




















ЮЛзЫВЮЪ§БцЪЖЯЕЭГ
1. аїТл
1.1 ЯюФПМђНщ
дкНЈЩшКНЬьЧПЙњЕФЕРТЗЩЯЃЌКНЬьЦїНЋГаЕЃдНРДдНЖрЕФШЮЮёЃЌЮДРДЕФКНЬьЦїЛсИќМгИДдгЃЌдкЙьЗўЮёММЪѕМАПеМфЖдПЙММЪѕОпгаЯджјЕФеНТдМлжЕ[1]ЁЃКНЬьЦїЖЏСІбЇВЮЪ§е§ШЗБцЪЖЪЧЭъГЩШЮЮёЕФживЊБЃеЯЃЌФмЙЛЮЊКНЬьЦїздЩэЬсЙЉЫљашЕФПижЦВЮЪ§ЃЌдіЧПКНЬьЦїздЪЪгІадМАжЧФмад[4]ЁЃФПЧАЃЌВЮЪ§БцЪЖжївЊвРППЪгОѕДЋИаЦїЃЌЪгОѕВтСПОпгаЯЕЭГМђЕЅЁЂГЩБОЕЭЁЂЖдФПБъЮоШХЖЏЁЂЗЧНгДЅЁЂВтСПВЮЪ§ЗсИЛЕШЬиЕу[6]ЃЌФмЙЛЭъГЩДЋЭГНгДЅЪНВтСПЗНЪНЮоЗЈЭъГЩЕФШЮЮё[3]ЁЃЯжгаЕФЛљгкЪгОѕЕФФПБъдЫЖЏВЮЪ§ВтСПММЪѕЃЌжївЊЪЧЖдЭМЯёжаЕФФПБъНјааЬиеїЬсШЁЁЂЭМЯёЪЖБ№МАдЫЖЏбЇДІРэ[2]ЁЃгЩгкЬиеїЕуЛсЗЂЩњЦЏвЦЃЌЕУЕНЕФФПБъдЫЖЏВЮЪ§ОЋЖШМАЪЕЪБадЧЗМбЃЌФбвдТњзуИпОЋЖШЁЂПьЯьгІЕФШЮЮёашЧѓЁЃвђДЫЃЌбаОПКНЬьЦїЮЛзЫВЮЪ§БцЪЖЕФжЧФмЫуЗЈгаЪЕМЪвтвх[5]ЁЃ
БОЮФжМдкЩшМЦЪЕЯжЪгОѕВтСПЧѓНтЕФЮЛзЫВЮЪ§БцЪЖЯЕЭГЃКЃЈ1ЃЉВЩгУЪгОѕВтСПЗНАИЃЌЪЕЯжЗЧНгДЅЁЂЕЭГЩБОЕФЭМЯёВЩМЏЯЕЭГЃЛЃЈ2ЃЉРћгУЩюЖШЩёОЭјТчЬсЙЉИќМгзМШЗЕФЬиеїЕуЬсШЁНсЙћЃЛЃЈ3ЃЉВЩгУPNPЮЛзЫНтЫуЗНЗЈЧѓНтЃЌЕУЕНЮЛзЫВЮЪ§БцЪЖНсЙћЁЃГѕВНЪдбщНсЙћБэУїЃЌИУЮЛзЫВЮЪ§БцЪЖЯЕЭГФмЙЛНЯКУЕФТњзуЪЙгУашЧѓЃЌЕУЕНОЋЖШНЯИпЕФБцЪЖНсЙћЁЃ
1.2 СЂЯюБГОА
дкНЈЩшКНЬьЧПЙњЕФЕРТЗЩЯЃЌКНЬьЦїНЋГаЕЃдНРДдНЖрЕФШЮЮёЃЌЮДРДЕФКНЬьЦїЛсИќМгИДдгЃЌдкЙьЗўЮёММЪѕМАПеМфЖдПЙММЪѕОпгаЯджјЕФеНТдМлжЕЁЃЧБдкЕФОќЪТашЧѓжївЊАќКЌЃКЃЈ1ЃЉЬЋПеРЌЛјЕФЧхРэЁЊЁЊЖдЬЋПеРЌЛјЕФаЮзДГпДчЁЂЮЛжУЁЂЫйЖШЕШдЫЖЏВЮЪ§НјааВтСПЃЌЮЊВЩШЁКЯРэЕФРЌЛјЧхРэЗНАИЬсЙЉЪ§ОнвРОнЃЛЃЈ2ЃЉдкЙьКНЬьЦїЕФЮЌЛЄМАзЅВЖЁЊЁЊЖдФПБъКНЬьЦїЕФдЫЖЏзЫЬЌМАЙьМЃНјааБцЪЖМАдЄВтЃЌБугкНјааВЙГфШМСЯЁЂИќЛЛЙЪеЯФЃПщЁЂИЈжњПижЦЕШВйзїЃЛЃЈ3ЃЉКНЬьЦїЕФдкЙьзАХфЁЊЁЊПеМфеОЕШДѓаЭКНЬьЩшБИФбвдЭЈЙ§вЛДЮЗЂЩфЭъГЩНЈЩшЃЌЖдНгЙ§ГЬжаЕФФПБъЖЈЮЛМАзЫЬЌШЗЖЈЪЧБивЊЕФММЪѕЪжЖЮЁЃвђДЫЃЌЗЩааЦїЮЛзЫВЮЪ§БцЪЖЪЧЭъГЩЩЯЪіШЮЮёЕФЛљДЁЧвЙиМќЕФЛЗНкжЎвЛЁЃ
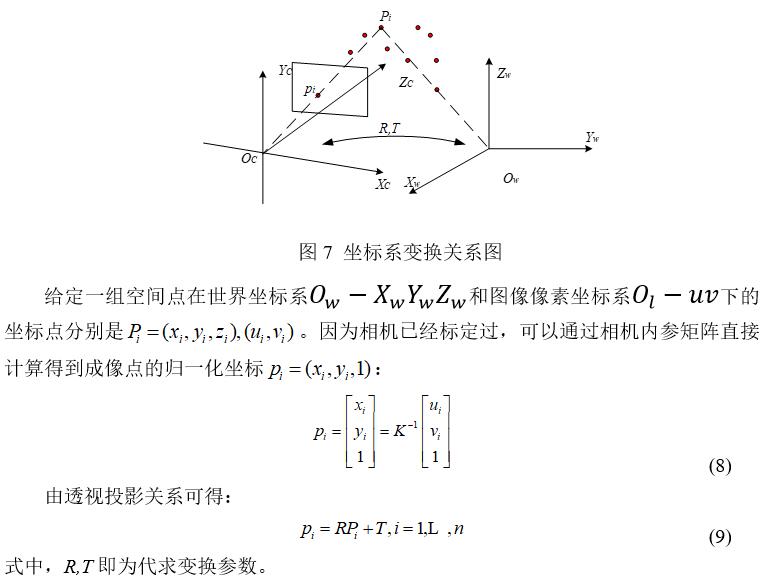
ЪгОѕВтСПОпгаЯЕЭГМђЕЅЁЂГЩБОЕЭЁЂЖдФПБъЮоШХЖЏЁЂЗЧНгДЅЁЂВтСПВЮЪ§ЗсИЛЕШЬиЕуЃЌдкФмЙЛЭъГЩДЋЭГНгДЅЪНВтСПЗНЪНЮоЗЈЭъГЩЕФШЮЮёЃЌЖргУгкПеМфФПБъЁЃЯжгаЕФЛљгкЪгОѕЕФФПБъдЫЖЏВЮЪ§ВтСПММЪѕЃЌжївЊЪЧЭЈЙ§ЪБМфађСаЩЯСЌајХФЩуЭМЦЌЕФЗНЪНЃЌЖдЭМЯёжаЕФФПБъНјааЬиеїЬсШЁЁЂЭМЯёЪЖБ№МАдЫЖЏбЇДІРэЁЃгЩгкЬиеїЕуЛсЗЂЩњЦЏвЦЃЌЕУЕНЕФФПБъдЫЖЏВЮЪ§ОЋЖШМАЪЕЪБадЧЗМбЃЌФбвдТњзуИпОЋЖШЁЂПьЯьгІЕФШЮЮёашЧѓЁЃЫцзХдЫЫуЫйЖШЕФЬсЩ§ЃЌМЦЫуЛњЪгОѕНќФъРДЗЂеЙбИУЭЃЌДѓЙцФЃЕФЪ§ОнМЏКЭГЌЧПЕФМЦЫуФмСІЮЊНсЙћЕФОЋЖШМАПЩааадЬсЙЉСЫБЃеЯЃЌЩюЖШбЇЯАЗНЗЈЕУвдЙуЗКПЊеЙЁЃ
ФПЧАжїСїЕФЪгОѕДЋИаЦїгавдЯТШ§жжЃКЕЅФПЩуЯёЭЗЃЈMonocular CameraЃЉЁЂЫЋФПЩуЯёЭЗЃЈBinocular CameraЃЉЁЂЩюЖШЩуЯёЭЗЃЈRGB-D CameraЃЉЁЃЩюЖШЩуЯёЭЗПЩвджБНгЛёЕУЭМЯёМАЦфЖдгІЕФЩюЖШаХЯЂЃЌЕЋЪЧГЩБОЬЋИпЃЌЬхЛ§НЯДѓЃЌВЛЪЪгУгкЪвФкЛЗОГЁЃЫЋФПЩуЯёЭЗПЩвдЭЈЙ§Ш§НЧЗНЗЈМЦЫуГіЩюЖШаХЯЂЃЌЕЋЪЧЫЋФПЩуЯёЭЗдкФПБъОрРыНЯдЖЪБОЭЛсБфГЩЕЅФПЩуЯёЭЗЁЃЕЅФПЩуЯёЭЗЭЈЙ§СйНќЭМЯёЦЅХфМЦЫуГіЩуЯёЭЗЮЛзЫЕФБфЛЛЃЌдкСНИіЪгНЧЩЯНјааШ§НЧВтОрЕУЕНЖдгІЕуЕФЩюЖШаХЯЂЃЌЭЈЙ§ЕќДњЪЕЯжЖЈЮЛМАНЈЭМЁЃЯрБШЖјбдЃЌЕЅФПЩуЯёЭЗОпгадиКЩЧсЁЂЬхЛ§аЁЁЂСщЛюЕШгХЪЦЃЌБОЯюФПВЩШЁЕЅФПЩуЯёЭЗЗНЪНЁЃ
злЩЯЫљЪіЃЌБОЯюФПНЋбаОПвЛжжЛљгкЕЅФПЩуЯёЭЗЕФЮЛзЫВЮЪ§БцЪЖЯЕЭГЁЃ
1.3 ЙњФкЭтбаОПЯжзД
1.3.1 ЗЩааЦїЮЛзЫВЮЪ§БцЪЖЗНЗЈбаОП
ПеМфШЮЮёЕФФПБъЗЩааЦїжївЊОпгавдЯТЬиадЃКЃЈ1ЃЉЮоЗЈеЦЮеФПБъЗЩааЦїЕФдЫЖЏЙьМЃЃЛЃЈ2ЃЉВЛФмгыФПБъЗЩааЦїНјаааХЯЂНЛЛЛЃЛЃЈ3ЃЉШБЗІФмЙЛИЈжњВтСПЕФЬиеїЛђКЯзїБъжОЁЂЁЃвђДЫЃЌЖдгкПеМфФПБъЃЌЮоЗЈЭЈЙ§ФкжУНгДЅЪНДЋИаЦїНјааВтСПЁЃашвЊЭЈЙ§ЭтжУДЋИаЦїЕФЗНЪННјааВтСПЃЌФПЧАЖдПеМфФПБъдЫЖЏдЫЖЏВЮЪ§ЕФЗЧНгДЅВтСПЗНЗЈжївЊгаЃК
ЃЈ1ЃЉЛљгкМЄЙтГЩЯёРзДяЩЈУшВтСП[1]: МЄЙтРзДягазХВЩбљЦЕТЪИпЁЂВЈЪјеЁЂЙЄзїОрРыГЄЁЂЪмЙтеегАЯьаЁЁЂПЙИЩШХЕШЬиЕуЁЃЛљгкМЄЙтГЩЯёРзДяЕФФПБъВтСПММЪѕбаОПРњЪЗгЦОУЃЌНЯЮЊГЩЪьЃЌЕЋЪЧДцдкЮоЗЈЖдФПБъНјааИпЫйЪЕЪБИњзйЃЌВЛФмЙЛСЌајВтСПЕШЮЪЬтЁЃ
ЃЈ2ЃЉЛљгкЛњЦїЪгОѕВтСП[2]: ЛњЦїЪгОѕВтСПгазХЗЧНгДЅЁЂЬхЛ§аЁЁЂЙІКФЕЭЁЂФмЙЛЬсЙЉИпЗжБцТЪЭМЯёЕШгХЪЦЃЌЪЧЯждкбаОПШЫдБЙуЗКЙизЂЕФЮЪЬтЁЃ
злЩЯЫљЪіЃЌЪгОѕВтСПММЪѕЪЧНќМИФъаТЗЂеЙЕФЗЧНгДЅЪНВтСПММЪѕЃЌдкПеМфФПБъзЅВЖЁЂдкЙьзАХфЁЂЗЩааЦїзЫЬЌВтСПЕШжюЖрСьгђЖМОпгаЗЧГЃЙуРЋЕФгІгУЧАОАКЭЧБдкМлжЕЁЃБОПЮЬтжївЊПЊеЙЛљгкЪгОѕЕФЗЩааЦїдЫЖЏВЮЪ§ВтСПЗНЗЈЁЃ
1.3.2 ЪгОѕВтСПЕФЙиМќЮЪЬтМАбаОПЯжзД
ЮЛзЫВЮЪ§ЪЧПеМфжаЮяЬхдЫЖЏзДЬЌБэеїЕФКЫаФВЮЪ§ЃЌЖдЦфНјаагааЇИпОЋЖШЕФВтСПЖдОќЪТЁЂКНЬьЕШСьгђЖМгажиДѓвтвхЁЃЮЛзЫВтСПЗНЗЈЗжГЩвдЯТШ§РрЃКЃЈ1ЃЉЛљгкФПБъФЃаЭЕФЗНЗЈ[3]ЁЊЁЊЭЈЙ§НЋОжВПЛђШЋВПЬиеїгыЯШбщФЃаЭНјааФЃАхЦЅХфЃЌИУЗНЗЈНтЫуОЋЖШИпЁЂТГАєадКУЃЌЕЋашвЊЯШбщаХЯЂЁЃЃЈ2ЃЉЛљгкШ§ЮЌЕудЦЕФЗНЗЈ[4]ЁЊЁЊЭЈЙ§НЈСЂЗЧКЯзїФПБъБэУцЕФШ§ЮЌЕудЦгывбжЊФПБъШ§ЮЌФЃаЭНјааЕќДњХфзМЃЌИУЗНЗЈОЋЖШИпЕЋЫуЗЈИДдгЁЂМЦЫуСПДѓЁЂЪЕЪБадВюЁЃЃЈ3ЃЉЛљгкФПБъЬиеїЕФЗНЗЈ[5]ЁЊЁЊЭЈЙ§ЖдФПБъЩЯЕФЬиеїНјааЪЖБ№ДгЖјЙРЫуФПБъЮЛзЫЃЌИУЗНЗЈОЋЖШКЭТГАєадНЯВюЃЌЕЋЪЧМЦЫуСПаЁЁЂЪЕЪБадИпЁЃЭЈЙ§бЁдёКЯЪЪЕФЬиеїБэЪОФмЙЛДѓЗљЕФЬсИпОЋЖШКЭТГАєадЃЌЪЧЯждкЕФбаОПжиЕуЁЃ
ЛљгкФПБъЬиеїЕФЪгОѕВтСПЙ§ГЬжївЊПЩвдЗжЮЊФПБъМьВтКЭЮЛзЫНтЫуСНИіВПЗжЃЌФПБъМьВтгУРДЬсШЁБЛВтФПБъЕФМИКЮЬиеїЛђЪЧгявхаХЯЂЃЛЮЛзЫНтЫуИљОнЬсШЁЕНЕФФПБъЬиеїЃЌЭЈЙ§МИКЮБфЛЛЕУЕНБЛВтФПБъЕФЮЛжУМАзЫЬЌаХЯЂЃЌЯТУцНіЖдФПБъМьВтЗНЗЈЕФбаОПЯжзДНјаазлЪіЁЃ
ДЋЭГЕФФПБъМьВтЗНЗЈ[6]ЃЌР§Шч SIFTЁЂHOGКЭDPMЕШЃЌетаЉЗНЗЈПЩвдЭЈЙ§ЯШбщжЊЪЖРДЩшМЦКЯЪЪЕФЪЖБ№ЬиеїЃЌдкЬиЖЈЕФГЁОАЯТЃЌФмЙЛДяЕННЯИпЕФМьВтОЋЖШЃЌВЂЧвЫйЖШНЯПьЁЃЕЋЪЧЃЌгЩгкДЋЭГФПБъМьВтЗНЗЈЬиБ№вРРЕЯШбщжЊЪЖЃЌашвЊЭЈЙ§ЯШбщжЊЪЖЖдгІЩшМЦЪЖБ№ЬиеїЃЌВЛОпБИЪЪгІадКЭЗКЛЏадЁЃ
ЛљгкЩюЖШбЇЯАЕФФПБъМьВтЗНЗЈФмЙЛЭЈЙ§ЪфШыздЪЪгІЕФЬсШЁФПБъЕФЬиеїЃЌПЩвдВЩгУдЄбЕСЗЃЌВЂЧвФмЙЛНЋбЕСЗКУЕФФЃаЭгІгУдкВЛЭЌЕФГЁОАжаЃЌФмЙЛгааЇЬсИпФЃаЭЕФЗКЛЏадЁЃ
ИљОнЗжРрЛиЙщгыЧјгђЬсШЁЪЧЗёЗжПЊЃЌЛљгкЩюЖШбЇЯАЕФФПБъМьВтФЃаЭПЩвдЗжЮЊЛљгкЛиЙщЕФФПБъМьВтФЃаЭКЭЛљгкЧјгђКђбЁЕФФПБъМьВтФЃаЭЁЃ
ЃЈ1ЃЉЛљгкЛиЙщЕФФПБъМьВтФЃаЭ[7]ЃКЛљгкЛиЙщЕФФПБъМьВтЗНЗЈЪЧИљОнЬиеїгГЩфЭМдЄЯШЛЎЗжФЌШЯПђЃЌИљОнФЌШЯПђЖдФПБъНјааЗжРрЃЌЕфаЭЕФЛиЙщФПБъМьВтЗНЗЈгаYOLOЁЂSSDМАЯргІЕФИФНјЫуЗЈЕШЃЌвдЩЯЫуЗЈОљВЩгУЛиЙщЕФЫМЯыЃЌЯШЬсШЁБпНчЕФЛиЙщПђЃЌдйНјааЕќДњЁЃЛљгкЛиЙщЕФФПБъМьВтЫуЗЈЕФгХЕуЪЧМьВтЫйЖШПьЃЌЕЋЪЧМьВтОЋЖШНЯВюЃЛ
ЃЈ2ЃЉЛљгкЧјгђКђбЁЕФФПБъМьВтФЃаЭЃКЛљгкЧјгђКђбЁЕФФПБъМьВтЗНЗЈЪзЯШЪЧЖдЬиеїгГЩфЭМНјааБпНчПђЬсШЁЃЌШЛКѓдйНЋБпНчПђЬсШЁНсЙћгыЬиеїгГЩфЭМвЛЦ№ЪфШыжСИааЫШЄЧјгђЕФГиЛЏВуЃЌЪЕЯжЖдФПБъЗжРрКЭЖЈЮЛЁЃЛљгкЧјгђКђбЁЕФФПБъМьВтЫуЗЈЕФгХЕуЪЧМьВтОЋЖШНЯИпЃЌЕЋЪЧЫйЖШНЯЛиЙщФЃаЭТ§ЁЃ
R-CNN[8]ФЃаЭЪЧНЋЩюЖШбЇЯАЧјгђКђбЁЗНЗЈв§ШыФПБъМьВтШЮЮёЕФПЊДДепЃЌФмЙЛЪЕЯжФПБъЕФздЪЪгІМьВтЁЃдкR-CNNЕФЛљДЁЩЯЃЌSPP-net[9]дкR-CNNжав§ШыСЫПеМфН№зжЫўГиЛЏВуЃЌМьВтОЋЖШгаЫљЬсЩ§ЁЃFast R-CNN[10]дкSPP-netЕФЛљДЁЩЯНјаагХЛЏЃЌМьВтЫйЖШМгПьЁЃFaster R-CNN[11]ЫуЗЈдкFast R-CNNЕФЛљДЁЩЯНјааИФНјЃЌдкЬсШЁКђбЁЧјгђЕФЙ§ГЬжав§ШыСЫЧјгђНЈвщЭјТчЃЌДгЖјЪЕЯжСЫЖЫЖдЖЫЕФбЕСЗЃЌМЋДѓЕиЬсИпСЫКђбЁЧјгђЬсШЁЕФОЋЖШвдМАЭјТчбЕСЗЕФЫйЖШЁЃMask R-CNN[12]ИФНјFaster R-CNNжаЕФИааЫШЄЧјгђГиЛЏВуЮЊИааЫШЄЧјгђЖдЦыЃЌВЂЧвВЩгУЁАЫЋЯпадВхжЕЗЈЁБЃЌгааЇНЕЕЭСЫБпНчЛиЙщПђЕФЮЛжУЮѓВюЁЃДЫЭтЃЌMask R-CNNЫуЗЈЩњГЩСЫбкФЄЃЌФмЙЛЭъГЩЪЕР§ЗжИюШЮЮёЁЃ
1.4 ЯюФПбаОПФкШнМАвтвх
БОПЮЬтжиЕуПЊеЙЛљгкЛњЦїбЇЯАЕФКНЬьЦїЮЛзЫВЮЪ§БцЪЖЫуЗЈбаОПЃЌВЂДюНЈЗТецМАЕиУцЪдбщЯЕЭГеЙПЊбщжЄЃЌЪзЯШЃЌРћгУЯрЛњеѓВЩМЏВЛЭЌНЧЖШЕФФЃФтЮРаЧЕФЭМЯёЃЌЙЙНЈбЕСЗЪ§ОнМЏЃЛЦфДЮЃЌРћгУгявхЗжИюЫуЗЈЛЎЗжФПБъЭМЯёПщЃЌЬсШЁЙиМќЕуЃЌНјЖјНтЫуФПБъЮЛзЫЃЛзюКѓЃЌгыДЋЭГЗНЗЈЕУЕНЕФЮЛзЫНсЙћНјааБШНЯЃЌЗжЮіВтСПОЋЖШЁЃжївЊбаОПФкШнШчЭМ1ЫљЪОЁЃ

дкЖдЯюФПашЧѓКЭбаОПЯжзДЗжЮіЕФЛљДЁЩЯЃЌБОЮФИјГіПЩвЛжжЛљгкЛњЦїбЇЯАЫуЗЈЕФЮЛзЫВЮЪ§жЧФмБцЪЖЯЕЭГЩшМЦЗНАИЁЃжївЊВЩгУЕЅФПЩуЯёЭЗНјааЭМЯёВЩМЏЃЌРћгУЩюЖШЩёОЭјТчНјааЭМЯёЙиМќЕуЬсШЁЃЌРћгУPNPЮЛзЫНтЫуЗНЗЈЕУЕНЮЛзЫВЮЪ§БцЪЖНсЙћЁЃ
1.5 ВЮПМЮФЯз
ГТЗяЃЌжьНрЃЌЙЫЖЌЧчЃЌЭѕгЏЃЌСѕгё. ЛљгкМЄЙтГЩЯёРзДяЕФПеМфЗЧКЯзїФПБъЯрЖдЕМКНММЪѕ[J]. КьЭтгыМЄЙтЙЄГЬЃЌ2016,(10):202-208.
ЭѕчцЃЌГТаЁУЗЃЌКЋаё. ОпгаЭЌаФдВЬиеїЕФЗЧКЯзїФПБъГЌНќОрРызЫЬЌВтСП[J]. ЙтЕчЙЄГЬЃЌ2018,45(8):180-183.
бюбє. ЛљгкФЃаЭЕФЫЋФПЮЛзЫВтСПЗНЗЈбаОПгыЪЕЯж[D]. ЮїАВЕчзгПЦММДѓбЇ:2015,12.
бюЗЋ. ЛљгкЕудЦШкКЯЕФЫЋФПЯпНсЙЙЙтШ§ЮЌВтСПЯЕЭГЕФбаОПгыгІгУ[D]. ЛЊФЯРэЙЄДѓбЇ:2018,4.
гкеМКЃ. УцЯђЗЧКЯзїФПБъЕФЫЋФПЪгОѕдЫЖЏЙРМЦМАШ§ЮЌжиЙЙЗНЗЈбаОП[D]. ЙўЖћБѕЙЄвЕДѓбЇ:2017,6.
ТЌКўДЈЃЌРюХхЯМЃЌЭѕЖА. ФПБъИњзйЫуЗЈзлЪі[J]. ФЃЪНЪЖБ№гыШЫЙЄжЧФм2018, (1) :30-33.
ЛЦНмОќЃЌКєгѕЃЌжмБѓЃЌУїЕТСа. ЛљгкИФНјYOLOЕФЫЋФЃФПБъЪЖБ№ЗНЗЈбаОП[J]. МЦЫуЛњгыЪ§зжЙЄГЬЃЌ2018,4(342):808-811.
Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation[J]. In CVPR, 2014,10,22.
KaimingHeЃЌXiangyu Zhang, Shaoqing Ren, Jian Sun. Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition[J]. In ECCV, 2014.
Ross Girshick. Fast R-CNN[J]. In ICCV, 2015,9,27.
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. In IEEE, 2016,1,6.
Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick. Mask R-CNN[J]. In IEEE, 2018,1,24.
АзБІСж. ЛљгкИФНјЕФMask R-CNNЕФГЕСОЪЖБ№МАМьВт[D]. АВЛеДѓбЇ:2018,4.
Rublee E, Rabaud V, Konolige K, et al. ORB: An efficient alternative to SIFT or SURF[C] IEEE International Conference on Computer Vision. IEEE, 2012:25642571.
ЭѕХєЃЌедКЙЧрЃЌЭѕНЗхЃЌСѕКьБђЃЌГТЮА. ЛљгкЕЅФПЪгОѕЕФЯрЛњЮЛзЫМЦЫу[J]. ЕчзгПЦММЃЌ2017, 12(5):75-78.
2. ЯюФПЗНАИ
ЛљгкЛњЦїбЇЯАЫуЗЈЕФЮЛзЫВЮЪ§БцЪЖЯЕЭГжївЊРћгУЭМЯёДІРэМАВЮЪ§НтЫуЕФЯрЙиРэТлЃЌЪЕЯжЖдЗЧКЯзїКНЬьЦїНјааЬиеїЬсШЁЁЂЬиеїЦЅХфЁЂЮЛзЫНтЫуЕШЃЌбаОПЙЄзїжївЊАќКЌвдЯТШ§ИіЗНУцЃК
ЃЈ1ЃЉЯрЛњВтСПФЃаЭМАЯрЛњБъЖЈЃЌВЩгУЕЅФПЩуЯёЭЗВЩМЏЭМЯёаХЯЂЃЌашвЊПМТЧЕБЧАЕФЛЗОГаХЯЂЃЌЖдЯрЛњНјааВЮЪ§БъЖЈЃЌЕУЕННЯЮЊзМШЗЕФЯрЛњФЃаЭЁЃ
ЃЈ2ЃЉЩюЖШЩёОЭјТчбЕСЗМАЙиМќЕуЬсШЁЃЌЙЙНЈЩюЖШЩёОЭјТчЃЌеыЖдадНјааВЮЪ§бЕСЗЃЌЕУЕНТГАєадНЯКУЕФЭјТчКЭЙиМќЕуЬсШЁНсЙћЁЃ
ЃЈ3ЃЉЮЛзЫВЮЪ§НтЫуЃЌРћгУPNPЮЛзЫВЮЪ§НтЫуЫуЗЈЃЌЪфШыВтСПЕНЕФЬиеїЕузјБъжЕЃЌЕУЕНЯрЖдЮЛжУМАзЊНЧВЮЪ§БцЪЖНсЙћЁЃ
2.1ЭМЯёВЩМЏЯЕЭГЩшМЦ
2.1.1зјБъЯЕЖЈвх

2.1.2 зјБъЯЕзЊЛЛЙиЯЕ

ЃЈ1ЃЉЭМЯёЮяРэзјБъЯЕзЊЛЛЯрЛњзјБъЯЕ
ЯрЛњзјБъЯЕЕНЭМЯёЮяРэзјБъЯЕЪєгкЭИЪгЭЖгАЙиЯЕЃЌЪЙгУеыПзЯрЛњФЃаЭЃЌДг3DзЊЛЛЕН2DЃЌТњзуШ§НЧаЮЯрЫЦдРэЃЌШчЭМ4ЫљЪОЁЃ

ЃЈ2ЃЉЪРНчзјБъЯЕзЊЛЛЭМЯёЯёЫизјБъЯЕ
ИљОнЩЯЪізјБъЯЕЕФБфЛЏЙиЯЕПЩЕУЙЋЪНЃК

2.1.3 ЯрЛњБъЖЈЗНЗЈ
ЯрЛњБъЖЈЗНЗЈгаЃКДЋЭГЯрЛњБъЖЈЗЈЁЂжїЖЏЪгОѕЯрЛњБъЖЈЗНЗЈЁЂЯрЛњздБъЖЈЗЈЁЃ
ДЋЭГЯрЛњБъЖЈЗЈашвЊЪЙгУГпДчвбжЊЕФБъЖЈЮяЃЌЭЈЙ§НЈСЂБъЖЈЮяЩЯзјБъвбжЊЕФЕугыЦфЭМЯёЕужЎМфЕФЖдгІЃЌРћгУвЛЖЈЕФЫуЗЈЛёЕУЯрЛњФЃаЭЕФФкЭтВЮЪ§ЁЃИљОнБъЖЈЮяЕФВЛЭЌПЩЗжЮЊШ§ЮЌБъЖЈЮяКЭЦНУцаЭБъЖЈЮяЁЃШ§ЮЌБъЖЈЮяПЩгЩЕЅЗљЭМЯёНјааБъЖЈЃЌБъЖЈОЋЖШНЯИпЃЌЕЋИпОЋУмШ§ЮЌБъЖЈЮяЕФМгЙЄКЭЮЌЛЄНЯРЇФбЁЃ
ФПЧАГіЯжЕФздБъЖЈЫуЗЈжажївЊЪЧРћгУЯрЛњдЫЖЏЕФдМЪјЁЃЯрЛњЕФдЫЖЏдМЪјЬѕМўЬЋЧПЃЌвђДЫЪЙЕУЦфдкЪЕМЪжаВЂВЛЪЕгУЁЃРћгУГЁОАдМЪјжївЊЪЧРћгУГЁОАжаЕФвЛаЉЦНааЛђепе§НЛЕФаХЯЂЁЃЦфжаПеМфЦНааЯпдкЯрЛњЭМЯёЦНУцЩЯЕФНЛЕуБЛГЦЮЊЯћЪЇЕуЃЌЫќЪЧЩфгАМИКЮжавЛИіЗЧГЃживЊЕФЬиеїЃЌЫљвдКмЖрбЇепбаОПСЫЛљгкЯћЪЇЕуЕФЯрЛњздБъЖЈЗНЗЈЁЃздБъЖЈЗНЗЈСщЛюадЧПЃЌПЩЖдЯрЛњНјаадкЯпЖЈБъЁЃЕЋгЩгкЫќЪЧЛљгкОјЖдЖўДЮЧњЯпЛђЧњУцЕФЗНЗЈЃЌЦфЫуЗЈТГАєадВюЁЃ
ЛљгкжїЖЏЪгОѕЕФЯрЛњБъЖЈЗЈЪЧжИвбжЊЯрЛњЕФФГаЉдЫЖЏаХЯЂЖдЯрЛњНјааБъЖЈЁЃИУЗНЗЈВЛашвЊБъЖЈЮяЃЌЕЋашвЊПижЦЯрЛњзіФГаЉЬиЪтдЫЖЏЃЌРћгУетжждЫЖЏЕФЬиЪтадПЩвдМЦЫуГіЯрЛњФкВПВЮЪ§ЁЃЛљгкжїЖЏЪгОѕЕФЯрЛњБъЖЈЗЈЕФгХЕуЪЧЫуЗЈМђЕЅЃЌЭљЭљФмЙЛЛёЕУЯпадНтЃЌЙЪТГАєадНЯИпЃЌШБЕуЪЧЯЕЭГЕФГЩБОИпЁЂЪЕбщЩшБИАКЙѓЁЂЪЕбщЬѕМўвЊЧѓИпЃЌЖјЧвВЛЪЪКЯгкдЫЖЏВЮЪ§ЮДжЊЛђЮоЗЈПижЦЕФГЁКЯЁЃ
БОЮФжївЊВЩгУеХе§гбБъЖЈЗЈЃЌвЛжжРћгУЦНУцЦхХЬИёНјааЯрЛњБъЖЈЕФЪЕгУЗНЗЈЁЃИУЗНЗЈНщгкЩугАБъЖЈЗЈКЭздБъЖЈЗЈжЎМфЃЌМШПЫЗўСЫЩугАБъЖЈЗЈашвЊЕФИпОЋЖШШ§ЮЌБъЖЈЮяЕФШБЕуЃЌгжНтОіСЫздБъЖЈЗЈТГАєадВюЕФФбЬтЁЃБъЖЈЙ§ГЬНіашЪЙгУвЛИіДђгЁГіРДЕФЦхХЬИёЃЌВЂДгВЛЭЌЗНЯђХФЩуМИзщЭМЦЌМДПЩЃЌШЮКЮШЫЖМПЩвдздМКжЦзїБъЖЈЭМАИЃЌВЛНіЪЕгУСщЛюЗНБуЃЌЖјЧв
2.2ЩюЖШЩёОЭјТчЩшМЦ
БОЮФВЩгУMask R-CNNЭјТчФЃаЭ[8]ЃЌЭјТчНсЙЙЭМШчЭМ5ЫљЪОЁЃ
 .
.
ЪфШывЛеХШЮвтДѓаЁЕФЭМЦЌНјШыMask R-CNNЭјТчКѓЃЌЩюЖШОэЛ§ЭјТчЛсЭъГЩСНИіШЮЮёЃЌвЛЪЧЭЈЙ§Faster R-CNNЕФRPNЭјТчЬєбЁКђбЁЧјгђЃЛЖўЪЧНјааФПБъМьВтВйзїЁЃЯрБШгкFaster R-CNNЫуЗЈЃЌMask R-CNNИФНјжївЊгаСНЕуЃЌЪзЯШЪЧЃЌНЋИааЫШЄЧјгђГиЛЏВуИФГЩСЫИааЫШЄЧјгђЖдЦыВйзїЃЌжївЊЪЧвђЮЊЗжИюЛљгкЯёЫиВйзїЃЌЖјИааЫШЄЧјгђГиЛЏЙ§ГЬжаДцдкЫФЩсЮхШыСПЛЏЃЌЪЙЕУЯёЫиЕФЪфШыКЭЪфГіВЛвЛвЛЖдгІ[9]ЁЃ
ИааЫШЄЧјгђЖдЦыжБНгНЋЬиеїЭМЛЎЗжВЂВЩгУЫЋЯпадВхжЕЃЌФмЙЛБЃжЄГиЛЏЙ§ГЬжаЯёЫидкЧАКѓЪфШыЕФвЛвЛЖдгІЙиЯЕЁЃ
дкЛиДЋЙ§ГЬжаЃЌНјааЗДЯђДЋВЅ[12]ЃЌМћЙЋЪНЃЈ1ЃЉЃК

Mask R-CNNдкFaster R-CNNдгаПђМмЛљДЁЩЯдіМгСЫбкТыЃЌФмЙЛЖдУПИіИааЫШЄЧјгђНјааЪЕР§ЗжИюВйзїЁЃ

дђЃЌЖдгкУПИіИааЫШЄЧјгђПЩвдЕУЕНЕФЦНОљЕУЗжЮЊЙЋЪНЃЈ3ЃЉЃК

Mask R-CNNжївЊЪЧВЩШЁСЫВЂСЊЭјТчВуЃЌНЋжїИЩЭјТчжаЕФЬиеїЬсШЁВугыбкТыВуВЂСЊФмЙЛдіЧПЭјТчЕФЗКЛЏФмСІЁЃВЂЧввђЮЊН№зжЫўЭјТчОпгаКсЯђСЌНгЕФздЖЅЯђЯТНсЙЙЃЌПЩвдЬсШЁВЛЭЌМЖБ№ЕФИааЫШЄЧјгђЬиеїЃЌВЂСЊКѓПЩвдАбИпВуЬиеїДјЕНЕЭВуДЮШЅЃЌЕЭВуДЮМШгагявхгжДцдкЯИНкЁЃ
Mask R-CNNЫуЗЈВНжш[10]ЃК
ЃЈ1ЃЉЪфШывЛЗљД§МьВтЕФЭМЦЌЃЌНјаадЄДІРэВйзїЃЛЛђепжБНгЪфШыдЄДІРэКѓЕФЭМЦЌЃЛ
ЃЈ2ЃЉЪфШыЕНдЄЯШбЕСЗКУЕФЩёОЭјТчжаЛёЕУЖдгІЕФЬиеїЭМЃЛ
ЃЈ3ЃЉЖдЬиеїЭМжаЕФУПвЛИіЕуЩшЖЈдЄЖЈИіаЫШЄЧјгђЃЌДгЖјЛёЕУЖрИіКђбЁаЫШЄЧјгђЃЛ
ЃЈ4ЃЉНЋКђбЁаЫШЄЧјгђЫЭШыЧјгђНЈвщЭјТчНјааЖўжЕЗжРрКЭЛиЙщЃЌЩИЯДВПЗжКђбЁЕФаЫШЄЧјгђЃЛ
ЃЈ5ЃЉЖдЪЃЯТЕФаЫШЄЧјгђНјааЖдЦыВйзїЃЌМДНЋдЭМЕФЬиеїгыЙЬЖЈЕФЬиеїНјааЦЅХфЃЛ
ЃЈ6ЃЉзюКѓЃЌЖдаЫШЄЧјгђНјааЗжРрЁЂЛиЙщЁЂБъЧЉЩњГЩЁЃ
2.3ЮЛзЫНтЫуЯЕЭГЩшМЦ
ЕЅФПЪгОѕЕФЮЛзЫВтСПЪЧИљОнЬиеїЕудкПеМфзјБъЯЕЕФзјБъжЕКЭЦфЭЖгАЕНЯрЛњЩЯЬиеїЕуЃЌгЩЩуЯёЛњЭЖгАФЃаЭЃЌМЦЫуГіПеМфзјБъЯЕЯрЖдгкЩуЯёЛњзјБъЯЕЕФЯрЖдЮЛжУКЭзЫЬЌЁЃ
2.3.1 ПеМфзјБъЧѓНт
РћгУЬиеїЕуЭЖгАЕФЖўЮЌЭМЯёЕуМЦЫуПеМфЕудкЩуЯёЛњзјБъЯЕЯТШ§ЮЌзјБъжЕЃЌПЩвдРћгУШ§НЧаЮЕФгрЯвЖЈРэРДЧѓНтЃЌШчЭМ6ЫљЪОЁЃ

2.3.2 зјБъЯЕБфЛЛЙиЯЕНтЫу
ИљОнПеМфЕудкЩуЯёЛњзјБъЯЕЯТзјБъжЕКЭБъЖЈКУЕФПеМфЕудкПеМфзјБъЯЕЯТзјБъжЕЃЌОЭПЩвдМЦЫуГіПеМфзјБъЯЕКЭЩуЯёЛњзјБъЯЕжЎМфЕФЯрЖдзЫЬЌКЭЯрЖдЮЛжУЃЌШчЭМ7ЫљЪО[14]ЁЃ

3. ЯюФПЪЕЪЉМАГЩЙћ
3.1 ЯрЛњБъЖЈНсЙћ
3.1.1 ЗТецФЃаЭЯрЛњБъЖЈНсЙћ
РћгУgazeboЗТецЛЗОГНЈСЂЯрЛњФЃаЭЃЌдкЦНУцЩЯЗН0.5mЮЛжУДІНЈСЂвЛИіЯрЛњФЃаЭЃЌЯрЛњГЏЯђЯђЯТЃЌЯёЫиЮЊ640*480ЃЌУПИіЯёЫи8ЮЛЃЌдкЦНУцЩЯЗХжУ7*8ЦхХЬИёБъЖЈАхЃЌЃЈЯрЛњФЃаЭШчЭМ8ЫљЪОЃЉЃЌВЂЪЙгУcalibrationБъЖЈЗНЗЈНјааБъЖЈЃЌБъЖЈЙ§ГЬШчЭМ9ЫљЪОЁЃ


3.1.2 ЪЕЮяЩуЯёЭЗБъЖЈНсЙћ
ВЩгУcalibrationЖдЭтжУUSBЕЅФПЩуЯёЭЗНјааБъЖЈЃЌЩуЯёЭЗЪЕЮяЭМШчЭМ10ЫљЪОЁЃЪфШыЭМЯёЯёЫиДѓаЁЮЊ640*480ЃЌБъЖЈЙ§ГЬЭМШчЭМ11ЫљЪОЁЃ


3.2 ЩёОЭјТчбЕСЗНсЙћ
ЮвУЧВЩгУСЫMask R-CNNГЩЪьЭјТчНсЙЙЃЌгІгУдЄбЕСЗШЈжиmask_rcnn_coco.h5ЃЌдкЫќЕФЛљДЁЩЯНјааШЈжиЮЂЕїЃЌдкЗТецЛЗОГжаВЩМЏ50жЁЭМЯёЃЌЖдПеМфФПБъНјааБъзЂЃЌЕќДњ250ДЮЃЌЕУЕНаТЕФШЈжиЃЌНјааМьВтЁЃ

3.3 ЮЛзЫВЮЪ§НтЫуНсЙћ
ЮЛзЫНтЫуСїГЬЭМШчЭМ17ЫљЪОЃЌЪфШыЯрЛњФкВЮОиеѓМАЛћБфЯЕЪ§ЃЌЬсШЁЦЅХфКѓЕФ2DЬиеїЕувдМАЖдгІЕФ3DзјБъжЕЃЌЧѓНтЯрЛњзЫЬЌМЦЫуХЗРНЧМАзјБъжЕЃЌЪфГіЯрЖдЮЛжУМАзЊНЧ[17]ЁЃ


3.4ГѕВНЪЕбщНсЙћ
РћгУДЋЭГЗНЪНКЭЩюЖШбЇЯАСНжжЗНЪННјааЬиеїЕуЦЅХфКЭЮЛзЫНтЫуЃЌШЁЕквЛжЁЭМЯёЩЯЕФзѓЬЋбєЗЋАхзѓЩЯНЧЮЊЪРНчзјБъЯЕдЕуЃЈ0ЃЌ0ЃЌ0ЃЉЃЌВЂвбжЊФЃаЭЭтаЮГпДчЁЃдкШэМўЩЯВйзїЗТецФЃаЭАкГіЯргІзЫЬЌЃЌМЧЮЊРэТлжЕЃЛЗжБ№ВЩгУДЋЭГКЭЩюЖШбЇЯАСНжжЗНЪНЕУЕНЕФЙиМќЕуНјааЮЛзЫНтЫуЃЌЮЛзЫНтЫуНсЙћЭМШчЭМ18-23ЫљЪОЁЃ

ащЯпЪЧРэТлжЕЃЌТЬЩЋЮЊДЋЭГЗНЗЈВтСПжЕЃЌКьЩЋЮЊЩюЖШбЇЯАЗНЗЈВтСПжЕЃЌДЋЭГЗНЗЈКЭЩюЖШбЇЯАСНжжЗНЗЈНтЫуГіЕФЮЛзЫНсЙћгыРэТлжЕЖМДѓжТЮЧКЯЁЃЕЋЪЧДЋЭГЗНЗЈдкЕкЦпжЁГіЯжСЫЛЕЕуЃЌПЩФмДцдкЬиеїЮѓЦЅХфЯжЯѓЃЌЩюЖШбЇЯАЗНЪНднЮДЗЂЯжЮѓЦЅХфЕуЁЃЩюЖШбЇЯАЗНЗЈНЯДЋЭГЗНЗЈгыРэТлжЕЕФВюОрИќаЁЃЌгыРэТлжЕИќМгЮЧКЯЃЌвђДЫПЩвдЕУГіНсТлЃЌдкПеМфФПБъЕФЬиеїЬсШЁКЭЮЛзЫНтЫуШЮЮёЩЯЃЌЩюЖШбЇЯАЗНЗЈБШДЋЭГЗНЗЈдкзМШЗадЗНУцЩЯвЊИќКУвЛаЉЁЃ
4. баОПНсТл
БОЮФжївЊбаОПСЫПеМфФПБъЮЛзЫВЮЪ§ВтСПЮЪЬтЁЃПеМфФПБъОпгаФЃаЭЮДжЊЃЌВЛФмвРППБОЬхДЋИаЦїЃЌВЛФмНјаааХЯЂНЛЛЅЕШЬиЕуЃЌЖдЦфНјааЖЏСІбЇВЮЪ§ВтСПашвЊгІгУЭтВПВтСПЪжЖЮЁЃЛљгкЛњЦїЪгОѕЕФВтСПЗНЗЈОпгаЬхЛ§аЁЁЂЗЧНгДЅЁЂГЩБОЕЭЕШгХЕуЃЌЯждкЪЧПеМфжаЕФжївЊВтСПЗНЪНжЎвЛЁЃБОЮФЛљгкЛњЦїЪгОѕЖдПеМфФПБъНјааСЫЮЛзЫВЮЪ§БцЪЖЃЌВЂНјааСЫЯрЙиЪЕбщМАЖдБШЗжЮіЁЃ
БОЮФЕУЕНЕФжївЊбаОПГЩЙћШчЯТЃК
ЃЈ1ЃЉ ЯрЛњФЃаЭНЈСЂМАЯрЛњБъЖЈ
НщЩмСЫЯрЛњВтСПФЃаЭАќКЌзјБъЯЕЖЈвхЁЂИеЬхБфЛЛВЮЪ§БэЪОЁЂЯрЛњГЩЯёФЃаЭЁЂзјБъЯЕЯрЛЅзЊЛЛЙиЯЕЕШЃЌВЂдкЗТецЛЗОГКЭЪЕЮяЯрЛњЗжБ№НјааСЫЯрЛњБъЖЈЁЃ
ЃЈ2ЃЉЛљгкЩюЖШЩёОЭјТчЕФПеМфФПБъгявхЗжИюМАЙиМќЕуЬсШЁ
ЙЙНЈСЫЩюЖШбЇЯАЗНЗЈНјаагявхЗжИюМАЙиМќЕуЬсШЁЭјТчЃЌРћгУЗТецЛЗОГДюНЈЕФЖЏСІбЇФЃаЭЕУЕНПеМфФПБъЭМЦЌЃЌдкдЄбЕСЗШЈжиЕФЛљДЁЩЯНјааЮЂЕїЃЌЪЙЦфФмЙЛЖдПеМфФПБъНјааЭМЯёгявхЗжИюМАЙиМќЕуЬсШЁЁЃ
ЃЈ3ЃЉПеМфФПБъЮЛзЫНтЫуЫуЗЈ
ЙЙНЈСЫСНжжЮЛзЫЙРМЦЗНЗЈЃКЛљгкДЋЭГЗНЗЈЕФЮЛзЫНтЫуЫуЗЈКЭЛљгкЩюЖШбЇЯАЕФЮЛзЫНтЫуЫуЗЈЁЃЪЕбщНсЙћБэУїЃЌСНжжЗНЪНОљПЩвдЪЕЯжЮЛзЫВЮЪ§ЕФВтСПЃЌДЋЭГЗНЗЈЫйЖШИќПьЃЌЩюЖШбЇЯАЗНЗЈНтЫуОЋЖШИќИпЁЃ
ЗжЯэШУИќЖрШЫПДЕН 
ЭЦМідФЖС
ДЋУНЭЦМі
 @УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад
@УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ
ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
ЯрЙиаТЮХ
- КєКЭКЦЬиЪа5дТ1ШеЦ№е§ЪНЦєгУКєКЭКЦЬи2000зјБъЯЕ
- Ек54ПХББЖЗЕМКНЮРаЧНјШыГЄЦкЙмРэФЃЪН
- СЩФўвдММЪѕЪжЖЮжЮЁАММЪѕВЁЁБ
- ЁАЮЂаХЗЂЫЭдЭМЁБЛсаЙТЖвўЫНТ№ЃП
- АыЕМЬхФкдиКЩзгЬиеїВЮЪ§діжС7Иі
- ЮвЙњПЦбаШЫдБГЩЙІЪЕЯжЖддТЧђБэУцдТГОРлЛ§жЪСПЕФВтСП
- ЪжЛњдѕУДжЊЕРЮвдкФФ ЕМКНЕФдРэФужЊЕРТ№ЃП
- жиЧьЕие№СвЖШЫйБЈгыдЄОЏЙЄГЬНЋдк2022ФъЭъГЩ
- vivo X27ЙйаћЃК3дТ19ШеШ§бЧЗЂВМЃЌцчСњ710ЃЌ8+256G
- РзОќЃКЦкД§аЁУз9ТєЬиБ№БувЫЃЌЭъШЋзіВЛЕН
ПЭЛЇЖЫЯТди
ШЫУёШеБЈЩчИХПі | ЙигкШЫУёЭј | БЈЩчеаЦИ | еаЦИгЂВХ | ЙуИцЗўЮё | КЯзїМгУЫ | ЙЉИхЗўЮё | Ъ§ОнЗўЮё | ЭјеОЩљУї | ЭјеОТЩЪІ | аХЯЂБЃЛЄ | СЊЯЕЮвУЧ
ЗўЮёгЪЯфЃКkf@people.cn ЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-65363263 ОйБЈгЪЯфЃКjubao@people.cn
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170001 | діжЕЕчаХвЕЮёОгЊаэПЩжЄB1-20060139
ЙуВЅЕчЪгНкФПжЦзїОгЊаэПЩжЄЃЈЙуУНЃЉзжЕк172КХ | ЛЅСЊЭјвЉЦЗаХЯЂЗўЮёзЪИёжЄЪщЃЈОЉЃЉ-ЗЧОгЊад-2016-0098
аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0104065 | ЭјТчЮФЛЏОгЊаэПЩжЄ ОЉЭјЮФ[2020]5494-1075КХ | ЭјТчГіАцЗўЮёаэПЩжЄЃЈОЉЃЉзж121КХ | ОЉICPжЄ000006КХ | ОЉЙЋЭјАВБИ11000002000008КХ
ШЫ Уё Эј Ац ШЈ Ыљ га ЃЌЮД О Ъщ Уц Ък ШЈ Нћ жЙ ЪЙ гУ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЦРТл

-
ЙизЂ
ЮЂаХЮЂВЉПьЪж
 ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
 БЈЕРШЋЧђ ДЋВЅжаЙњ
БЈЕРШЋЧђ ДЋВЅжаЙњ
 ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
