




















��ʷͼ�ϵ�PageRank�㷨�����ʵ��
ժҪ�� ��Щ����,���ھ�̬ͼ���о�Խ��Խȫ�桢���룬�Ѿ��γ������Ƶ�������ϵ�����ǣ�������ǵ������е�һЩӦ�����⣬���罻�����в��ϱ仯�Ĺ�ϵ�ȣ�ʹ�þ�̬ͼ��ʾ����ʱ�̶��ڱ仯�Ĺ�ϵ�ƺ��Ե���Щ����������ʷͼ�������Ա�ʾ��̬�仯��PageRank�㷨�����ں�����ҳ��Ҫ�̶ȵ��㷨���������в�������վ�½���ɾ������������������ʷͼ����ʾ�Ե��൱���У�������ǿ�������ʷͼ������CSR(Compressed Sparse Row)�ṹʵ��PageRank,ʹ�ó����ܹ������ڼ���Ŀ��ʱ��ĸ���վ�����֣������ܹ��ṩ��վ���ֵı仯�����������վӰ�������Ƶ�Ԥ�⡣��Wekipedia�ṩ����ҳ�������ӵ�Hyperlink networks���ݼ��Ͻ�����������������ʵ��PageRank�㷨���Ƚϣ������ʾ�����ܴ������ʹ�������ṹ�������������ݹ�ģ��Ŀ��ʱ���ģ�����������ƽ���Խ��Խ���ԡ�
�ؼ��ʣ� PageRank��CSR(Compressed Sparse Row)�ṹ����ʷͼ
1 ����
1.1 ���ⱳ�����о���Ŀ�ĺ�����
�����ʱ��������������Ϣ����չ��һ���εIJ�������ݲ������������ϵĴ����䱳�������Ÿ�����ҵ��������۸��ӵĹ�ϵ���������Ĺ�ϵ�����̺�����ҵ��ֵ����м�ֵ[1]����ͼ����������ʾ��ϵ��һ�ֺܺõ����ݽṹ�����ܹ���Ч��ֱ�۵�������ʵ�����и�������֮��ĸ��ӹ�ϵ�Լ��������ﱾ�������е�һЩ���ʡ�����ʵ�����������ڵĶ�����Գ���Ϊͼ�еĶ��㣬����Ͷ���֮���ij�ֻ��߶��ֹ�ϵ���Գ���Ϊ�����붥��֮��ĵ����߶�߹�ϵ���������罻�����У��û����û�֮��ĺ��ѹ�ϵ�ȡ�
���ڴ�ͳ��ͼ������˵�����Ǿ�̬�ģ�ֻ�ܱ�ʾһ����һʱ�̵����ݡ���������ʵ�����У�����ÿʱÿ�̶��ڱ仯�������弰�������˵����̬ͼע������ʾ��Przytycka������Ϊ��δ���Ĺ����дӾ�̬���������������̬��������DZز����ٵ�[2]��ͬ���������ʱ��ض��ڱ仯�Ļ�������ÿʱÿ�̶���ҳ��IJ��ϼ�����˳������������Ҫһ�����õĽṹ����ʾ���������
1.2 �������ڸ��о��������״
��ͳ��PageRank �Ƽ��㷨��Ҫȫͼ�����������������ʱ�临�Ӷȷdz��ߣ�����Ӱ�����Ƽ���Ч�ʡ��ܾ����������PageRank�Ĺؼ���������������ڵ���ҵ���������˼��[3]��Ϊ�˼����㷨�ĺ�ʱ������ΰ����[4]��PageRank�㷨�ĵ��������м���ɿ��Ƶ��������IJ���b��һ�������������������ֵ����Ȼ�������������Ե������У�ʹ���˹�һ�����ڽӾ��������ֵ�����������������ڵ�֮��ľ��룬�Ӷ��������յ��Ƽ��б������б��еĶ���������������ϸ�Щ������APP������˵����Ȼ���չؼ�������������Ӧ����������ԱȽϸߣ����������β�롣����������[5]��PageRank�㷨���������뱣��ʱ�����ӣ�ʹ�û�����ʱ��Խ�̵� APP ��������ȥ������ʱ�䳤�� APP �ܿ��ٸ���������Francisco Pedroche����[6]���о��У�PageRank����Ϊ�������Ʒ�����1�ף��ľ�ֹ״̬����������ǰ״̬��֪ʶ��ת��ϵͳ��״̬���������á����Ի�����������PageRank����ƫ��ij���ڵ㡣�������ǽ�PageRank�Ͷ�·����������������������Multiplex PageRank��
���ڴ�ͳ�ľ�̬ͼ���Ƶ�������ϵ�ṹ��˵����ʷͼ���ڷ�չ�С����ʱ�����3-5�꣬����������IJ����������꣬Խ��Խ��Ĺ�ע����������ʷͼ��ط�����о���
������[7]�У���ʷͼ������Ϊһϵ�еľ�̬ͼ���С�����������ģ��̬ͼ�Ŀɴ��ѯ�о����٣����д�������ѹ�������Լ�ͼ�ṹ���Ż������⣬�����յ���[8]�����һ��֧�ִ��ģ���ݵĻ��ڸĽ�����������Ŀɴ��ѯ�����������÷������ȶ�Ԥ����ͼ���нṹ�ϵ�����ѹ�����õ�˫ѹ��ͼ����Σ�����˫ѹ��ͼ���һ��ǰlabel�������������ܹ���Ч����ڵ��Ŀɴ��ϵ��������˫ѹ��ͼ���ݽ��Ϳɴ��ѯ�������Ż��㷨������ṹ�仯�Ķ�̬ͼƥ������������ 2009���� Wang �� Chen ��� , ���ǹ����ڽڵ���(NNT)[9]�����˶�ƥ���ѡ�����й���,�Ӷ���Ч���ټ�����ƥ�����IJ����� ��֮��Ĵ������㷨����IncIsoMatch [10]��SJ-Tree[11]��,���Ƕ���ͼƥ���ִ��Ч�ʽ�һ�������ṩ�˲�ͬ����������[12]ָ��������һ������ͼ�������������֮�������һ����Ҫ�����⡣�����������Ƚ��Ļ��ڿռ���ɺͻ��ڶ�����Ҫ�Եķ������ۺϱȽϡ���ʹ�þ��ж����ǧ�������ĸ�����ʵ��·���磬�ֱ���������ּ�����Ԥ����ʱ�䣬�ռ����ĺͲ�ѯЧ�ʣ��Դ����������ּ�����
2 PageRank�㷨

��������������и�С���⡣���Ǵ���ֻ��������������Ľڵ㣬��ô���ڵ���ʱ�����ѭ����ϻ���Ȩ�أ�������������Ȩ�ء���������û�г��ȵ���ҳ���������������ҳ���г��ȡ�
PageRank����������̿��Ա�ʾΪ�㷨һ
�㷨1 PageRank�㷨
���룺 Graph G
����� PageRank Value
1.Initialize:float array PR[]
2.for i=1 up to max_interation do
3. change = 0
4. for node �� G.nodes() do
5. PR(node) = ��_(v��G.nodes)?(PR(v))/Nv
6. PR(node) += (1-c)/N
7. change += |��PR��_old-��PR��_new| /*�ۼƸ��������ֲ�ֵ*/
8. end for
9. if change < threshold then
10. break
11. end if
12. end for
Ȼ��PageRankȴ�����������Ժ�����ԡ����硰ƻ����һ�ζ��ڲ�ͬ������̺���ͬ����˼����˾Ͳ����˸��Ի���PageRank[14]���������е�PageRank[15]���ֲ���Щ���⡣�����PageRank��IF-TDF�������[16]�ܹ������ĵ��������û���ѯ�������Զ��ĵ�����������ͬʱ��PageRankҲ����Ӧ�õ�����ϵͳ[17]�;���ͨ��ϵͳ�� [18] ��
3 ��ʷͼ
��ʷͼ���ݣ��ֿ��Գ�Ϊ��ʱͼ����(temporal graph)����̬ͼ����(dynamic graph)���䶥��ɱ�ʾij��ʵ�����������ҳ��ͨ��˫���ȡ���߿ɱ�ʾΪ����Ĺ�ϵ��ͼ�ı��ߵ��ϴ���ʱ�������ʾ���ߵ���ֻ���ʧ��ʱ�䡣
��ʷͼ�ṹ����ʱ��ı仯���仯���䶯̬����Ҫ����Ϊ��ͱߵIJ�ȷ���ԡ�
��ʷͼ���������������ɣ�ÿ�������Կ���һ����Ԫ��(v1,v2,operation,timestamp)���ֱ��ʾ�ڵ�1���ڵ�2����������(��\��)��ʱ�����һ���㷨�õ�����Ԫ�����ݾ�����˽ṹ��
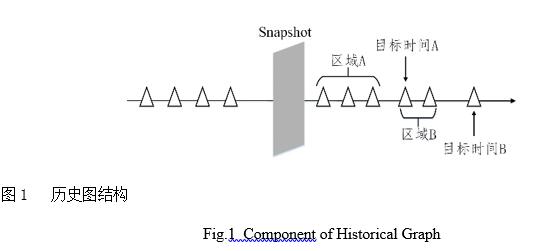
������ʷͼ��صļ���ʱ��Ϊ�˱���Ŀ��ʱ����뿪ʼʱ����������������±���һ�������в��Ŀ���(��ͼ1)�����Ա�ʾ��ʱ�̵�ͼ�ṹ,�����ѯʱ�����snapshot��ʱ�䣬��ô����ֱ�Ӷ�ȡsnapshot�����ݼ��ɻ������ʱ���߰��ʱ��״̬��
4 CSR�ṹ
4.1 �ṹ����
CSR�ṹ��һ�������������ʾͼ���ݵ����ݽṹ��һ�����飨�����飩��¼ÿ������ھ�����һ�����飨�����飩�е�λ�ã�����������ڴ���ھӵı�š���˾Ϳ��Ը������������е����ݻ�ԭͼ�е��������ݡ�
4.2 �ṹ�ص�������
�ڿռ䷽�棬������ÿ��Ԫ�ذ����������֣�һ�������Ǵ洢�����ݣ���һ��������ָ����һ������ַ��ָ�룬������ڱ�ʾͼ��ʱ����Ҫ��ռ��m��ָ������Ҫ�Ŀռ�(m��ʾ�ߵ���Ŀ)����ʹ��CSR�ṹֻ��Ҫm+n��int�͵Ŀռ伴�ɱ�ʾͬ����ͼ(n��ʾ�����Ŀ)����ˣ�CSR�ṹ����ʡ�ռ䡣
��ʱ�䷽�棬���������Ԫ�����ڴ�ռ�����������ţ���������ŵĿռ�����������ģ�Ҳ�����Dz������ģ�����ڱ������ݻ�ȡͼ��Ϣ��ʱ��CSR�ṹ����������졣ͬʱ���ڴ����ߵ�ɾ������ʱ��������Ҫ���в��ҡ�ɾ��������ָ��IJ������ȽϷ�ʱ��
5 ʹ��CSR�ṹʵ��PageRank
5.1 LinkedList Method
ʹ����ֱ�۵�����ά��һ��ͼ����ÿ��delta����������Ǽӱߣ���Ӧ�ĵ�ָ����������������ھӽڵ㣬����Ǽ��ߣ����ڸõ���ھ��������ҵ���Ӧ�ھӣ�ɾ���ڵ���������ˡ���������Ҫ����PageRank��ʱ���ʱ�����ݵ�ǰ��ͼ�����Ի�ȡ����Ҫ��������Ϣ���ڵ���Ŀ����ֹ����Ŀ���ڵ��ھӵȣ���Ȼ�����PageRank�������м��㡣
���㷨2-1�У����Ȼ�ȡ��ʷͼ����Ԫ��v(Line2~3)��������/���������в�ͬ�Ĵ���(Line7~11)���������Ŀ��ʱ����Ŀ��ʱ������в�����ɺ���м���PageRankֵ�IJ���(3~6)
�㷨2-1 ��������
���룺Historical graph data v[4],target time array t[]
����� PageRank Value in every target time
1. while True do
2. reload v /*��ȡ��Ԫ������*/
3. node1,node2,ope,time��v[0],v[1],v[2],v[3]
4. if time is one of target times then
5. calPR() /*����PageRankֵ*/
6. end if
7. if ope=1 then
8. addNode(node1,node2) /*����*/
9. else
10. deleteNode(node1,node2) /*����*/
11. end if
12.end while

5.2 Serial Method
����CSR�ṹ����ֱ�۵��뷨�ǰ���ʱ��˳����м��㡣��ͼ2��ʾ����snapshot������һ��CSR�ṹ��������գ�CSR-A����ͼ2-1����ͬʱ������A������delta��������ڵ������������һ��CSR�ṹ��CSR-B����ͼ2-2�������CSR-A��CSR-B�л��洢����������������PageRankʱ�����ڵ�A����CSR-A�л�ȡ�ھӣ�B��C��D��������PageRank��Ȼ�����CSR-B����������A�IJ��������ĸı䣬���CSR-B��Bָ��A�ı߱�ɾ������˵��֮ǰ���Ƕ��ۼ���һ��ֵ����ô��ʱ���ȥ���ɡ��Դ����������㡣
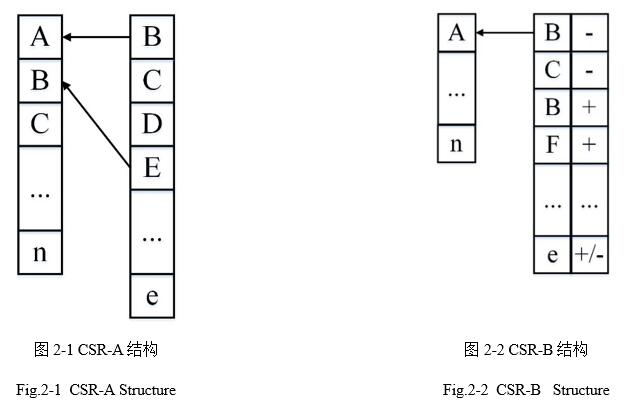
���㷨3-1�������жϲ�ѯʱ���Ƿ�����ʱ�����벿�֣������������ȴ����õ���������CSR-A(Line2~5)��֮�Ͻ�v���ӵ�ope_array��(Line14)�����time��Ŀ��ʱ����ope_array����ָ��ڵ�(node2)��������Ȼ������CSR-B��֮�ɸ���CSR-A��CSR-B����PageRank�ļ��㡣
�㷨3-1 ���Է�PageRank
���룺Historical graph data v[4],half historical graph file h_hg_file,target time array t[]
����� PageRank Value in every target time
1. initialize:int array ope_array[][4] /*��Ԫ������*/
2. if first target time >= half_time then
3. h_hg_file.rdbuf()
4. create CSR-A
5. end if
6. while True do
7. reload v
8. node1,node2,ope,time��v[0],v[1],v[2],v[3]
9. if time is one of target time then
10. sort(ope_array) by node2
11. create CSR-B
12. calPR(CSR-A,CSR-B)
13. end if
14. ope_array.append(v)
15. end while
���㷨3-2�а������㷨2-2һ���ķ�����ʼ��PR[](Line1)��֮��ʼ����������ÿ���㣬�ռ�����CSR-A�е��ھӣ���PageRankֵ�����ۼӡ��ٸ��ݸõ���CSR-B�е���ز�������PRֵ�ĸ��£�Line5~6��������Ǽ��߲�����Ҫ�۳�֮ǰ����ϵ�ֵ��������Ǽӱ߲�����Ҫ���϶�Ӧ��ֵ����ij��PRֵ����һ�ֵIJ�ֵС���趨��ֵʱ����������
�㷨3-2 ��������calPR
���룺CSR-A,CSR-B
����� PageRank Value in the target time
1. initialize:float array PR[]
2. for i=0 up to max_interation do
3. change = 0
4. for node in nodes do
5. accumulate rank in CSR-A
6. update rank according to ope in CSR-B
7. rank += damping_value
8. change += |PR[node] - rank|
9. update PR[node] with rank
10. end for
11. if change < threshold then
12. break
13. end if
14.end for
15.return PR
5.3 Parallel Method
ά��һ���ھӼ�������ʾij������ֹ����ھӣ�ͬʱά��һ��bitset<query_count>�ṹ����ʾÿ��Ŀ��ʱ����ھ��Ƿ���ڣ����������Ҫ��ʾ���бߣ�����Ҫһ������Ϊ�߳���Ԫ��Ϊbitset������bitset<query_count> nei_exist[edge_count]�������ڵڶ���Ŀ��ʱ���У�CSR�ṹ�б�����ĵ�index���ߴ��ڣ���ônei_exist[index][1] = 1����֮��Ϊ0��ͬʱά��������ά����node_exist,�Դ�����¼ÿ��Ŀ��ʱ���нڵ����״̬�ͳ��ȵ���Ϣ�������ڵڶ���Ŀ��ʱ��������ɨһ������֮���֪�����е���Ϣ����ͬ�ļ���ģ��ƾ��ʱ��ȥ����ÿ��������г��ֹ����ھӣ�������ʱ���Ӧ�ı�־λ���Ƿ�Ϊ1��Ϊ1��ʾ���ھӸ�ʱ�̴��ڣ������ڡ�Ȼ��Ϳ��Լ���ÿ�����PageRankֵ���Դ˴ﵽ���е�Ч����
���㷨4-1�У����Ŀ��ʱ�䶼������ǰ�벿�֣���ô����ֻ���snapshot���ݣ�����������Ҫ��ȡȫ������(Line2~5)����Щ�ĵ������ձ�ָ��ڵ��������֮����ݴ���v�еĦ�����������nei_exist��ͬʱ����CSR�ṹ(Line7~12)��֮�����ÿ��target time��nei_exist����Ӧ��״̬����PageRank���м���(Line13)��
�㷨4-1 ���з�PageRank
���룺Historical graph data v[4],target time array t[]
����� PageRank Value in every target time
1. initialize:bitset array nei_exist[]
2. if last target time < half_time then
3. read front part of the historical file
4. else
5. read whole part of the historical file
6. end if
7. while True do
8. reload v
9. node2,node1,ope,time��v[0],v[1],v[2],v[3]
10. update nei_exist
11. Build CSR
12.end while
13.calPR(nei_exist,all target time) in Parallel way
5.4 �㷨�ܽ�
Serial Method��ʹ�õ�CSR�ṹ������������������ʵ�ֵģ�����������洢�������ģ��ռ�ռ��Ҳ����������С������������Ҫ��������ij��ȣ��������䲻���˷ѿռ�Ҳ���������������������е����ݻ���������������Ϲ���CSRǰ��Ҫ���������ݽ�������ʱ�临�Ӷ�ΪO(nlogn),֮�����PageRankֵʱ��������ֻ��Ҫ��CSR�з��ʼ��ɣ�ʱ�临�Ӷ�ΪO(1)��
Parallel Method�н���Ҫɨ��һ�鰴ʱ�估��ָ�����ź�������ݣ�֮���ղ�����������ñ߸�ʱ���Ƿ���ڼ��ɣ��ò���ʱ�临�Ӷ�ΪO(n)��a����ÿ����ƽ�����ڼ���ijʱ��PageRankֵʱ�����CSR�ṹ����ȡ���ݵ�ʱ�临�Ӷȶ�ΪO(1)�����ɼ��㡣
6 ʵ��
6.1 ʵ������
ʵ����������KONECT�����ݼ�¼������ҳ�������ӵ�Hyperlink networks��ʵ���в�ͬ��С�����ݼ���Դ�Ը����ݼ���
���ݼ���ÿ�����ݶ���һ����Ԫ��(v1,v2,+/-,t)����ʾ��tʱ�����ӻ���ɾ��v1ָ��v2�ıߡ�
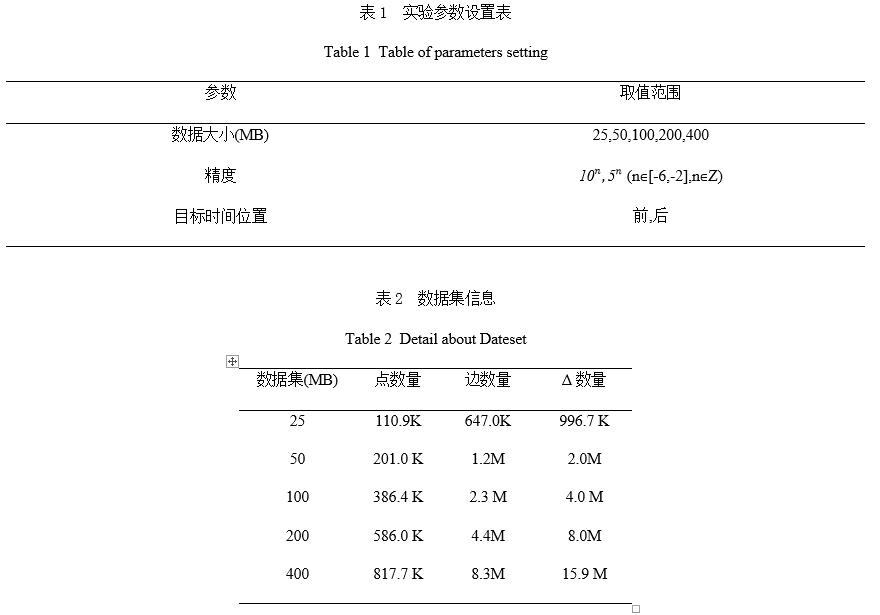
��1չʾ��ʵ����������ã���2չʾ��ÿ�����ݼ���������
ʵ�������»������У�
CPU��16 Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz���ܺ�����8
�ڴ棺231022144 kB��Լ220GB
����ϵͳ��Linux
6.2 ʵ��1��PageRank�����ִ�ʵ��
6.2.1 ʵ��˵��
����֪��PageRankֵ��Ҫͨ����ε������ܴﵽ��������������̽Ѱ��ͬ��С��ͼ�������ִ�֮����ڵ�һЩ��ϵ�Լ�ͬһ�����ݼ��������ִκͼ�����������ֵ֮��ı任��ϵ��
���Ƕ���ÿ�����ݼ��������������ֵ����¼��ͬ��ֵ�µĵ����ִΣ�����ֵΪ���ᣬ�����ִ�Ϊ������ͼ��ʵ������ͼ3-1��ʾ��

6.2.2 ʵ�����
��ͼ�п��Կ�����������ֵ���������ִ�ȫ������Ϊ�½����ƣ�����ֵԽС����������ִ�Խ����ֵԽ����������ִ�ԽС��
���⣬�ձ���˵�����ݼ�Խ������ͬ����ֵ����ĵ�������Խ����Ҳ���ڲ�ͬ���ݼ�����ͬ��ֵ�µ����ִ���ͬ����С�����ݼ������ִδ��ڴ�����ݼ��������
���ǿ��Եó��ձ�Ľ��ۣ���ֵԽ�����ݼ�Խ������ĵ����ִ�Ҳ��Խ��
6.3 ʵ��2������������ܲ���
6.3.1 ʵ��˵��
ʵ��������������������Ų�ѯ������������ĸı䡣���пɱ�IJ���������ѯλ�á���ѯ��ȡ���ѯλ�õ�ǰ��ֱ�����Ų�ѯ������ʱ�����ǰ�벿�ֺͺ�벿�֣�������ʾ����������ֱ��Dz�ѯ���ȷֲ���ʱ����ǰ�벿�ֺͺ�벿�֡�
6.3.2 ʵ������ͼ

6.3.3 ʵ�����
��ͼ3-2���Կ���һ����˵����IJ�ѯʱ�伯���ں�벿�ֵ�ʱ�����ʱ���ȼ�����ǰ�벿�ֵĶ࣬��Ϊ��Ҫ��ȡsnapshot���ݵ�ԭ��
���⣬�������ݴ�С����ѯλ����ʲô����������ʱ���������ѯ��������������ң�����ͼ�е�������������ѯʱ��Ͳ�ѯ�������dz����Թ�ϵ��
����������ʹ����������ʹ��CSR�ṹ�ķ������ʹ�����������ÿ�Щ������LinkedList Method��������������Parallel Method�������ݹ����п���������ʱ�����Ǻ���������Բ��н��У�Ҳ���Ч��������ߡ�
6.4 ʵ��3��������ѯ���ܲ���
6.4.1 ʵ��˵��
֮ǰ�IJ������ڲ�ͬ��ȣ���ͬ��ѯ��������½��в��Եġ������Dz��Ե�ʱ����������ѯ���ܹ��ļ���ʱ�䣬����Ҳֻ�ܵõ�����ÿ����ѯ��ƽ��ʱ�䣬������֪��Щ��ʱ������ϲ�ͬλ�õ���ѯ����ʱ��IJ�ͬ��
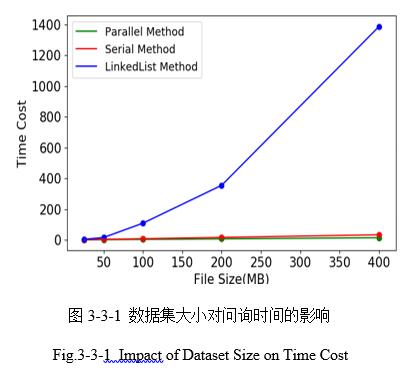
Ϊ�˸���ֱ�۵Ļ�֪���ݼ���С�Ͳ�ѯʱ��Ĺ�ϵ��������Բ�ͬ���ݼ���ֻ��ѯ�����ʱ�������PageRankֵ���Դ����������֮��Ĺ�ϵ��ʵ������ͼ3-3-1��ʾ��
���⣬Ϊ��̽���������̵�ʱ����Ҫ�ķ���ʲô�ط���ʵ��ͳ�������������ڲ�ͬ���ݼ���������ʱ������ʱ��ıȣ���ʱ�����������ʱ��ͼ���ʱ�䣩��ʵ��������ͼ3-3-2��ʾ��

6.4.2 ʵ�����
��ʵ��ͼ3-3-1�п��Կ����������ݼ��IJ�������ʹ����������������ʱ�佫�ἱ�����ӣ���ʹ��CSR�ṹ����������Serial Method��Parallel Method����ֳ�ƽ�ȵ�̬�ƣ��������ܴ������ʹ�������ķ�����
��ʵ��ͼ3-3-2�п��Կ��������������Ĵ�ʱ�䶼�������������ϣ�Ҳ���Ƕ�ͼ�ṹ��ά�������С����������ϣ�LinkedList Method��������ʱ���90%���ң���Serial MethodҲ������75%���ң�Parallel Method����40%���ҡ��ɴ����ǿ��Եó������㲿�ֵ�ʱ�䲢�����ܺ�ʱ�ľ������أ�����ܸ�Ч��ά���������ݲ������Ч�ʵĹؼ���
������
��������ʷͼ�������Ͻ���PageRank�������ؼ��㣬��������ʷͼ�Ļ���������PageRank�Ļ���˼·�����о���Ҫ���˼·ʱ�����ǵ���ʷͼ�ĸ������ʣ���Ƶ����ɾ���ʹ���Ч�ʣ���ʹ�������ṹ�����������Ӵ����������ѯ���ķѵ�ʱ�佫��ܴ��������ʹ��CSR�ṹ��Ϊ��Ҫ�����ݽṹ���ڴ˻����Ͻ�����м���Ͳ��м����˼�������������ͬ�ķ����������������Ǹ��Ե��ص㡣
ʵ�������ʹ��CSR�ṹ�����ʷͼ��PageRank���������ȷʵ������ʹ�������ṹ������Ч�����ԡ�
Ŀǰ���ڵ�������£����ڴ��������ѯParallel Method��Ч�ʵ���Serial Method��Ч�ʡ��ڽ������Ĺ����лῼ��ʹ�÷ֲ�ʽ���ݴ���ϵͳ����Parallel Method����ʵ���Ż���������������Ч�ʡ�
�����
[1]WU J P,LIN S,XU K,et al.Advances in Evolvable New Generation Internet Architecture[J].Chinese Journal of Computer,2012,35(06):1094-1108.
�⽨ƽ,����,��㡵�.���ݽ�����һ����������ϵ�ṹ�о���չ[J].�����ѧ��,2012,35(06):1094-1108.
[2]Przytycka T M, Singh M , Slonim D K.Toward the dynamic interactome:It's about time[J].Briefings in Bioinformatics,2010,11(1):15�C29.
[3]CAO J.Analysis of Google's PageRank techno-
logy[J].Journal of Information,2002(10):15-18.
�ܾ�.Google��PageRank��������[J].�鱨��־2002(10):15-18.
[4]Chang J W,DAI D H.Personalized Recommend-
ation Algorithm Based on PageRank and Spectral Method[J].Computer Science,2018,45(S2):398-401.
����ΰ,��ĵ��.����PageRank�������ĸ��Ի��Ƽ��㷨[J].�������ѧ,2018,45(S2):398-401.
[5]LI C S,LIU X G,JIAO H T et al.An Improved PageRank Algorithm Based on APP Search System[J].Computer and Modernization, 2018(07):24-27+38.
���,��С��,������,�ſɼ�.����APP����ϵͳ��PageRank�Ľ��㷨[J].��������ִ���,2018(07):24-27+38.
[6]Francisco Pedroche,Esther Garc��a,Miguel Romance,et al.On the spectrum of two-layer approach and Multiplex PageRank[J]. Journal of Computational and Applied Mathematics,2018,344.
[7]Harary F,Gupta G.Dynamic graph models[J]. Mathematical and Computer Modelling, 1997, 25(7):79-87.
[8]DING L L,LI Z D,JI W T, et al.Reachability Query of Large Scale Dynamic Graph Based on Improved Huffman Coding[J]. Acta Electronica Sinica,2017,45(02):359-367.
������,������,������,�α���.���ڸĽ�����������Ĵ��ģ��̬ͼ�ɴ��ѯ����[J].����ѧ��2017,45(02):359-367.
[9]WANG C,CHEN L.Continuous Subgraph Pattern Search over Graph Streams[C]// International Conference on Data Engineering. IEEE, 2009.
[10] FAN W , LI J , LUO J , et al.Incremental graph pattern matching[C]//Acm Sigmod International Conference on Management of Data. ACM, 2011.
[11]Choudhury S, Holder L, Chin G, et al.Proc. of the Workshop on Dynamic Networks Management and Mining[C]// International Conference on Management of Data. SIGMOD/PODS'13, 2013.
[12]WU L K,XIAO X K,DENG D X, et al.Shortest Path and Distance Queries on Road Networks:An Experimental Evaluation[J].Proceeding of the VLDB Endowment, 2012,5(5):406-417.
[13] Page L,Brin S,Motwani R,et al. The PageRank Citation Ranking: Bringing Order to the Web[J]. Stanford Digital Libraries Working Paper,1998, 9(1):1-14.
[14]WEI Z W,HE X D,X X K,et al. TopPPR: Top-k Personalized PageRank Queries with Precision Guarantees on Large Graphs[C].// International Conference on Management of Data.SIGMOD,2018.
[15]HAVELIWALA,T.H .Topic-sensitive pagerank: A context-sensitive ranking algorithm for web search[J]. IEEE Transactions on Knowledge and Data Engineering, 2003, 15(4):784-796.
[16] ROUL R.K., SAHOO J.K., ARORA K. Query-Optimized PageRank: A Novel Approach[M]. Computational Intelligence in Data Mining. Advances in Intelligent Systems and Computing. Singapore:Springer,2019:673-683
[17]LI C C,KANG Z J,YU H G, et al. Identification Method of Key Nodes in Power System Based on Improved PageRank Algorithm[J]. Transactions of China Electrotechnical Society,2019,34(09):168-175.
�����, ���ҽ�, �ں��, et al. ����PageRank�Ľ��㷨�ĵ���ϵͳ�ؼ��ڵ�ʶ��[J].�繤����ѧ��, 2019, 34(09):168-175.
[18]LIU Z Y,LI Q F,CENG C, et al.An Optimization Method of PageRank Based on Spark and its Application Research[J].Journal of CAEIT, 2018(4):399-405.
������, ���ո�, ����, et al.����Spark��PageRank�㷨�Ż��������Ӧ���о�[J]. �й����ӿ�ѧ�о�Ժѧ��, 2018(4):399-405
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
