




















基于动宾短语和主题模型的相似缺陷报告识别方法
摘要:近年来,随着软件技术的蓬勃发展,软件系统及开发团队的规模也随之迅速增长。若能识别出与新的待修复缺陷报告相似的缺陷报告集合,则对修复缺陷的方法以及修复者指派具有指导性意见;识别相似的代码文件对修复相似的缺陷也有着重要意义,另外对于大型的软件项目,从投入使用到维护阶段,其历史缺陷报告及历史代码文件也会越来越多,其中可用的信息也会越来越多。
本文提出一种基于动宾短语和主题模型的相似缺陷报告识别方法。除了利用通常使用的向量空间模型方法表示文本信息外,通过句法分析提取缺陷报告的结构化信息作为衡量报告间相似度的重要依据。
关键字:相似缺陷;缺陷报告;句法分析
0 引言
随着软件系统的发展,代码数量与日俱增,系统规模及开发人员数量也随之增加。因此,在软件开发及测试的过程中,开发人员会得到大量的缺陷报告。这些缺陷报告中,也会存在更多的重复或相似的缺陷报告。当开发人员处理这样的缺陷报告时,必然会降低其工作效率,甚至引入一些不必要的错误;而相似的缺陷报告往往可通过相同或相似的方法予以解决,因此,相似缺陷报告的出现从某种程度上可为开发人员处理新的待修复缺陷报告提供部分解决思路和方法。
1 背景
缺陷报告中的缺陷信息是用自然语言描述的,因此,需要将缺陷报告中的摘要及描述等文字信息转换成计算机能够识别的信息。目前使用最广泛且较适合于提取缺陷报告文本信息的方法是G Salton等人提出的向量空间模型(VSM:Vector Space Model),且目前较为流行也是效果较好的两种表示方式为TF-IDF以及word2vec两种方法,这两种方法也广泛用于很多其他的自然语言处理的问题上,并取得了较好效果[1,2,3]。
但仅依据以上两种方法构建的向量空间模型仅是将缺陷报告中的文本转化为向量,而没有考虑到结构化信息以及语序对向量模型的影响。若要对缺陷报告文本进行客观、准确的相似度评价,还要参考实验文本中语句的词序、语句结构、文本结构等因素对实验结果的影响。
因此,本文结合缺陷报告的文本特点,在计算词汇间相似度的基础上加入文本的结构化信息从而构建出每份缺陷报告的特征向量,之后将三部分特征向量拼接在一起得到用来表征每份缺陷报告的特征向量,最后使用目前常用的几种机器学习分类算法对缺陷报告集合分类。该部分相似缺陷报告提取方法如图所示。
得到每份缺陷报告的特征向量后,可以基于每个特征向量间的欧氏距离、皮尔森相关系数、余弦相似度等方法衡量其相似度。

2 基于白名单的特征向量构建
本文采用的数据集均为基于Java语言的软件工程及项目,而每种高级程序语言均由其独有的词汇表示。这些词汇在不同类型的缺陷报告中出现的频率不尽相同,也就是说,在某种类型的缺陷报告集合中某个词或某几个词出现的概率较大、次数较多,而其他词语出现的概率较小、次数较少。因此,每一份缺陷报告都可以基于其文本中特定的某些词出现的频率分布预测该缺陷报告的类别。
本文基于Java语言的特点,预先找出其相关的专业词汇列表(即白名单),对每一份缺陷报告统计列表中词语在该缺陷报告的摘要及描述信息中出现的次数,即用one-hot的形式对每一份缺陷报告统计某些词出现的次数以构建该部分特征向量。
另外,由于每份缺陷报告中文本的长度不同,每个文本中包含的词汇量有时差异会很大,因此每个词出现的次数差别较大,为避免该因素对实验结果的影响,对每份缺陷报告得到的特征向量均作归一化处理。也就是说,特征向量的每一维都转化为表示该词汇在该缺陷报告中的频率,即该词在这份缺陷报告中的重要程度,这其实更符合本文要求。
3 基于结构化信息的特征向量构建
对于每一份缺陷报告,并不是文本中的每一个词语对文本来说都非常重要,如果将这些词也考虑进去势必会影响预测结果的准确性。因此,需要利用某种方法提取出文本中最重要的那些词语。
在本文使用的数据集中,缺陷报告均由英文书写。基于英文特殊的表述方式,可以观察到,当用户或测试人员编写缺陷报告时,需要依托于动宾短语的表述形式描述软件的缺陷现象以及该缺陷的重现方法等等。因此,本文对每份缺陷报告的摘要及描述信息文本句法分析并提取其中的动宾短语,找到该缺陷报告文本中最能表征缺陷内容的文本片段,再基于这些文本片段构建其对应的特征向量。
3.1句法分析
句法分析(parsing)是指对文本中语句的词语进行语法功能分析。句法分析在自然语言处理(natural language processing,NLP)领域中占有重要地位,是其关键底层技术之一,其主要应用是确定文本中语句的句法结构以及语句中每个词汇间的依存关系。
针对本文中的缺陷报告,需要提取其中的动宾短语结构,因此,本文对相应的缺陷报告文本使用句法结构分析。本文使用斯坦福自然语言句法解析器(Stanford NLP Parser)对自然语言语句进行句法分析,建立句法结构树。该解析器基于一个经过训练优化的概率上下文无关文法(PCFG)对语句的句法树进行分析构造。
图2分别为缺陷报告(编号239120)描述信息中的语句“I will take a look at this today. Can you tell me what version of AspectJ you are on, is it the release candidate for 1.6.1rc1?”的句法结构示意图。
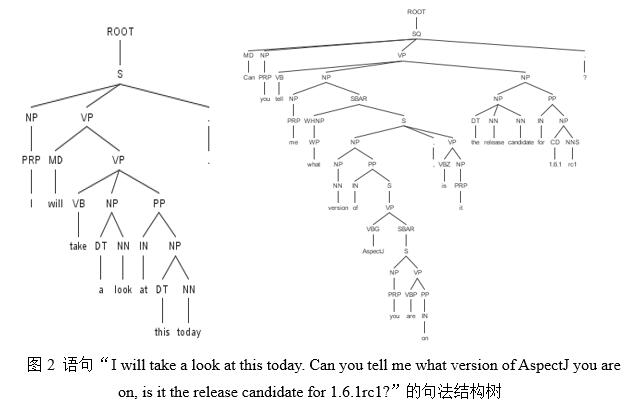
其中,常见标注信息有: S:完整语句;VP:动词性短语;VB.*:不同形式的动词(VB.*表示以 VB 开头的所有标注信息);NP:名词性短语等。句法结构树中动宾短语被标注为VP,因此,需要提取出句法结构树中所有标注为VP的文本片段。

3.2启发式过滤规则
仅仅依靠句法分析中提取出来的动宾短语(VP)文本片段,其中还会保留一部分无关信息。有些动宾短语文本片段由于代词、虚词等成分的词语出现等原因导致该文本片段信息不完整或与该缺陷的实际信息有些偏差。因此,还需要将这种文本片段过滤掉。
本文基于一种启发式规则对筛选出来的候选动宾短语进行过滤[4]。设定某一阈值,并保留通过该启发式规则过滤器后高于该阈值的候选动宾短语。即预先设定一组启发式规则,并对句法分析得到的所有动宾短语文本片段进行筛选。当某个动宾短语片段匹配到某一条规则时,若符合该条规则,则加上既定的分数,同理若不符合该条规则,则减掉既定的分数。当通过所有的启发式规则后,过滤掉所有得分低于阈值的候选动宾短语片段,既而得到缺陷特征的候选集合。本文在[4]的基础上综合考虑缺陷报告文本的特点,最终选取了两类启发式规则:基于短语结构特征的过滤规则,以及基于停止词的过滤规则。
(a)基于短语结构特征的过滤规则
在动宾短语中,如果不包含动词(VB.*)或名词(NP)成分,则将其判定为无效的动宾短语,即为保证该动宾短语描述信息的完整性,候选动宾短语中必须包含动词成分及名词成分。因此,在动宾短语的句法结构树中,如果某一棵子树的根节点第一层中不包含动词成分(VB.*)或名词成分(NP),则将其判定为无效的动宾短语结构,并将该短语的置信度评分设为最低分,结束过滤过程。
(b)基于停用词的过滤规则
在自然语言处理领域,文本预处理中有一种常见操作是删除停用词。停用词是由英文单词stop words翻译过来的。英文中有很多使用频率很高的单词(如a、the、或or)对文本的语义理解并没有帮助,这些单词的存在反而影响计算的效率和准确性,因此通常在处理文本前,会先将文本中的停止词删除掉。
同理,对于缺陷报告的文本集合,有些词在文本的某些位置上也不应该出现,也就是说候选动宾短语中的某些词不应该出现在某些位置上。因此,可以针对缺陷报告集合设定专用的停用词表,当某个候选动宾短语中出现这些停用词时,直接将其移除候选动宾短语集合或减掉一定的分数。本文选用了两种停用词:
助动词(例如be、do、have等)和情态动词(例如can、may、must等)作为句子的基本组成结构,经常出现在动宾短语中,但由于英文特殊的语法结构,当助动词或情态动词出现时,并不是在准确描述该缺陷报告想要描述的缺陷特征。因此,应设定一定规则减少助动词及情态动词对缺陷描述结果的影响。具体规则如下:
1)当助动词或情态动词出现在候选动宾短语的动词位置时,将该短语的置信度评分设为最低分,直接结束过滤过程;
2)当助动词或情态动词出现在候选动宾短语的其他位置时,将该短语的置信度评分减1。
当代词(例如it、me等)出现在候选动宾短语中时,代词在某一单一语句中会因指代不明而使得表达的语意不准确或不完整,因此,应将其作为负面规则减掉一定分数或直接判定为无效的候选动宾短语。另外,若某个代词带有一定的实际意义,其指代的词语也通常在上文出现过,因此,过滤掉该代词所在的候选动宾短语不会影响候选动宾短语集合表述缺陷语义的完整性。具体规则如下:
1)当代词出现在候选动宾短语的名词位置,并且是最后的核心名词时,将该短语的置信度评分设为最低分,直接结束过滤过程;
2)当代词出现在候选动宾短语的名词位置,但不是核心名词时,将该短语的置信度评分减2;
3)当代词出现在候选动宾短语的其他位置时,将该短语的置信度评分减1。
上述语句“I will take a look at this today. Can you tell me what version of AspectJ you are on, is it the release candidate for 1.6.1rc1?”依上述规则筛选后得到两个文本片段,分别为“take a look”以及“release candidate for 1.6.1”。当对该缺陷报告中的所有文本信息提取候选动宾短语并依据以上的启发式规则过滤后,则会得到表述该缺陷报告语义的所有候选动宾短语。
3.3领域术语自动抽取
过滤每份缺陷报告的候选动宾短语集合,得到表征的文本片段后,还需建立每份缺陷报告与类别之间的联系。
在自然语言处理领域,自动抽取语料库中各领域对应的领域术语是其中的一项重要任务。领域术语自动抽取是指从一定规模的语料库中提取出能够表示该语料库中各领域文本特征的词语。目前,针对领域术语的自动抽取已有大量的研究,这些研究大多采用基于统计或基于规则的方法。
本文借鉴Liu等人提供的方法[5],该方法基于以下的假定:
1)不同领域的术语在不同领域的文本中分布应该是不均匀的;
2)相同领域的术语在与其相关领域的文本内应该是均匀分布的。
在给定了分类语料中每个领域的前提下,该算法既考虑了每个领域术语在不同领域文本集合中分布的不均匀性,以及在某些领域文本集合内分布的均匀性。而如果在某个领域内,其语料越多, 则某个词语在该类语料中出现的可能性会越大。因此,该算法使用正规化方法用以减少语料规模对词语的出现带来的影响。算法中的符号定义见表1:

词语在领域类别间的分布,是利用信息熵来定义的,记作corpus distribution(CD),定义如式(1)所示。
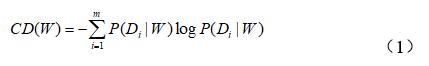
针对语料的不平衡性,对词语的类间分布进行正规化定义,记作NCD,定义如式(2)所示.
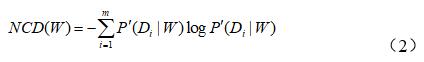
其中:
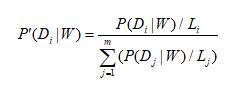
考虑到语料的不平衡性,对词语的类内分布进行正规化定义,记作NDD,定义式(3)所示。
其中
若NCD(W)的值越小,则该文本中的词语W越有可能成为某个或某几个类别的表征术语;而相反的,若NDD(W,Di)的值越大,则词语W越有可能成为用于表征某个类别Di的领域术语。也就是说,式(2)是选择NCD值小的词语作为候选的领域术语,而式(3)则认为领域术语应该在与其相关领域内尽可能均匀的分布。
基于以上方法,可得到缺陷报告集合中每个类别的表征词语,依据NDD值的大小,选择每个类别排名前20的词语。因此,在Eclipse项目的5个优先级类别中,共得到100个表征词语。
对于每份缺陷报告,分别计算这100个表征词语与筛选出的候选动宾短语文本片段中的每个词语的相似度,并取其中的最大值作为特征向量中的某一维,以此得到一个100维的特征向量,如图4所示。与基于白名单构建特征向量的方法类似,对该部分特征向量值也需做归一化处理。
因此,将基于白名单方法得到的特征向量与基于动宾短语提取和领域术语的特征向量拼接在一起,如图5所示。
4 基于LDA主题模型的特征向量构建
主题模型(Topic Model)是一种用于在一组文本集合中查找出抽象主题的统计模型。简单来说,每个文本都有其中心思想,围绕着该中心思想一些特定的词语会更加频繁的出现。主题模型就是统计这组文本中每个词语出现的次数,根据统计信息判断这组文本当中有哪些主题以及每个主题所占的比重是多少。
LDA主题模型是一种非监督的机器学习算法,主要被用于自动生成文档主题,特别是对于文本数量很多的文档数据集合,常用LDA主题模型挖掘数据集中潜在的主题信息。LDA中主题个数的确定是一个比较困难的问题,依经验一般设置为50到500之间。因此,本文基于以上研究经验以及第2节和第3节中得到的两部分特征向量维数,选取100个主题,并将得到的结果与第3节中得到的特征向量(图5所示)拼接在一起,即完整的特征向量如图6所示。
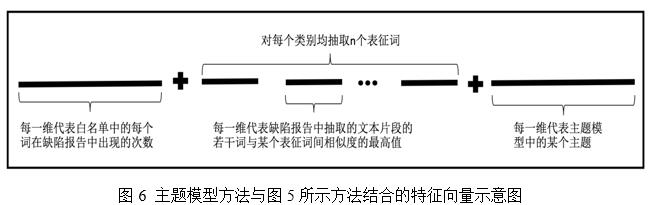
5 基于句法结构的相似缺陷报告识别方法的实验结果与分析
得到每份缺陷报告的特征向量后,基于目前较为成熟的支持向量机、随机森林等机器学习分类算法对缺陷报告分类,计算几种分类算法的准确率并比较几种算法在缺陷报告集合中的适用性。
本文随机选取开源项目Eclipse中的5000份缺陷报告作为实验对象。由于目前没有完备的缺陷报告分类数据集,而缺陷报告的优先级可以看作对缺陷报告的粗分类,因此选用缺陷报告的优先级评估实验结果。
得到每份缺陷报告的特征向量后,对每个类别的缺陷报告,随机选取十分之一,即100份作为测试集,剩余900份缺陷报告作为训练集,并通过K近邻、支持向量机、随机森林、GBDT等机器学习算法实现分类,以探究这几种分类算法在缺陷报告集合中的实用性。
本文对第3节及第4节提出的方法进行了比较,图5及图6分别表示的两种特征向量提取方法的缺陷报告分类准确率如表1所示。其中第一行为基于白名单方法与基于动宾短语提取和领域术语抽取方法结合(图5所示)的实验结果,第二行为白名单方法、基于动宾短语提取和领域术语抽取方法及基于主题模型方法三者结合(图6所示)的实验结果。
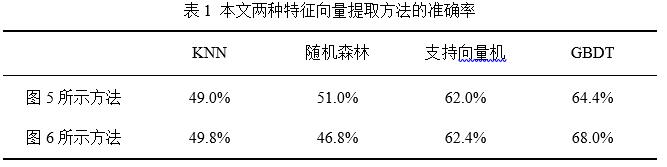
从表1中可以看出,白名单方法、基于动宾短语提取和领域术语抽取方法及基于主题模型方法三者结合的方法(图6所示)的实验效果在KNN、支持向量机及GBDT三种分类算法上略有提升,并且GBDT的提升效果较明显,为3.6%。GBDT作为近年来应用较为广泛的机器学习算法,在缺陷报告分类方面也有较好的实验结果。
目前本文在上述几个模型中均使用默认参数,对实验结果也有一定影响,还需尝试找到更合适的模型参数。另外,更多的算法和模型也有待于研究和尝试。
6 结束语
本文首先介绍了相似缺陷报告集合提取方法的基本流程以及缺陷报告的各部分特征组成。第2节介绍了基于白名单的特征向量构建方法,第3节介绍了基于结构化信息的特征向量构建方法以及基于LDA主题模型的特征向量构建方法,本文将文本信息的结构化信息提取以及基于启发式规则的文本片段筛选方法应用到缺陷报告文本中,并利用领域术语抽取的方法建立缺陷报告与其类别之间的联系。
参考文献
[1] Runeson P, Alexandersson M, Nyholm O. Detection of Duplicate Defect Reports Using Natural Language Processing. Proceedings of 29th International Conference on Software Engineering, 2007, 499-510.
[2] Wang X Y ,Zhang L, Xie T, Anvik J, Sun J. An Approach to Detecting Duplicate Bug Reports Using Natural Language and Execution Information. Proceedings of the 30th International Conference on Software Engineering, 2008, 461-470.
[3] Jalbert N, Weimer W. Automated Duplicate Detection for Bug Tracking System. Proceedings of the International Conference on Dependable Systems and Networks, 2008, 1-10.
[4] 朱子骁,邹艳珍,华晨彦,沈琦,赵俊峰.基于StackOverflow数据的软件功能特征挖掘组织方法.软件学报 ISSN 1000-9825
[5] 刘桃,刘秉权,徐志明,王晓龙.领域术语自动抽取及其在文本分类中的应用.电子学报 2007.
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
