




















海量新闻信息处理中的语义角色标注研究
摘要:
语义角色标注(SRL)是语义识别的关键研究方向之一。语义角色标注是一种浅层语义分析技术,以句子为单位,分析句子的谓词-论元结构,具体来说,语义角色标注的任务就是以句子的谓词为中心,研究句子中各成分与谓词之间的关系,并且用语义角色来描述他们之间的关系。语义角色标注在问答系统、机器翻译和信息抽取等方面得到了成功地应用[1]。在过去使用深度学习处理新闻信息的案例中,Bi-LSTM模型在语义角色标注上取得了较大的成功[2]。然而,过去在新闻处理中应用的语义识别方法存在几个问题。首先是Bi-LSTM+CRF的方法模型计算复杂度较高,其次是过去基于BIO文本标注方法的模型,必须要给定谓词,而且无法准确的识别出同一个句子中多个谓词以及它们所对应的论元之间的关系,而且还存在一个严重的限制―无法预测多谓词-论元的重叠区域的信息。 本文介绍了一种新的方法,一种端到端的联合预测多个谓词组合的方法[18],克服了以上所说的限制。在LSTM结构中加入了Highway [3]结构,能够有效的缓解梯度消失的问题。并且应用了今年来兴起的大型预训练语言模型来进一步获得句子中的语义信息,本文使用ELMo进行实验[4]。这对于人民网在内容语义识别上能发挥重要的作用。
关键词:语义角色标注,SRL,语义识别,深度学习,Bi-LSTM,CRF,highway,ELMO
一、 引言
社会媒体的快速发展使得世界的联系越来越紧密,新闻已经成为了人们获得信息的重要途径。近年来,新闻行业数字化发展迅猛,新闻网络平台的普及,极大地满足了人们“足不出户而知天下事”的心愿。人民网作为大型网络新闻媒体,更是成为了民众的焦点平台,成为了获取时事信息的重要途径。
随着社会发展,新闻的数量也在与日俱增,面对日益增加的新闻,如何更好的处理、展示新闻信息就成了一个重要的研究课题。语义识别技术,能够捕捉到新闻句子中的语义信息,语义角色识别作为语义识别的重要研究方向,更是可以很好的分析出句子中的谓语以及相对应的角色信息,对于筛选、处理以及更好的展示新闻中的关键信息有着重要的意义,这也正是本文的研究意义所在。
二、 研究背景以及现状
(一) 研究背景
在当今社会,大量信息不断出现,这无疑给信息的分析等工作造成了巨大的困难。语义角色标注技术的出现,帮助不同用户理解并获取知识,围绕知识搜集、描述、组织、检索和使用构建知识库与用户模型。知识组织 SRL 模型及其可行性方案的实现将会解决知识获取、求精和结构化等问题。目前,SRL 技术已经被成功地应用于问答系统、信息抽取、自动文摘、文本蕴涵、词义消歧、信息检索、 指代消解、机器翻译、生物信息学等领域。
然而,过去在新闻处理中应用的语义识别方法存在一些问题。传统的语义角色标注方法只能根据特定领域,不能准确的捕捉到新闻信息的语义信息,而且可移植性低,不适合大型信息平台使用。深度学习兴起后,出现了一些具有时代意义的处理模型。然而,经常使用的Bi-LSTM+CRF的方法模型计算复杂度较高,其次是过去基于BIO文本标注方法的模型,必须要给定谓词,而且无法准确的识别出同一个句子中多个谓词以及它们所对应的论元之间的关系,而且还存在一个严重的限制―无法预测多谓词-论元的重叠区域的信息。本文介绍了一种方法,在降低特征提取模型的复杂度的基础上,克服了不能预测多谓词-论元的重叠区域的信息的限制,在LSTM结构中还加入了Highway结构[3],能够有效的缓解梯度消失的问题。对于新闻平台处理信息的工作具有极大的意义。
(二) 传统的SRL方法
1. 基于依存句法关系的SRL
依存关系可以是句中词与词之间的句法关系,也可以是语义关系。依存句法使用了不同的信息组成 方式,信息重组对于本地化特定谓词的语义角色非常有用。通过依存关系,依存树可以直接对与谓词节点相连的语义角色结构进行编码。英文方面,HACIOGLU[5]首次采用基于依存分析的方法来实现 SRL; LAFFERTY等[6]在研究自然语言处理曾应用过此机器学习方法。相比基于句法成分的英文 SRL,中文基于依存关系的标注对词汇的依赖性较弱,鲁棒性较高。
2. 基于特征向量的SRL
比较文本信息中不同特征,以基本的特征和语料数据资源为基础,筛选便于识别和分类的特征进行SRL. DING等[7]提出了一种层次化特征选择策略,XUE等[8]在GILDEA标准特征集合的基础上尝试了组合特征,BOXWELL等[9]提出一种基于丰富特征的SRL方法。目前的研究一般将基本的特征加以组合来降低特征空间的维度,提高 SRL 的性能;人工智能知识表示中的“框架-槽”、模式识别中的“特征”、多媒体数据库中的“特征向量”等已经开始应用此技术。
3. 基于最大熵分类器的SRL
基本思想是为所有已知的因素建立模型,把所有未知因素排除在外。预测了全部能够在句法分析树中找到匹配成分的角色后,采用简单的后处理规则去识别那些找不到匹配成分的角色。使用最大熵模型进行SRL的有XUE等[10]和刘挺等[11]。XUE等[12]使用最大熵模型进行实验,在基于单一句法树的基础上,详细 验证了GILDEA等[13]研究中的各个基本特征在SRL各阶段的贡献,并提出了新的特征。刘挺等[14]选取了较多的特征采用最大熵分类器对句子中谓词的语义角色同时进行识别和分类,取得很好效果。
4. 基于核函数的SRL
一般使用核函数的目的是将低维线性不可分问题映射到高维空间,使之成为线性可分问题。可以通过计算核函数隐式达到,从而降低时间和空间复杂性很好地融入到 SRL 技术中。MOSCHITTI[15]最早使 用核函数的方法来实现 SRL,CHE等[16]在其研究基础上,将 PAK 核分为路径核和成分结构核,通过线 性组合集成 2 个核。ZHANG等[17]指出传统树核函数都是“硬”匹配,不利于计算相似成分或近义的语法标记,支持向量机(support vector machine,SVM)、感知器等学习算法。
5. 基于条件随机场的SRL
条件随机场(conditional random fields,CRFs)模型擅长处理序列标记问题,是一种无向图模型,考察给定输入序列对应的标注序列的条件概率,训练目标是使条件概率最大化。它以浅层句法分析为基础,把短语或命名实体作为标注的基本单元,将CRFs用于句子中谓词的SRL. COHN等[18]在PropBank 句子的完全句法分析树上建立树 CRFs 标注模型,标注结果好于最大熵模型;董静[19]等考虑句法树中水平层次上的角色标签之间的马尔科夫依赖关系,在 PropBank 语料基础上进行了SRL实验;YU 等[20]使用CRFs模型研究了英文 PropBank 的SRL问题,使用浅层短语块和命名实体块作为标注单位。以上使用CRFs模型的SRL实验都取得了不错的效果。
三、 相关研究工作
(一) 数据集
本次实验使用国际上信息处理认可的PropBank SRL数据集。
(二) Jointly Predicting Predicates + Highway+ELMO模型
以往的基于BIO标注方法的模型已经有了不错的表现,但是存在一个问题,就是都需要假设谓词作为输入的一部分,并且还不能包括跨度级别的特征,本次介绍的模型不仅可以解决这个问题,而且也达到了优于其他模型的效果。以下是本次介绍的模型与BIO标注的模型在双谓词特征上的区别如图1所示,
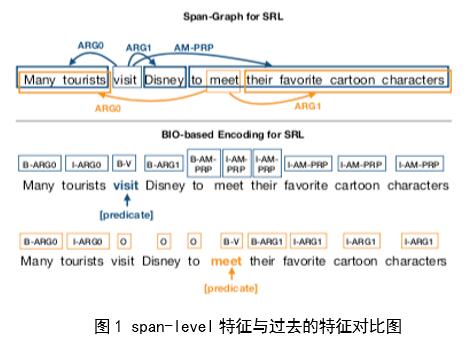
可以看出,我们可以同时预测出多个谓词与他们相对应的角色对。而且,这个模型还克服了一个重要的限制:模型可以预测交叉重叠的数据区域而不受影响。
2.1 数据处理
输入数据要经过分词、去停用词、去除标点,只留下有意义的信息,使得模型捕捉到的信息不会因为诸如“着,的”等词稀释。
2.2 算法模型
模型分别两部分,第一部分是建立所需要的span-level词向量,结构如下图2所示,

最底层的向量由预训练好的词向量和字级别的向量拼接而成,然后将每个词的向量输入到m层的Bi-LSTM中,并且加入了Highway(如本文介绍的第一个模型一致)。
Bi-LSTM层,LSTM是RNN的变种,采用双向的LSTM,LSTM计算公式如下公式(2-1)、公式(2-2)、公式(2-3)、公式(2-4)、公式(2-5)、公式(2-6)所示:

在LSTM的基础上加入Highway的计算方式,图中LSTM传输上的曲线就是Highway,加入Highway-LSTM结构可以有效的缓解梯度消失的问题,计算如公式(2-7)、公式(2-8)、公式(2-9)所示,
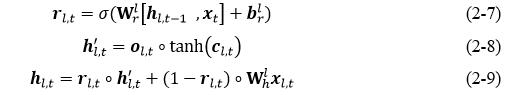
图中的span head(x_h)是一种注意力机制,它的输入是Bi-LSTM的输出。实现方式如下,其中e是计算的中间过程,注意力机制计算过程如公式(2-10)、公式(2-11)所示,
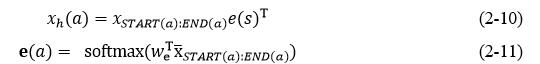
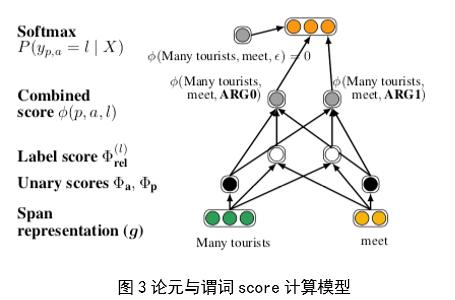
第二部分是通过前馈神经网络计算每个论元(argument)与谓词之间的得分,判断它们之间是否存在关系,模型结构如图3所示,
在图5中,score的计算规则如公式(2-12)、公式(2-13)、公式(2-14)所示,
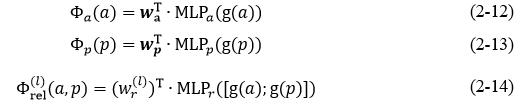
其中,g表示span representation,a表示论元arguments,p表示谓词predicates,MLP表示全连接层。
如图3.17中,Combined score的操作,就是简单的相加。Combined score的操作的计算方式如公式(2-15)所示,
![]()
最后的softmax分类结果有三种,分别是具有arg0关系、具有arg1关系、没关系,计算概率最大的一个作为最终的结果。
2.3 降低计算复杂度

2.4 ELMO
近两年大型预训练语言模型在各个NLP领域的任务中表现卓越,其中也包括语义角色标注,本文使用ELMo进行预训练。ELMO是一个包含语法语义信息而且能够解决一词多义信息的词向量训练的语言模型,结构如图4所示,

将ELMo输出的向量,作为模型Bi-LSTM的输入向量,原来设定的最底层的数据输入作为ELMo模型的输入。最终结果表明,ELMo语言模型的加入,有效的提升了模型的效果。
(三) 模型评分标准
模型评价使用计算的F1值为标准。F1值的计算公式如公式(2-16)所示,

(四) 模型对比结果
本次使用PropBank SRL公开中文数据集进行模型评测,三个模型的评测结果如表1所示,

结果表明,加入ELMo语言模型的联合预测效果显著
(五) 使用人民网新闻数据进行测试
从人民网中摘一句话,“贺一诚以392票高票当选澳门特区第五任行政长官人选”,用模型生成预测结果如图5所示

上述是原句分词的结果,生成结果中6表示谓词的位置,即本句中的当选,论元角色分别有贺一诚、行政长官人选,“以392票高票”是方式,A0表示第一个论元,MNR表示方式,A1表示第二个论元。可以看到,效果还是很不错的。
(六) 总结
本文介绍了三个改进点,有着各自的特点与优势。
第一个点是在LSTM中Highway结构的加入,可以有效的缓解RNN梯度消失的问题。
第二个点是大型预训练语言模型ELMo的加入,近年来兴起的预训练语言模型在NLP领域中表现卓越,对于语义识别任务也有较大的提升。
第三个点是提出了新颖的span-level特征的提取方式,并且能够一次性预测多个谓词及相关的论元对,不需要事先定义好谓词进行输入,并且克服了不同论元交叉区域的影响,具有很强的现实意义。
中文的语义角色标注一直存在着很多问题,而且语义的捕捉也更加困难,本文介绍的改进点对于在海量的新闻信息处理上解决这些问题可以提供一些新的思路。
四、 结论
针对中文文本的特点,结合当下语义识别的实际需求,本文通过改善LSTM/RNN等循环神经网络模型,在模型复杂度以及识别的限制的问题上进行了改善。并结合语言模型ELMo,提出了一种联合预测方案,能够实现中文句子多谓词情况下的语义角色的自动标注。对新闻网站的建设以及更好的展示和挖掘新闻中的信息,有着一定的推动意义。
可以看到,语义识别技术的发展,使得新闻网站关键信息的着重突出以及更加的人性化,可以给用户带来更好的体验。
参考文献:
[1] LOWE J B, BAKER C F, FILLMORE C J. A frame-semantic approach to semantic annotation[C]//Proceedings of the SIGLEX Workshop on Tagging Text with Lexical Semantics: Why, What, and How. 1997: 4-5.
[2] Zhiheng Huang, Wei Xu, and Kai Yu. 2015. Bidirectional LSTM-CRF models for sequence tagging. CoRR, abs/1508.01991.
[3] Luheng He, Kenton Lee, Mike Lewis, and Luke S. Zettlemoyer. 2017. Luheng He, Kenton Lee, Mike Lewis, and Luke S. Zettlemoyer. 2017. Deep semantic rol
[4] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matthew Gardner, Christopher T Clark, Kenton Lee, and Luke S. Zettlemoyer. 2018. Deep contextualized word representations. CoRR, abs/1802.05365.
[5] HACIOGLU K. Semantic role labeling using dependency trees[C]//Proceedings of the 20th International Conference on Computational Linguistics. Stroudsburg: ACM Press, 2004: 1273.
[6] LAFFERTY J. McCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th International Conference on Machine Learning 2001(ICML 2001). ACMPress, 2001: 282-289.
[7] DING J T, WANG H L, ZHOU G D, et al. On optimized combination of features in semantic role labeling[J]. Computer Applications and Software, 2009, 26(5): 17-21.
[8] XUE N W, PALMER M. Calibrating features for semantic role labeling[C]//Proceedings of the EMNLP. Stroudsburg: ACL,2004: 88-94.
[9] BOXWELL S A, MEHAY D, BREW C. Brutus: a semantic role labeling system incorporating CCG, CFG, and dependency features[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language. ACM Press, 2009: 37-45.
[10] 刘挺,车万翔,李生. 基于最大熵分类器的语义角色标注[J]. 软件学报,2007,18(3):565-573. LIU T, CHE W X, LI S. Semantic role labeling with maximum entropy classifier[J]. Journal of Software, 2007, 18(3):565-573. (in Chinese)
[11] GILDEA D, PALMER M. The necessity of parsing for predicate argument recognition[C]//Proceedings of the 40th Meeting of the Association for Computational Linguistics. Philadelphia, PA: ACM Press, 2002: 239-246.
[12] MOSCHITTI A. A study on convolution kernels for shallow semantic parsing[C]//Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA: ACM Press, 2004: 335-342.
[13] CHE W X, ZHANG M, LIU T, et al. A hybrid convolution tree kernel for semantic role labeling[C]//Proceedings of the COLING/ACL on Main Conference Poster Sessions. Stroudsburg, PA: ACM Press, 2006: 73-80.
[14] ZHANG M, CHE W X, ZHOU G D, et al. Semantic role labeling using a grammar-driven convolution tree kernel[J]. IEEE Transaction on Audio, Speech and Language Processing, 2008, 16(7): 1315-1329.
[15] COHN T, BLUNSOM P. Semantic role labelling with tree conditional random fields[C]//Proceedings of the Ninth Conference on Computational Natural Language Learning. Stroudsburg, PA: ACM Press, 2005: 169-172.
[16] 董静,孙乐,吕元华,等. 基于线性链条件随机场模型的语义角色标注[C]//中国中文信息学会二十五周年学术会议,北京,2006:32-37.DONG J, SUN L, LU? Y H, et al. Semantic role labling based on conditional random[C]//Chinese Information Processing Society Conference Twenty-fifth Anniversary of China. Beijing, 2006: 32-37. (in Chinese)
[17] YU J D, FAN X Z, PANG W B, et al. Semantic role labeling based on conditional random fields[J]. Journal of Southeast University (English Edition), 2007, 23(3): 361-364.
[18] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In NAACL.
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
