»сИЎДЈКЅµД№¤ЧчБчіМИзПВЈє
1. їН»§¶ЛµчУГclient_send ЈЁ±н1Ј©ЅУїЪЅ«ЗлЗуНЁ№эRDMA РґІЩЧч·ўЛНµЅ·юОсЖчµДДЪґжЦР
2. ·юОсЖчНЁ№эµчУГserver_recv ЈЁ±н1Ј©ЅУїЪґУ±ѕµШДЪґжЦР»сµГїН»§¶ЛЗлЗуЈ¬Іўґ¦АнХвР©ЗлЗуЎЈ

ФЪФ¶іМ»сИЎДЈКЅЦРЈ¬·юОсЖчФЪґ¦АнНкЗлЗуєуІўІ»Ѕ«Ѕб№ы·ў»ШёшїН»§¶ЛЎЈПа·ґЈ¬·юОсЖчµчУГµДserver_send ЅУїЪЅцЅ«Ѕб№ы±ЈґжФЪ±ѕµШµДДЪґжЦРЎЈµ±їН»§¶ЛµчУГclient_recv ЅУїЪК±Ј¬client_recv ЅУїЪ»бНЁ№эRDMA ¶БІЩЧчЅ«Ѕб№ыґУ·юОсЖчµДДЪґжФ¶іМ»сИЎµЅ±ѕµШДЪґжЦРЎЈ
·юОсЖчєНїН»§¶Л¶јТЄО¬»¤Т»¶ЁКэБїµДЗлЗуДЪґжЗшєНЅб№ыДЪґжЗшЈ¬ТФУГАґЅшРРЗлЗуКэѕЭєНЅб№ыКэѕЭµДЅ»»»ЎЈХвР©ДЪґжЗш±ШРлТЄМбЗ°ФЪRDMA НшїЁЦРЅшРРЧўІбЈ¬ІЕДЬ±»RDMA ІЩЧчАыУГЎЈТтґЛЈ¬Ф¶іМ»сИЎДЈКЅ»№МṩБЛБЅёцДЪґжІЩЧчПа№ШµДЅУїЪЈєmalloc_buf єНfree_bufЈЁИз±н1ЛщКѕЈ©ЎЈХвБЅёцЅУїЪ·Ц±р±»УГАґЙкЗлєНКН·ЕФЪRDMA НшїЁЙПТСѕЧўІбєГµДДЪґжЗшЎЈОЮВЫКЗ·юОсЖч»№КЗїН»§¶ЛЈ¬ЛьГЗФЪУГRDMA ґ«КдКэѕЭЦ®З°РиТЄЅ«¶ФУ¦µДКэѕЭґж·ЕФЪНЁ№эmalloc_buf ЅУїЪЙкЗлµДДЪґжЗшЦРЈ¬ХвСщ»№ДЬ±ЈЦ¤Ф¶іМ»сИЎДЈКЅДЬ№»АыУГRDMA µДКэѕЭБгїЅ±ґМШРФЎЈИзНј1ЛщКѕЈ¬ГїёцДЪґжЗш¶јУРТ»їйН·ІїРЕПўЈ¬ёГН·ІїРЕПўІ»Ѕцє¬УРЗлЗуКЗ·сТСѕґпµЅ»тХЯЅб№ыКЗ·сТСѕЧј±ёѕНРчµДЧґМ¬РЕПўЈ¬»№°ьє¬ЗлЗуКэѕЭ»тХЯЅб№ыКэѕЭµДґуРЎЎЈБнНвЈ¬ГїёцЅб№ыДЪґжЗшµДН·ІїРЕПў»№є¬УРТ»ёц2ЧЦЅЪґуРЎµДґ¦АнК±јд±дБїЈ¬УГАґ±Јґж·юОсЖчґ¦Ан¶ФУ¦ЗлЗуЛщ»Ё·СµДК±јдЎЈёГ±дБї±»їН»§¶ЛУГАґЕР¶П·юОсЖчёєФШµДёЯµНЎЈ
ИзНј2ЛщКѕЈ¬єН·юОсЖч»ШёґДЈКЅТФј°·юОсЖчЕФВ·ДЈКЅПа±ИЈ¬Ф¶іМ»сИЎДЈКЅјИДЬ±ЈБф·ўПЦ1єН·ўПЦ2 Йжј°µЅµДУЕµгЈ¬УЦДЬ±ЬГв·ўПЦ1 єН·ўПЦ2 Йжј°µЅµДИ±µгЎЈКЧПИЈ¬єН·юОсЖч»ШёґДЈКЅТ»СщЈ¬Ф¶іМ»сИЎДЈКЅТІТААµ·юОсЖчАґґ¦АнЗлЗуЎЈТтґЛЈ¬ґ«НіRPC ЅУїЪїЙТФєЬИЭТЧµШКµПЦІўМṩёшЙПІгПµНіК№УГЈ¬Хв±ЈБфБЛ·юОсЖч»ШёґДЈКЅїЙ±аіМРФєГµДУЕµгЎЈФЪФ¶іМ»сИЎДЈКЅЦРЈ¬їН»§¶ЛІ»РиТЄФЩПыєД¶аёцRDMA ІЩЧчАґНкіЙТ»ёцЗлЗуЈ¬ТІІ»РиТЄ№ШЧўЅвѕціеН»µДОКМвЈ¬Хв±ЬГвБЛ·юОсЖчЕФВ·ДЈКЅµДИ±µгЎЈЖдґОЈ¬Ф¶іМ»сИЎДЈКЅІ»ТЄЗу·юОсЖчЅ«CPU ЧКФґАЛ·СФЪНЁ№эНшВзЅ«Ѕб№ы·ў»ШёшїН»§¶ЛµДІЩЧчЙПЈ¬ХвТ»µгКЗєНґ«НіµДИПЦЄУРєЬґуІ»Н¬µДЎЈФ¶іМ»сИЎДЈКЅЦ»ТЄЗу·юОсЖчЅ«ґ¦АнНкµДЅб№ы»єґжФЪ±ѕµШµДДЪґжЦРЈ¬ІўТЄЗуїН»§¶ЛНЁ№эRDMA ¶БІЩЧчЦч¶ЇґУ·юОсЖчДЪґжЦР»сИЎЅб№ыЎЈТтґЛЈ¬Ф¶іМ»сИЎДЈКЅѕНІ»»бКЬµЅ·юОсЖчRDMA НшїЁФЪRDMA КдіцІЩЧчЙПРФДЬЖїѕ±µДПЮЦЖЈ¬¶шЗТДЬ№»АыУГ·юОсЖчRDMA НшїЁёЯРФДЬµДRDMA КдИлІЩЧчЎЈХв±ЈБфБЛ·юОсЖчЕФВ·ДЈКЅµДУЕµгЈ¬±ЬГвБЛ·юОсЖч»ШёґДЈКЅµДИ±µгЎЈНЁ№эід·ЦАыУГRDMA НшїЁµДРФДЬ·З¶ФіЖРФЈ¬Ф¶іМ»сИЎДЈКЅ»сµГБЛ±И·юОсЖч»ШёґДЈКЅєН·юОсЖчЕФВ·ДЈКЅёьёЯµДРФДЬЎЈ
2.3ОКМвУлМфХЅ
КµПЦФ¶іМ»сИЎДЈКЅ±ШРлТЄЅвѕцБЅёцОКМвЈєµЪТ»ёцОКМвКЗїН»§¶ЛУ¦ёГФЪКІГґК±єтґУ·юОсЖч»сИЎЅб№ыЈ¬µЪ¶юёцОКМвКЗїН»§¶ЛТ»ґОУ¦ёГ»сИЎµДЅб№ыКэѕЭОЄ¶аґуЎЈ±ѕВЫОД·Ц±рМбіцАґЅб№ыКэѕЭ»мєПґ«Кд»ъЦЖєНRDMAНшїЁРФДЬМШХчМбИЎ»ъЦЖАґЅвѕцПаУ¦ОКМвЎЈ
Ѕб№ыКэѕЭ»мєПґ«Кд»ъЦЖЈєёГ»ъЦЖКЧПИ»бІЙУГІ»јд¶П»сИЎ·ЅКЅАґЅ«Ѕб№ыКэѕЭґУ·юОсЖчґ«КдµЅїН»§¶ЛЈ¬µ«КЗЈ¬Из№ыЖдјаІвµЅІ»јд¶П»сИЎ·ЅКЅЛщРиТЄµДRDMA ¶БІЩЧчКэДїґуУЪТ»¶ЁµДгРЦµЈЁёГгРЦµјґОЄTЈ©К±Ј¬Ль»бЧФ¶ЇЗР»»µЅ·юОсЖч»Шёґ·ЅКЅЎЈ·юОсЖч»Шёґ·ЅКЅјґОЄ·юОсЖч»ШёґДЈКЅІЙУГµДКэѕЭґ«Кд·ЅКЅЈє·юОсЖчНЁ№эRDMA РґІЩЧчЅ«Ѕб№ыЦч¶Ї·ў»ШёшїН»§¶ЛЎЈЅб№ыКэѕЭ»мєПґ«Кд»ъЦЖДЬ№»ЦЗДЬµШФЪІ»јд¶П»сИЎ·ЅКЅєН·юОсЖч»Шёґ·ЅКЅЦ®јдЧцЗР»»Ј¬ТФФЪ·ГОКСУіЩЎўIOPS єНїН»§¶ЛCPU К№УГВКЦ®јдІ»¶ПµШЧцИЁєвЎЈTµДСЎФсРиТЄТАѕЭѕЯМеµДУІјюЕдЦГЗйїцЈ¬°ьАЁRDMA НшїЁµДЕдЦГЎў»ъЖчCPU µДЕдЦГµИЎЈ
RDMAНшїЁРФДЬМШХчМбИЎ»ъЦЖЈєёГ»ъЦЖДЬ№»ЧФ¶ЇёщѕЭRDMA НшїЁµДУІјюМШРФєНПµНіЅб№ыґуРЎµД·¶О§ЙиЦГFSЈ¬ёшПµНіМṩЧоУЕµДРФДЬЎЈ¶ФУЪДіёцМШ¶ЁµДПµНіЈ¬Ф¶іМ»сИЎДЈКЅ»бМбЗ°Ѕ«ёГПµНіФЛРРТ»¶ОК±јдЈ¬ІўКХјЇёГПµНіЦРГїёцRPC µчУГµДЅб№ыґуРЎЎЈФ¶іМ»сИЎДЈКЅ»№»бМбЗ°№№ЅЁєГFSµДјЇєПЈ¬јЇєПЦРє¬УРЛщУРїЙДЬµДFS КэЦµЈ¬ГїёцКэЦµ¶ФУ¦µДIOPS КЗФ¶іМ»сИЎДЈКЅёщѕЭRDMA НшїЁУІјюМШРФНЁ№эТ»ґОІвКФ¶шЧФ¶Ї»сµГµДЎЈИ»єуЈ¬¶ФУЪFS јЇєПЦРµДГїёцКэЦµЈ¬Ф¶іМ»сИЎДЈКЅ»бјЖЛгФЪПµНіМṩµДЛщУРЅб№ыґуРЎµДЗйїцПВЈ¬ёГКэЦµИГПµНі»сµГµДРФДЬЎЈДЬ№»ИГПµНі»сµГµДЧоґу»ЇРФДЬµДКэЦµјґОЄёГПµНі¶ФУ¦µДЧоУЕFSЎЈ
3RPCКµПЦ·ЅКЅ
3.1ѕЯМе±аіМЅУїЪУлКµК©·ЅКЅ
ОЄБЛСйЦ¤Ф¶іМ»сИЎДЈКЅ¶ФЙПІгПµНіµДУРР§РФєНБјєГµДїЙ±аіМРФЈ¬ЧчХЯ»щУЪФ¶іМ»сИЎДЈКЅЙијЖІўКµПЦБЛДЪґжКэѕЭївJakiroЎЈJakiro °ьє¬БЅёцЦчТЄµДДЈїйЈєТ»ёцКЗУГАґ±Јґжkey-value ¶ФµДДЪґжКэѕЭЅб№№Ј¬БнТ»ёцКЗУГАґНкіЙRPC µчУГµДНЁРЕРТйЎЈJakiro ДЪґжКэѕЭЅб№№µДЙијЖ¶АБўУЪФ¶іМ»сИЎДЈКЅЈ¬¶шНЁРЕРТйµДЙијЖКЗК№УГФ¶іМ»сИЎДЈКЅµДЎЈ
ФЪJakiro ЦРЈ¬·юОсЖчПтїН»§¶Л±©В¶ґ«НіµДRPC ЅУїЪЈ¬їН»§¶ЛНЁ№эµчУГХвР©RPC ЅУїЪНкіЙkey-value ¶ФµД¶Б»тХЯРґІЩЧчЎЈµ±їН»§¶ЛµчУГRPC К±Ј¬НЁРЕРТйёєФрНкіЙХвР©RPCµчУГЈ¬ІўПтїН»§¶Л·µ»ШµчУГЅб№ыЎЈѕЯМеАґЛµЈ¬НЁРЕРТйµД№¤ЧчБчіМИзПВЈє
1. ·ўЛНЗлЗуЎЈµ±їН»§¶ЛЅшРРRPC µчУГєуЈ¬їН»§¶ЛПЯіМ»б¶ФµчУГµДєЇКэј°ЖдІОКэЅшРРРтБР»ЇЈ¬ІўЅ«РтБР»ЇєуµДКэѕЭґж·ЕµЅНЁ№эmalloc_buf ЙкЗлµДЗлЗуДЪґжЗшЦРЎЈИ»єуЈ¬їН»§¶ЛПЯіМµчУГclient_send ЅУїЪ·ўЛНЗлЗуЎЈclient_send »бЧј±ёєГЗлЗуДЪґжЗшµДН·ІїРЕПўЈ¬ІўЅ«Т»ёц1 ЧЦЅЪґуРЎµДОІІї±дБїЈЁ±дБїµДЦµЙиОЄ1Ј©Ч·јУФЪЗлЗуКэѕЭµДОІІїЎЈµ±ХвР©ІЩЧч¶јНкіЙєуЈ¬client_send µчУГRDMAРґІЩЧчЅ«ЗлЗу·ўЛНµЅ·юОсЖчЦР¶ФУ¦µДЗлЗуДЪґжЗшЦРЎЈФЪЗлЗуКэѕЭµДОІІїФЩјУТ»ёцОІІї±дБїКЗ±ШТЄµДЈ¬ТтОЄµ±·юОсЖчјмІвµЅОІІї±дБї±дОЄ1 К±Ј¬ѕНЛµГчїН»§¶Л·ўЛНЗлЗуµДІЩЧчТСѕИ«ІїНкіЙБЛЎЈ
2. ґ¦АнЗлЗуЎЈ·юОсЖчПЯіМ»бЦЬЖЪРФµШµчУГserver_recv ЅУїЪАґ»сµГАґЧФїН»§¶ЛµДЗлЗуЎЈµ±server_recv јмІвµЅЗлЗуДЪґжЗшН·ІїµДЧґМ¬РЕПўТСѕѕНРчІўЗТЗлЗуКэѕЭД©¶ЛµДОІІї±дБї±дОЄ1 К±Ј¬Ль»бЅ«ЗлЗу·µ»Шёш·юОсЖчПЯіМЎЈ·юОсЖчПЯіМДГµЅЗлЗуєуЈ¬»б·ґРтБР»ЇЗлЗуѕЯМеµчУГµДєЇКэТФј°ПаУ¦µДІОКэЈ¬ІўФЪЛьЛщ№ЬАнµДДЪґжКэѕЭЅб№№ЙПЦґРРёГЗлЗуЎЈµ±ЗлЗуЦґРРНкіЙєуЈ¬·юОсЖчПЯіМ¶ФЦґРРЅб№ыЅшРРРтБР»ЇЈ¬Ѕ«РтБР»ЇєуµДКэѕЭґж·ЕµЅНЁ№эmalloc_buf ЙкЗлµДЅб№ыДЪґжЗшЦРЈ¬ІўµчУГserver_send ЅУїЪЎЈserver_send Чј±ёєГЅб№ыДЪґжЗшµДН·ІїРЕПўєу·µ»ШЎЈ
3. ґ«КдЅб№ыЎЈФЪЅ«ЗлЗу·ўЛНёш·юОсЖчєуЈ¬їН»§¶ЛПЯіМѕНµчУГclient_recv ЅУїЪ»сИЎЗлЗуµДЅб№ыЎЈclient_recv »бК№УГІ»јд¶П»сИЎ·ЅКЅ»тХЯ·юОсЖч»Шёґ·ЅКЅЅ«Ѕб№ыґУ·юОсЖчµДДЪґжґ«КдµЅїН»§¶ЛµДДЪґжЈ¬ІўЅ«Ѕб№ы·µ»ШёшїН»§¶ЛПЯіМЎЈїН»§¶ЛПЯіМ¶ФЅб№ыЅшРР·ґРтБР»ЇЈ¬ІўЅ«Ѕб№ыЧоЦХ·µ»ШёшЙПІгПµНіЎЈ
ґУЙПКцїЙТФїґіцЈ¬Jakiro НЁРЕРТйФЪФ¶іМ»сИЎДЈКЅЙПµДКµПЦєНФЪґ«НіTCP/IP ЅУїЪЙПµДКµПЦјёєхГ»УРґуµДІо±рЈ¬Ф¶іМ»сИЎДЈКЅ¶ФУЪJakiro НЁРЕРТйАґЛµЦ»КЗТ»ёцСЪёЗµЧІгёґФУРФµДНЁРЕївЎЈХвТІЅшТ»ІЅЦ¤ГчБЛФ¶іМ»сИЎДЈКЅѕЯУРєЬєГµДїЙ±аіМРФЎЈ
JakiroЦРФ¶іМ»сИЎДЈКЅЦРёєФрRDMAґ«КдµДНЁРЕївІЙУГµДКЗMellanox №«ЛѕМṩµДrdmacm єНibverbs НЁРЕївЎЈФЪJakiro ЦРЈ¬·юОсЖчПЯіМєНїН»§¶ЛПЯіМЦ±ЅУ·ГОКЖд»ъЖчЙПµДДЪґжЗшєНRDMA НшїЁЈ¬ТФ»сИЎПыПўЈЁЗлЗу»тЅб№ыЈ©·ўЛН/ЅУКХµДКВјюЎЈН¬К±Ј¬Гїёц·юОсЖчПЯіМТЄёєФрЛщУРУР№ШКэѕЭРтБР»Ї/·ґРтБР»ЇЎўКэѕЭ·ўЛН/ЅУКХТФј°ЗлЗуґ¦АнµДПа№Ш№¤ЧчЎЈ
3.2К±јдµД»сИЎУлРФДЬµчУЕ
±ѕВЫОДФЪФ¶іМ»сИЎДЈКЅПВЈ¬ЅвѕцБЛБЅёцОКМвЈєµЪТ»ёцОКМвКЗїН»§¶ЛУ¦ёГФЪКІГґК±єтґУ·юОсЖч»сИЎЅб№ыЈ¬µЪ¶юёцОКМвКЗїН»§¶ЛТ»ґОУ¦ёГ»сИЎµДЅб№ыКэѕЭОЄ¶аґуЎЈ
1.»сИЎЅб№ыµДК±јдЈє
client_id ±нКѕДіёцїН»§¶ЛЈ¬УГRPC_id ±нКѕДіЦЦАаРНµДRPC µчУГЈ¬Н¬К±Н¬Т»АаРНµДRPC µчУГФЪЦґРРК±јдµДКэБїј¶ЙПІо±рІ»ґуЎЈДЗГґЈ¬¶ФУЪГї¶Ф?client_id,RPC_id?Ј¬їН»§¶ЛєН·юОсЖч¶ј»бО¬»¤Т»ёцґ«Кд·ЅКЅ±кЦѕmode_flagЈ¬ёГ±кЦѕУГАґ±нКѕФ¶іМ»сИЎДЈКЅДїЗ°ХэФЪК№УГµДґ«Кд·ЅКЅЎЈmode_flag Ц»ДЬ±»Жд¶ФУ¦µДїН»§¶ЛАґРЮёДЈ¬ёГїН»§¶ЛНЁ№э±ѕµШµДДЪґжРґРЮёД±ѕµШО¬»¤µДmode_flagЈ¬НЁ№эRDMA РґІЩЧчФ¶іМРЮёД·юОсЖчО¬»¤µДmode_flagЎЈФЪПµНіёХЖф¶ЇК±Ј¬mode_flag ±»ЙиЦГОЄІ»јд¶П»сИЎ·ЅКЅ¶ФУ¦µД±кЦѕЎЈТтґЛЈ¬їН»§¶Л»бІ»НЈµШНЁ№эRDMA ¶БІЩЧчґУ·юОсЖчДЪґжЦР»сИЎЅб№ыЎЈИз№ыїН»§¶ЛБ¬Рш5 ґОµДRDMA ¶БІЩЧч¶јГ»УРіЙ№¦µШЅ«Ѕб№ы»сИЎµЅ±ѕµШЈ¬ЛµГч·юОсЖчґ¦АнёГЗлЗуµДК±јд±ИЅПі¤Ј¬ДЗГґїН»§¶ЛѕН»бЅ«±ѕµШєН·юОсЖчµДmode_flag ёьРВіЙ·юОсЖч»Шёґ·ЅКЅ¶ФУ¦µД±кЦѕЎЈФЪ±кЦѕёьРВНкіЙєуЈ¬їН»§¶ЛѕНІ»ФЩµчУГRDMA ¶БІЩЧчЈ¬¶шКЗµИґэЅб№ыУЙ·юОсЖчНЁ№эRDMA РґІЩЧч·ўЛН»ШАґЎЈИз№ыїН»§¶Лµ±З°ґ¦УЪ·юОсЖч»Шёґ·ЅКЅЈ¬Ль»бјмІвЅб№ыДЪґжЗшН·ІїРЕПўЦРµДґ¦АнК±јд±дБїЎЈµ±ёГ±дБї±нКѕµД·юОсЖчґ¦АнЗлЗуК±јд±д¶МК±Ј¬їН»§¶Л»бРЮёД±ѕµШєН·юОсЖчµДmode_flagЈ¬Ѕ«ЖдёьРВіЙІ»јд¶П»сИЎ·ЅКЅЎЈ
РиТЄЛµГчµДКЗЈ¬УЙУЪїН»§¶ЛёьРВ·юОсЖчµДmode_flag УГµДКЗRDMA ІЩЧчЈ¬¶шRDMA ІЩЧчµД№эіМКЗ·юОсЖчµДCPU ОЮ·ЁЦЄПюµДЈ¬ТтґЛЈ¬µ±mode_flag ¶ФУ¦µДКЗІ»јд¶П»сИЎ·ЅКЅµДЧґМ¬К±Ј¬їН»§¶ЛёьРВmode_flag К±»бґжФЪїН»§¶ЛЗР»»µЅБЛ·юОсЖч»Шёґ·ЅКЅЎў¶ш·юОсЖчИФНЈБфФЪІ»јд¶П»сИЎ·ЅКЅµДїЙДЬЎЈґЛК±Ј¬їН»§¶ЛІ»»бИҐ»сИЎЅб№ыЈ¬·юОсЖчТІІ»»бЦч¶ЇЅ«Ѕб№ы·ў»ШЈ¬їН»§¶ЛєН·юОсЖчЦ®јдґжФЪЧЕТ»ЦЦЛАЛшЧґМ¬Ј¬ХыёцПµНіОЮ·ЁјМРшПтЗ°ЦґРРЎЈЧчХЯНЁ№эИГ·юОсЖчЦЬЖЪРФµШјмІвmode_flag АґЅвѕцХвёцОКМвЎЈµ±·юОсЖчОЄїН»§¶ЛЧј±ёєГЅб№ыєуЈ¬»бКЧПИјмІв¶ФУ¦µДmode_flagЈ¬ІўёщѕЭmode_flag µДЧґМ¬АґЦґРР¶ФУ¦µДКэѕЭґ«Кд·ЅКЅЎЈµ«КЗґЛК±ЦґРРµДКэѕЭґ«Кд·ЅКЅІўІ»Т»¶ЁКЗїН»§¶ЛТЄЗуµДКэѕЭґ«Кд·ЅКЅЎЈ·юОсЖчФЪЦґРРНкґ«Кд·ЅКЅєуЈ¬Гїёф1 ОўГл»бФЩјмІвmode_flag µДЧґМ¬Ј¬Из№ы·ўПЦmode_flag µДЧґМ¬УРёД±дЈ¬ѕНЦґРРРВµДКэѕЭґ«Кд·ЅКЅЎЈХвСщѕНґтЖЖБЛmode_flag ЗР»»К±їЙДЬґшАґµДЛАЛшЧґМ¬ЎЈµ±mode_flag ¶ФУ¦µДКЗ·юОсЖч»Шёґ·ЅКЅК±Ј¬їН»§¶ЛёьРВmode_flag »бґжФЪїН»§¶ЛЗР»»µЅІ»јд¶П»сИЎ·ЅКЅЎў¶ш·юОсЖчИФНЈБфФЪ·юОсЖч»Шёґ·ЅКЅµДїЙДЬЎЈґЛК±Ј¬Ѕб№ы»бґ«КдµЅїН»§¶ЛБЅґОЈ¬Т»ґОКЗїН»§¶ЛЦч¶Ї»сИЎµДЈ¬Т»ґОКЗ·юОсЖчЦч¶Ї·ў»ШµДЈ¬µ«ХвІ»»бУ°ПмЅб№ыХэИ·µШґУ·юОсЖчґ«КдµЅїН»§¶ЛЎЈ
БнНвЈ¬mode_flag µДёД±д»№РиТЄїјВЗі¤ОІЈЁlong-tailЈ©ПЦПуЎЈі¤ОІПЦПуЦёµДКЗФЪРн¶аПаН¬АаРНµДµчУГЦ®ЦРЈ¬»бУРј«ЙЩКэµДµчУГіцПЦЦґРРК±јдєЬі¤µДЗйїцЎЈі¤ОІПЦПу»бК№їН»§¶ЛОЮ·ЁНЁ№эІ»јд¶П»сИЎ·ЅКЅіЙ№¦»сИЎЅб№ыЈ¬µјЦВЅб№ыКэѕЭ»мєПґ«Кд»ъЦЖЅшРРІ»±ШТЄµД·ЅКЅЗР»»ЎЈОЄБЛЅвѕцХвёцОКМвЈ¬Ѕб№ыКэѕЭ»мєПґ«Кд»ъЦЖЦ»УРµ±Б¬РшNёцЗлЗуЈЁN > 1Ј©ёцRPC µчУГ¶јѕАъБЛT ґОRDMA ¶БІЩЧч¶шГ»УРіЙ№¦»сИЎµЅЅб№ыК±Ј¬ІЕ»бИГїН»§¶ЛєН·юОсЖчґУІ»јд¶П»сИЎ·ЅКЅЗР»»µЅ·юОсЖч»Шёґ·ЅКЅЎЈ·сФтЈ¬Из№ыЦ»УР1 ёцRPC µчУГѕАъБЛTtry ґОRDMA ¶БІЩЧч¶шГ»УРіЙ№¦»сИЎµЅЅб№ыЈ¬ДЗГґѕНІ»ЅшРРґ«Кд·ЅКЅµДЗР»»ЎЈКµСйЅб№ыПФКѕЈ¬µ±їН»§¶ЛЗлЗуІ»»бґшАґєЬґуµДЦґРРёєФШК±Ј¬Ц»УР0.2% µДRPC µчУГ»бѕАъі¤ОІПЦПуЈ¬Тт¶шБ¬РшБЅёцЙхЦБ¶аёцRPC µчУГ¶јѕАъі¤ОІПЦПуµДёЕВКј«µНЎЈ
2. »сИЎЅб№ыµДґуРЎЈє
ФЪФ¶іМ»сИЎДЈКЅЦРЅ«Ѕб№ыЅфБЪЧЕН·ІїРЕПўґжґўФЪЅб№ыДЪґжЗшЦРЈ¬ІўОЄГїёцїН»§¶ЛЙиЦГТ»ёцФ¶іМ»сИЎЅб№ыґуРЎµД±дБїЈ¬јЗОЄFSЎЈГїёцїН»§¶ЛЦ»µчУГТ»ґОRDMA ¶БІЩЧчЈ¬Ѕ«Ѕб№ыДЪґжЗшЦРµДН·ІїРЕПўТФј°FS ґуРЎµДЅб№ыКэѕЭТ»Н¬»сИЎµЅ±ѕµШЎЈИ»єуїН»§¶Л»бјмІвН·ІїРЕПўЦРјЗВјµДЅб№ыКэѕЭµДКµјКґуРЎЈ¬Ц»УРµ±КµјКґуРЎґуУЪFS К±Ј¬їН»§¶ЛІЕРиТЄФЩ·ўЛНТ»ґОRDMA ¶БІЩЧчЅ«УаПВµДКэѕЭИЎ»ШЎЈХвЦЦ·ЅКЅїЙТФґу·щЅµµННкіЙТ»ґОRPC µчУГЛщРиТЄµДRDMA ¶БІЩЧчКэДїЈ¬УИЖдКЗµ±Ѕб№ыКэѕЭНЁіЈ¶ј±ИЅПРЎµДЗйїцПВЎЈ
FS µДЙиЦГ¶ФПµНіРФДЬµДУ°ПмК®·ЦПФЦшЈ¬ТтОЄЛьѕц¶ЁБЛФ¶іМ»сИЎЅб№ыЛщРиТЄµДRDMA ІЩЧчКэДїЎЈАэИзЈ¬јЩЙиДіёцПµНіµДRPC µчУГЅб№ыµДґуРЎФЪ257 ЧЦЅЪµЅ512 ЧЦЅЪЦ®јдЎЈИз№ыЅ«FS ЙиЦГОЄ256 ЧЦЅЪЈ¬ДЗГґїН»§¶ЛѕНЦБЙЩРиТЄ2 ґОRDMA¶БІЩЧчІЕДЬЅ«RPC µчУГµДЅб№ы»сИЎµЅ±ѕµШЈ¬Хв»бАЛ·СRDMA НшїЁµДIOPS ЧКФґЈ¬ФміЙПµНіРФДЬµДПВЅµЎЈИз№ыЅ«FS ЙиЦГОЄ512 ЧЦЅЪЈ¬ДЗГґЛщУРµДЅб№ы¶јїЙТФНЁ№эТ»ґОRDMA ¶БІЩЧчѕНїЙТФ»сИЎµЅїН»§¶Л±ѕµШЎЈТтґЛЈ¬јґ±гRDMA НшїЁµДRDMAКдИл¶БІЩЧчФЪ512 ЧЦЅЪЙПµДIOPSЈЁ7.34MOPSЈ©ТЄµНУЪЖдФЪ256 ЧЦЅЪЙПµДIOPSЈЁ10.79MOPSЈ©Ј¬µ«КЗЅ«FS ЙиОЄ512 ЧЦЅЪДЬ№»ёшПµНіМṩ5.41MOPS µДРФДЬЈ¬¶шЅ«FS ЙиОЄ256 ЧЦЅЪИґЦ»ДЬёшПµНіМṩ3.75MOPS µДРФДЬЎЈ

¶ФУЪДіёцМШ¶ЁµДПµНіЈ¬Ф¶іМ»сИЎДЈКЅ»бМбЗ°Ѕ«ёГПµНіФЛРРТ»¶ОК±јдЈ¬ІўКХјЇёГПµНіЦРГїёцRPC µчУГµДЅб№ыґуРЎЎЈФ¶іМ»сИЎДЈКЅ»№»бМбЗ°№№ЅЁєГFS µДјЇєПЈ¬јЇєПЦРє¬УРЛщУРїЙДЬµДFS КэЦµЈ¬ГїёцКэЦµ¶ФУ¦µДIOPS КЗФ¶іМ»сИЎДЈКЅёщѕЭRDMA НшїЁУІјюМШРФНЁ№эТ»ґОІвКФ¶шЧФ¶Ї»сµГµДЎЈИ»єуЈ¬¶ФУЪFS јЇєПЦРµДГїёцКэЦµЈ¬Ф¶іМ»сИЎДЈКЅ»бјЖЛгФЪПµНіМṩµДЛщУРЅб№ыґуРЎµДЗйїцПВЈ¬ёГКэЦµИГПµНі»сµГµДРФДЬЎЈДЬ№»ИГПµНі»сµГµДЧоґу»ЇРФДЬµДКэЦµјґОЄёГПµНі¶ФУ¦µДЧоУЕFSЎЈµ±И»Ј¬FS јЇєПЦРµДКэЦµІўІ»КЗОЮПЮ¶аµДЈ¬¶шКЗУРЙППЮєНПВПЮµДЎЈјЇєПЦРµДЙППЮєНПВПЮТІКЗёщѕЭRDMA НшїЁµДУІјюМШРФЙи¶ЁµДЎЈАэИзЈ¬¶ФУЪЧчХЯК№УГµДІвКФјЇИєАґЛµЈ¬FS јЇєПµДПВПЮЙиЦГОЄ256 ЧЦЅЪЈ¬ТтОЄРЎУЪ256 ЧЦЅЪµДFS І»»бМбёЯїН»§¶ЛФ¶іМ»сИЎЅб№ыµДРФДЬЈЁИзНј3ЛщКѕЈ©ЎЈ

ТтОЄRDMA НшїЁНЁ№эRDMA ІЩЧчґ«КдКэѕЭК±ОЮ·Ё±ЬГв¶оНвµДУІјюїЄПъЈЁІОјыНј4Ј©ЎЈН¬К±Ј¬FS јЇєПµДЙППЮЙиЦГОЄ1024ЧЦЅЪЈ¬ТтОЄґуУЪ1024 ЧЦЅЪµДFS ТІІ»»бМбёЯїН»§¶ЛФ¶іМ»сИЎЅб№ыµДРФДЬЈ¬ТтОЄ¶ФRDMA НшїЁАґЛµЈ¬ґЛК±іЙОЄРФДЬЖїѕ±µДКЗНшВзґшїн¶шІ»КЗIOPSЎЈµ±НшВзґшїніЙОЄРФДЬЖїѕ±К±Ј¬У°ПмРФДЬµДЦчТЄКЗґ«КдКэѕЭµДґуРЎЈ¬¶шІ»КЗRDMA НшїЁЙП¶оНвµДУІјюїЄПъЎЈ
4КµСйУлРФДЬ·ЦОц
±ѕВЫОДК№УГТ»ёц»щУЪInfiniBand НшВзґоЅЁµДјЇИєЅшРРБЛКµСйІвЖАЎЈХвёцјЇИєЧЬ№ІУЙ8 МЁ»ъЖч№№іЙЈ¬ГїМЁ»ъЖчЕд±ёБЛБЅёцIntel Xeon E5-2640 v2 µД8 єЛРДCPUЈЁЦчЖµОЄ2.0GHzЈ©Ўў96 GB ґуРЎµДДЪґжєНТ»ёцРНєЕОЄMT27500 µДMellanox ConnectX-3InfiniBand НшїЁЈЁґшїнОЄ40GbpsЈ©ЎЈЛщУРХвР©»ъЖчНЁ№эРНєЕОЄInfiniScale-IV µД18їЪMellanox Ѕ»»»»ъБ¬ЅУФЪТ»ЖрЎЈГїМЁ»ъЖчФЛРРUbuntu 14.04 µДІЩЧчПµНіЈ¬ІўЗТ°ІЧ°БЛMellanox МṩµДЦ§іЦInfiniBand µДЗэ¶ЇіМРтЈ¬Зэ¶ЇіМРтµДРНєЕОЄMLNXOFED-LINUX-2.3-2.0.0ЎЈ
1. ІвКФКэѕЭјЇЈєЧчХЯСЎФсІвКФКэѕЭјЇЦРµДkey µДґуРЎОЄ16 ЧЦЅЪЈ¬value µДґуРЎОЄ32 ЧЦЅЪЎЈёГІвКФКэѕЭјЇЦРkey-value ¶ФµДґуРЎєНКµјККэѕЭЦРРДАпФЛРРµДДЪґжКэѕЭївµДkey-value ¶ФґуРЎАаЛЖЎЈ¶ФУЪkey ѕщФИ·ЦІјІвКФјЇЈ¬ЧчХЯК№УГYCSB»щЧјІвКФіМРтѕщФИµШІъЙъkey-value¶ФЎЈ¶ФУЪkey ·ЗѕщФИ·ЦІјІвКФјЇЈ¬ЧчХЯК№УГYCSB ІўТАѕЭІОКэОЄ.99 µДZipf·ЦІјІъЙъkey-value ¶ФЎЈКµСйЧЬ№ІІъЙъБЛ1.28 ТЪёцkey-value ¶ФЈ¬Гїёцkey-value ¶Ф±»ІЩЧч20 ґОЎЈ¶ФУЪvalue ґуРЎОЄ32 ЧЦЅЪµДІвКФјЇАґЛµЈ¬Ф¶іМ»сИЎДЈКЅЅ«FS µДґуРЎЙиОЄ256 ЧЦЅЪЎЈ
2. ¶Ф±ИПµНіСЎФсЈєЧчХЯЅ«Jakiro єНБЅёцІЙУГ·юОсЖч»ШёґДЈКЅµДДЪґжkey-value КэѕЭїв¶Ф±ИЎЈµЪТ»ёцДЪґжkey-value КэѕЭївјЗЧцServerReplyЈ¬ЛьµДДЪґжКэѕЭЅб№№єНJakiro µДДЪґжКэѕЭЅб№№Т»ДЈТ»СщЈ¬ОЁТ»єНJakiro І»Т»СщµДѕНКЗЛьНкИ«ІЙУГ·юОсЖч»ШёґДЈКЅАґґ«КдЅб№ыЎЈµЪ¶юёцДЪґжkey-value КэѕЭївјЗЧцRDMA-MemcachedЈ¬ЛьКЗУЙ¶нєҐ¶нЦЭБўґуС§µДСРѕїИЛФ±їЄ·ўµДАыУГRDMA МбЙэРФДЬµДMemcachedЎЈ
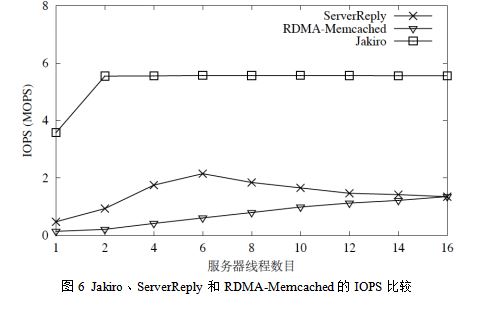
3. НМНВБї±ИЅПЈєНј6Х№КѕБЛµ±value ґуРЎОЄ32 ЧЦЅЪК±Ј¬JakiroЎўServerReply єНRDMAMemcachedµДIOPSЎЈJakiro µДIOPS ·еЦµОЄ5.5 MOPSЈ¬ёГКэЦµЗЎєГОЄ·юОсЖчRDMA НшїЁµДRDMA КдИл¶БІЩЧчIOPS ·еЦµµДТ»°лЈЁ11.2MOPSЈ¬ИзНј6ЛщКѕЈ©ЎЈёГЅб№ыТІЦ¤ГчБЛФ¶іМ»сИЎДЈКЅОЄJakiro ЙиЦГµДФ¶іМ»сИЎЅб№ыґуРЎFSЈЁ256 ЧЦЅЪЈ©КЗЧоУЕµДЎЈ¶ФJakiro АґЛµЈ¬НкіЙТ»ґОkey-value ¶ФµДRPC µчУГЖЅѕщЦ»РиТЄ2.005 ґОRDMA ІЩЧчЈєТ»КЗїН»§¶ЛНЁ№эТ»ґОRDMA РґІЩЧчЅ«ЗлЗу·ўЛНёш·юОсЖчЈ¬¶юКЗїН»§¶ЛНЁ№э1.005 ґОRDMA ¶БІЩЧчЅ«Ѕб№ыґУ·юОсЖчµДДЪґжЦРФ¶іМ»сИЎµЅ±ѕµШЎЈ256ЧЦЅЪµДFS јёєхГ»УРАЛ·СПµНіЦРµДНшВзЧКФґЎЈ
Jakiro µДIOPS ·еЦµТЄ±ИServerReply µДIOPS ·еЦµЈЁ2.1MOPSЈ©ёЯіц158%Ј¬±ИRDMA-Memcached µДIOPS ·еЦµЈЁ1.3MOPSЈ©ёЯіц310%ЎЈ
РиТЄЛµГчµДКЗЈ¬µ±Jakiro µДїН»§¶Л»ъЖчЖф¶Їёь¶аКэДїµДїН»§¶ЛПЯіМК±Ј¬JakiroµДIOPS »б»єВэПВЅµЈ¬ИзНј3.11ЛщКѕЎЈХвКЗТтОЄїН»§¶Л»ъЖчПт·юОсЖч·ўЛНµДRDMA¶БРґІЩЧч¶ФїН»§¶Л»ъЖчµДRDMA НшїЁАґЛµКЗКдіцµДЈ¬Из№ыїН»§¶Л»ъЖчЙПЖф¶ЇµДїН»§¶ЛПЯіМКэДїФцјУЈ¬ЛьГїГлДЬ№»Пт·юОсЖч·ўЛНµДRDMA ІЩЧчКэУЙУЪїЙА©Х№РФµДОКМвѕН»бПВЅµЎЈµ«КЗЈ¬јґК№ФЪГїМЁїН»§¶Л»ъЖчЙПЖф¶Ї16 ёцПЯіМЈЁ7 МЁїН»§¶Л»ъЖчЧЬ№І112 ёцПЯіМЈ©Ј¬Jakiro µДIOPS ИФИ»ДЬ№»ґпµЅ3.1 MOPSЎЈХвёцIOPS Цµ»№КЗ»бёЯУЪServerReply єНRDMA-Memcached µДIOPS ·еЦµЎЈ
4. СУіЩµД±ИЅПЈєµ±value ґуРЎОЄ32 ЧЦЅЪК±Ј¬Jakiro µДkey-value ¶Ф¶БРґЗлЗуµДЖЅѕщСУіЩОЄ5.78ОўГлЈ¬ёГКэЦµТЄ±ИServerReply µДЖЅѕщСУіЩЈЁ12.06 ОўГлЈ©УЕ108%Ј¬±ИRDMAMemcachedµДЖЅѕщСУіЩЈЁ14.76 ОўГлЈ©УЕ155%ЎЈНј7Х№КѕБЛХвИэёцПµНіФЪIOPSґпµЅ·еЦµК±Ј¬ёчЧФСУіЩµДАЫјЖёЕВК·ЦІјЈЁCumulative Probability DistributionЈ¬јтіЖCPDЈ©ЎЈґУёГНјїЙТФ№ЫІмµЅЈ¬ServerReply УР15% µДRPC µчУГµДСУіЩТЄ±ИJakiro µДСУіЩµНЎЈФміЙХвЦЦПЦПуµДФТтУРБЅµгЈєЈЁ1Ј©µҐёцRDMA РґІЩЧчµДСУіЩТЄ±ИµҐёцRDMA ¶БІЩЧчµДСУіЩµНЎЈґУRDMA НшїЁУІјюІгГжЙПАґ·ЦОцЈ¬RDMA РґІЩЧчЛщРиТЄµДЧґМ¬єНУІјюІЩЧч±ИRDMA ¶БІЩЧчµДТЄЙЩЈ¬ТтґЛЖдРФДЬТЄУЕУЪRDMA ¶БІЩЧчЎЈ
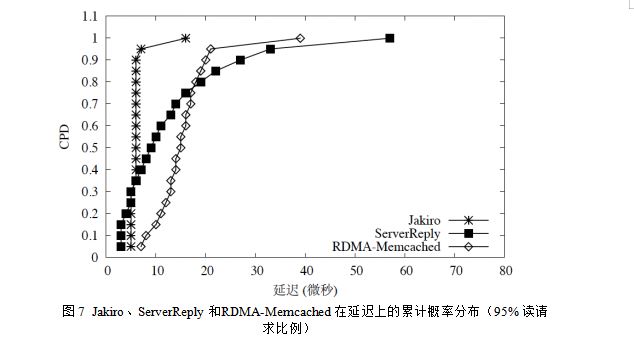
БнНвЈ¬±ѕВЫОДМбіцµДЅб№ыКэѕЭ»мєПґ«Кд»ъЦЖ°пЦъJakiro єЬєГµШИЁєвБЛСУіЩєНIOPSЎЈФЪJakiro ЦРЈ¬Т»Р©СУіЩєЬёЯЈЁ15 ОўГлµЅ17 ОўГлЈ©µДRPC µчУГРиТЄ4 µЅ8 ґОRDMA ІЩЧчАґНкіЙЗлЗуµД·ўЛНєНЅб№ыµД»сИЎЈ¬¶шѕЯУРХэіЈСУіЩµДRPC µчУГЦ»РиТЄ2 ґОRDMA ІЩЧчѕНДЬНкіЙЎЈµ«КЗЈ¬РиТЄ¶аУЪ2 ґОRDMA ІЩЧчАґНкіЙµДRPC µчУГЦ»ХјЛщУРЗлЗуµД0.2%Ј¬ІўЗТГ»УРіцПЦБ¬РшБЅёцRPC µчУГ¶јОЮ·ЁФЪ5 ґОRDMA ¶БІЩЧчДЪіЙ№¦»сИЎЅб№ыµДЗйїцЎЈТтґЛЈ¬ФЪJakiro ЦРЈ¬Ц»РиЅ«ЗлЗуµДёцКэNЙиЦГОЄ2ѕНДЬ±ЬГвФ¶іМ»сИЎДЈКЅФЪІ»јд¶П»сИЎ·ЅКЅєН·юОсЖч»Шёґ·ЅКЅЦ®јдЅшРРІ»±ШТЄµДЗР»»Ј¬ІўФЪМṩµНСУіЩµДЗ°МбПВ±ЈЦ¤5.5MOPS µДIOPS ·еЦµЎЈїЄ·ўХЯїЙТФёщѕЭПµНіКµјКµДФЛРРЗйїцЙиЦГNµДґуРЎЈ¬ТФѕц¶ЁЅб№ыґ«Кд·ЅКЅµДЗР»»К±јдЎЈ
5ЅбУп
ФЖґжґўПµНіЦРRPCµДЦґРРѕц¶ЁЧЕХыёцПµНіµДРФДЬЈ¬±ѕОДНЁ№эАыУГRDMAјјКхАґУЕ»ЇФЖґжґўЙијЖДЈКЅЈ¬ЧоЦХґпµЅЅПёЯµДНМНВБїЈ¬ХвЦЦ·ЅКЅ¶ФУЪWebУ¦УГµДєЛРДЧйјюKey-Value Storeј°ЖдУЕ»Їј«ЖдУСєГЎЈТтґЛёГЙијЖДЈКЅУРЦъУЪМбёЯФЖґжґўПµНіµДХыМеРФДЬЈ¬ІўУЕ»Ї»щУЪНшТі¶ЛµД·юОсЎЈ
·ЦПнИГёь¶аИЛїґµЅ 
НЖјцФД¶Б
ґ«ГЅНЖјц
 @ГЅМеИЛЈ¬РВОЕ±ЁµА±рИОРФ
@ГЅМеИЛЈ¬РВОЕ±ЁµА±рИОРФ НшХѕФЛУЄХЯ ХвР©"ємПЯ"І»ДЬІИЈЎ
НшХѕФЛУЄХЯ ХвР©"ємПЯ"І»ДЬІИЈЎ Т»НјЧЭААЦР№ъНшВзКУМэРРТµ
Т»НјЧЭААЦР№ъНшВзКУМэРРТµ
Па№ШРВОЕ
- і¬ј¶SIMїЁЈєґуґжґўУл5GНшВзїЙјжµГ
- РВРНґЕґжґўЖчјюУРНыЅвѕцAIЎ°ДЪґжЖїѕ±Ў±
- ТЄПсИЛАаТ»СщґПГч AIПИµГН»ЖЖЛгБ¦ј«ПЮ
- ИэРЗµзЧУФ¤Ів2019ДкАыИуґуµш53%
- Ў°ВЭРэ№вЎ±Ѕ«НјЖ¬РЕПўґжґўДЬБ¦МбёЯ100±¶
- МмєУі¬ЛгґжґўПµНі»сі¬ЛгґжґўПµНі500Зї°сµҐґшїнµЪТ»Гы
- ИэРЗАыИуПВ»¬Ј¬ ґжґўРРТµ°§єи±йТ°
- ИнУІЅбєПЈєїмКЦНЖјцПµНі№ъДЪВКПИ»щУЪіЦѕГДЪґжУ¦УГТм№№ґжґў
- СРѕїИЛФ±їЄ·ўіцµНДЬєДНЁУГРНКэѕЭґжґўЙи±ё
- 5Gі¬ј¶SIMїЁіЙ»»»ъЙсЖч
їН»§¶ЛПВФШ
ИЛГсИХ±ЁЙзёЕїц | №ШУЪИЛГсНш | ±ЁЙзХРЖё | ХРЖёУўІЕ | №гёж·юОс | єПЧчјУГЛ | №©ёе·юОс | КэѕЭ·юОс | НшХѕЙщГч | НшХѕВЙК¦ | РЕПў±Ј»¤ | БЄПµОТГЗ
·юОсУКПдЈєkf@people.cn ОҐ·ЁєНІ»БјРЕПўѕЩ±Ёµз»°Јє010-65363263 ѕЩ±ЁУКПдЈєjubao@people.cn
»ҐБЄНшРВОЕРЕПў·юОсРнїЙЦ¤10120170001 | ФцЦµµзРЕТµОсѕУЄРнїЙЦ¤B1-20060139
№гІҐµзКУЅЪДїЦЖЧчѕУЄРнїЙЦ¤ЈЁ№гГЅЈ©ЧЦµЪ172єЕ | »ҐБЄНшТ©Ж·РЕПў·юОсЧКёсЦ¤КйЈЁѕ©Ј©-·ЗѕУЄРФ-2016-0098
РЕПўНшВзґ«ІҐКУМэЅЪДїРнїЙЦ¤0104065 | НшВзОД»ЇѕУЄРнїЙЦ¤ ѕ©НшОД[2020]5494-1075єЕ | НшВзіц°ж·юОсРнїЙЦ¤ЈЁѕ©Ј©ЧЦ121єЕ | ѕ©ICPЦ¤000006єЕ | ѕ©№«Нш°І±ё11000002000008єЕ
ИЛ Гс Нш °ж ИЁ Лщ УР Ј¬Оґ ѕ Кй Гж КЪ ИЁ Ѕы Ц№ К№ УГ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЖАВЫ

-
№ШЧў
ОўРЕОўІ©їмКЦ
 µЪТ»К±јдОЄДъНЖЛНИЁНюЧКС¶
µЪТ»К±јдОЄДъНЖЛНИЁНюЧКС¶
 ±ЁµАИ«Зт ґ«ІҐЦР№ъ
±ЁµАИ«Зт ґ«ІҐЦР№ъ
 №ШЧўИЛГсНшЈ¬ґ«ІҐХэДЬБї
№ШЧўИЛГсНшЈ¬ґ«ІҐХэДЬБї
