




















ЛљгкдЄВтЕФDCМфСїСПдіСПЕїЖШбаОП
еЊвЊ
ФПЧАвбОгаДѓСПЙигкЬсИпЪ§ОнжааФМфЭјТчадФмЕФбаОП[1][2][3][4][5]ЃЌЕЋетаЉвбгабаОПЖМзЈзЂгкИФЩЦУПИіЪ§ОнжааФЖджЎМфЕФЙугђЭјТЗОЖЕФадФмЁЃгЩгкетаЉЗНЗЈЮДФмРћгУДцдкгкЕиРэЗжВМЕФЪ§ОнжааФЩЯЕФДѓСПгІгУВуИВИЧТЗОЖЃЌвВЮДФмЗЂЯжЗўЮёЦїДцДЂзЊЗЂЪ§ОнЕФФмСІЃЌвђЖјЫќУЧЪЧВЛЭъБИЕФЁЃЖјЭЈЙ§ИВИЧТЗОЖЕФЪЙгУЃЌНсКЯЖдДјПэЕФдЄВтЃЌЪЕЪБЕиЖдЪ§ОнИДжЦДЋЪфНјааЕїЖШЃЌФмЙЛЪЕжЪадЕиЬсИпЪ§ОнжааФМфЪ§ОнИДжЦЕФадФмЁЃ
ЙиМќДЪЃК Ъ§ОнжааФ СїСПЕїЖШ дЄВт
вЛЁЂ в§бд
ШчНёЃЌдНРДдНЖрЕФДѓаЭЦѓвЕдкШЋЙњИїЕиЙЙНЈЦ№СЫздМКЕФЪ§ОнжааФвдМАПчЪ§ОнжааФгђЕФЪ§ОнДЋЪфЦНЬЈЁЃЕЋЪЧЃЌСЌНгУПИіЪ§ОнжааФЖдЕФГЄЭОСДТЗЪЎЗжАКЙѓЃЌвђДЫЬсИпЪ§ОнжааФМфСДТЗЕФРћгУТЪФмЙЛЮЊЦѓвЕДјРДОоДѓЕФаЇвцЃЌгШЦфЪЧЫцзХ5GЕФЕНРДвдМАДЋЪфЪ§ОнСПЕФМБОчХђеЭЃЌЪ§ОнжааФМфСДТЗРћгУТЪЕФЬсЩ§ИќЮЊНєЦШЃЌЦфЫљДјРДЕФаЇвцИќЮЊЯджјЁЃ
ДЋЭГЕФЪ§ОнжааФМфЕФЪ§ОнИДжЦЗНЗЈОпгаШ§ИіОжЯоЃК
ЕквЛЃЌЕЭаЇЕФОжВПЪЪгІЁЃЯжгаЕФЗЧМЏжаЪНЕФавщШБЩйШЋОжЪгЭМЃЌетНЋЕМжТДЮгХЕФЕїЖШКЭТЗгЩОіВпЁЃУПИіЗўЮёЦїНіПДЕНПЩгУЕФЪ§ОндДЃЈвбЯТдиВПЗжЮФМўЕФЗўЮёЦїЃЉЕФзгМЏЃЌвђДЫВЛФмРћгУЫљгаПЩгУЕФИВИЧТЗОЖРДзюДѓЛЏЭЬЭТСПЁЃМДЪЙИВИЧЭјТчжЛЪЧВПЗжЗжЩЂЃЌЕУЕНДЮгХадФмЕФЯжЯѓвВЛсЗЂЩњ[9]ЁЃМДЪЙУПИіЗўЮёЦїЖМгаШЋОжЪгЭМЃЌЕЅИіЗўЮёЦїЕФБОЕиЪЪгІШдШЛЛсдкИВИЧТЗОЖЩЯВњЩњЧБдкЕФШШЕуКЭгЕШћЁЃ
ЕкЖўЃЌИпМЦЫуПЊЯњЁЃЮЊСЫЕУЕНШЋОжЪгЭМВЂЧвЪЕЯжзюгХЕФЕїЖШавщЃЌЯжгаЕФМЏжаЛЏЕФавщЖМвЊГаЪмИпЕФМЦЫуПЊЯњЁЃДѓЖрЪ§ФЃаЭЖМЪЧГЌЯпадЕФЃЌЫљвдМЏжаЛЏавщЕФМЦЫуПЊЯњЭЈГЃЖМЪЧжИЪ§діГЄЕФЃЌетЪЙЕУетаЉавщЪЕМЪЩЯВЛПЩааЁЃ
ЕкШ§ЃЌЙЬЖЈЕФДјПэЗжРыЁЃЙЬЖЈЕиЗжРыСДТЗДјПэНЋЛсЕМжТЙ§ЖШЪЙгУДјПэЛђепВЛФмГфЗжЪЙгУДјПэЕФЯжЯѓЁЃРэТлЩЯЃЌШчЙћЮвУЧФмЙЛЪЕЪБЕиГфЗжРћгУдкЯпСїСПЫљЪЃЕФПЩгУДјПэЃЌдђСДТЗРћгУТЪЛсИќЮШЖЈЁЃ
ЫљвдБОЮФЬсГіСЫЛљгкдЄВтЕФЪЕЪБдіСПЕїЖШЕФЗНЗЈЁЃ
ЖўЁЂ баОПБГОАМАЯжзД
дкЪ§ОнжааФМфНјааЪ§ОнИДжЦЕФашЧѓМБОчдіГЄЃЌЮЊСЫТњзуетвЛашЧѓЃЌАйЖШМИФъЧАВПЪ№СЫвЛИігІгУВуЕФИВИЧЭјТчЁЊЁЊGingkoЁЃОЁЙмКѓРДGingkoНјааСЫИФСМЃЌЕЋЫќвРШЛЛљгкНгЪеепЧ§ЖЏЕФЗЧМЏжаЛЏЕФИВИЧЖрВЅавщЃЌетРрЫЦгкдкЦфЫћИВИЧЭјТчЃЈШчCDNsКЭЛљгкИВИЧЕФЪЕЪБЪгЦЕСї[6][7][8]ЃЉжаЪЙгУЕФавщЁЃЫќЕФЛљБОЫМТЗЪЧЃЌЕБЖрИіЪ§ОнжааФЯЃЭћДгвЛИідДЪ§ОнжааФжаЧыЧѓвЛИіЪ§ОнЮФМўЪБЃЌБЛЧыЧѓЕФЪ§ОнНЋЛсОЙ§ЖрНзЖЮЕФжаМфЗўЮёЦїДЋЛиЧыЧѓЗНЃЌЦфжаЃЌУПИіНзЖЮЕФЗЂЫЭЗНбЁдёЪЧгЩЯТвЛНзЖЮЕФНгЪеепвдЗжЩЂЕФЗНЪНЧ§ЖЏЕФЁЃ
ЮЊСЫЬсИпЪ§ОнжааФМфWANЕФСДТЗРћгУТЪЃЌGoogleЯШКѓЬсГіСЫB4 WAN[17]вдМАЫќЕФЩ§МЖАцБОB4 and After[18]ЃЌДЫЭтЛЙгажЇГжTEзщМўЕФBwEзщМўЁЃ
B4ЪЧСЌНгGoogleШЋЧђЪ§ОнжааФЕФзЈгУWANЃЌдкЫќЬсГіЪБЃЌGoogleдкШЋЧђЕФЪ§ОнжааФеОЕуга12ИіЃЌЖјЕНB4 and AfterЬсГіЪБЃЌGoogleЕФШЋЧђЪ§ОнжааФеОЕувбОДяЕНСЫ33ИіЁЃЖјЧвGoogleвВБэУїЃЌдкB4ЬсГіжЎКѓЕФ5ФъжЎФкЃЌДјПэашЧѓвбОдіГЄСЫ100БЖЃЌЖјЧвЛсвдУП9ИідТЗБЖЕФЫйЖШдіГЄЁЃB4 ећЬхВЩгУSDNЕФНсЙЙРДЪЕЯжЃЌSDNФмЙЛЬсЙЉвЛИідЫаадкЩЬгУЗўЮёЦїЩЯЕФЁЂзЈгУЕФЁЂЛљгкШэМўЕФПижЦЦНЬЈЃЌШУЪЙгУепФмЖдШЋОжзДЬЌНјааЗжЮіЃЌМђЕЅЕиЖдМЦЛЎФкКЭМЦЛЎЭтЕФЭјТчБфЛЏНјаааЕїЁЃOpenFlowФмЙЛДюНЈSDNЕФЩњЬЌЯЕЭГЃЌGoogleЭЈЙ§ЫќПЩвдПЊЗЂЖржжswitch/dataЦНУцдЊЫиЁЃSDNКЭOpenFlowНЋШэгВМўЕФЗЂеЙНјааСЫНтёюЃЌЪЙЕУПижЦЦНУцЕФШэМўИќМђЕЅЃЌЗЂеЙИќПьЃЌЭЌЪБДйЪЙЪ§ОнЦНУцЕФгВМўФмЙЛЛљгкПЩБрГЬадРДЗЂеЙЁЃДЫЭтЃЌЪЙгУSDNЕФНсЙЙЛЙгаЦфЫћгХЪЦЃКаТавщЕФПьЫйЕќДњЃЛМђЛЏЕФВтЪдЛЗОГЃЛЭЈЙ§ФЃФтШЗЖЈаджабыTEЗўЮёЦїЖјВЛЪЧГЂЪдЗжВМЪНавщЕФвьВНТЗгЩЃЌПЩвдИФНјTEЙцЛЎЃЛЭЈЙ§вдНсЙЙЮЊжааФЖјВЛЪЧвдТЗгЩЦїЮЊжааФЕФWANЪгЭМЃЌПЩвдМђЛЏЭјТчЙмРэЁЃгЩгкB4ВЩгУСЫSDNЕФНсЙЙЃЌЖјЧвЕБЪБУЛгаЯжгаЦНЬЈПЩвджЇГжSDNВПЪ№ЃЌвђДЫGoogleЛЙЖЈжЦСЫздМКЕФНЛЛЛЛњгВМўЁЃB4жївЊЭЈЙ§вЛИіМЏжаЪНЕФСїСПЙЄГЬЃЈTEЃЉЫуЗЈРДЮЊгІгУЗжХфДјПэЃЌЪЕЯжзюДѓзюаЁЙЋЦНЃЈmax-min fairnessЃЉЃЌетвЛЗНЪНФмЙЛЪЙСДТЗРћгУТЪДяЕННгНќ100%ЁЃ
еыЖддіГЄСЫ100БЖЕФДјПэашЧѓЃЌДг99%ЕН99.99%ЕФПЩППадвЊЧѓЃЌвдМАШнСПВЛЖдГЦЕФЯжЯѓЃЌGoogleЬсГіСЫB4 and AfterЁЃB4ЕФРЉеЙЗНАИЪЧдкдгаеОЕуИННќаТдіеОЕуЃЌетбљНЋЛсгАЯьTEгХЛЏЫуЗЈЕФадФмЃЌЖјЧвгаЯоЕФНЛЛЛЛњзЊЗЂБэПеМфНЋГЩЮЊЦПОБЁЃвђДЫB4 and AfterНЋУПвЛИіеОЕуЩшМЦЮЊСНВуЕФЭиЦЫГщЯѓЃЌЕзВув§ШывЛИіГЦЮЊsupernodeЕФНсЙЙЃЌетЪЧгЩЩЬгУЙшНЛЛЛаОЦЌЙЙГЩЕФБъзМСНВуClosЭјТчЃЌЖЅВуНЋЖрИіsupernodeНкЕуСЌГЩвЛИіШЋЭјзДЕФЭиЦЫЁЃетбљвЛРДЃЌЭЈЙ§ЬэМгsupernodeНкЕуБуПЩвдЪЕЯжКсЯђЕФРЉеЙЃЌЭЈЙ§НіИќаТашвЊЕФsupernodeБуПЩвдЪЕЯжзнЯђЕФРЉеЙЃЌЛЎЗжЮЊsupernodeЕФСЃЖШгжФмЙЛЬсИпПЩгУадЁЃЗжВуЭиЦЫНсЙЙжаЕФШнСПВЛЖдГЦЯжЯѓЛсНЕЕЭСДТЗПЩРћгУЕФПеМфЃЌзшАСДТЗРћгУТЪЕФЬсЩ§ЃЌЮЊСЫНтОіетвЛЮЪЬтЃЌGoogleв§ШыСЫsidelinksЕФИХФюЁЃSidelinksСЌНгУПИіеОЕужаЕФsupernodesЃЌЙЙГЩШЋЭјзДЕФНсЙЙЃЌЭЈЙ§ЪЙгУsidelinksЃЌжабыПижЦЦїЖЏЬЌЕиЦНКтвЛИіеОЕужаЕФгЩWANСДТЗЙЪеЯв§Ц№ЕФШнСПВЛЖдГЦЁЃШЛЖјЃЌжЎЧАЕФеОЕуМЖБ№ЕФTEВЂВЛФмзіЕНетаЉЃЌетОЭашвЊвЛИіsupernodeМЖБ№ЕФTEРДМЦЫуsidelinksЕФШнСПЁЃЕЋЪЧЃЌНіЪЙгУsupernodeМЖБ№ЕФTEЃЌашвЊНјааIP-in-IPЕФЗтзАЃЌЖјЧвВЛФмКмКУЕиЪеСВМЦЫуЪБМфЃЌЭЌЪБЛЙашвЊИќДѓЕФНЛЛЛЛњзЊЗЂБэРДжЇГжЁЃгкЪЧЃЌGoogleВЩгУСЫЗжВуTEЕФзіЗЈЃЌНсКЯЪЙгУеОЕуМЖБ№ЕФTEКЭsupernodeМЖБ№ЕФTEЁЃетбљЕФзіЗЈжЛашвЊвЛДЮЗтАќЗтзАОЭФмЙЛЪЕЯжеОЕуЕНеОЕуЕФДЋЪфЃЌЖјЧвзюЖЬТЗОЖЕФМЦЫуГЩБОНЯЕЭЃЌФмЙЛЪЕЯжПЩРЉеЙЁЃ
Ш§ЁЂ ЖЏЬЌЗжРыЕФДЋЪфЛњжЦ
3.1 DCМфСїСПЬиеїЗжЮі
ЖдгкДѓаЭдкЯпЗўЮёЬсЙЉЩЬЃЌвЛИіКмживЊЕФЪ§ОнЭЈаХФЃЪНЪЧDCЃЈData CenterЃЉМфЕФДѓСПЪ§ОнИДжЦЃЌдкDCМфНјааЪ§ОнИДжЦЫљгУЕФСїСПеМDCМфЫљгаСїСПЕФжївЊВПЗжЁЃЫцзХЬсЙЉЩЬНЋдНРДдНЖрЕФЪ§ОнжааФВПЪ№ЕНШЋЧђИїЕиЃЌвдМАКЃСПЪ§ОнЕФМБОчХђеЭЃЌDCМфЕФЪ§ОнИДжЦашвЊвдвЛжжИќМгЦЕЗБЖјЧвИпаЇЕФЗНЪНРДНјааЁЃ
дкЪ§ОнжааФМфНјааЪ§ОнИДжЦЫљЪЙгУЕФСїСПЃЌеМОнЪ§ОнжааФМфзмСїСПЕФвЛДѓВПЗжЃЌЭЌЪБвВеМОнСЫУПжжгІгУРраЭзмСїСПЕФвЛДѓВПЗжЁЃЛљгкетбљЕФЪТЪЕЃЌгХЛЏЪ§ОнжааФМфЪ§ОнИДжЦЕФадФмОЭЯдЕУЪЎЗжживЊЁЃ
ЖдгкЪ§ОнжааФМфЕФЪ§ОнИДжЦЃЌЫќУЧДЋЪфЕФФПЕФЕиЪЧДѓВПЗжЕФЪ§ОнжааФЃЌЖјВЛЪЧЩйЪ§ЕФМИИіЪ§ОнжааФЃЌЖјЧвдкДЋЪфКЭДЋЪфжЎМфЃЌдДЪ§ОнжааФКЭФПЕФЪ§ОнжааФЖМгаКмДѓЕФВювьЁЃетвЛЯжЯѓБэУїЃЌЯывЊЪТЯШХфжУКУЫљгаПЩФмЕФЪ§ОнИДжЦЧыЧѓЪЧВЛЧаЪЕМЪЕФЁЃвђДЫашвЊетбљвЛИіЯЕЭГЃЌЫќФмздЖЏЕиТЗгЩКЭЕїЖШЫљИјЕФШЮвтЪ§ОнИДжЦДЋЪфЧыЧѓЁЃ
Ъ§ОнжааФМфЪ§ОнИДжЦЕФЙцФЃЭЈГЃКмДѓЃЌ60%ЕФЪ§ОнИДжЦЕФЙцФЃГЌЙ§1TBЃЌЖј90%ЕФЪ§ОнИДжЦЕФЙцФЃГЌЙ§50GBЁЃМйЖЈЗжХфИјУПИіDCМфЪ§ОнИДжЦДЋЪфЕФзмЙугђЭјДјПэЪЧМИGBУПУыЃЌетаЉДЋЪфВЛЪЧСйЪБЕФЖјЪЧГжајЕФЃЌЭЈГЃзюЩйГжајЪ§ЪЎУыЃЌдђШЮКЮгХЛЏЪ§ОнИДжЦДЋЪфЕФЗНАИЖМБиаыЖЏЬЌЕиЪЪгІЪ§ОнДЋЪфЙ§ГЬжаЕФШЮКЮадФмБфЛЏЁЃСэвЛЗНУцЃЌетжжЪБМфГжОУадвВвтЮЖзХЪ§ОнжааФМфЕФЪ§ОнИДжЦДЋЪфПЩвдШнШЬгЩМЏжаПижЦЛњжЦв§Ц№ЕФЩйСПбгГйЁЃ
3.2 ЪЕЪБдіСПЕїЖШ
ЛљгкетбљЕФЖЏЛњЃЌБОЮФЬсГіСЫвЛИіМЏжаЛЏЕФНќЫЦзюгХЕФгІгУВуЭјТчЯЕЭГЃЌЫќАбЪ§ОнЗжГЩЯИСЃЖШЕФЕЅдЊЃЌЭЈЙ§ЦПОБВЛЯрНЛЕФИВИЧСДТЗ[10]ВЂааЕиЗЂЫЭЫќУЧЃЌЖЏЬЌЕиЙВЯэДјПэЁЃБОЯЕЭГЕФКЫаФЪЧвЛИіМЏжаЛЏЕФОіВпжЦЖЈЫуЗЈЃЌЫќМИКѕЪЕЪБЕижмЦкадЕиХњСПИќаТИВИЧТЗгЩОіВпЁЃЭЈЙ§НЋТЗгЩКЭОіВпНјааНтёюЃЌБОЯЕЭГФмЙЛевЕНзюМбЕФНтОіЗНАИЃЌЭЌЪБзіГіНќЫЦЪЕЪБЕФИќаТЃЌЕУЕНТњвтЕФНсЙћЁЃ
ЮЊСЫЪЕЯжПЩРЉеЙадЃЌЬсИпЖдЭјТчЖЏЬЌЕФЯьгІЃЌЙугђИВИЧЭјЕФДЋЭГЫМТЗдкФГжжГЬЖШЩЯвРРЕгкЕЅИіНкЕуЃЈЛђжаМЬЗўЮёЦїЃЉЕФОжВПЪЪгІ[6][9][11][12]ЃЌОЁЙмвђДЫЛсгЩгкШБЗІШЋОжЪгЭМКЭаЕїЖјДяЕНДЮгХЕФадФмЁЃгыДЫЯрЗДЃЌБОЯЕЭГШЯЮЊЃЌНЋЙугђИВИЧЭјЕФПижЦЭъШЋМЏжаЃЌЭЌЪБдкХфжУЪ§ОнжааФМфЕФзщВЅЪБЪЕЯжНќЫЦзюгХЕФадФмЪЧПЩааЕФЁЃИХРЈЕиЫЕЃЌБОЯЕЭГгавЛИіМЏжаПижЦЦїЃЌЫќжмЦкадЕиДгЫљгаЗўЮёЦїРШЁЪ§ОнДЋЪфзДЬЌЕФаХЯЂЃЌИќаТгаЙиИВИЧТЗгЩЕФОіВпЃЌАбЫќУЧЭЦЫЭЕНдкЗўЮёЦїБОЕиЩЯдЫааЕФДњРэЁЃВЂЧвЕБПижЦЦїГіЯжЙЪеЯЛђЮоЗЈЗУЮЪЪБЃЌЯЕЭГЛсЭЫЛиЕНДЋЭГЕФЗЧМЏжаЕФПижЦФЃЪНЁЃ
МЏжаЛЏЕФЯЕЭГФмЙЛВњЩњНгНќзюгХЕФОіВпЃЌЕЋЭЌЪБвВЛсЕМжТКмаЁЕФИќаТбгГйЃЌвђДЫвЊПМТЧдкСНепжЎМфНјааШЈКтЁЃДяЕНЦНКтЕФЙиМќЪЧНќЫЦзюгХЕФИпаЇЕФИВИЧТЗгЩЫуЗЈЃЌЫќПЩвдзіЕНМИКѕЪЕЪБЕиИќаТОіВпЁЃШЛЖјЃЌгЩгкОіВпПеМфЪЎЗжХгДѓЃЌЪЙгУБъзМТЗгЩКЭЯпадЙцЛЎЕФЗНЗЈКмФбЕУЕННќЫЦзюгХЕФОіВпЃЌетЪЧЪЕЯжМЏжаПижЦЕФЙиМќЮЪЬтЁЃ
БОЯЕЭГвдМЏжаЕФЗНЪНжмЦкадЕиЃЈФЌШЯЮЊ3УыЃЉИќаТТЗгЩКЭЕїЖШОіВпЃЌУПИіжмЦкЕФЙЄзїСїГЬШчЯТЃК
1) гЩдЫаадкУПИіЗўЮёЦїБОЕиЕФДњРэШЗШЯБОЕиЕФзДЬЌЃЌАќРЈЪ§ОнПщЕФДЋЪфзДЬЌЃЈФФаЉПщЕНРДЃЌФФаЉПщЮДЭъГЩЃЉЃЌЗўЮёЦїЕФПЩгУадЃЌДХХЬЙЪеЯЃЌЕШЕШЁЃ
2) ШЛКѓетаЉЪ§ОнБЛАќзАГЩвЛИіПижЦЯћЯЂЃЌЭЈЙ§ДњРэМрЪгЦїЕФИпаЇЕФЯћЯЂДЋЕнВуЗЂЫЭИјМЏжаЛЏЕФПижЦЦїЁЃ
3) ПижЦЦївВДгЭјТчМрЪгЦїНгЪеЭјТчВуЕФЪ§ОнЃЈбгГйУєИааЭСїСПЕФДјПэЯћКФЃЌвдМАУПЬѕЪ§ОнжааФМфСДТЗЩЯЕФРћгУТЪЃЉЁЃ
4) вЛЕЉНгЪеЕНРДздЫљгаДњРэКЭЭјТчМрЪгЦїЕФИќаТаХЯЂЃЌПижЦЦїОЭдЫааМЏжаЛЏЕФОіВпжЦЖЈЫуЗЈЃЌвдЕУЕНаТЕФЕїЖШКЭТЗгЩОіВпЃЌВЂЧвЭЈЙ§ДњРэМрЪгЦїЕФЯћЯЂДЋЕнВуНЋаТОЩОіВпМфЕФВювьЗЂЫЭИјУПИіЗўЮёЦїБОЕиЕФДњРэЁЃ
5) зюКѓЃЌДњРэЮЊУПИіЪ§ОнДЋЪфЗжХфДјПэЃЌИљОнПижЦЦїЕФТЗгЩКЭЕїЖШОіВпРДНјааЪЕМЪЕФЪ§ОнДЋЪфЁЃ
БОЯЕЭГзіСЫСНИіЖюЭтЕФгХЛЏРДЪЙЯЕЭГЕФдЫааИќИпаЇЃК
1) ПщЕФКЯВЂЁЃЮЊСЫМѕаЁМЦЫуЙцФЃЃЌЪЕЯжИќИпаЇЕФДЋЪфЃЌБОЯЕЭГНЋОпгаЯрЭЌдДКЭФПЕФЕФПщКЯВЂЮЊвЛИізгШЮЮёЁЃетбљгаСНИіЗНУцЕФКУДІЃКЪзЯШЃЌЫќЯджјЕиМѕЩйСЫУПИіЕїЖШжмЦкжаЙвЦ№ЕФПщЃЌвђДЫМѕЩйСЫМЏжаЛЏЕФОіВпжЦЖЈТпМЕФМЦЫуПЊЯњЁЃЦфДЮЃЌЫќМѕЩйСЫЗўЮёЦїМфЕФВЂааTCPСЌНгЃЌетаЉВЂааЕФTCPСЌНгЛсНЕЕЭСДТЗЕФРћгУТЪКЭадФмЁЃ
2) ЮозшШћИќаТЁЃЕБПижЦЦїдЫааМЏжаЛЏЕФОіВпжЦЖЈЫуЗЈЪБЃЌЮЊСЫЗРжЙБЛОіВпжЦЖЈЫуЗЈзшШћЃЌУПИіБОЕиДњРэЖМЪЙе§дкНјааЕФЪ§ОнДЋЪфБЃГжЛюЖЏзДЬЌЁЃРрЫЦЕиЃЌПижЦЦївВПМТЧСЫетвЛЕуЃЌЫќдкОіВпБЛжиаТМЦЫуЕФЪБКђдЄВтЪ§ОнДЋЪфзДЬЌЕФБфЛЏЃЌВЂЧвгУетаЉдЄВтЕФЪ§ОнДЋЪфзДЬЌзїЮЊетИіМЏжаТпМЕФЪфШыЁЃ
3.3 дкЯпСїСПдЄВт
дкДЋЭГЕФЙЬЖЈДјПэЗжРыЕФФЃЪНжаЃЌгЩгкЗжХфИјдкЯпСїСПКЭРыЯпСїСПЕФДјПэЪЧЙЬЖЈЕФЃЌЫљвдМДЪЙдкЯпСїСПКмЩйЪБЃЌРыЯпСїСПвВВЛФмРћгУЗжХфИјдкЯпСїСПЕЋФПЧАПеЯаЕФДјПэЃЌетНЋЕМжТКмЕЭЕФСДТЗРћгУТЪЁЃЫљвдБОЯЕЭГВЩгУСЫЖЏЬЌДјПэЗжРыФЃЪНЃЌЫќФмЪЕЪБЕиЮЊДѓСПЪ§ОнДЋЪфЕїећПЩгУДјПэЃЌЭЈЙ§ВЛЖЯЕидЄВтдкЯпСїСПКЭздЖЏЕиЕїећЕїЖШОіВпЃЌРДГфЗжРћгУЭјТчДјПэЁЃОпЬхРДЫЕЃЌБОЯЕЭГИљОнВЛЭЌЕФЭјТчЧщПіРДздЖЏЕїећЕїЖШНсЙћЃКЕБдкЯпСїСПЕНДяЦфЗхжЕЪБЃЌБОЯЕЭГЫѕМѕРыЯпСїСПгЕгаЕФДјПэвдБмУтгЕЖТЃЌЕБдкЯпСїСПЕНДяЦфЙШжЕЪБЃЌБОЯЕЭГШУРыЯпСїСПЪЙгУИќЖрЕФДјПэвдГфЗжЪЙгУЪЃгрДјПэЁЃЮЊСЫЪЕЯжетвЛЙІФмЃЌБОЯЕЭГЪЙгУСЫдкЯпСїСПдЄВтЫуЗЈЃЌЫќФмЪЖБ№ЗўЮёЦїДјПэЪЙгУЕФБфЛЏЃЌДЅЗЂжиЕїЖШРДЕїећЗжХфИјДѓСПЪ§ОнДЋЪфЕФДјПэЁЃЭМ 1ЮЊБОЯЕЭГЖЏЬЌДјПэЗжРыЕФТпМЭМЁЃЭјТчМрЪгЦїЖСШЁгЩДњРэЙлВьЕНЕФtrafficжЕЃЌШЛКѓжДаавЛИігЩEWMAЃЈExponentially Weighted Moving-AverageЃЉ[13]КЭЙеЕуМьВтЫуЗЈ[14]зщГЩЕФSliding-kФЃПщЃЌEWMAИКд№МЦЫуЕБЧАжмЦкЕФСїСПдЄВтжЕЃЌЙеЕуМьВтИКд№ЙлВьРњЪЗЪ§ОнШЛКѓХаЖЯЕБЧАЪЧЗёгаЭЛБфГіЯжЃЌЪЙДњРэМрЪгЦїЦНЮШЖјЧвУєИаЁЃ
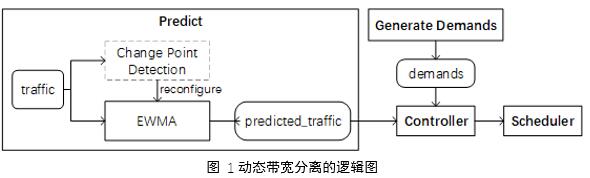
ФПЧАгавЛаЉЛљБОЗНЗЈПЩвдМьВтдкЯпСїСПБфЛЏВЂЖЏЬЌЕїећЕїЖШЕФХфжУЃЌШчEWMAЁЂk-SigmaЕШ[15][16]ЁЃЕЋетаЉЗНЗЈгаЪБКђЛсСЌајЕижиХфжУЃЌЩѕжСдкЭјТчКмЮШЖЈЕФЪБКђвВЛсШчДЫЁЃвђДЫЃЌдкдЄВтПЩгУДјПэЕФЪБКђУцСйзХвЛИіШЈКтЃКЕБЮвУЧдкВЮПМЪБИќПДжизюНќЕФЪ§ОнЃЌдЄВтжЕНЋЛсГіЯжУїЯдЕФе№ЕДЃЌетНЋв§Ц№ВЛБивЊЕФСЌајжиЕїЖШЃЛЖјЕБЮвУЧдкВЮПМЪБИќПДжиРњЪЗЪ§ОнЃЌдЄВтжЕЪмНќЦкМьВтЕНЕФЙеЕуЕФгАЯьОЭНЯаЁЃЌетЪЙЕУЯЕЭГЖдгкЭјТчБфЛЏВЛФЧУДУєИаЁЃ
ЮЊНтОівдЩЯЮЪЬтЃЌБОЯЕЭГНЋEWMA[13]КЭЙеЕуМьВтЫуЗЈ[14]НсКЯЃЌВЂЧвЩшМЦСЫЖЈжЦЕФЛЌЖЏkЫуЗЈЁЃОпЬхРДЫЕЃЌЮвУЧЮЊEWMAЫуЗЈЩшжУСЫвЛИіЩЯНчKЃЌШєЕБЧАУЛгаЙеЕуЃЌkНЋБЛЩшжУЮЊKЃЌЖјЕБвЛИіЙеЕуБЛМьВтЕНЪБЃЌkНЋБЛЩшЮЊ0ЃЌШЛКѓж№НЅЕидіГЄЕНKЁЃЮвУЧАбЙеЕуМьВтЗХЕНЭјТчБфЛЏМрЪгЦїжаЃЌЪЕЯжСЫЖЈжЦЫуЗЈЁЃ
дквЛИіЕїЖШжмЦкФкЃЌЭјТчБфЛЏМрЪгЦїВЛЖЯЕиЛёШЁЗўЮёЦїЭЬЭТСПЕФвЛЯЕСаДњРэЙлВьжЕЃЌетаЉжЕдкЯТвЛИіЕїЖШжмЦкФкБЛгУРДдЄВтПЩгУДјПэЁЃ
3.3.1 EWMA
EWMAМДжИЪ§МгШЈвЦЖЏЦНОљЗЈЃЌетвЛЗНЗЈПЩвдИљОнРњЪЗЙлВтжЕРДЙРМЦЕБЧАЕФжЕЃЌдЄВтЪБИјЙлВтжЕЕФШЈжЕЫцЪБМфГЪжИЪ§ЕнМѕЃЌРыЕБЧАЪБМфдННќЕФЪ§ОнШЈжидНДѓЁЃ
EWMAЕФБэДяЪНШчЯТЃК

ДгЩЯЪНПЩвдПДГіЃЌЙлВтжЕЕФШЈжЕЫцзХЪБМфГЪжИЪ§ЪНЯТНЕЁЃИјНќЦкЙлВтжЕНЯДѓЕФШЈжиЪЧвђЮЊЫќЖддЄВтжЕгаНЯДѓЕФгАЯьЃЌИќФмЗДгІНќЦкБфЛЏЕФЧїЪЦЁЃ
3.3.2 БДвЖЫЙдкЯпЙеЕуМьВтЫуЗЈ
ЮЊСЫЭЌЪББЃжЄЮШЖЈадвдМАЖдЭјТчБфЛЏЕФУєИаГЬЖШЃЌдЄВтФЃПщв§ШыБДвЖЫЙЙеЕуМьВтЫуЗЈЁЃ
ИУЫуЗЈЪЙгУЯћЯЂДЋЕнЫуЗЈМЦЫуЕБЧАЁАдЫааЁБГЄЖШЛђздЩЯвЛИіБфЛЏЕувдРДЕФЪБМфЕФИХТЪЗжВМЁЃ
ИУЫуЗЈдкЕЅБфСПЪБМфађСаЩЯвддкЯпЗНЪНжДааБДвЖЫЙЙеЕуМьВтЁЃКЫаФЫМЯыЪЧдкУПИіаТЪ§ОнЕуЕНДяЪБЕнЙщМЦЫуЁАдЫааГЄЖШЁБЕФКѓбщИХТЪЁЃдЫааГЄЖШЖЈвхЮЊздЩЯДЮИќИФЕуЗЂЩњвдРДЕФЪБМфЁЃ
3.3.2 Sliding-k
дкЖдађСаНјаадЄВтЪБЃЌШєEWMAЕФВЮЪ§ІСЩшжУЕУКмаЁЃЌвтЮЖзХИјОУдЖвЛаЉЕФРњЪЗЙлВтжЕЕФШЈжиИќДѓЃЌдЄВтНсЙћЛсИќМгЦНЮШЃЌЕЋЖдгкЭЛЗЂЕФЖЖЖЏВЛЙЛСщУєЃЌШєІСКмДѓЃЌвтЮЖзХИјНќЦкЙлВтжЕЕФШЈжидНДѓЃЌдЄВтНсЙћОЭЛсдНСщУєЃЌЕЋЪЧдЄВтжЕЛсГіЯжВЈЖЏЃЌв§Ц№СЌајЕФжиХфжУЃЈШчЙћдЄВтНсЙћИњЩЯвЛжмЦкЕФдЄВтжЕЯрВюВЛДѓЃЌдђЮоашжиаТХфжУзДЬЌаХЯЂЃЌМѕаЁИќаТбЙСІЃЉЁЃЫљвдБОЯЕЭГВЩгУСЫSliding-kЕФЗНЪНЃЌМДЕБЧАЮоЙеЕуЪБОЭИјОУдЖвЛаЉЕФЙлВтжЕИќДѓЕФШЈжиЃЌвдБЃжЄдЄВтНсЙћЕФЦНЛЌЃЌЖјвЛЕЉМьВтГіЙеЕуЃЌОЭИјНќЦкЙлВтжЕИќДѓЕФШЈжиЃЌБЃжЄдЄВтНсЙћЕФСщУєЁЂзМШЗЁЃ
ЦфжївЊВНжшШчЯТЃК
1ЃЉ БДвЖЫЙЙеЕуМьВтЫуЗЈМЦЫуЕБЧАжмЦкЮЊЙеЕуЕФИХТЪЁЃ
2ЃЉ ЭЈЙ§НЋЩЯвЛВНЕУГіЕФИХТЪжЕгыЮвУЧЩшЖЈКУЕФуажЕЖдБШЃЌХаЖЯЕБЧАжмЦкЪЧЗёЮЊЙеЕуЁЃ
3ЃЉ ШчЙћЕБЧАжмЦкЮЊЙеЕуЃЌдђEWMAЕФЪфШыађСаЕФДАПкДѓаЁЮЊ1ЃЌвВОЭЪЧEWMAЪфШыађСаНіАќКЌЩЯвЛжмЦкЕФЙлВтжЕЃЌЧвВЮЪ§ІСЩшжУЮЊ1ЃЌМДдЄВтЪБНіВЮПМЩЯвЛжмЦкЕФЙлВтжЕЃЌжЎКѓУПОЙ§вЛИіжмЦкІСжЕМѕаЁ0.1ЃЌжБЕНІСжЕНЕЕЭЕНЮвУЧжИЖЈЕФЮШЖЈжЕЃЈШч0.6ЃЉЁЃ
4ЃЉ ШчЙћЕБЧАжмЦкЗЧЙеЕуЃЌдђEWMAЕФЪфШыађСаЮЊЩЯвЛИіЙеЕуГіЯжЪБЕНЩЯвЛжмЦкетЖЮЪБМфФкЕФвЛЯЕСаЙлВтжЕЁЃ
5ЃЉ EWMAИљОнЪфШыЕФађСажЕКЭІСжЕдЄВтЕБЧАжмЦкЕФжЕЃЌЪфГіЕНЕїЖШФЃПщЁЃ
Sliding-kИљОнЙеЕуМьВтЕФНсЙћЖЏЬЌЕиЕїећдЄВтЗНЪНЃЌЪЙЕУдкЮоЙеЕуЪБФмЙЛБЃжЄдЄВтНсЙћЕФЦНЛЌЃЌЖјгаЭЛЗЂЙеЕуЪБгжФмСщУєЕиЯьгІЃЌзіГізМШЗЕФдЄВтЁЃ
ЫФЁЂ ЪЕбщЦРЙР
ЮвУЧдкЪЕбщжаЖдБШСЫЙЬЖЈДјПэЗжРыгыЮвУЧЖЏЬЌДјПэЗжРыЕФЗНАИЁЃжївЊЪЧдкЯЕЭГжаЙЬЖЈИеадСїСПКЭЕЏадСїСПЕФБШжЕРДФЃФтОВЬЌДјПэЗжРыЕФаЇЙћЃЌЖјЮвУЧЕФЯЕЭГдђПЩвдЖЏЬЌЕидЄВтЕБЧАжмЦкЕФИеадСїСПашЧѓЕФДѓаЁЃЌШЛКѓНЋЪЃЯТЕФПеЯаДјПэЖМЗжХфИјЕЏадСїСПЁЃ
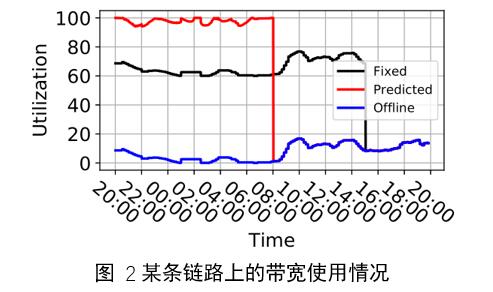
ШчЭМ 2ЫљЪОЃЌЪЕбщНсЙћжаЃЌРЖЯпДњБэСЫИеадСїСПеМзмДјПэЕФАйЗжБШЃЌКкЯпДњБэЙЬЖЈДјПэЗжРыЗНАИЯТзмЕФДјПэРћгУТЪЃЈИеадСїСПКЭЕЏадСїСПеМзмДјПэЕФАйЗжБШЃЉЃЌКьЯпДњБэБОЯЕЭГЗНАИЯТЕФзмЕФДјПэРћгУТЪЁЃДгЭМжаПЩвдПДЕНЃЌЮЊИеадСїСПгыЕЏадСїСПЩшжУЙЬЖЈЕФБШжЕ2:3ЪБЃЌЕЏадСїСПзюЖржЛФмЪЙгУЭъЪєгкздМКЕФзмДјПэЕФ60%ЃЌОЁЙмИеадСїСПдЖЮДЪЙгУЭъЗжХфИјЫќЕФзмДјПэЕФ40%ЃЌЕЏадСїСПвВВЛФмШЅНшгУетВПЗжПеЯаСїСПЃЌетОЭдьГЩСЫДјПэЕФРЫЗбЁЃЦфжаЃЌЭМжаКкЯпгыРЖЯпаЮзДЯрЫЦЪЧвђЮЊЕЏадСїСПдкУПжмЦкФкЖМЪЙгУСЫ60%ЕФДјПэЃЈЦфЩЯЯоЃЉЃЌвВОЭЪЧЫЕКкЯпЪЧРЖЯпЭљЩЯЦНвЦСЫ60%ЃЌетгыЮвУЧЕФЩшЯыЪЧвЛжТЕФЁЃ
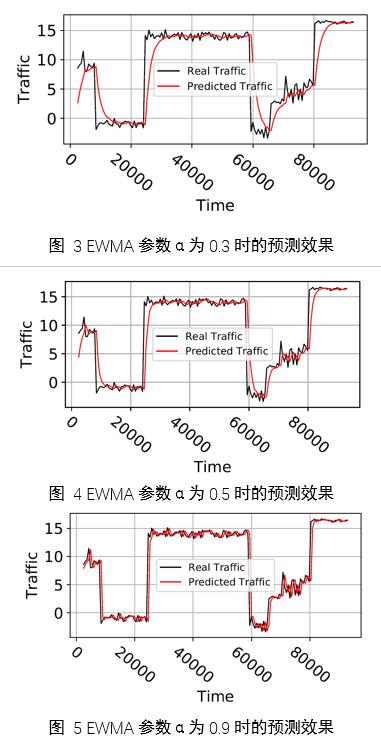
ЮЊСЫбщжЄSliding-kЗНЗЈЕФдЄВтаЇЙћЃЌЮвУЧЫцЛњЩњГЩСЫЗжЖЮЕФДјЁАУЋДЬЁБЕФађСаЃЌЪзЯШЪЙгУEWMAЖдИеадСїСПНјаадЄВтЃЌЕБІСЩшжУЮЊ0.3ЁЂ0.5ЁЂ0.9ЪБдЄВтаЇЙћЗжБ№ШчЭМ 3ЭМ 4ЭМ 5ЫљЪОЃЌЦфжаКкЯпДњБэецЪЕжЕЃЌКьЯпДњБэдЄВтжЕЃЌПЩвдПДЕНІСжЕЮЊ0.3ЪБдЄВтНсЙћБШНЯЦНЛЌЕЋВЛЙЛзМШЗЃЌЬиБ№ЪЧдкЙеЕуГіЯжЕФЪБМфЕуЩЯЃЌЖјІСЮЊ0.9ЪБдЄВтжЕЪЎЗжНгНќецЪЕжЕЃЌЕЋетбљЕФдЄВтаЇЙћБШНЯЖЖЖЏЃЌЛсв§Ц№ЦЕЗБЕФжиХфжУЃЌдіМгИќаТбЙСІЃЌЖјІСЮЊ0.5ЪБЃЌЫфШЛЙеЕуДІЕФдЄВтжЕВЛЪЎЗжЬљНќецЪЕжЕЃЌЕЋЪЧФмЙЛМцЙЫдЄВтЦНЛЌКЭдЄВтСщУєетСНЕуашЧѓЁЃ
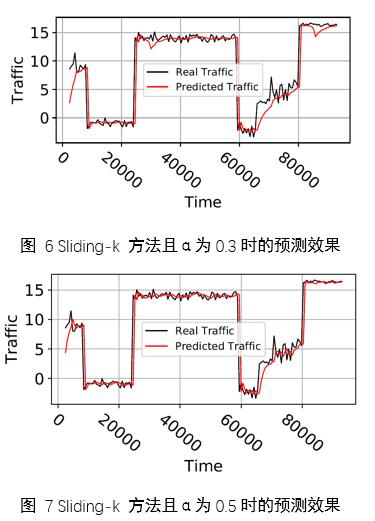
гЩгкЯывЊЪЕЯждЄВтжЕзуЙЛЦНЛЌЃЌЧвдкЙеЕуДІЕФдЄВтзуЙЛСщУєзМШЗЃЌвђДЫвЊНЋЙеЕуМьВтКЭEWMAНсКЯЪЙгУЃЌвВОЭЪЧБОЮФЬсГіЕФSliding-kЗНЗЈЁЃЕБEWMAЕФВЮЪ§жЕЩшжУЮЊ0.3ЪБЃЌЪЙгУSliding-kЗНЗЈЕУЕНЕФдЄВтаЇЙћШчЭМ 6ЃЌЖдБШІСЭЌбљЮЊ0.3ЕЋНіЪЙгУEWMAЗНЗЈЕФдЄВтаЇЙћЃЈЭМ 3ЃЉПЩвдЗЂЯжЃЌSliding-kФмЙЛУжВЙEWMAЕФВЛзуЃЌЪЙЙеЕуГіЯжЪБЕФдЄВтаЇЙћИќМгзМШЗЃЌЖјЕБІСЩшжУЮЊ0.5ЪБЃЌSliding-kдЄВтаЇЙћИќКУЃЌШчдЄВтаЇЙћдкЮоЙеЕуЪБЦНЛЌЃЌЖјдкгаЙеЕуЪБУєИаЧвзМШЗЃЌДяЕНСЫдЄЦкЕФдЄВтаЇЙћЁЃ
ЮхЁЂ НсТл
ДЋЭГЙЬЖЈДјПэЗжРыЕФЗНЪНЛсдьГЩетбљвЛжжЯжЯѓЃЌЕБИеадСїСПДІгкЙШжЕЕФЪБКђЃЌФЧаЉдЄСєИјЫќЕФДјПэгЩгквбОБЛЙЬЖЈЕиЗжХфИјСЫИеадСїСПЖјВЛФмБЛДѓСПЕЏадСїСПГфЗжРћгУЃЌДгЖјдьГЩЪ§ОнжааФМфСДТЗДјПэЕФРЫЗбЁЃЖјБОЮФЪЙгУСЫЖЏЬЌДјПэЗжРыЕФЗНЪНЃЌдЄВтИеадСїСПЕФДјПэеМгУЧщПіЃЌдкБЃжЄбгГйУєИааЭЕФИеадСїСПВЛЪмгАЯьЕФЬѕМўЯТНЋЪЃгрПЩгУЕФСДТЗДјПэШнСПЗжХфИјЕЏадСїСПЃЌетжжЛљгкдЄВтЕФдіСПЕїЖШЗНЪНПЩвдЪЙСДТЗРћгУТЪНгНќ100%ЃЌГфЗжЕиРћгУСЫСДТЗДјПэЁЃЮДРДПЩвдПМТЧЪЙгУEWMAжЎЭтЕФИќКУЕФЪБМфађСадЄВтЫуЗЈРДЬсИпдЄВтаЇЙћЃЌЪЙСДТЗРћгУТЪИќИпЖјЧвИќМгЮШЖЈЁЃ
ВЮПМЮФЯз
[1] Hong C Y, Kandula S, Mahajan R, et al. Achieving high utilization with software-driven WAN[C]//ACM SIGCOMM Computer Communication Review. ACM, 2013, 43(4): 15-26.
[2] Kumar A, Jain S, Naik U, et al. BwE: Flexible, hierarchical bandwidth allocation for WAN distributed computing[J]. ACM SIGCOMM Computer Communication Review, 2015, 45(4): 1-14.
[3] Savage S, Collins A, Hoffman E, et al. The end-to-end effects of Internet path selection[C]//ACM SIGCOMM Computer Communication Review. ACM, 1999, 29(4): 289-299.
[4] Zhang H, Chen K, Bai W, et al. Guaranteeing deadlines for inter-data center transfers[J]. IEEE/ACM Transactions on Networking (TON), 2017, 25(1): 579-595.
[5] Zhang Y, Xu K, Wang H, et al. Going fast and fair: Latency optimization for cloud-based service chains[J]. IEEE Network, 2017, 32(2): 138-143.
[6] Andreev K, Maggs B M, Meyerson A, et al. Designing overlay multicast networks for streaming[C]//Proceedings of the fifteenth annual ACM symposium on Parallel algorithms and architectures. ACM, 2003: 149-158.
[7] Sripanidkulchai K, Maggs B, Zhang H. An analysis of live streaming workloads on the internet[C]//Proceedings of the 4th ACM SIGCOMM conference on Internet measurement. ACM, 2004: 41-54.
[8] Zhang X, Liu J, Li B, et al. CoolStreaming/DONet: A data-driven overlay network for peer-to-peer live media streaming[C]//Proceedings IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies. IEEE, 2005, 3: 2102-2111.
[9] Huang T Y, Johari R, McKeown N, et al. A buffer-based approach to rate adaptation: Evidence from a large video streaming service[C]//ACM SIGCOMM Computer Communication Review. ACM, 2014, 44(4): 187-198.
[10] Datta A K, Sen R K. 1-Approximation algorithm for bottleneck disjoint path matching[J]. Information processing letters, 1995, 55(1): 41-44.
[11] Repantis T, Cohen J, Smith S, et al. Scaling a monitoring infrastructure for the Akamai network[J]. ACM SIGOPS Operating Systems Review, 2010, 44(3): 20-26.
[12] Mukerjee M K, Hong J A, Jiang J, et al. Enabling near real-time central control for live video delivery in CDNs[C]//ACM SIGCOMM Computer Communication Review. ACM, 2014, 44(4): 343-344.
[13] Lucas J M, Saccucci M S. Exponentially weighted moving average control schemes: properties and enhancements[J]. Technometrics, 1990, 32(1): 1-12.
[14] Adams R P, MacKay D J C. Bayesian online changepoint detection[J]. arXiv preprint arXiv:0710.3742, 2007.
[15] Roberts S W. Control chart tests based on geometric moving averages[J]. Technometrics, 1959, 1(3): 239-250.
[16] Lucas J M, Saccucci M S. Exponentially weighted moving average control schemes: properties and enhancements[J]. Technometrics, 1990, 32(1): 1-12.
[17] Jain S, Kumar A, Mandal S, et al. B4: Experience with a globally-deployed software defined WAN[C]//ACM SIGCOMM Computer Communication Review. ACM, 2013, 43(4): 3-14.
[18] Hong C Y, Mandal S, Al-Fares M, et al. B4 and after: managing hierarchy, partitioning, and asymmetry for availability and scale in google's software-defined WAN[C]//Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication. ACM, 2018: 74-87.
ЗжЯэШУИќЖрШЫПДЕН 
ЭЦМідФЖС
ДЋУНЭЦМі
 @УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад
@УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ
ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
ЯрЙиаТЮХ
ПЭЛЇЖЫЯТди
ШЫУёШеБЈЩчИХПі | ЙигкШЫУёЭј | БЈЩчеаЦИ | еаЦИгЂВХ | ЙуИцЗўЮё | КЯзїМгУЫ | ЙЉИхЗўЮё | Ъ§ОнЗўЮё | ЭјеОЩљУї | ЭјеОТЩЪІ | аХЯЂБЃЛЄ | СЊЯЕЮвУЧ
ЗўЮёгЪЯфЃКkf@people.cn ЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-65363263 ОйБЈгЪЯфЃКjubao@people.cn
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170001 | діжЕЕчаХвЕЮёОгЊаэПЩжЄB1-20060139
ЙуВЅЕчЪгНкФПжЦзїОгЊаэПЩжЄЃЈЙуУНЃЉзжЕк172КХ | ЛЅСЊЭјвЉЦЗаХЯЂЗўЮёзЪИёжЄЪщЃЈОЉЃЉ-ЗЧОгЊад-2016-0098
аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0104065 | ЭјТчЮФЛЏОгЊаэПЩжЄ ОЉЭјЮФ[2020]5494-1075КХ | ЭјТчГіАцЗўЮёаэПЩжЄЃЈОЉЃЉзж121КХ | ОЉICPжЄ000006КХ | ОЉЙЋЭјАВБИ11000002000008КХ
ШЫ Уё Эј Ац ШЈ Ыљ га ЃЌЮД О Ъщ Уц Ък ШЈ Нћ жЙ ЪЙ гУ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЦРТл

-
ЙизЂ
ЮЂаХЮЂВЉПьЪж
 ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
 БЈЕРШЋЧђ ДЋВЅжаЙњ
БЈЕРШЋЧђ ДЋВЅжаЙњ
 ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
