




















基於深度學習的新聞圖像情感識別模型的設計與實現
【摘 要】現代媒體中,圖片在新聞傳播過程中發揮了越來越重要作用,隨著受眾視覺媒介依賴程度的提高,基於圖像高級語義的組織分類成為現在迫切需要解決的問題。雖然每個人文化背景、評判標准都存在著個體主觀差異,但整體方向存在相似性,能夠准確分析新聞圖像的情感語義對於提升圖片與文字報道情感色彩的符合度以及避免圖文相悖的報道對大眾產生情感誘導具有重要意義。
圖像情感識別准確率依賴於圖像識別技術,本文對圖像識別中經常會使用到經典的模式進行了概述,詳細介紹了日趨重要的基於人工神經網絡的深度學習算法,重點探究了深度學習在圖像識別領域的一個重要網絡模型——卷積神經網絡(Convolutional Neural Network,CNN)。並提出了一種基於CNN的圖像情感識別方法,該方法分為兩個步驟:圖像數據預處理和模型訓練,採用該模型進行圖像情感識別能夠獲取較高准確率。為了進一步驗証模型准確率並對新聞圖像情感進行分析,本文運用網絡爬虫技術,隨機獲取了150篇含有圖片的新聞報道及其閱讀量進行分析對比。
實驗結果表明機器識別與大多數人為感知大致吻合,但是也可以看到目前新聞報道中圖片情感與文字情感符合度較低。由此可知,新聞圖片選取時可能更重視圖片內容本身,而忽略了圖片情感語義與報道本身所要表達的情感是否相符。同時,通過對閱讀量的粗略分析可知,新聞圖片情感與文字報道情感吻合度與新聞報道的閱讀量正相關。本文所提出的算法可用於人民網新聞圖片的選取,用以提高圖片與文字的情感吻合度,加強讀者對新聞整體的接受感。
【關鍵詞】卷積神經網絡(CNN)﹔圖像情感識別﹔新聞圖像
第一章 概述
1.1 圖像識別
圖像識別是按照所觀測到的圖像,通過計算機對圖像自動進行處理、分析,理解圖像的內容,以達到分類識別不同模式的目標和對象的效果。隨著計算機計算能力的大幅提高和大數據時代的來臨,圖像識別技術正向著高級語義理解方向發展。
通常情況下,一個圖像識別系統由三個部分組成:圖像預處理、特征提取、分類器的識別[1]。其中圖像預處理是為了減小圖像對識別的干擾並提高后續算法效率,常見的預處理包括降噪、圖像增強、分辨率歸一化、顏色矯正等﹔特征提取是提取能夠代表圖像類別的特征,是圖像識別中至關重要的步驟,直接影響識別性能的好壞,在一幅圖像的眾多特征中,需要提取區分能力強且可以抗干擾的特征,常用的特征有顏色特征、形狀特征、紋理特征、能夠穩定出現並具有良好區分點的局部特征信息(SIFT、HOG、LBP、MSER等)以及它們的組合﹔分類器的識別則是按照圖像特征所提取的結果進行分類。
1.2 圖像情感識別
近年來,隨著計算機網絡技術和數字媒體處理技術的發展,圖像數據量越來越龐大。基於圖像識別的多領域融合已成為研究熱點。考慮到人們對所看的圖像所產生的主觀情緒,本文提出圖像情感識別。雖然由於文化背景等差異,每個人對視聽覺媒體的評判標准和感官存在著差異,特別是對媒體情感語義的理解。但對於圖像的情感表現又有群體相似性。因此,如果能夠准確分析圖像的情感語義對於相關領域的發展具有重要意義。
目前圖像識別技術試圖用圖像的視覺特征來代表圖像,同時也包含圖像自身包含的情感信息,但這部分特征往往被忽略。研究表明圖像情感識別是一種重要的識別內容,它可以被認為是圖像中蘊含的能引起人類某種情感反應的信息[2]。基於機器學習的方法用圖像視覺特征識別個性化情感內容,來彌合視覺低層特征和人類情感高層語義之間的語義鴻溝。
近些年與圖像情感分析相關工作的有圖像受喜愛度分類(affection)[18]或情緒(emotions)分類[19]。Machajdik等人根據心理學和美學理論設計出較為細致的底層特征組合,這些特征更能代表圖像的情感內容,具體顏色特征、紋理特征、復雜度、景深、三分構圖法、動力學等圖像結構特征,還有人臉和膚色的圖像內容特征。最終在International Affective Picture System(IAPS)數據集上訓練分類器,將圖像分為快樂(Amusement)、生氣(Anger)、敬畏(Awe)、滿足(Contentment)、惡心(Disgust)、興奮(Excitement)、恐懼(Fear)、悲傷(Sad)八個情緒類別。
第二章 圖像識別技術
圖像情感識別是圖像識別的一個方向是將圖片根據人類情感進行分類,屬於模式識別的范疇[1]。模式識別是人類的一種基本認知能力,是人類智能的重要組成部分,幾乎每個人都會在不經意間輕而易舉地完成模式識別的過程。通過視覺信息識別文字、圖片和周圍的環境,通過聽覺信息識別與理解語言等,在各種人類活動中都有著重要作用。但如果要讓機器做同樣的事情,決非這麼輕鬆。
在對圖像進行分類的過程中,其經常會使用到經典的模式進行識別,如:模板匹配模式識別、模糊模式識別、支持向量機的模式識別,以及目前越來越受到重視的基於人工神經網絡的深度學習技術。
2.1 模板匹配模式識別
模板匹配是一項在圖像識別領域非常重要的識別技術,這種方法的優點在於匹配算法較為簡單,但計算量大,在圖像變化不大的情況下識別率較高。模板匹配的原理是選擇已知的對象作為模板,通過相關函數計算來找到它和被搜索圖的坐標位置,與圖像中選擇的區域進行比較,從而識別目標[4]。
模板匹配主要應用於對圖像中對象物位置的檢測,運動物體的跟蹤,不同光譜或者不同攝影時間所得的圖像之間位置的配准等[3]。但如果圖像和模板大到一定程度,就會導致計算機無法處理,也就失去了圖像識別的意義。模板匹配的另一個缺點是光線變化能引起圖像顏色值的漂移,盡管漂移沒有改變顏色直方圖的形狀,但漂移引起了顏色值位置的變化,從而可能導致匹配策略失效。
2.2 模糊模式識別
模糊模式識別是以模糊理論和模糊集合數學為支撐的一種識別方法。它根據人辨識事物的思維邏輯,吸取人腦的識別特點,將計算機中常用的二值邏輯轉向連續邏輯。模糊識別的結果是用被識別對象隸屬於某一類別的程度即隸屬度來表示的,一個對象可以在某種程度上屬於某一類別[3]。基於模糊集理論的識別方法有:最大隸屬原則識別法、擇近原則識別法和模糊聚類法。
採用模糊推理的方法,用隸屬函數作為樣本和模板的度量,能反映模式的整體特征,針對樣品中的干擾和畸變,有很強的剔除能力。但模糊規則往往是根據經驗得出,准確合理的隸屬函數往往難以建立,因此限制了它的應用。
2.3 支持向量機的模式識別
支持向量機(Support Vector Machine,SVM) 是由Vapnik領導的AT&Bell 實驗室研究小組在1963 年提出的一種非常有潛力的分類技術[3],其基本思想是:先在樣本空間或特征空間,構造出最優超平面,使得超平面與不同類樣本集之間的距離最大,從而達到最大的泛化能力[6]。支持向量機結構簡單,並且具有全局最優性和較好的泛化能力,自提出以來得到了廣泛的研究。
支持向量機方法是求解模式識別和函數估計問題的有效工具。SVM能夠尋找圖像像素之間的特征的差別,即從像素點本身的特征和周圍的環境(臨近的像素點)出發,尋找差異,然后將各類像素點區分出來。用支持向量機的方法處理一些二值圖像和灰度圖像,能獲得較好的統計結果[6]。
2.4 人工神經網絡
人工神經網絡(Artificial Neural Network,即ANN)是人類在對其大腦及大腦神經網絡認識理解的基礎上,人工構造的模擬人腦及其活動並能夠實現某種功能的理論化數學模型。人工神經網絡區別於其他識別方法的最大特點是它對待識別的對象不要求有太多的分析與了解,具有一定的智能化處理的特點[3]。神經網絡具有大規模並行、分布式存儲和處理、自組織、自適應和自學習的能力,特別適用於處理需要同時考慮許多因索和條件的、不精確和模糊的信息處理問題,因此它在圖像識別領域應用廣泛[7]。
2.5 深度學習
深度學習通過深度神經網絡實現,相較於傳統信息提取過程,深度學習的層次特征是一種由數據驅動的特征學習過程,該過程需要大量的數據來進行學習。大數據時代的來臨正可以解決數據的來源問題[8]。因此,深度學習技術已經成為目前圖像識別最為火熱的領域之一。
深度學習在圖像特征的分層提取中,低層可以提取到一些邊緣紋理信息,中間層可以在邊緣信息的基礎上學習到部分區域特征,高層實現識別目標的語義信息[9]。通過深度學習,可以使用高級語義特征來實現對目標的識別,在物體分類、識別、檢測等應用中具有明顯優勢。
2.5.1 卷積神經網絡
卷積神經網絡( CNN) 是一種前饋神經網絡,是深度學習中處理數據非常著名的算法。卷積神經網絡也被多數研究人員認為在圖像識別領域有突出的優勢。
卷積神經網絡對圖像的層級特征提取,主要通過卷積層后接下採樣層這種循環結構來實現的[10]。通過卷積核和共享權值應用使卷積神經網絡需要處理的數據量大幅減少,下採樣層在一定程度上對輸入的小型變化具有特征不變性,可以使特征更加的魯棒。每一個卷積層后加上下採樣層作為一個基本單元,提取圖像特征,下一次這種單元將對已提取的特征進行更高級特征的提取。
2.5.2 卷積神經網絡的發展
卷積神經網絡可感知圖像的局部特征,並對局部特征進行綜合得到全局特征,在對大型圖像進行分類時表現出色[11],這在ImageNet ILSVRC 圖像分類任務挑戰中有很好的體現。
2012年Hinton 的研究小組利用卷積神經網絡將該測試集上的錯誤率由傳統方法的26.172%大幅降到15.315%。與傳統網絡相比,它有採用了dropout 的訓練策略,並使用整流線型單元作為非線性的激發函數,這不僅大大降低了計算的復雜度,而且各種干擾更加魯棒。2014年深度學習又取得了重要進展, GooLeNet將top5 錯誤率降到6.656%。它大大增加了卷積網絡的深度,超過20 層,這在之前是不可想象的。很深的網絡結構給預測誤差的反向傳播帶了困難。GooLeNet 採取的策略是將監督信號直接加到多個中間層,這意味著中間和低層的特征表示也需要能夠准確對訓練數據分類。
2.6 本章小結
本章對圖像識別技術發展進行綜述,以時間為線索的重要節點有:Vapnik等人於1995年在統計學習理論的基礎上提出了支持向量機(SVM),它根據有限的樣本信息在模型的復雜性和學習能力之間尋求最佳折衷,具有較好的泛化能力﹔神經網絡一派的大師Hinton等人於2006年提出了神經網絡的Deep Learning算法,使神經網絡的能力大大提高,為圖像識別的發展提供了新的思路,機器通過無監督學習自動識別圖像特征﹔2012年在ImageNet ILSVRC挑戰中卷積神經網絡取得優異成績,目前基於卷積神經網絡的圖像識別技術應用最為廣泛。
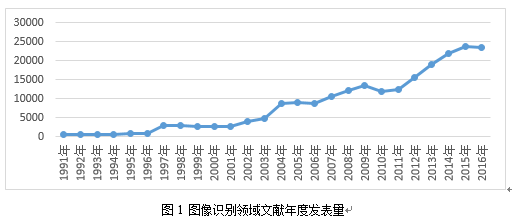
圖1為Web of Science數據庫中圖像識別領域文獻年度發表量,文獻年度發表量在1997年、2004年、2007年-2009年、2012年-2015年有迅猛增長,與前文所述新技術的提出時間相吻合,從這個角度也可以反映出技術的每次發展都會引起圖像識別領域研究的高潮。
 |
分享讓更多人看到 
推薦閱讀
傳媒推薦
 @媒體人,新聞報道別任性
@媒體人,新聞報道別任性 網站運營者 這些"紅線"不能踩!
網站運營者 這些"紅線"不能踩! 一圖縱覽中國網絡視聽行業
一圖縱覽中國網絡視聽行業
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
