




















互聯網新聞標題生成方法研究
摘要:
近年來,網絡新聞的“震驚體”文不對題現象層出不窮,為保証更加高效准確的信息檢索及用戶體驗,本文探討圖結構、編解碼器、注意力機制下編解碼器以及指針生成器四種方法應用於新聞標題生成任務中的可行性。指針生成器模型根據原文詞先驗分布抽取及高維語義信息生成兩種方式聯合所生成的新聞標題在語義上較為完整,表達較為准確。
關鍵詞:“震驚體”,自然語言生成、新聞標題、編解碼器
一、引言
隨著web2.0的快速發展,以人民網、微信、微博為代表的新興媒體加速崛起。此前,國家新聞出版廣電總局印發的《關於進一步加快廣播電視媒體與新興媒體融合發展的意見》提出要大力推廣傳統廣電媒體與新興互聯網媒體深度融合、一體共生。在這樣的時代背景和政策導向引導下,人們發布和獲取新聞內容的途徑發生了天翻地覆的變化,逐漸由傳統媒體轉向網絡新興媒體。同時大量的新興媒體的普及也引發了互聯網媒體上的新聞內容爆炸式增長。
人民網作為世界十大報紙之一《人民日報》建設的以新聞為主的大型網上信息發布平台,每日收稿量巨大。然而,這些稿件新聞內容質量良莠不齊,其中不乏一些選取華麗標題卻缺乏實質內容的“標題黨”文章浪費了審稿人員大量的時間精力,如何快速的獲取文章的真實主旨成為了審稿人員的重要能力。除了人工的加強審稿能力外,人工智能技術,尤其是自然語言處理技術將極大的助力新聞主旨檢索。本文討論通過標題再生成的方法,生成最貼切新聞文章內容的新聞標題,未來希望通過此方法來減少人工排查“標題黨”的時間。
目前的新聞檢索大多採用搜索引擎加關鍵字權重的方法,忽略了文章的內涵。因此,如何根據新聞內容生成言簡意賅的新聞標題是一項具有挑戰性的研究課題。近年來,隨著國內外學者在自然語言處理領域的不斷深入研究,相關理論體系和實作方法論的不斷進步,使得對文本的智能理解和挖掘技術愈加成熟。文本摘要就是一類運用自然語義處理方法,幫助機器理解冗長自然語言文本內容,並生成一些簡短、精煉高度概括文本內涵的句子的技術。除了直接呈現文本摘要結果給用戶閱讀外,文本摘要技術還在很多下游任務中充當著重要角色,如長文本情感分析、搜索引擎、推薦系統等。相比於直接使用原文,使用好的摘要能夠在提升性能的同時又盡少的造成信息損失。新聞標題生成可以看成文本摘要技術的一種應用場景。由於新聞結構的特點、標題一般而言都是非常簡練、甚至有點抽象、高度概括文章內容的句子。文本摘要技術作為一種重要的自然語言處理技術,對於快速獲取和更好展示新聞內容具有重要的意義,這也是本文的研究意義所在。
二、研究現狀
隨著自然語言處理技術的進步,越來越多的研究在自然語言生成任務(NLG)上取得了明顯進步。根據輸入信息的不同,NLG可分為:數據到文本的生成、文本到文本的生成、意義到文本的生成、圖像到文本的生成等。 因本文意在討論根據新聞文本生成新聞標題的NLG技術,屬於“文本-文本”生成,故下文著重討論此技術相關方法。文本-文本生成技術用於智能聊天、文章自動摘要、文章自動生成標題等問題都有著廣闊前景。近年來,許多優秀的研究著力於提升文本生成的准確、流暢程度。文章標題是精煉的文章內容,其使用最簡短的語言最大限度的反應文章的主要內容。標題自動生成算法根據其選擇、組織語言的方式可分為抽取式方法和生成式方法。
抽取式方法依據文本的統計信息提取關鍵的詞、句的排序並重新組合成為標題,Luhn[1]是最早使用主題詞法的研究員之一,他們使用頻率閾值來定位文檔中的描述性詞語並表示文檔主題。Dunning[2]提出了一個更高級的概念,他們使用對數似然比檢驗來識別解釋性詞語,在總結文獻中稱之為“主題簽名”。利用主題簽名詞作為主題表示非常有效,提高了新聞領域多文檔摘要的准確性[3]。Vanderwende等人[4]提出一個名為sumbaic的系統,該系統僅使用單詞概率權重的逐步迭代方法來確定句子的重要性,進而生成標題。TFIDF權重在單詞概率基礎上進行改進,利用詞頻和反轉詞向量計算重要性,具有計算簡單、快速的優點。工作[5-7]的共組基於這種方法取得了不錯的效果。Gong等[8]提出了一種基於lsa的新聞領域單文檔和多文檔摘要高排名句子選擇方法,該方法對每個主題都選取一個最高得分的句子,最后根據所需要生成的限定長度保留主題的數量。Henning等人[9] 提出一種將句子映射到本體概念的句子提取方法。通過考慮本體特征,可以提高句子的語義表達,有利於總結句子的選擇。
生成式方法則是通過對全文的語義分析,經由特征變換得到詞、句、段的高維表示,進而依據語義生成相應的標題,區別於抽取式方法,生成式方法對標題的選詞可能是文章中從未出現過的新詞。其中傳統算法,包括基於樹結構、基於模板、基於語義、基於圖等的方法都取得了較好的結果。在基於樹結構方法框架中,算法根據如謂詞-論據結構[10]、依賴樹[11]等方式提取摘要要考慮的重要文本。然后,使用淺層解析器從文本中識別出相似的句子。類似的句子被填充到樹狀結構中。在基於模板的方法中,依賴於文本深層的句法和語義分析[12],使用預定義的模板結構有助於創建簡潔、連貫的摘要。但是,由於規則和模式是手動定義的,因此這類方法非常耗時,還需要大量手動操作[13]。基於語義的自然語言生成方法首先通過查找信息項、謂詞參數結構或創建語義圖來獲得文本的語義表示。通過編輯謂詞-論據距離度量等相似性度量從中發現語義相似的結構,並通過k-均值或層次聚類等方法將語義相似的結構合並在一起[14]。然后,將此表示形式輸入自然語言生成系統。基於語義圖的方法通過把文本分割成若干組成單元(如單詞、句子等)並建立圖(節點-邊)模型, 利用投票機制對文本中的重要成分進行排序, 僅利用單篇文檔本身的信息即可實現關鍵詞的提取、文摘。隨著深度學習的興起,以Sequence-to-sequence神經網絡結構為框架的深度學習模型開始在文章標題、文章摘要等方向嶄露頭角。Chopra[15]等人使用RNN及其變種LSTM構成編碼器-解碼器結構來生成文章總結,Jobson[16]等人,在使用編-解碼器結構的同時利用注意力機制提取重要詞,取得了更優秀的結果。Song[17]等人以短語替代單詞作為輸入,經由LSTM組成的編解碼結構來生成文章簡介.Abigail[18]等人在解碼器端進行了改進提出了pointer-generaer網絡,通過指針從源文本復制單詞,提高了OOV單詞的准確性和處理能力,同時保留了產生新詞的能力。
三、相關模型
3.1、 基於圖計算的自然語言生成方法
TextRank 可以表示為一個有向有權圖 G =(V, E)。該圖由點集合 V和邊集合 E 組成,其中,E 是V × V的子集,圖中任意兩點 Vi , Vj 之間邊的權重為 wji 。 對於任意一個給定點 Vi ,In(Vi) 為 指 向 該 點 的 點 集 合 , Out(Vi) 為點 Vi 指向的點集合。點 Vi 的得分定義如下:
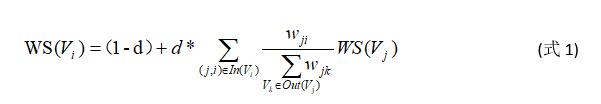
其中, d 為阻尼系數, 取值范圍為 0 到 1, 代表從圖中某一特定點指向其他任意點的概率。使用TextRank 算法進行圖計算時,對圖中的節點得分進行隨機初始化,並遞歸計算直到收斂(圖中任意一點的誤差率小於給定的閾值)
3.2基於深度學習的自然語言生成方法
(1) 編碼-解碼器(encoder-decoder)介紹:
encoder-decoder是一種經典的seq2seq結構。它能夠實現將一個序列轉換到另一個序列,並且不要求轉換的兩個序列等長,十分適合文本摘要任務。而類似自然語言文本這種序列數據都存在這時序關系,因此seq2seq常常使用LSTM,GRU這種能夠有效緩解梯度消失問題的神經網路結構來建模。具體網絡結構如圖1所示:
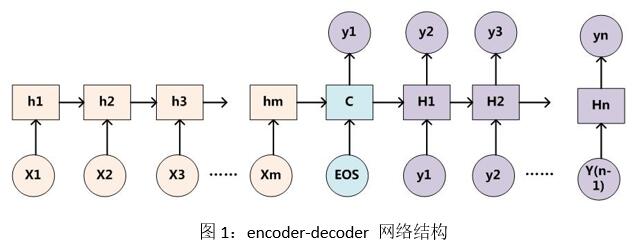
在這幅圖中,encoder端接收文本序列[x1:xm]的詞向量表示作為輸入,詞向量可以由word2vec、glove、BERT等語言模型訓練得到。encoder端把文本內容編碼成一個固定大小的理論上包含全文信息的隱層向量C,C的計算公式如式2所示。

要找到最優最大概率的摘要序列Y,有兩種方法可以選擇,一種式基於貪心搜索算法,即在每一步都選取概率最大的單詞作為輸出。這是一種最低成本的方法,但是這種方案得出的結果未必是最優的。因為當前時間步的解碼輸出會影響之后的解碼輸出。累計乘積可能並非最高。另一種方法則是枚舉所有輸出序列並計算得分,這種方法一定能找到全局最優解,但是時間復雜度和空間復雜度過高,實用性不強。因此Seq2Seq使用了一種這種的方法beam search。這種方法是貪心搜索和暴力枚舉的這種方案。在每個時間步內保留topk個最優候選結果,它本質還是屬於貪心算法的范疇,隻不過在貪心的過程中保留了更多可能。
(2)注意力機制下跌的編碼解碼器結構(Attention based encoder-decoder)
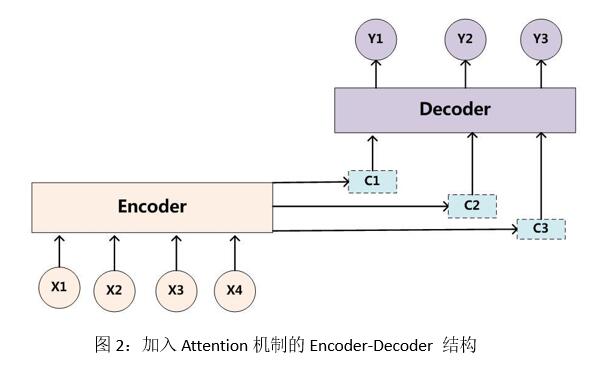
單純的編-解碼器結構有一個顯著的缺點,就是整個編碼-解碼過程共享一個單獨不變的語義編碼C,對於不同的生成詞都使用同一個C造成的結果就是模型不會根據當前生成詞位置的不同而採取不同的採樣方式。而Attention機制在整合encoder-RNN不同時間步生成encoder的隱藏狀態的序列時,輸出解碼的狀態St。及相應attention權重α。

至此,算法可達到收斂。其模型結構如圖2所示:
(3) pointer-generator
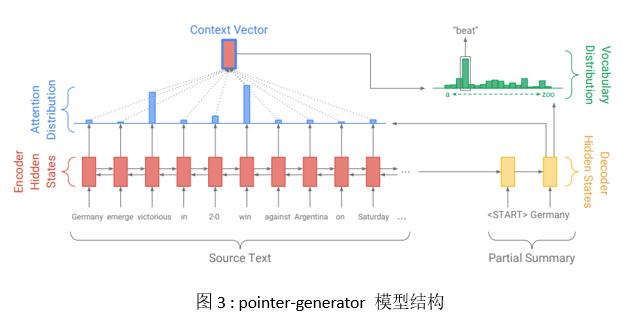
傳統的Seq2seq在生成摘要的每一個單詞時,通過一個softmax層計算詞匯表中每一個單詞的得分。即生成的摘要一定是來自於詞表裡面有的單詞,而在模型訓練之前,這個詞表已經是確定了的。因此訓練出來的模型在文中遇到詞表中沒有的詞卻又是非常關鍵的細節詞時會出現細節表述不清的問題。這也就是集外詞(OOV)問題。此外,由於解碼時隻看見前一個時刻的解碼出來的單詞,因此非常容易生成重復的摘要片段。針對傳統文本摘要模型存在的這兩個問題,Abigail See等基於傳統的attention-based encoder-decoder模型結構做了修改提出了pointer-generator模型(以下簡稱PG模型)。一方面,PG模型引入pointer指針來按一定概率從原文中復制某些單詞作為摘要。另一方面,引入coverage機制,在生成詞時,增加對每個詞歷史累計attention得分的懲罰。作者認為之前出現過詞在摘要中再次連續出現的概率應該要降低。PG的模型結構如圖3所示:

四、實驗方法
本文基於互聯網上公開的標准新聞數據。通過利用上述研究的文本摘要模型,進行智能互聯網新聞標題生成實驗,為新聞內容的快速獲取和有效展示提供可行的方案。
4.1 數據集構建
我們使用公開數據集ION dataset[19],由於ION數據集原文部分使用原文url鏈接而非原文文本,我們遵守url鏈接網站robots協議爬取了相對應的文本。新聞文章-標題共計66518條,格式如表1中所示:

4.2 數據處理
數據預處理是機器學習領域相關工作必不可少的環節之一,在文本數據預處理中,主要工作是消除無意義的特殊字符、常見的無意義或欠意義的詞(a, the 等)以及分詞來降低數據中的噪聲以達到最優的模型效果。在本文工作中,因文本主要通過爬虫爬取,其中包含有許多HTML頁面中的標記符號以及表情符號,我們使用正則匹配的方式進行了噪聲過濾。分詞在中文領域是非常重要的環節,但由於本文使用英文公開數據集,英文單詞由空格切分,無需進一步設計分詞算法。
最大截斷句長是NLP任務中為了保証輸入的批次數據一致性而產生的超參數之一,即設定最大截斷句長后,所有文本中大於截斷句長的部分需要舍棄。在本文選用的數據集中,文章篇幅偏長(2000-3000字左右,如圖4所示),方差偏大(最大值30000字)。在深度學習算法的模型輸入數據中,批量的結構化數據以矩陣的形式輸入到模型中,每一批次中的各條數據必須符合相同的形狀(shape)才能夠集體約束模型收斂。所以合理的最大截斷句長分析是必不可少的,圖4中展示了以一個單詞為1單位計算的文章長度和標題長度的對比分析,以覆蓋95%的截斷策略來說,最佳階段長度應在5000附近,但考慮到新聞文本的特殊性--新聞文本普遍在文章開頭部分直入主題,我們對最大長度的截斷策略進行了變化,選擇以平均值附近的句長來進行截斷,其中,文章最大長度為2000, 標題最大長度為25。

文本向量化方法將文本形式的數據轉換成具有語義信息的向量形式用以進行建模計算,有one-hot、tf-idf值、word2vec算法、glove算法等進行編碼的方式。但是,One-hot編碼採用詞袋模型,不考慮詞與詞之間的順序,並假設詞與詞相互獨立,損失了部分語義信息,還會得到一個離散稀疏的特征矩陣,十分浪費內存,tf-idf, word2vec,glove算法都渴望通過設計一套算法來遞歸的計算出最能代表詞的向量,但人為設計的算法計算出的向量結果表示能力受限於算法原理,故在本文中,我們採用在模型中設置可訓練的、隨機初始化參數的詞嵌入層的方式,利用模型自動訓練出一個具有最佳表示能力、最貼合本文選取的語料的詞向量輸入。
4.3 模型參數
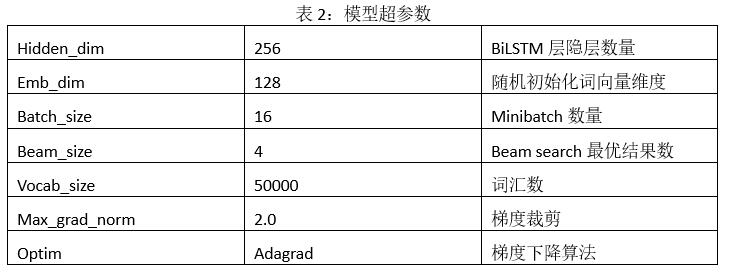
4.4 實驗結果
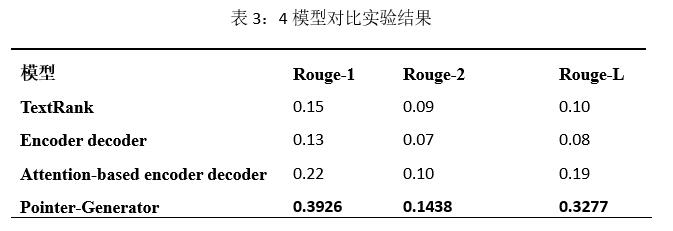
結果表明Pointer-Generator在新聞標題生成任務中具有顯著的優勢。

圖5是PG生成摘要的每個單詞對應全文的attention分布,以及每個單詞的P_gen概率。從圖中可以看出,當生成摘要的第一個詞Photographer時,模型將絕大部分注意力放在原文中的photographer、russian、photographer、nick這四個單詞中並以0.189的P_gen概率生成了摘要的第一個詞。這表明PG模型具備發現文本細節的能力,並能夠理解文章內容之間的關聯從而能夠達到最佳的標題生成能力。

五、結論
本文切入當今互聯網新聞領域文不對題,新聞快速獲取和稿件審核困難的痛點。結合當下的自然語言技術發展現狀,沿著文本摘要技術的發展脈絡,介紹了文本摘要模型的兩類基本方法論即基於圖結構模型和基於深度學習的模型。並介紹了基於深度學習的文本摘要模型的幾處比較新穎的改進。最后通過爬取新聞網站上的真實互聯網新聞數據,進行了多模型的新聞標題生成對比實驗。最后的實驗結果表明基於pointer-generator模型的新聞標題生成結果最為理想,能夠有效地應用到海量互聯網新聞地標題生成應用中。同時,現有的文本摘要技術仍然存在一些不太完善的問題,如模型更易於生成長句,且重復現象仍然存在。
應用新聞標題生成方法生成的“有效標題”能夠較為高效的減少人工審核稿件時間,然而,為了徹底解決“震驚體”現象排查繁瑣的問題,“有效標題”與“震驚體標題”的對比檢測必不可少,本文暫時著重討論有效標題的生成方法,在后續工作中,將著重探討對兩種標題的檢測部分。
參考文獻
[1] Hans Peter Luhn. 1958. The automatic creation of literature abstracts. IBM Journal of research and development 2, 2 (1958), 159–165.
[2] Ted Dunning. 1993. Accurate methods for the statistics of surprise and coincidence. Computational linguistics 19, 1 (1993), 61–74.
[3] Sanda Harabagiu and Finley Lacatusu. 2005. Topic themes for multi-document summarization. In Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 202–209.
[4] Lucy Vanderwende, Hisami Suzuki, Chris Brockett, and Ani Nenkova. 2007. Beyond SumBasic: Task-focused summarization with sentence simplification and lexical expansion. Information Processing & Management 43, 6 (2007), 1606–1618.
[5] Rasim M Alguliev, Ramiz M Aliguliyev, Makrufa S Hajirahimova, and Chingiz A Mehdiyev. 2011. MCMR: Maximum coverage and minimum redundant text summarization model. Expert Systems with Applications 38, 12 (2011), 14514–14522.
[6] Rasim M Alguliev, Ramiz M Aliguliyev, and Nijat R Isazade. 2013. Multiple documents summarization based on evolutionary optimization algorithm. Expert Systems with Applications 40, 5 (2013), 1675–1689.
[7] Günes Erkan and Dragomir R Radev. 2004. LexRank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res.(JAIR) 22, 1 (2004), 457–479
[8] Yihong Gong and Xin Liu. 2001. Generic text summarization using relevance measure and latent semantic analysis. In Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 19–25
[9] Leonhard Hennig, Winfried Umbrath, and Robert Wetzker. 2008. An ontologybased approach to text summarization. In Web Intelligence and Intelligent Agent Technology, 2008. WI-IAT’08. IEEE/WIC/ACM International Conference on, Vol. 3.IEEE, 291–294.
[10] Sunitha, C., Jaya, A., & Ganesh, D. A. (2016). A study on abstractive summarization techniques in indian languages. In Fourth international conference on recent trends in computer science and engineering (pp. 25–31).
[11] Barzilay, R., & McKeown, K. R. (2005). Sentence fusion for multidocument news summarization. Computational Linguistics, 31(3), 297–327.
[12] Oya, T., Mehdad, Y., Carenini, G., & Ng, R. (2014). A template-based abstractive meeting summarization: Leveraging summary and source text relationships. In Proceedings of the 8th international natural language generation conference (pp. 45–53).
[13] Alshaina, S., John, A., & Nath, A. G. (2017). Multi-document abstractive summarization based on predicate argument structure. In International conference on signal processing, informatics, communication and energy systems (SPICES) (pp. 32–37). doi:10.1109/SPICES.2017.8091339.
[14] Alshaina, S., John, A., & Nath, A. G. (2017). Multi-document abstractive summarization based on predicate argument structure. In International conference on signal processing, informatics, communication and energy systems (SPICES) (pp. 32–37). doi:10.1109/SPICES.2017.8091339.
[15] Chopra, Sumit, Michael Auli, and Alexander M. Rush. "Abstractive sentence summarization with attentive recurrent neural networks." Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016.
[16] Jobson, E., & Gutirrez, A. (2018). Abstractive text summarization using attentive sequence-to-sequence rnns. Stanford Reports.
[17] Song, S., Huang, H., & Ruan, T. (2018). Abstractive text summarization using lstmcnn based deep learning. Multimedia Tools and Applications, 1(6), 53–57. doi:10. 1007/s11042-018-5749-3.
[18] See, Abigail, Peter J. Liu, and Christopher D. Manning. "Get to the point: Summarization with pointer-generator networks." arXiv preprint arXiv:1704.04368 (2017).
[19] Hollink L , Bedjeti A , Vanharmelen M , et al. A corpus of images and text in online news[J]. 2016.
分享讓更多人看到 
推薦閱讀
傳媒推薦
 @媒體人,新聞報道別任性
@媒體人,新聞報道別任性 網站運營者 這些"紅線"不能踩!
網站運營者 這些"紅線"不能踩! 一圖縱覽中國網絡視聽行業
一圖縱覽中國網絡視聽行業
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
