




















»щУЪЗ±ТтЧУЖА·Ц·өАҰС§П°µДІН№ЭНЖәц
ХҒТҒӘғµ±ҢсЙз»бӘ¬ФЪИЛГЗНвіцңНІНК±Ә¬ңНІНµДСҰФсІ»ҢцҢцИҰңцУЪО¶µАӘ¬Н¬К±ТІКЬµҢРн¶аЖдЛыТтЛШµДУ°ПмҰӘТтөЛӘ¬ІНМьНЖәцЦР№ШәьµДОКМв±гКЗӘ¬·ұңтУГ»§СҰФсК±µДЗ±ФЪУ°ПмТтЛШҰӘ±ңОДёщңЭµ±ПВЦчБчІНТыЙзҢ»НшВзµДКэңЭҢшРР·ЦОцӘ¬ФЪёцРФ»ҮНЖәцәәКхДӘРНУлЛг·ЁЙПМбіцБЛРВµДДӘРНӘ¬Т»·ҢГжӘ¬¶ФУЪОөАөЦЗДЬЙъ»оµДІНТыНЖәц·юОс·ҢКҢә°ЖдНшВзәәКхЧціцБЛМҢЛчУлЛµГчӘ¬БнТ»·ҢГжӘ¬¶ФөуЦЪІНТыПы·СОД»ҮөУКэңЭНЪңтҢЗ¶ИЧціцәәКхМҢЛчУлЛµГчӘ¬үЙғуРшОҒИЛГсНшҢв¶БөуЦЪІНТыПы·СРДАнЧцәәКхҢЗ¶ИЦ§іЕҰӘ±ңОДНЪңтУГ»§СҰФсІНМьК±Лщ№ШРДµДҰұЗ±ФЪµДЦчМвТтЛШӘ¬ІұҢ«ЖдУ¦УГФЪІН№ЭНЖәцЦРҰӘОТГЗК№УГLDAДӘРНМбИҰБЛІНМьµДЗ±ФЪЦчМвМШХчӘ¬ёщңЭЗ±ФЪЦчМвТтЛШ·ЦІәМШХчҢшРРЖАә¶·өАҰС§П°ТФә°әЖЛгПаЛЖ¶ИӘ¬ІұңЭөЛЧціцЖАә¶Ф¤ІвғНІНМьНЖәцҰӘ±ңОДАыУГYelpКэңЭәҮЦРµДЖАВЫКэңЭҢшРРБЛКµСйӘ¬МҢЛчБЛЛг·ЁµДРФДЬғНЧоУЕЦчМвКэKҰӘКµСйҢб№ы±нГчӘ¬ёГЛг·ЁФЪЖАә¶Ф¤Ів·ҢГжИҰµГБЛТ»Р©ҢшХ№ғНіЙ№ыҰӘөУТ»¶ЁіМ¶ИЙПАөЛµӘ¬Ң«З±ФЪЦчМв·ЦІәУ¦УГУЪІНМьНЖәцОКМвүЙТФҢвңцКэңЭПҰКиРФОКМвӘ¬әхЙЩәЖЛгО¬¶ИӘ¬МбёЯЖАә¶Ф¤ІвµДЧәИ·РФҰӘ
№ШәьөК: З±ФЪТтЛШ; ЖАә¶·өАҰ; ІНМьНЖәц; LDA
1. әтҢй
ҢьДкАөӘ¬ІНТыТµ·ұХ№СёЛЩӘ¬Рн¶аІНМьФЪІНТыӘ¬ІНТы·юОсғНІНТыЧ°КО·зёс·ҢГжҢшРРБЛөөРВіұКФҰӘ ДкЗбИЛФЪСҰФсІНМьК±үәВЗµДТтЛШТІ±дµГ¶аСщ»ҮӘ¬¶шІ»ҢцҢцКЗЦ»№ШЧұКіОпµДО¶µАБЛҰӘТ»Р©ІНТыЙзҢ»ГҢМеМṩБЛ¶а·ҢГжЖАә¶»ъЦЖӘ¬АэИзӘ¬өуЦЪµгЖАНшМṩ»·ңіҰұЖ·О¶Ұұ·юОсИэ·ҢГжЖАә¶·юОсҰӘФЪХвСщµДЖАә¶»ъЦЖПВӘ¬УГ»§ЖАә¶РЕПұФЪ·өУіІНМьМШХч·ҢГжИФИ»ПФµГБ¦І»өУРДҰӘТтөЛӘ¬µ±ПВРиТҒТ»ёц¶аО¬µДҰұ°ьғ¬¶аЦЦУ°ПмТтЛШЖАә¶РЕПұАө±нКңІНМьµДМШХчҰӘ
КіЖ·ЧЁәТүЙТФ¶ФІНңЯҢшРРПкПё·ЦАаӘ¬µ«ғЬДСүШЦЖ·ЦАаµДБӘ¶ИӘ¬ТІғЬДСОҒПаУ¦ЦЦАаµДІНМьЙиЦГИЁЦШЦµҰӘө«НіµД»щУЪОпЖ·µДРµч№эВЛНЖәцЛг·ЁУЙУЪ»щУЪУГ»§µДАъК·РРОҒҢшРРНЖәціӘіӘүЙТФёшіцПа№ШҢвКНӘ¬ХвР©ҢвКННЁіӘ»бИГУГ»§ёьәУРЕ·юҰӘ±ңОДКФНәҢЁБұТ»ёцДӘРНӘ¬үәВЗІНМьµДЗ±ФЪµДҰұ¶аСщ»ҮµДТтЛШғНүН»§µДАъК·РРОҒӘ¬ОҒүН»§МбіцУРР§µДІНМьНЖәцҰӘ
ТФЗ°µДСРңү±нГчӘ¬УГ»§МṩµДЖАВЫ°ьғ¬µДРЕПұ±ИіӘәыНЖәцПµНіЦРө¦АнµДЖАә¶РЕПұёь·бё»[1]Ә¬ТтөЛӘ¬±ңОДЧЕЦШөУУГ»§ІъЙъµДЖАВЫЦРНЪңтёчЦЦЗ±ФЪµДІНМьЦчМвТтЛШҰӘ
±ңОДМбіцБЛТ»ЦЦ»щУЪLDAµДРН¬№эВЛЛг·ЁӘ¬ёГЛг·ЁүәВЗБЛЖАВЫЦРЗ±ФЪµДЦчМвТтЛШНЪңтғНүН»§µДАъК·ЖАә¶·өАҰӘ¬ІұҢшРРБЛКµСйСйЦ¤БЛЛг·ЁµДУРР§РФҰӘЧоЦХµДіЙ№ыОҒӘғ1Ә©ФЪПтУГ»§НЖәцІНМьК±Ә¬І»ҢцүәВЗүЪО¶ТтЛШӘ¬Н¬К±ТІүәВЗёчЦЦЗ±ФЪµДЦчМвТтЛШӘ»2Ә©МбИҰІНМьµДЗ±ФЪЦчМв·ЦІәМШХчӘ¬ІұТАөЛЙъіЙЗ±ФЪµДK-ЦчМвЖАә¶ңШХуӘ¬Ңш¶ш·ЦОцУГ»§µДЖ«ғГҰӘ3Ә©У¦УГМбИҰµГµҢµД¶аЦЦЗ±ФЪТтЛШАөҢшРРІН№ЭНЖәцҰӘ
±ңОД·ЦОҒЖЯёцІү·ЦҰӘµЪТ»Іү·ЦҢйЙЬБЛОКМвµДЖрФөғН±ің°Ә¬µЪ¶юІү·ЦҢйЙЬБЛҢшРРµДПа№Ш№¤ЧчҰӘ¶шµҢБЛµЪИэІү·ЦӘ¬ҢшРРБЛОКМвµД¶ЁТеӘ»µЪЛДІү·ЦФтКЗГиКцБЛ№¤ЧчЦРМбіцµДДӘРНҰӘµЪОеІү·ЦӘ¬ПкПёГиКцБЛКµСйµДХыМеІұ¶ФКµСйҢб№ыҢшРРБЛ·ЦОцҰӘµҢБЛµЪБщІү·ЦӘ¬КЗЧоЦХµДҢбВЫғНПВТ»ІҢТҒҢшРРµД№¤ЧчҰӘЧоЦХФтКЗТэУГµДОДПЧБР±нҰӘ
2. Па№Ш№¤Чч
Lihua Sun µИИЛФЪ¶ФФЪПЯЦРОДЖАВЫҢшРРЗйёР·ЦОцµД»щөҰЙПӘ¬Ң«І»И·¶ЁРФАнВЫТэИлІНМьНЖәцПµНіӘ¬ІұТФөЛАөНЪңтУГ»§µДТвәы[1]ҰӘSonya ZhangµИИЛНЁ№эҢЁБұ»щУЪПы·СХЯИғМеІНМьЖАВЫµДНЖәцПµНіӘ¬МбіцБЛДЪИЭ№эВЛНЖәцПµНіӘ¬ёГПµНіЖА№АёцИЛФЪПЯЖАВЫӘ¬ІұОҒПё·ЦіцµДОеёцПы·СХЯАаРН·ЦЕдПаУ¦µДКэЦµµГ·Ц[2]ҰӘХвР©ВЫОД¶әФЪТ»¶ЁіМ¶ИЙПЖф·ұБЛ±ңОДµДЛәВ·ҰӘОҒБЛНЪңтёчЦЦЗ±ФЪµДЦчМв·ҢГжғНМШХчӘ¬±ңОДК№УГБЛ»щУЪНЪңтУГ»§µДЖАВЫµД·Ң·ЁАөЦЖЧчІНМьМШЙ«Пё·ЦҰӘ
Chao LiӘ¬Srn FengµИУ¦УГLDAғНWordNetЧйғПЛг·ЁНЪңтСРңүүОМвµД¶ҮМ¬Ә¬ИҰµГБЛғЬғГµДіЙ№ы[3]ҰӘMaha AmamiµИИЛҢ«»щУЪLDAµД·Ң·ЁУ¦УГУЪүЖС§ВЫОДНЖәц[4]ҰӘShinjee PyoµИФЪНіТ»µДЦчМвҢЁДӘүтәЬЦРӘ¬К№УГLDAДӘРН·ЦОцµзКУУГ»§ИғғНµзКУҢЪДүӘ¬Ң«АаЛЖµДµзКУУГ»§ғН№ШБҒГиКцөКН¬К±УГУЪ№ЫүөµзКУҢЪДү[5]ҰӘLDAДӘРНФЪЗ±ФЪµДЦчМвМШХчЦР±нПЦіцғЬөуµДУЕКЖӘ¬ІұЗТіЙ№¦ЦёіцБЛККµ±µДАа±рҰӘ
ТФНщµДСРңү±нГчӘ¬ІНМь№ЛүНЖАВЫүЙТФ·ЦОҒ¶аЦЦТтЛШӘ¬Из·юОсЦКБүӘ¬ІъЖ·ЦКБүӘ¬ІЛµӨ¶аСщРФӘ¬әЫёсғНәЫЦµӘ¬·ХО§µИ[2]ҰӘYifan GaoµИИЛҢЁБұБЛТ»ёц»щУЪРВДӘРНµДІНМьНЖәцПµНіӘ¬ёГДӘРНІ¶»сЖАВЫғНКэЧЦЖАә¶ЦРТюІШ·ҢГжЦ®әдµДПа№ШРФӘ¬ІұНЁ№эКµСйЦ¤ГчБЛЖдУЕКЖ[6]ҰӘТтөЛӘ¬ҢЁБұТ»ёцүәВЗБЛөУЖАВЫғНүН»§µДАъК·РРОҒНЪңтµДЗ±ФЪТтЛШµДҰұ»щУЪLDAДӘРНУлitem-CFµДІНМьНЖәцПµНіКЗЦµµГғНүЙРРµДҰӘ
3. ОКМв¶ЁТе

ОҒБЛҢвңцХвёцОКМвӘ¬±ңОДКФНәК№УГРЮёДғуµДitem-CFАөФ¤ІвЖАә¶ҰӘКЧПИӘ¬ФЪө«НіµДitem-CFЦРӘ¬К№УГУГ»§-ПоДүЖАә¶ңШХуАөәЖЛгПоДүЦ®әдµДПаЛЖРФҰӘИ»ғуӘ¬СҰФсУлДү±кПоңЯУРЧоөуПаЛЖ¶ИµДЗ°KёцПоӘ¬ТФ№№ФмБЪңУәҮҰӘЧоғуӘ¬НЁ№эБЪңУәҮµДТСЦҒЖАә¶µДәУИЁғНАөФ¤ІвДү±кПоµДОөЦҒЖАә¶ҰӘФЪ±ңОДЦРӘ¬ОТГЗКФНәАыУГЖАВЫЦРµДЗ±ФЪТтЛШМШХчАөәЖЛгПоДүЦ®әдµДПаЛЖРФӘ¬¶ш·ЗК№УГУГ»§-ПоДүЖАә¶ңШХуµДМШХчҰӘ
4. »щУЪLDAµДНЖәцДӘРН
ФЪ±ңҢЪЦРӘ¬±ңОДКЧПИНЁ№эLDAЦчМвДӘРННЪңтЖАВЫАөМбИҰІН№ЭЗ±ФЪµДЦчМв·ЦІәМШХчҰӘЛжғуӘ¬ОТГЗҢйЙЬПаЛЖ¶ИµДәЖЛгҰӘЧоғуӘ¬ОТГЗҢшРРЖАә¶Ф¤ІвғНЙъіЙНЖәцҰӘ
4.1. З±ФЪЦчМв·ЦІәМШРФ
±ңОДКФНәНЁ№эНЪңтУГ»§№ШРДµДЗ±ФЪТтЛШ№№ҢЁЗ±ФЪµДЦчМв·ЦІәМШХчӘ¬ІұТФөЛАө±нКңІНМьµДМШХчҰӘңЯМеАөЛµӘ¬ОҒБЛХТµҢЗ±ФЪµДҰұУГ»§№ШРДµДТтЛШӘ¬±ңОДЦВБ¦УЪХТµҢУГ»§ңіӘЖАВЫµДЦчМвӘ¬ІұНЖ¶ПёГЦчМвФЪІНМьµДЖАВЫЦРЖАВЫµДЖµВКҰӘОҒөЛӘ¬±ңОДІЙУГLDAЦчМвДӘРНөУІНМьЖАВЫЦР»сИҰЗ±ФЪµДЦчМв·ЦІәҰӘ
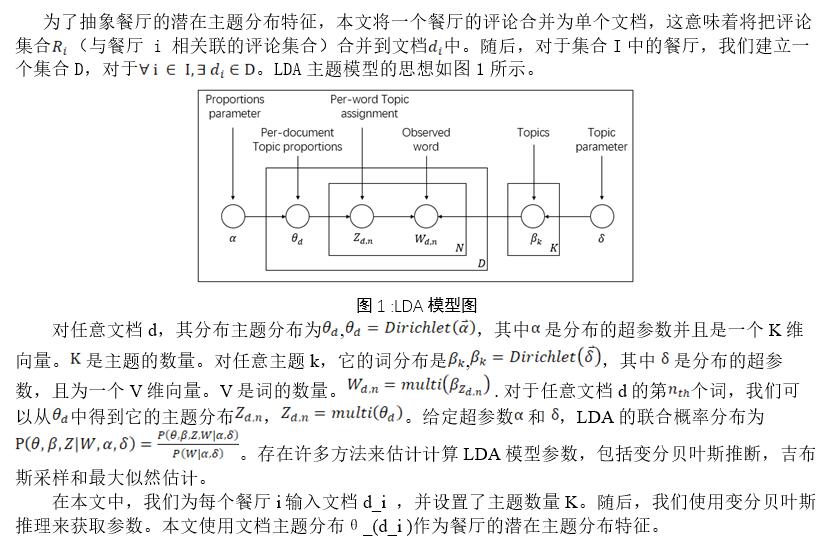
4.2. ПаЛЖ¶ИәЖЛг
З±ФЪЦчМв·ЦІәМШХч·өУіБЛУГ»§№ШРДµДЦчМвТФә°УГ»§№ШЧұөЛЦчМвµДЗү¶ИӘ¬µ«ОЮ·Ё·өУіЦчМвКЗ»эә«»№КЗПыә«µДҰӘТтөЛӘ¬ОТГЗҢ«ЖАә¶·ЦҢвµҢKёцЗ±ФЪЦчМв·ЦІәӘ¬»сµГПоДү-KЦчМвЖАә¶ңШХуҰӘФЪДіЦЦіМ¶ИЙПӘ¬ПоДү-KЦчМвЖАә¶ңШХуУлУГ»§¶ФІНМьµДёчёц·ҢГжµДПкПёЖАә¶РЕПұ»щ±ңПаН¬ҰӘ

4.3. ЖА·ЦФ¤ІвУлЙъіЙНЖәц
ФЪК№УГПоДүKЦчМвЖАә¶ңШХуәЖЛгІНМьЦ®әдµДПаЛЖРФЦ®ғуӘ¬К№УГ»щУЪПоДүµДРН¬№эВЛЛг·ЁАөФ¤ІвЖАә¶ІұЗТК№µГTop-KІНМьРОіЙНЖәцБР±нҰӘ¶ФУЪУГ»§uғНІНМьiӘ¬ЖАә¶Ф¤ІвЧсСТФПВ№«КҢӘғ
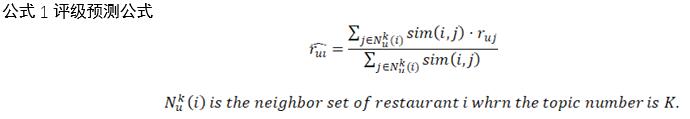
5. КµСй
5.1. КэңЭәҮ
±ңОДК№УГYelpКэңЭәҮМфХҢИьµЪ12ВЦМṩµДYelpКэңЭәҮҢшРРБЛКµСйҰӘХыёцКэңЭәҮ°ьАЁ10ёцөуіЗКРµД18.8Нтёц±ңµШЖуТµғН1518169ёцУГ»§¶Ф188593ёцЖуТµµД5996995МхЖАВЫµДРЕПұҰӘЖдЦРӘ¬ОТГЗК№УГЖАВЫКэңЭЦРµДЗ°25176МхЖАВЫәЗВәҢшРРБЛКµСйӘ¬ЖдЦР°ьғ¬АөЧФ10,000ёцУГ»§µД18,479әТІНМьµДЖАә¶ғНПаУ¦ЖАВЫҰӘ
КЧПИӘ¬ОТГЗҢ«Н¬Т»ІНМьµДЖАВЫғПІұµҢН¬Т»ОДµµЦРҰӘҢУЧЕӘ¬К№УГБЛnltkүвФ¤ө¦АнОДµµҰӘИ»ғуӘ¬К№УГsklearnүвОҒОДµµ№№ҢЁLDAДӘРНӘ¬ТФ»сµГІНМьµДЗ±ФЪЦчМв·ЦІәӘ¬ІұҢ«ЖАә¶·ЦҢвµҢK-ЦчМвЙПғуәЖЛгІНМьЦ®әдµДПаЛЖРФҰӘЧоғуӘ¬ОТГЗҢ«ПаЛЖРФУ¦УГУЪРН¬№эВЛЛг·ЁӘ¬УГУЪЖА·ЦФ¤ІвғНTop-KНЖәцҰӘ±ңКµСйК№УГMAEӘЁЖҢңщңш¶ФЖ«ІоӘ¬әы·ҢіМ2Ә©Ә¬RMSEӘЁңщ·ҢёщОуІоӘ¬әы·ҢіМ3Ә©Ә¬FCPӘЁРµч¶ФµД·ЦКэ[7]Ә©АөУГ5ХЫҢ»ІжСйЦ¤ІвБүЛг·ЁµДЖАә¶Ф¤ІвµДЧәИ·РФҰӘӘЁОТГЗК№УГКэңЭәҮµД80ӘӨЧчОҒСµБ·КэңЭӘ¬ТФә°Чч20ӘӨОҒІвКФәҮӘ©ҰӘMAE·өУіБЛЖАә¶Ф¤ІвЛг·ЁµДңш¶ФОуІоЛ®ЖҢӘ¬RMSE·өУіБЛЧәИ·Ф¤ІвЖАә¶µДОИ¶ЁРФӘ¬¶шFCP±нКңФ¤ІвҢб№ыУлКµәККэңЭЦ®әдµДТ»ЦВРФ¶ФКэҰӘ

5.2. ЧоУЕЦчМвКэK
±ңОДЦРӘ¬ПаЛЖ¶ИµДәЖЛгИҰңцУЪөУLDAДӘРНЦРМбИҰµДЗ±ФЪЦчМв·ЦІәӘ¬ЦчМвКэK¶ФЛг·ЁµДЧәИ·РФУРТ»¶ЁµДУ°ПмҰӘТтөЛӘ¬±ңКµСйМҢЛчБЛЧоУЕЦчМвКэKӘ¬ҢшРРБЛKҰК[6,38]µДКµСйӘ¬ЖдЦРғНKҰКNЗТІҢі¤ОҒ4ҰӘКµСйҢб№ыИзПВНәЛщКңӘЁәыНә2ғН±н1Ә©ҰӘ
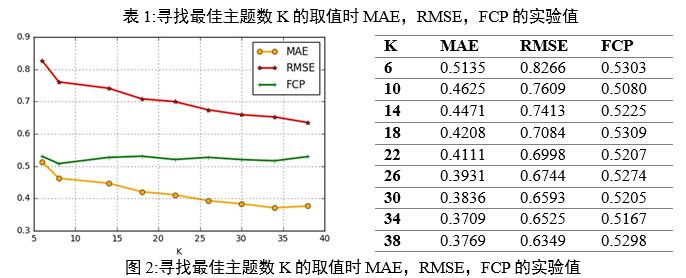
ИзНәЛщКңӘ¬µ±KЦµФцәУК±Ә¬MAEғНRMSEµДЦµәхРҰӘ¬ХвТвО¶ЧЕЛг·ЁµДЧәИ·РФФцЗүӘ¬Лг·ЁРФДЬµДОИ¶ЁРФФцЗүҰӘЛжЧЕKµДФцәУӘ¬FCPµДЦµФЪғЬРҰµД·¶О§ДЪІЁ¶ҮӘ¬ХвТвО¶ЧЕТ»ЦВ¶ФКэµДКэБүГ»УРПФЧЕФцәУҰӘҢб№ыӘ¬KµД±д»Ү¶ФМбёЯЧәИ·ЖАә¶Ф¤ІвµДТ»ЦВРФЛ®ЖҢәёғхГ»УРУ°ПмҰӘЧЬМе¶шСФӘ¬KµДФцәУүЙТФПФЧЕҢµµНMAEғНRMSEӘ¬µ«КЗ¶ФFCPµД±д»ҮГ»УРПФЧЕУ°ПмӘ¬ХвТвО¶ЧЕёцМеµГ·ЦФ¤ІвµДЧәИ·РФғНОИ¶ЁРФҢ«µГµҢМбёЯӘ¬µ«ЧЬМеФ¤ІвТ»ЦВРФІ»»бУРғЬөуМбЙэҰӘ
БнТ»·ҢГжӘ¬µ±KµДЦµФцәУК±Ә¬ХвР©ЦчМвµДүЙҢвКНРФҢµµНІұЗТЛг·ЁµДәЖЛгёөФУРФФцәУҰӘ»щУЪЙПКц·ЦОцӘ¬¶ФУЪЦчМвKҰК[6,38]Ә¬ЖдЦРKИҰЦµТАөООҒІҢі¤ОҒ4µДЧФИ»КэӘ¬ЧоУЕKОҒ38ҰӘ
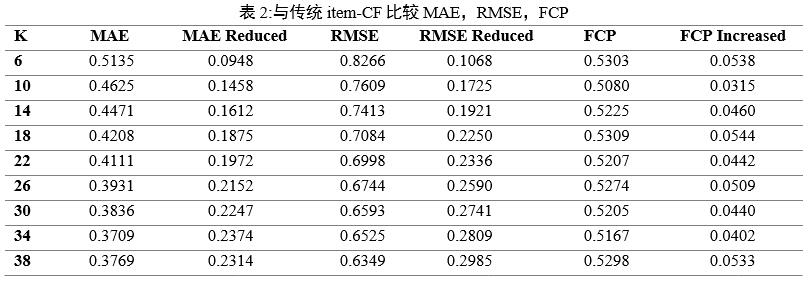
5.3. Лг·ЁРФДЬ
ФЪПаН¬МхәюПВӘ¬±ңОДІЙУГө«НіµД»щУЪПоДүµДРН¬№эВЛЛг·Ё¶ФПаН¬КэңЭҢшРРКµСйҰӘҢб№ыИзПВӘғMAE=0.6083, RMSE=0.9334, FCP=0.4765ҰӘУлө«НіµДРН¬№эВЛЛг·ЁПа±ИӘ¬ёГЛг·ЁµДMAEғНRMSEТ»°гҢПРҰӘ¬ТтөЛүЙТФЛµМбёЯБЛЛг·ЁµДЧәИ·РФғНОИ¶ЁРФҰӘёГДӘРНЦРµДFCPҢПөуӘ¬ТтөЛӘ¬ёГЛг·ЁµДТ»ЦВРФµГµҢБЛёДЙЖӘЁәы±н2Ә©ҰӘАыУГёГЛг·ЁӘ¬үЙТФМбёЯёцМеµГ·ЦФ¤ІвµДЧәИ·РФғНОИ¶ЁРФӘ¬ІұФЪТ»Р©ДЪИЭЙПМбёЯХыМеФ¤ІвТ»ЦВРФҰӘОТГЗүЙТФµГіцТФПВҢбВЫӘғLDAЦчМвДӘРНФЪІНМьМШХчМбИҰғНІНМьНЖәцТФә°ОД±ңПа№ШНЖәцЦР±нПЦіцБәғГµДРФДЬҰӘ
5.4. КµСйҢб№ыУлМЦВЫ
±ңОДК№УГПоДүKЦчМвЖАә¶ңШХуАөәЖЛгПаЛЖРФӘ¬Хл¶ФДіР©ДЪИЭӘ¬ҢвңцУЙПҰКиУГ»§ПоЖАә¶ңШХуТэЖрµДКэңЭПҰКиРФОКМвӘ¬ІұҢ«әЖЛгО¬¶ИөУУГ»§КэәхЙЩµҢЦчМвКэҰӘПоДүKЦчМвЖАә¶ңШХуГиКцБЛАөЧФK·ҢГжµДІНМьµДМШХчӘ¬Жд±ИУГ»§ЖАә¶ңШХуёьПкПёӘ¬ТтөЛөшАөёьЧәИ·µДПаЛЖРФғНЖАә¶Ф¤ІвҰӘ
6. ҢбВЫ
±ңОДөУНЪңтУГ»§№ШРДµД¶аЦЦЗ±ФЪЦчМвµДҢЗ¶ИСРңүБЛІНМьНЖәцПµНіҰӘОТГЗЙиәЖБЛЗ±ФЪЦчМв·ЦІәМШХчғНПоДү-KЦчМвЖАә¶ңШХуӘ¬ТФХығПЗ±ФЪТтЛШғНЖАә¶әЗВәЦР°ьғ¬µДМШХчӘ¬ІұҢ«ЛьГЗУ¦УГУЪПаЛЖ¶ИәЖЛгҰӘ±ңОД»№ҢшРРБЛТ»ПоКµСйӘ¬ТФМҢЛчЧоәСЦчМвКэKӘ¬ІұҢ«РФДЬУл»щПЯЛг·Ё-Item CFҢшРР±ИҢПҰӘёщңЭКµСйҢб№ыӘ¬ОТГЗүЙТФµГіцҢбВЫӘ¬НЪңтУГ»§№ШРДµДЗ±ФЪ·ҢГжүЙТФ°пЦъҢвңцІНМьНЖәцµДОКМвҰӘ
7. ІОүәОДПЧ
[1] Lihua Sun, Junpeng Guo, Yanlin Zhu. Applying uncertainty theory into the restaurant recommender system based on sentiment analysis of online Chinese reviews[J]. World Wide Web,2019,2019, 22(1): 83-100
[2] Sonya Zhang, Mohammad Salehan, Andrew Leung, Ishmene Cabral, Navid Aghakhani. A Recommender System for Cultural Restaurants Based on Review Factors and Review Sentiment[A]. AMCIS[C].2018
[3] Chao Li, Sen Feng, Qingtian Zeng, Weijian Ni, Hua Zhao, Hua Duan:Mining Dynamics of Research Topics Based on the Combined LDA and WordNet[J]. IEEE Access,2019,7: 6386-6399
[4] Maha Amami, Gabriella Pasi, Fabio Stella, Rim Faiz.An LDA-Based Approach to Scientific Paper Recommendation[J]. NLDB,2019: 200-210
[5] Shinjee Pyo, Eunhui Kim, Munchurl Kim. LDA-Based Unified Topic Modeling for Similar TV User Grouping and TV Program Recommendation[J]. IEEE Trans. Cybernetics,2015,45(8): 1476-1490
[6] Yifan Gao, Wenzhe Yu, Pingfu Chao, Rong Zhang, Aoying Zhou, Xiaoyan Yang:A Restaurant Recommendation System by Analyzing Ratings and Aspects in Reviews. DASFAA,2015,(2) : 526-530
[7] Koren Y , Sill J. Proceedings of the Twenty-Third international joint conference on Artificial Intelligence[A].Collaborative filtering on ordinal user feedback[C]. 2013.
·ЦПнИГёь¶аИЛүөµҢ 
НЖәцФД¶Б
ө«ГҢНЖәц
 @ГҢМеИЛӘ¬РВОЕ±ЁµА±рИОРФ
@ГҢМеИЛӘ¬РВОЕ±ЁµА±рИОРФ НшХңФЛУҒХЯ ХвР©"ғмПЯ"І»ДЬІИӘҰ
НшХңФЛУҒХЯ ХвР©"ғмПЯ"І»ДЬІИӘҰ Т»НәЧЭААЦР№ъНшВзКУМэРРТµ
Т»НәЧЭААЦР№ъНшВзКУМэРРТµ
Па№ШРВОЕ
- ИГҰ°ГААцТтЧУҰ±·ұЙъҰ°БС±дҰ±
- ЧЁәТӘғөчүЪХЦЗЪПөКЦЧи¶ПБЛЦВІҰТтЧУө«ІӨ
- РВ№ЪТЯЗй»тФміЙУҰ¶ИЦБЙЩЛДіЙІН№Эµ№±Х
- БщіЙКЬ·ГХЯЦ»»бСҰФс·АТЯөлК©µҢО»µДІН№Э
- ғфУхёь¶аІН№ЭНЖіцҰ°РҰ·ЭІЛҰ±Ұ°ЖөЕМІЛҰ±
- Ч·ЗуҰ°У°ПмТтЧУҰ±І»ИзәбКШ°мүҮҰ°ТтЧУҰ±
- ФщЛНҰ°№вЕМҰ±Ң±Аш ёчІН№Э¶аөлІұңЩ±ЬГвңНІНАЛ·С
- ИИөш·з±©µЗВҢЕ¦Фә »ҒІғІН№Э»§НвУГІНКЬУ°Пм
- ЖА·Ц·ЧХщІ»¶ПӘғИИГЕУ°КУңзµДҰ°үЪ±®Ұ±»№үЙүүВр
- °І»Х»өДПНЁ±ЁІН№Э±¬ХЁФТт ңУҒХЯ±»ТА·ЁүШЦЖ
үН»§¶ЛПВФШ
ИЛГсИХ±ЁЙзёЕүц | №ШУЪИЛГсНш | ±ЁЙзХРЖё | ХРЖёУұІЕ | №гёж·юОс | ғПЧчәУГЛ | №©ёе·юОс | КэңЭ·юОс | НшХңЙщГч | НшХңВЙК¦ | РЕПұ±Ә»¤ | БҒПµОТГЗ
·юОсУКПдӘғkf@people.cn ОӨ·ЁғНІ»БәРЕПұңЩ±Ёµз»°Әғ010-65363263 ңЩ±ЁУКПдӘғjubao@people.cn
»ӨБҒНшРВОЕРЕПұ·юОсРнүЙЦ¤10120170001 | ФцЦµµзРЕТµОсңУҒРнүЙЦ¤B1-20060139
№гІӨµзКУҢЪДүЦЖЧчңУҒРнүЙЦ¤ӘЁ№гГҢӘ©ЧЦµЪ172ғЕ | »ӨБҒНшТ©Ж·РЕПұ·юОсЧКёсЦ¤КйӘЁң©Ә©-·ЗңУҒРФ-2016-0098
РЕПұНшВзө«ІӨКУМэҢЪДүРнүЙЦ¤0104065 | НшВзОД»ҮңУҒРнүЙЦ¤ ң©НшОД[2020]5494-1075ғЕ | НшВзіц°ж·юОсРнүЙЦ¤ӘЁң©Ә©ЧЦ121ғЕ | ң©ICPЦ¤000006ғЕ | ң©№«Нш°І±ё11000002000008ғЕ
ИЛ Гс Нш °ж ИЁ Лщ УР Ә¬Оө ң Кй Гж КЪ ИЁ Ңы Ц№ К№ УГ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЖАВЫ

-
№ШЧұ
ОұРЕОұІ©үмКЦ
 µЪТ»К±әдОҒДъНЖЛНИЁНюЧКС¶
µЪТ»К±әдОҒДъНЖЛНИЁНюЧКС¶
 ±ЁµАИ«Зт ө«ІӨЦР№ъ
±ЁµАИ«Зт ө«ІӨЦР№ъ
 №ШЧұИЛГсНшӘ¬ө«ІӨХэДЬБү
№ШЧұИЛГсНшӘ¬ө«ІӨХэДЬБү
