




















基於用戶畫像與新聞詞向量的個性化新聞推薦模型【2】
4.1 基於指數衰減模型的詞向量訓練框架
指數衰減模型的CBOW+Hierarchical Softmax訓練框架根據上下文詞與目標詞之間詞的數量來構造指數衰減模型的權重因子,此時投影層為 中所有詞向量的疊加,其公式為


4.2 新聞向量特征融合
對於新聞文本而言,特征提取方法主要是在整個文檔集中進行選擇,包括TF-IDF,信息增益等特征,其忽略了不同領域以及同領域之間的特征詞的分布情況[9]。往往不能有效的選擇出具有較好區分能力的特征,難以發現用戶對新聞的潛在偏好。
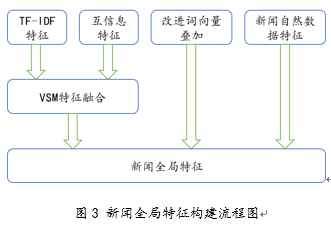
本模型採用新聞特征詞的向量空間模型特征與詞向量疊加相融合的特征,並將新聞的額外信息,包括發布時間,點擊次數等信息,共同形成對應新聞的融合特征。
對於向量空間模型特征,本模型主要採用TF-IDF以及互信息特征。雖然TF-IDF簡單快速,結果比較符合實際情況,但是單純以"詞頻"衡量一個詞的重要性,不夠全面,有時重要的詞可能出現次數並不多。而且,這種特征無法體現詞的位置信息,同時未能考慮特征項在新聞領域間和領域內的情況。然而,互信息作為特征詞和類別之問的測度,如果特征詞屬於該類的話,它們的互信息量最大。由於該方法不需要對特征詞和類別之問關系的性質作任何假設,因此非常適合於文本分類任務。對於每一領域來講,特征的互信息越大,說明它與該領域的共現概率越大,因此,以互信息作為提取特征的評價時應選互信息最大的若干個特征。將互信息與TF-IDF特征相結合,彌補了TF-IDF未考慮新聞領域間和領域內的問題,能夠有效的對新聞進行表達和特征提取。
本文採用基於指數衰減模型的詞向量訓練框架對新聞語料庫進行訓練,在對新聞進行分詞並去掉停用詞之后,可以得到表示新聞的特征詞詞向量集合。在使用詞向量集合表示方面,如果將特征詞詞向量首尾相接作為新聞文本特征向量,此時向量的維度等於特征個數與詞向量維度的乘積。由於每個詞的詞向量維度普遍在100~300之間,若新聞特征詞選擇較少,無法對新聞進行有效的表示,選擇較多則會造成詞向量維度災難,文本特征維度過高、增加計算資源開銷。因此,本文選擇將所有特征詞詞向量進行疊加,從而獲得新聞表示的詞向量特征。
對於新聞其他屬性,例如瀏覽數、熱度、評論人數等等,在融合向量空間模型和詞向量特征時,同時將其與融合特征首尾連接構造成能夠表達新聞內容與自然特征的全局特征,從而對新聞進行有效的表達。
5、分類算法
在得到用戶畫像特征和新聞全局特征后,模型可以採用高效並行的分類算法對用戶的行為進行預測,例如深度森林(gcForest)、Xgboost等。
深度森林是一種全新的決策樹集成算法,使用級聯結構讓深度森林來做表征學習[6]。通過對比分析,gcForest使用相同的參數設置,在不同的領域中都獲得了突出的效果,並且無論是大規模還是小規模的數據,都能得到很好的泛化。此外,相對於神經網絡,gcForest整體是基於樹的結構,更加容易分析和解釋。
XGBoost在基於梯度提升的框架下,其對目標函數進行二階泰勒展開,使用了二階導數加快了模型收斂速度,並使用正則化的目標函數,控制模型的復雜度。不僅如此,XGBoost算法借鑒了隨機森林的做法,支持列抽樣,不僅能降低過擬合,還能減少計算,同時在進行完一次迭代后,會將葉子節點的權重乘上縮減系數,削弱每棵樹的影響,讓后續迭代有更大的學習空間。
這兩種分類算法都是基於樹的算法,都能夠有效的實現並行化,在保証模型效果的基礎上,提升學習速率。
分類算法在預測某一用戶對眾多新聞的點擊概率后,通過Softmax歸一化方法進行處理,獲得用戶點擊概率較高的新聞,並推薦給用戶。
6、總結
本文就目前推薦模型中存在的用戶行為數據的高維稀疏特點、新聞文本特征相似性衡量兩方面,從分類的角度考慮用戶對新聞的行文,提出一種融合用戶畫像和內容詞向量特征的個性化新聞推薦模型,通過構建用戶畫像模型,挖掘用戶的潛在偏好,並使用指數衰減模型的Word2Vec算法進行詞向量訓練,結合向量空間模型特征對新聞進行表示,並採用基於樹的集成算法進行預測評估,獲取用戶可能點擊閱讀的新聞,將其推薦給用戶。
本文提出的模型有效的避免了對高維稀疏的用戶行為數據進行相似性衡量,並採取融合特征對新聞全局特征進行表示,能夠較好的區別新聞之間的差異,挖掘用戶的潛在新聞偏好,提高推薦效果,可廣泛應用於新聞門戶推薦網站,例如人民網、網易新聞等。
 |
分享讓更多人看到 
推薦閱讀
傳媒推薦
 @媒體人,新聞報道別任性
@媒體人,新聞報道別任性 網站運營者 這些"紅線"不能踩!
網站運營者 這些"紅線"不能踩! 一圖縱覽中國網絡視聽行業
一圖縱覽中國網絡視聽行業
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
