




















гявхжЧФмЕМУЄЦНЬЈбаОП
1. аїТл
1.1 ЯюФПМђНщ
ЫцзХПЦММЕФЗЂеЙЃЌЖрбљЕФвЦЖЏЦНЬЈМАЦфПижЦЗНЗЈЕФбаОПЗЂеЙбИУЭЃЌжЧФмвЦЖЏЦНЬЈЕФзджїЕМКНММЪѕГЩЮЊбаОПШШЕуЁЃSLAMЃЈSimultaneous Localization and MappingЃЌЭЌЪБЖЈЮЛгыЕиЭМЙЙНЈЃЉММЪѕБЛШЯЮЊЪЧНтОізджїЕМКНЮЪЬтЕФЙиМќЁЃетИіЮЪЬтПЩвдУшЪіЮЊЃКЛњЦїШЫдкЮДжЊЛЗОГжаДгвЛИіЮДжЊЮЛжУПЊЪМвЦЖЏЃЌдквЦЖЏЙ§ГЬжаИљОнЮЛжУЙРМЦКЭвбгаЕиЭМНјааздЩэЖЈЮЛЃЌЭЌЪБдкздЩэЖЈЮЛЕФЛљДЁЩЯНЈдьдіСПЪНЕиЭМЃЌДгЖјЪЕЯжзджїЖЈЮЛКЭЕМКНЁЃетжжОпгаИпЖШжЧФмЕФФЉЖЫзджївЦЖЏЦНЬЈгаЙуРЋЕФгІгУЧАОАЃЌШчЃКжЧФмбВМьЁЂЙЪеЯБЈОЏЁЂЮоШЫМнЪЛЁЂЮодДеьВьЕШЕШЁЃ
БОЮФжМдкЩшМЦЪЕЯжНЛЛЅадКУЕФгявхжЧФмЕМУЄЯЕЭГЃК(1) ВЩгУТѓПЫФЩФЗТжвЦЖЏЦНЬЈКЭPIDЫЋБеЛЗПижЦЯЕЭГЪЕЯжвЛжжИпаЇзМШЗЕФвЦЖЏЗНЪНЃЛ(2) РћгУIMUЙпадЕМКНФЃПщКЭЩуЯёЭЗФЃПщШкКЯИажЊЬсЙЉИќМгОЋзМЕФЮЛзЫаХЯЂЃЛ(3) ДђЦЦЯжгаЕФгадДЕМКНЗНЪНЃЌЖЏЬЌЙЙНЈЕиЭМЁЂЖЈЮЛКЭЙьМЃЙцЛЎЃЛ(4) ЭЈЙ§гявхЯЕЭГдіЧПгыУЄШЫЕФНЛЛЅадЁЃГѕВНЪдбщНсЙћБэУїЃЌИУЯЕЭГФмНЯКУЕФТњзувЦЖЏЦНЬЈЕФИпОЋЖШЁЂЖдЛЗОГНјааИажЊФмСІКЭЖрЛЗОГЕФЪЪгІФмСІЁЃ
1.2 СЂЯюБГОА
НќФъРДЃЌЕМУЄЮЪЬтГЩЮЊЩчЛсЙизЂЕФШШЕуЮЪЬтЃЌДЋЭГЕФЕМУЄШЎгаКмЖрЕФЯожЦЃЌБШШчЫЕФжЪаЧјВЛАВШЋЧщаїВЛЮШЖЈЕШЕШЃЌОпгавЛЖЈЮЃЯеадЃЌДЫЭтЃЌЛЙгаЪжеШРрЕМУЄИЈОпЁЂДЉДїЪНЕМУЄИЈОпЁЂвЦЖЏЪНЕМУЄИЈОпЁЃЕМУЄЪжеШФмЙЛШУЪЙгУепИаЪмЕНвЛЖЈИпЖШЕФеЯАЮяЃЌЭЈЙ§е№ЖЏЪжБњЭЈжЊЪЙгУепЃЌЕЋЪЧдкааЖЏЩЯгажюЖрЪмЯоЃЌУЄШЫдкЩњЛюжаЛЙЪЧУцСйКмДѓЕФЬєеНЁЃбќДјЪНааЖЏИЈОпвдГЌЩљВЈЪдЭМУшЛцГіЧјгђФкЕФШЋОАЕиЭМЃЌзЊБфГЩЩљвєЕФДѓаЁЁЂЦЕТЪМАзѓгвЗНЮЛВювьЕШЗЂвєЗНЪНЃЌИцжЊЪЙгУепЫљдкЧјгђФкеЯАЮяЕФДѓаЁЁЂдЖНќЕШаХЯЂЃЌЕЋЪЧЮоЗЈзджїШЅХаЖЯЃЌЛЙЪЧвЊвРППЪЙгУепШЅЬНЫїЁЃ
ЫцзХШЫЙЄжЧФмКЭЛњЦїбЇЯАММЪѕЕФЗЂеЙЃЌМЦЫуЛњНЅНЅПЩвдЭЈЙ§ЭМЦЌБцБ№ГіЮяЬхЁЂШЫСГЁЂЩљвєЁЂЮФзжЕШЕШЁЃФЧУДЃЌЮвУЧЪЧВЛЪЧПЩвдЭЈЙ§ЩуЯёЭЗДњЬцУЄШЫЕФблОІФиЃПвђДЫЃЌШчКЮФмЙЛШУЛњЦїШЫЕФЩуЯёЭЗДњЬцУЄШЫЕФблОІЪЧвЛИіжЕЕУбаОПЕФЮЪЬтЁЃЦфФбЕудкгкЃКдкУЛгаЯШбщаХЯЂЕФЧщПіЯТдѕбљЖЏЬЌНЈСЂЕиЭМФЃаЭЃЌОпгазджїдЫЖЏЕФФмСІЁЃ
ЮЊСЫФмЙЛОпгазджїдЫЖЏФмСІЃЌашвЊУїШЗШ§ИіЮЪЬтЃКздМКдкФФРяЃПетЪЧЪВУДЕиЗНЃПдѕУДРыПЊетИіЕиЗНЃПSLAMЪЧНтОіЧАСНИіЮЪЬтЕФЙиМќЗНЗЈЁЃSLAMЪЧжИДюдиЬиЖЈДЋИаЦїЕФжїЬхЃЌдкУЛгаЛЗОГЯШбщаХЯЂЕФЧщПіЯТЃЌдкдЫЖЏЙ§ГЬжаНЈСЂЛЗОГЕФФЃаЭЃЌЭЌЪБЙРМЦздМКЕФдЫЖЏЁЃАДДЋИаЦїВЛЭЌжївЊЗжЮЊЛљгкМЄЙтРзДяЕФSLAMКЭЛљгкЪгОѕЕФSLAMЁЃМЄЙтРзДяФмвдКмИпОЋЖШВтГіЛњЦїШЫжмЮЇеЯАЕуЕФНЧЖШКЭОрРыЃЌЬсЙЉЛњЦїШЫБОЬхгыжмЮЇЛЗОГеЯАЮяМфЕФОрРыаХЯЂЃЌЪЧЙХРЯВЂЧвДЋЭГЕФЗНЪНЃЌЕЋЪЧМЄЙтРзДяЕФдьМлАКЙѓЃЌЗДРЁаХЯЂНЯЩйЁЃVIO-SLAMЃЈVisual Inertial Odometry SLAMЃЌМДЛљгкЪгОѕЙпадРяГЬМЦЕФSLAMЃЉЪЧвдЩуЯёЭЗКЭЙпадЕМКНдЊМўзїЮЊжївЊДЋИаЦїЃЌЭЈЙ§МЦЫуЛњЪгОѕДІРэЪжЖЮЃЌдкдЫЖЏЙ§ГЬжаНЈСЂЛЗОГФЃаЭВЂЙРМЦдЫЖЏЁЃЯрБШЃЌVIO-SLAMЕФДЋИаЦїЩуЯёЭЗвЊБувЫКмЖрЃЌВЂЧвВЩМЏЕФЪ§ОнЪЧвЛжЁжЁЭМЯёАќКЌаХЯЂКмЗсИЛЃЌгаРћгкКѓЦкЕФЪ§ОнДІРэКЭЭкОђЁЃвђДЫЃЌБОЯюФПНЋЛљгкVIO-SLAMеЙПЊбаОПЁЃ
VIO-SLAMвЛжБЪЧбаОПШШЕуЃЌРћгУЪгОѕРяГЬМЦНјааЖЈзЫЖЈЮЛЃЌФПЧАжїСїЕФЪгОѕДЋИаЦїгавдЯТШ§жжЃКЕЅФПЩуЯёЭЗЃЈMonocular CameraЃЉЁЂЫЋФПЩуЯёЭЗЃЈBinocular CameraЃЉЁЂЩюЖШЩуЯёЭЗЃЈRGB-D CameraЃЉЁЃЩюЖШЩуЯёЭЗПЩвджБНгЛёЕУЭМЯёМАЦфЖдгІЕФЩюЖШаХЯЂЃЌЕЋЪЧГЩБОЬЋИпЃЌЬхЛ§НЯДѓЃЌВЛЪЪгУгкЪвФкЛЗОГЁЃЫЋФПЩуЯёЭЗПЩвдЭЈЙ§Ш§НЧЗНЗЈМЦЫуГіЩюЖШаХЯЂЃЌЕЋЪЧЫЋФПЩуЯёЭЗдкФПБъОрРыНЯдЖЪБОЭЛсБфГЩЕЅФПЩуЯёЭЗЁЃЕЅФПЩуЯёЭЗЭЈЙ§СйНќЭМЯёЦЅХфМЦЫуГіЩуЯёЭЗЮЛзЫЕФБфЛЛЃЌдкСНИіЪгНЧЩЯНјааШ§НЧВтОрЕУЕНЖдгІЕуЕФЩюЖШаХЯЂЃЌЭЈЙ§ЕќДњЪЕЯжЖЈЮЛМАНЈЭМЁЃЯрБШЖјбдЃЌЕЅФПЩуЯёЭЗОпгадиКЩЧсЁЂЬхЛ§аЁЁЂСщЛюЕШгХЪЦЃЌБОЯюФПВЩШЁЕЅФПЩуЯёЭЗЗНЪНЁЃ
ЛљгкЕЅвЛЕФЭМЯёДІРэЕФSLAMММЪѕЃЌЩуЯёЭЗдкПьЫйвЦЖЏЙ§ГЬжаЃЌЛсГіЯждЫЖЏФЃК§ЃЌСНжЁЭМЦЌжЎМфжиЕўЧјгђЬЋЩйЮоЗЈЭъГЩЬиеїЦЅХфЃЌдьГЩЖЈЮЛЙРМЦЮѓВюЗЧГЃДѓЃЌФбвдЪЪгУгыПьЫйдЫЖЏЁЃЮЊСЫНтОіетИіЮЪЬтЃЌБОЯюФПНЋВЩгУЙпадВтСПЕЅдЊЃЈIMUЃЉКЭЩуЯёЭЗСНжжДЋИаЦїЯрШкКЯЕФЗНЪНЁЃIMUФмЙЛЭЈЙ§ФкжУЕФЭгТнвЧКЭМгЫйЖШМЦВтСПНЧЫйЖШКЭМгЫйЖШЃЌНјЖјЭЦЫуЯрЛњЕФзЫЬЌЁЃдкОВЬЌЙ§ГЬжаЃЌвђДцдкУїЯдЕФЦЏвЦЖјЕМжТСНДЮЛ§ЗжКѓЕУЕНЕФЮЛзЫЪ§ОнЗЧГЃВЛПЩППЁЃЕЋЖдгкЖЬЪБМфФкЕФПьЫйдЫЖЏЃЌIMUФмЙЛЬсЙЉНЯКУЕФЙРМЦЁЃЩуЯёЭЗНЯЪЪКЯгкЕЭЫйдЫЖЏЙ§ГЬЛђепОВЬЌЙ§ГЬЃЌЮЛжУзЫЬЌЙЬЖЈЗЧГЃЮШЖЈЃЌПЩвдаоВЙIMUЕФЦЏвЦЮѓВюЁЃЫљвдЃЌВЩгУЩуЯёЭЗКЭIMUЯрНсКЯЕФЗНЪНЖдгкИпЫйдЫЖЏЯТЪЧЪЎЗжБивЊЕФЁЃвђДЫЃЌБОЯюФПЕФзджївЦЖЏЦНЬЈВЩгУIMUКЭЕЅФПSLAMЯрНсКЯЕФЗНЪНЁЃ

жБНгНЈСЂЕФЕиЭМЪЧдгТвЮоеТЕФЕуЃЌШєЯывЊЛњЦїШЫПЩвдИцЫпЪЙгУепЧАЗНЕНЕзЪЧЪВУДЃЌОЭвЊВЩгУЩюЖШбЇЯАЕФЗНЪНШЯжЊГіЮяЬхЃЌВЂЧвдкЕиЭМЩЯБъзЂБъЧЉЃЌетИіЙ§ГЬГЦЮЊгявхSLAMЁЃетбљЛњЦїШЫБуПЩвдАбЮяЬхЕФОпЬхаХЯЂЗДРЁИјЪЙгУепЃЌЯрБШДЋЭГЕФЕМУЄИЈОпОпгаИќКУЕФНЛЛЅадЁЃ
злЩЯЫљЪіЃЌБОЯюФПНЋвЊбаОПвЛжжЛљгкгявхVIO-SLAMЖрДЋИаЦїШкКЯЕФЖЏЬЌНЈФЃзджїЕМУЄЦНЬЈЁЃ
1.3 ЙњФкЭтбаОПЯжзД
НгЯТРДЃЌДгвЦЖЏЛњЦїШЫЁЂвЦЖЏЛњЦїШЫЖЈЮЛЗНЗЈЁЂвЦЖЏЛњЦїШЫЕФЕиЭМДДНЈгыЭЌВНЖЈЮЛММЪѕЁЂЛљгкЩюЖШбЇЯАЕФгявхЗжИюЕШМИИіЗНУцНщЩмЯТЙњФкЭтдкИУСьгђЕФбаОПЯжзДЁЃ
1.3.1 вЦЖЏЛњЦїШЫ
ЙњМЪБъзМЛЏзщжЏ(ISO)жаЕФЙЄвЕздЖЏЛЏЯЕЭГЮЏдБЛс(TC184)ЫљЪєЙЄвЕЛњЦїШЫЗжЛс(SC2)ЖдЛњЦїШЫЕФЖЈвхЪЧЃКЁАA robot is a machine which can be programmed to performsome tasks which involve manipulative or locomotive actions under automatic controlЁБЃЌМДЁАЛњЦїШЫЪЧвЛжжздЖЏПижЦЯТЭЈЙ§БрГЬПЩЭъГЩФГаЉВйзїЛђвЦЖЏзївЕЕФЛњЦїЁБЁЃЛњЦїШЫЪЧдкДДдьвЛИіЁАгыШЫвЛбљЫМПМЁЂвЛбљааЖЏЕФЛњаЕзАжУЁБЕФЙЙЯыЯТЕЎЩњЕФЁЃЫцзХЛњЦїШЫгІгУСьгђЕФВЛЖЯЭиеЙЃЌЛњЦїШЫММЪѕвбОГЌГіЙЄвЕЛњЦїШЫЗЖГыЁЃдчдкЦпЪЎФъДњжаЦкЃЌдкМЦЫуЛњММЪѕЁЂДЋИаЦїММЪѕКЭШЫЙЄжЧФмРэТлЕФЭЦЖЏЯТЃЌЙњМЪЩЯЙуЗКПЊеЙСЫЖджЧФмЛњЦїШЫЕФбаОПЃЌЦфжавдвЦЖЏЛњЦїШЫ[1]ЕФбаОПзюЮЊЙуЗКЁЃНќФъРД,вЦЖЏЛњЦїШЫММЪѕдкЙЄвЕЁЂХЉвЕЁЂвНбЇМАЩчЛсЗўЮёвЕЕШСьгђЯдЪОСЫдНРДдНЙуЗКЕФгІгУЧАОАЁЃдкЮвЙњЃЌвЦЖЏЛњЦїШЫбаОПвВХюВЊПЊеЙЦ№РДЃЌгШЦфЕБЩёжнЮхКХдиШЫЗЩДЌЗЂЩфГЩЙІжЎКѓЃЌЙњМвМгДѓдкгюКНСьгђЕФПЦбЇбаОПСІЖШЃЌвЦЖЏЛњЦїШЫзїЮЊаЧМЪЬНЫїЕФживЊЙЄОпЃЌГЩЮЊЯрЙиПЦММШЫдБбаОПЙЅЙижиЕуЁЃ
ЫљЮНвЦЖЏЛњЦїШЫОЭЪЧжИФмЙЛЖдИДдгЕФЛЗОГНјаазджїЕФЗжЮіЁЂХаЖЯКЭОіВпЃЌВЂЪЕЯжПьНнЁЂАВШЋЁЂздгЩвЦЖЏЕФЛњЦїШЫЁЃ
ДгЙЄзїЛЗОГРДЗжЃЌПЩЗжЮЊЪвФквЦЖЏЛњЦїШЫКЭЪвЭтвЦЖЏЛњЦїШЫЃЛ
АДвЦЖЏЗНЪНРДЗжЃЌПЩЗжЮЊТжЪНвЦЖЏЛњЦїШЫЁЂВНаавЦЖЏЛњЦїШЫЁЂШфЖЏЛњЦїШЫЁЂТФДјЪНвЦЖЏЛњЦїШЫЁЂХРааЛњЦїШЫКЭЫЎЯТЭЦНјЪНЛњЦїШЫЕШЃЛ
АДПижЦЬхЯЕНсЙЙРДЗжЃЌПЩЗжЮЊЙІФмЪНЃЈЫЎЦНЪНЃЉНсЙЙЛњЦїШЫЁЂааЮЊЪНЃЈДЙжБЪНЃЉНсЙЙЛњЦїШЫКЭЛьКЯЪННсЙЙЛњЦїШЫЃЛ
АДЙІФмКЭгУЭОРДЗжЃЌПЩЗжЮЊвНСЦЛњЦїШЫЁЂОќгУЛњЦїШЫЁЂжњВаЛњЦїШЫЁЂЧхНрЛњЦїШЫКЭЙмЕРМьВтЛњЦїШЫЕШЃЛ
АДзївЕПеМфРДЗжЃЌПЩЗжЮЊТНЕивЦЖЏЛњЦїШЫЁЂЫЎЯТЛњЦїШЫЁЂЮоШЫЗЩЛњКЭПеМфЛњЦїШЫЁЃ
ФПЧАЃЌЙњФкЭтЙигквЦЖЏЛњЦїШЫЕФбаОПжївЊМЏжадкЛњЙЙЩшМЦРэТлЁЂПижЦВпТдбаОПЁЂПеМфЖЈЮЛММЪѕЁЂзджїЕМКНЕШЗНУцЁЃвЦЖЏЛњЦїШЫЕФадФмДгИљБОЩЯШЁОігкЩЯВуОіВпЯЕЭГЕФЩшМЦЃЌШчКЮдкЮДжЊЛЗОГжаНјааЖЈЮЛгыЕМКНЪЧиНД§НтОіЕФЙиМќЮЪЬтЁЃЙњФкЭтвбгПЯжГіВЛЩйзлКЯЕФОіВпЗНЗЈЃЌжївЊгаРюШКЫуЗЈЁЂСЃзгШКЫуЗЈЕШЁЃ
1.3.2 вЦЖЏЛњЦїШЫЖЈЮЛЗНЗЈ
ЖЈЮЛЪЧШЗЖЈЛњЦїШЫдкЦфзївЕЛЗОГжаЫљДІЮЛжУЕФЙ§ГЬЁЃИќОпЬхЕиЫЕЪЧРћгУЯШбщЛЗОГЕиЭМаХЯЂЁЂЛњЦїШЫЮЛзЫЕФЕБЧАЙРМЦвдМАДЋИаЦїЕФЙлВтжЕЕШЪфШыаХЯЂЃЌОЙ§вЛЖЈЕФДІРэКЭБфЛЛЃЌВњЩњИќМгзМШЗЕФЖдЛњЦїШЫЕБЧАЮЛзЫЕФЙРМЦЁЃгІгУДЋИаЦїИажЊЕФаХЯЂЪЕЯжПЩППЕФЖЈЮЛЪЧзджївЦЖЏЛњЦїШЫзюЛљБОЁЂзюживЊЕФвЛЯюЙІФмЃЌвВЪЧвЦЖЏЛњЦїШЫбаОПжаБЖЪмЙизЂЁЂИЛгаЬєеНадЕФвЛИіживЊбаОПжїЬтЁЃЖЈЮЛЗНЗЈжївЊгаСНДѓРрЃЌвЛРрЪЧЯрЖдЖЈЮЛЃЌСэвЛРрЪЧОјЖдЖЈЮЛЁЃ
ЃЈ1ЃЉЯрЖдЖЈЮЛ
ЯрЖдЖЈЮЛАќРЈСНжжЖЈЮЛЗНЗЈЃКЙпадЕМКН[3]КЭВтОрЗЈЁЃЙпадЕМКНЭЈГЃЪЙгУМгЫйЖШМЦЁЂЭгТнвЧЁЂЕчДХТоХЬЁЂРяГЬМЦЕШДЋИаЦїЁЃРДздУмаЊИљДѓбЇЛњЦїШЫЪЕбщЪвМАBarshanКЭDurrant-Whyte[2]ЕФЪЕбщНсЙћБэУїМгЫйЖШМЦЖЈЮЛВЂВЛКмРэЯыЁЃЮЊСЫЛёЕУЮЛжУаХЯЂЃЌМгЫйЖШМЦБиаыЛ§ЗжСНДЮЃЌвђДЫЖдЦЏвЦЬиБ№УєИаЁЃдквЛАуЕФВйзїзДЬЌЯТМгЫйЖШМЦЕФМгЫйЖШКмаЁЃЌжЛга0.01g зѓгвЕФЪ§СПМЖЃЛШЛЖјжЛвЊМгЫйЖШМЦЯрЖдгкЫЎЦНЮЛжУЧуаБ0.5ЁуЃЌОЭЛсВњЩњЖдгІЪ§СПМЖЕФВЈЖЏЃЌвђДЫЛсДјРДНЯДѓЕФВтСПЮѓВюЁЃКЭМгЫйЖШМЦЯрБШЃЌЭгТнвЧФмЙЛЬсЙЉИќЮЊОЋШЗЕФКНЯђаХЯЂЃЛШЛЖјЃЌЭгТнвЧФмЙЛжБНгЬсЙЉЕФжЛЪЧНЧЫйЖШаХЯЂЃЌБиаыОЙ§вЛДЮЛ§ЗжВХФмЛёЕУКНЯђаХЯЂЃЌвђДЫОВЬЌЦЋВюЦЏвЦЖдЭгТнвЧЕФВтСПжЕгаКмДѓгАЯьЁЃДЫЭтЃЌРяГЬМЦЫфШЛОпгаСМКУЕФЖЬЦкОЋЖШЃЌЕЋГЄОрРыКЭГЄЪБМфЖЈЮЛЪБЃЌЛсгЩгкЮѓВюЕФВЛЖЯРлМгЃЌЖјбЯжигАЯьЖЈЮЛаЇЙћЁЃ
ЙувхВтОрЗЈРћгУЭтНчДЋИаЦїЩЈУшЛњЦїШЫЕМКНЛЗОГЃЌЬсШЁЛЗОГЬиеїаХЯЂВЂКЭЛЗОГЕиЭМЦЅХфЃЌгІгУЪ§ОнШкКЯЫуЗЈРДЬсИпЛњЦїШЫЕФЖЈЮЛОЋЖШЁЃЛњЦїШЫЖЈЮЛЙ§ГЬжаЃЌашвЊРћгУЭтНчЕФДЋИаЦїаХЯЂВЙГЅВтОрЗЈЕФЮѓВюЁЃЙуЗКгУгкЛњЦїШЫЖЈЮЛЕФЭтНчДЋИаЦїгаЭгТнвЧЁЂЕчДХТоХЬЁЂКьЭтДЋИаЦїЁЂГЌЩљВЈДЋИаЦїЁЂЩљФЩЁЂМЄЙтВтОрвЧЁЂЪгОѕЯЕЭГЕШЁЃ
ФПЧАРћгУЪвФкЛЗОГЕФздШЛЬиеїЪЕЯжЛњЦїШЫЕФЮЛжУЙРМЦБфЕУдНРДдНСїааЁЃЛњЦїШЫЖЈЮЛбаОПжаЃЌвЛАуРћгУЭтНчДЋИаЦїЬсШЁЕМКНЛЗОГЬиеїЃЌВЂКЭЛЗОГЕиЭМНјааЦЅХфвдаое§ВтОрЗЈЕФЮѓВюЁЃвђДЫРћгУЭтНчДЋИаЦїЖЈЮЛЛњЦїШЫЪБЃЌжївЊШЮЮёдкгкШчКЮЬсШЁЕМКНЛЗОГЕФЬиеїВЂКЭЛЗОГЕиЭМНјааЦЅХфЁЃдкЪвФкЛЗОГжаЃЌЧНБкЁЂзпРШЁЂЙеНЧЁЂУХЕШЬиеїБЛЙуЗКЕигУгкЛњЦїШЫЕФЖЈЮЛбаОПЃЌдкЛњЦїШЫЕФбаОПСьгђЛёЕУСЫЙуЗКЕФгІгУЃЌАќРЈЛњЦїШЫБмеЯ[4]ЁЂЪвФкЭтЛЗОГЬиеїЬсШЁ[5]ЁЂЕиЭМДДНЈ[6]КЭЖЈЮЛ[7]ЕШСьгђЁЃ
ЃЈ2ЃЉОјЖдЖЈЮЛ
ОјЖдЖЈЮЛВЛРћгУвдЧАЕФЮЛжУаХЯЂЃЌЭъШЋИљОнДЋИаЦїЕФЙлВтШЗЖЈЕБЧАЮЛжУЃЌвВЮоашжЊЕРЛњЦїШЫЕФГѕЪМЮЛжУЃЌЖдгкЛњЦїШЫЮЛжУЖЊЪЇКѓЕФЮЛжУЛжИДЗЧГЃгагУЁЃОјЖдЖЈЮЛОГЃвРРЕгкШчЯТЕФМИжжЗНЗЈЃКЕМКНаХБъЁЂжїЖЏЛђБЛЖЏБъЪЖЁЂЭМаЮЦЅХфЁЂЛљгкЮРаЧЕФЕМКНаХКХЃЈGPSЖЈЮЛЃЉЁЂИХТЪЖЈЮЛЕШ
ЛљгкаХБъЕФОјЖдЖЈЮЛОГЃВЩгУШ§ЪгОрЗЈ[8](Trilateration)КЭШ§ЪгНЧЗЈ[9](Triangulation)ЁЃБъЪЖЖЈЮЛЪЧвЛжжГЃМћЕФОјЖдЖЈЮЛММЪѕЁЃБъЪЖЪЧОпгаУїЯдЬиеїЕФЁЂФмБЛЛњЦїШЫДЋИаЦїЪЖБ№ЕФЬиЪтЮяЬхЁЃИљОнБъЪЖЕФВЛЭЌЃЌЗжЮЊЛљгкздШЛБъЪЖЖЈЮЛКЭЛљгкШЫЙЄБъЪЖЖЈЮЛЁЃЦфжаЃЌШЫЙЄБъЪЖЖЈЮЛММЪѕгІгУзюЮЊГЩЪьЁЃШЫЙЄБъЪЖЖЈЮЛЪЧдквЦЖЏЛњЦїШЫЕФЙЄзїЛЗОГРяЃЌШЫЮЊЕиЩшжУвЛаЉзјБъвбжЊЕФБъЪЖЃЌШчГЌЩљВЈЗЂЩфЦїЁЂМЄЙтЗДЩфАхЕШЃЌЛњЦїШЫЭЈЙ§ЖдБъЪЖЕФЬНВтРДШЗЖЈздЩэЕФЮЛжУЁЃЕиЭМЦЅХфжИвЦЖЏЛњЦїШЫЭЈЙ§здЩэЕФДЋИаЦїЬНВтжмЮЇЛЗОГЃЌВЂРћгУИажЊЕНЕФОжВПаХЯЂНјааОжВПЕиЭМЙЙдьЃЌШЛКѓНЋетИіОжВПЕиЭМгыдЄЯШДцДЂЕФЛЗОГЕиЭМНјааБШНЯЃЌШчЙћСНЕиЭМЯрЛЅЦЅХфЃЌОЭФмМЦЫуГіЛњЦїШЫдкЙЄзїЛЗОГжаЕФЮЛжУгыЗНЯђЁЃЛЗОГЕиЭМПЩвдЪЧ CAD ФЃаЭЃЌЛђепЪЧДЋИаЦїНЈСЂЕФФЃаЭЁЃЕиЭМЦЅХфЖЈЮЛЕФСНИіЙиМќММЪѕЪЧЕиЭМФЃаЭЕФНЈСЂКЭЦЅХфЫуЗЈЁЃGPS ЪЧвЛжжвдПеМфЮРаЧЮЊЛљДЁЕФЕМКНгыЖЈЮЛЯЕЭГЃЌдкжЧФмНЛЭЈЯЕЭГЃЈIntelligent Transportation SystemЃЌITSЃЉжаЛёЕУСЫЙуЗКЕФгІгУЁЃШЛЖјЃЌЕБГЕСООЙ§ИпТЅЁЂСжвёЕРЁЂЫэЕРЁЂСЂНЛЧХЕШЧјгђЪБЃЌУЏУмЕФЪївЖдьГЩЮРаЧаХКХЕФДѓЗљЖШЫЅМѕЃЌИпТЅзшЕВЛђепЗДЩфВПЗжЮРаЧаХКХЃЌДгЖјЕМжТ GPS НгЪеЛњВЛФмЙЛЖЈЮЛЛђепЖЈЮЛЮѓВюНЯДѓЃЌвђДЫФПЧАжївЊЪЧАб GPS КЭКНЮЛЭЦЫуЯЕЭГЃЈDead ReckoningЃЌDRЃЉМЏГЩдквЛЦ№ЃЌЪЕЯжГЕСОСЌајЁЂИпОЋЖШЕФЕМКНЖЈЮЛ[10,11,12]ЁЃ
1.3.3 вЦЖЏЛњЦїШЫSLAMММЪѕ
ЩЯЪРМЭ80 ФъДњЪБЕФSLAM ЮЪЬт[13]ЪЧвЛИізДЬЌЙРМЦЮЪЬтЃЌзюдчЪЧгЩSmith, Self КЭCheeseman [14]ЬсГіРДЕФЃЌЕБЪББЛГЦЮЊЁАПеМфзДЬЌВЛШЗЖЈадЕФЙРМЦЁБЁЃгЩДЫПЊЪМЕФШ§ЪЎФъ, ЧАвЛНзЖЮЕФЖўЪЎФъРДжївЊбаОПСЫЛљгкИХТЪЙРМЦЕФSLAMЃЌР§ШчРЉеЙПЈЖћТќТЫВЈЁЂСЃзгТЫВЈКЭзюДѓЫЦШЛЙРМЦЃЌетвЛНзЖЮУцСйзХЪ§ОнЙиСЊЮШЖЈадКЭЫуЗЈгааЇадЕФЬєеНЃЛжЎКѓЕФЪЎФъдђЪЧЫуЗЈЕФЗжЮіЃЌжївЊАќКЌЫуЗЈЕФПЩЙлВтадЁЂЪеСВадЁЂвЛжТадЮЪЬтЃЌТЫВЈЫуЗЈБфЕУШеЧїГЩЪьЁЃ
ЫцзХМЦЫуЛњЪгОѕЕФЗЂеЙЃЌдк2006ФъЪгОѕSLAMзїЮЊвЛИіаТЕФЗжжЇБЛЬсГіВЂЪмЕНбаОПепЕФЙизЂЃЌ2012ФъЪгОѕSLAMГЩЮЊЛњЦїШЫСьгђЕФШШЕуЮЪЬтЁЃЖјдкетИіЙ§ГЬжаЃЌSLAMж№НЅБЛЛЎЗжЮЊСНИіВПЗжЃЌЪзЯШЪЧЧАЖЫЃЌЭЈЙ§ДЋИаЦїЕФЙлВтРДЛёШЁЯрЙиаХЯЂЃЌжївЊЩцМАМЦЫуЛњЪгОѕМАаХКХДІРэЯрЙиРэТлЃЌШчЭМЯёЕФЬиеїЬсШЁгыЦЅХфЕШЃЛЦфДЮЪЧКѓЖЫЃЌЖдЛёШЁЕФаХЯЂЩИбЁгХЛЏВЂЕУЕНгааЇаХЯЂЃЌЦфжаМИКЮЁЂЭМТлЁЂгХЛЏЁЂИХТЪЙРМЦЕШЖМЪЧЫљКИЧЕФбаОПФкШн, жївЊЩцМАТЫВЈМАЗЧЯпадгХЛЏЃЌШчЛиЛЗМьВт[15]ЁЂЮЛзЫЭМгХЛЏ[16]ЁЃ
ЛљгкИХТЪЙРМЦЕФSLAMжївЊЕФгІгУЛЗОГЁЂЕиЭМБэЪОжївЊЪЧдкЖўЮЌПеМфЃЌЖјдкШ§ЮЌПеМфЕФРЉеЙгаЫљОжЯоЁЃЖдгкИУЮЪЬтЃЌвЛЗНУцашвЊЬсИпвЦЖЏЛњЦїШЫЖдЛЗОГЕФИаФмСІЃЌСэвЛЗНУцвВашвЊдкЯжгаИажЊФмСІЯожЦЯТЃЌЩшМЦИќКУЕФSLAMЯЕЭГЃЌвдЬсИпЯЕЭГЕФЪЕгУадЁЃЪгОѕSLAM[17]зюПЊЪМЪЙгУЕФЭтВПДЋИаЦїжївЊгаЩљФЩКЭМЄЙтРзДяЃЌОпгаЗжБцТЪИпЁЂПЙгадДИЩШХФмСІЧПЕШгХЕуЃЌЕЋЦфЙЄзїЪмЕНСЫЛЗОГЕФдМЪјЃЌШчGPS аХКХЁЃгЩгкSLAMжївЊдкЮДжЊЛЗОГЯТЭъГЩЃЌЮвУЧЮоДгЛёжЊЛЗОГаХЯЂЃЌЖјЯрЛњФмЙЛЛёШЁОЋзМжБЙлЕФЛЗОГаХЯЂЧвГЩБОЕЭЁЂЙІКФаЁЁЃЫцзХМЦЫуЛњЪгОѕЕФЙуЗКгІгУЃЌРћгУЯрЛњзїЮЊЭтВПДЋИаЦїГЩЮЊСЫЪгОѕSLAM баОПЕФжївЊЗНЯђЁЃИљОнЦфЙЄзїЗНЪНЕФВЛЭЌЃЌПЩЗжЮЊвдЯТШ§жжЃКЕЅФПЯрЛњЁЂЫЋФПЯрЛњЁЂRGB-DЯрЛњ[18]ЁЃ
вЦЖЏЛњЦїШЫЭЈЙ§ДЋИаЦїРДИажЊжмЮЇЛЗОГЃЌзюжеНЈСЂздМКЕФЛЗОГЕиЭМЁЃбаОПепЖдгкЕиЭМДцдкВЛЭЌашЧѓЃЌЙЙНЈЕиЭМжївЊЪЧЗўЮёгкЖЈЮЛЃЌдђашвЊНЈСЂгыШЮЮёвЊЧѓЖдгІЕФЕиЭМЁЃЙЙНЈЕФЕиЭМашТњзувдЯТШ§ЕувЊЧѓЃК
?ЕиЭМвЊФмзМШЗУшЪіЛЗОГЬиеї;
?дкгадыЩљИЩШХЕШВЛШЗЖЈаХЯЂЕФДцдкЯТзМШЗЙРМЦЛњЦїШЫЕФЮЛзЫ;
?ЕиЭМЕФЙЙНЈФмЙЛГфЗжеЙЪОЛЗОГЕФЬиеїаХЯЂЃЌИљОнВЛЭЌЕФШЮЮёашЧѓНЈСЂЯргІЕФЕиЭМФЃаЭ, ВЂБЃжЄSLAM ЕФОЋЖШЁЃдкБЃжЄОЋЖШЕФЭЌЪБЃЌОЁСПМѕЩйЕиЭМДДНЈЙ§ГЬжаЕФЪ§ОнСПЃЌРДЬсИпSLAM ЫуЗЈЕФЪЕЪБадЁЃ
ГЃгУЕФвЛаЉЛЗОГЕиЭМЕФЙЙНЈЗНЗЈ[19]га2DеЄИёЕиЭМЁЂ2DЭиЦЫЕиЭМЁЂ3DЕудЦЕиЭМЁЂ3D ЭјИёЕиЭМЃЌвдМАНќСНФъИеаЫЦ№ЕФАЫВцЪїЃЌИУЗНЗЈеМгУДцДЂПеМфаЁЧвФмЙЛЪЕЯжЖЏЬЌНЈФЃЃЌдкЪЕЪБадЩЯгХгк3D ЕудЦЕиЭМ[20]ЁЃ
1.3.4 ЛљгкЩюЖШбЇЯАЕФгявхЗжИю
дкЛњЦїЪгОѕСьгђЃЌЫцЛњЩСжЗжРргыЮЦРэЛљдЊЩСжЗжРрЪЧЭМЯёгявхЗжИюЕФДЋЭГзїЗЈЁЃзюГѕЕФЗжИюДѓЖМЛљгкМђЕЅЕФЯёЫиМЖБ№ЕФЁАуажЕЗЈЁБЃЌЫцзХЗжИюММЪѕЕФВЛЖЯИФНјЃЌЛљгкЁАЭМЛЎЗжЁБЕФЗжИюЗЈИФЩЦаЇЙћУїЯдЃЌОЋЖШНЯИпЃЌГЩЮЊОЕфЕФДЋЭГгявхЗжИюЗНЗЈжЎвЛЁЃдкЩюЖШбЇЯАЫуЗЈБЛДДдьадЕив§ШыЛњЦїЪгОѕСьгђКѓЃЌгявхЗжИю[21,22]ЮЪЬтгаСЫЭЛЦЦадНјеЙЃЌШчШЋОэЛ§ЩёОЭјТчЛљгкЖрЭМбЇЯАгыПщЖдНЧдМЪјЕФШЋМрЖНгявхЗжИюЗНЗЈЁЂЛљгкФЃаЭЦРЙРЕФШѕМрЖНгявхЗжИюЗНЗЈЕШаэЖрЛљгкЩёОЭјТчбЕСЗЕФгявхЗжИюЗНЗЈЯрМЬГіЯжЃЌЗжИюОЋЖШВЛЖЯЬсИпЁЃ
ШЋОэЛ§ЩёОЭјТчЃЈFCNЃЉЪЧФПЧАгявхЗжИюзюГЃгУЕФЭјТчЃЌвВЪЧЩюЖШбЇЯАдкЭМЯёгявхЗжИюШЮЮёЩЯЕФПЊДДадЙЄзїЁЃЩюЖШОэЛ§ЩёОЭјТчФЃаЭЃЈCNNЃЉЪЧЭМЯёМЖБ№гявхРэНтЕФРћЦїЃЌЖјFCNдђЪЧЛљгкCNNЪЕЯжЕФЯёЫиМЖБ№ЕФгявхРэНтЃЌЪЪгУгкЭМЯёгявхЗжИюЁЂБпдЕМьВтЕШгІгУГЁОАЁЃFCNПЩвдНгЪмШЮвтГпДчЕФЪфШыЭМЯёЃЌВЩгУЗДОэЛ§ВуЖдзюКѓвЛИіОэЛ§ВуЕФЬиеїЭМНјааЩЯВЩбљЃЌЪЙЫќЛжИДЕНгыЪфШыЭМЯёЯрЭЌЕФГпДчЃЌДгЖјПЩвдЖдУПИіЯёЫиЖМВњЩњвЛИідЄВтЃЌЭЌЪББЃСєдЪМЪфШыЭМЯёжаЕФПеМфаХЯЂЃЌзюКѓдкЩЯВЩбљЕФЬиеїЭМЩЯНјааж№ЯёЫиЗжРрЁЃ
1.4 ЯюФПбаОПФкШнМАвтвх
ЩчЛсРЯСфЛЏЮЪЬтИќМгДпЩњСЫЗўЮёЛњЦїШЫГЩЮЊбаОПШШЕуЃЌжЧФмЕМУЄЦНЬЈЮЊУЄШЫЬсЙЉЩњЛюЗўЮёЪЧЦфжаживЊЗНУцЃЌЦфЩцМАЕНЕФЙиМќЮЪЬтАќРЈМлИёЁЂАВШЋадКЭЛЅЖЏадЁЃдкМлИёЗНУцЃЌЕМУЄЪжеШЮовЩЪЧзюЕЭЕФЃЌЕЋЪЧдкАВШЋадКЭЛЅЖЏадЗНУцЖМБШНЯВюЃЛдкЛЅЖЏадЗНУцЃЌЕМУЄШЎНЯКУЃЌЕЋЪЧМлИёАКЙѓЃЛгкДЫЯрБШЃЌЮвУЧЬсГіЕФжЧФмЕМУЄЦНЬЈПЩвдНЯгХЕФИјГіНтОіЗНАИЁЃ
дкЖдашЧѓКЭбаОПЯжзДЗжЮіЕФЛљДЁЩЯЃЌБОЮФИјГіСЫвЛжжЛљгкгявхVIO-SLAMЕФЖрДЋИаЦїШкКЯЕУЖЏЬЌНЈФЃзджїЕМУЄЦНЬЈЩшМЦЗНАИЁЃжївЊВЩгУЕЅФПЩуЯёЛњКЭЙпЕМЯЕЭГIMUЯрНсКЯЕФЗНЪНЃЌРћгУЕЅФПORB-SLAMЫуЗЈЪЕЯжЮДжЊЛЗОГжаЕФЕиЭМЙЙНЈгыЪЕЪБЖЈЮЛЃЌРћгУЛљгкЩюЖШЩёОЭјТчЕФгявхЗжИюЫуЗЈЪЕЯжГЃМћГЁОАЯТЕиЭМЕФгявхБъзЂЁЃ
1.5 ВЮПМЮФЯз
[1]АзОЎСМУї. ЛњЦїШЫЙЄГЬ. ПЦбЇГіАцЩч. 2001.
[2]Jensfelt P, Kristensen S. Active global localization for a mobile robot using multiple hypothesis tracking [J]. IEEE Transactions on Robotics and Automation, 2001, 17(5): 748-759.
[3]Li Bowen, Yao Danya. Low-cost MEMS IMU navigation positioning method for land vehicle [J]. Journal of Chinese Inertial Technology,2014,22(6):719-723.
[4]Martinez J L, Pozo-Ruz A, Pedraza S, et al. Object following and obstacle avoidance using a laser scanner in the outdoor mobile robot Auriga-ІС. in: Proceedings of the 1998 IEEE/RSJ International Conference on Intelligent Robots and Systems. Canada. 1998. 204-209.
[5]Roumeliotis S I, Bekey G A. SEGMENTS: a layered, dual-Kalman filter algorithm for indoor feature extraction. in: Proceedings of the 2000 IEEE/RSJ International Conference on Intelligent Robots and Systems. 2000. 454-461.
[6]Kwon Y D, Lee J S. A stochastic map building method for mobile robot using 2-D laser range finder. Autonomous Robots, 1999, 7(2): 187-200.
[7]Zhang L, Ghosh B K. Line segment based map building and localization using 2D laser rangefinder. in: Proceedings of the 2000 IEEE International Conference on Robotics and Automation. San Francisco. April 2000. 2538-543.
[8]Figueroa J F, Mahajan A. A robust navigation system for autonomous vehicles using ultrasonics. Control Engineering Practice. 1994, 2(1): 49-59.
[9]McGillem C, Rappaport T. Infra-red location system for navigation of autonomous vehicles. in: Proceedings of the 1988 IEEE International Conference on Robotics and Automation. Philadelphia, PA. 1988. 1236-1238.
[10]Zhang L, Ghosh B K. Line segment based map building and localization using 2D laser rangefinder. in: Proceedings of the 2000 IEEE International Conference on Robotics and Automation. San Francisco. April 2000. 2538-2543.
[11]ЙўЬиРћ.МЦЫуЛњЪгОѕжаЕФЖрЪгЭММИКЮ[M]. АВЛеДѓбЇГіАцЩчЃЌ2002ЃК158-256.
[12]Endres F, Hess J, Sturm J, et al. 3-D mapping with an RGB-D camera[J]. IEEE Transactions on Robotics, 2014, 30(1):177-187.
[13]A. Elfes and H. Moravec, High resolution maps from wide angle sonar, in Proceedings of the 1985 IEEE International Conference on Robotics and Automation, 116-121, 1985.
[14]Bar-Shalom Y, Daum F, Huang J. The probabilistic data association filter. IEEE Control Systems, 2009, 29(6):82-100.
[15]Latif Y, Cadena C, Neira J. Robust loop closing over time for pose graph SLAM. The International Journal of Robotics Research, 2013, 32(14): 1611-1626.
[16]Carlone L, Censi A, Dellaert F. Selecting good measurements via relaxation: A convex approach for robust estimation over graphs. Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2014). Chicago, IL, USA. 2014. 2667-2674.
[17]SЈЙnderhauf N, Protzel P. Towards a robust back-end for pose graph SLAM. Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA). Saint Paul, MN, USA. 2012. 1254-1261.
[18]Bailey T, Durrant-Whyte H. Simultaneous localization and mapping (SLAM): Part II. IEEE Robotics & Automation Magazine, 2006, 13(3): 108-117.
[19]Beeson P, Modayil J, Kuipers B. Factoring the mapping problem: Mobile robot map-building in the hybrid spatial semantic hierarchy. The International Journal of Robotics Research, 2010, 29(4): 428-459.
[20]Hornung A, Wurm KM, Bennewitz M, et al. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Autonomous Robots, 2013, 34(3): 189-206.
[21]еХчц.ЭМЯёгявхЗжИюЫуЗЈбаОП[D].ЩЯКЃЃКИДЕЉДѓбЇ,2014.
[22]ВмХЪ,ЧЎОќКЦ,ГТжЧ,ЕШ.ЛљгкЭМЯёЗжВуЪїЕФЭМЯёгявхЗжИюЗНЗЈ[J].МЦЫуЛњгІгУбаОП,2017.
2. ЯюФПЗНАИ
ЛљгкVIO-SLAMЕФШЋЯђзджївЦЖЏЦНЬЈжївЊРћгУЭМЯёДІРэКЭТЗОЖЙцЛЎЕФЯрЙиРэТлЃЌЪЕЯжЖдЮДжЊЛЗОГжаЕФГЁОАаХЯЂНјааЬиеїЬсШЁЁЂЬиеїЦЅХфЁЂБеЛЗМьВтЕШЃЌВЂНјааЕиЭМФЃаЭЕФЙЙНЈЃЛШЛКѓЃЌЪЕЪБНјааТЗОЖЙцЛЎЃЌЕНДядЄЦкФПЕФЕиЁЃбаОПЙЄзїАќКЌвдЯТШ§ИіЗНУцЃКвЦЖЏЯЕЭГЩшМЦЁЂПижЦЯЕЭГДюНЈЁЂОіВпЯЕЭГДюНЈЁЃ
ЦфжаЃЌдкОіВпЯЕЭГжаЃЌашвЊЩюШыбаОПIMUКЭЩуЯёЭЗСНжжДЋИаЦїЕФЪ§ОнШкКЯЗНЪНЃЌашвЊПМТЧЛЗОГЕФЪЪгІадЃЌбЁдёеМгХЕФФЃаЭМмЙЙЃЌзХжиПМТЧЧАЖЫЬиеїЬсШЁМАБеЛЗМьВтЕФзМШЗадЃЌЛљгкЩюЖШбЇЯАЗНЗЈЖдЭМЯёНјаагявхЗжИюЃЌНЋвЛаЉвбжЊЮяЬхгыдБОКСЮовтвхЕФЕудЦЕиЭМЯрШкКЯзХжиПМТЧЪЕЪБадКЭХаЖЯзМШЗадЃЛвЦЖЏЯЕЭГЩшМЦЗНУцЃЌашвЊЭъГЩЖдвЦЖЏЦНЬЈЕФНЈФЃКЭЪмСІЗжЮіЙЄзїЃЌЭЌЪБПМТЧЕННсЙЙЕФЮШЖЈадКЭВЛЭЌГЁОАЕФЪЪгІадЃЌашвЊЖдЦНЬЈЭтаЮНјааКЯРэЕФВМОжКЭгХЛЏЃЌБЃжЄАВШЋадКЭУРЙлЃЛдкПижЦЯЕЭГДюНЈЙ§ГЬжаЃЌашвЊПМТЧБеЛЗПижЦОЋЖШЃЌЕїНкPIDВЮЪ§ЃЌвдБЃжЄПижЦЯЕЭГЕФНЁзГадЁЃЭЈЙ§ЩшМЦКЯРэЕФММЪѕТЗЯпКЭбаОПЗНАИЃЌПЊЗЂГівЛИігявхНЛЛЅЕФжЧФмвЦЖЏЦНЬЈЁЃ
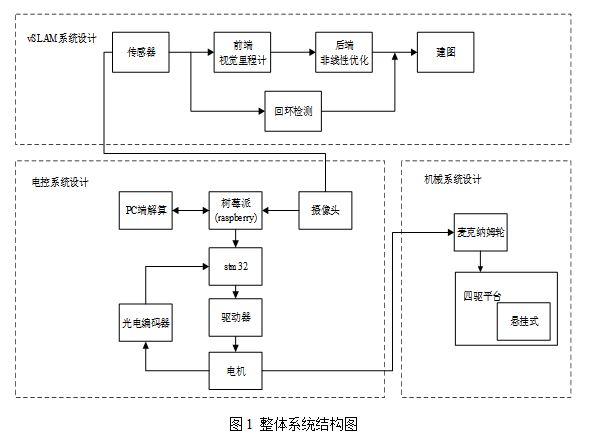
НгЯТРДЃЌЗжБ№еыЖдЩЯЪіШ§ИіЗНУцЕФЮЪЬтЯЕЭГеЙПЊТлЪіЃЌИјГіУПИіВПЗжЕФОпЬхММЪѕТЗЯпЁЃ
2.1ОіВпЯЕЭГЩшМЦ
ЃЈ1ЃЉSLAMСїГЬ
SLAMжївЊСїГЬЗжЮЊЃКДЋИаЦїаХЯЂЛёШЁЃЌЯрЛњЭМЯёаХЯЂЕФЖСШЁЁЂДЋЪфКЭдЄДІРэЃЌIMUЙпадДЋИаЦїЕШаХЯЂЕУЖСШЁКЭЭЌВНЃЛЪгОѕРяГЬМЦЃЌЙРЫуЯрСкЭМЯёМфЯрЛњЕУдЫЖЏЃЌЭЈЙ§IMUФкжУЕФЭгТнвЧКЭМгЫйЖШМЦПЩвдВтСПНЧЫйЖШКЭМгЫйЖШЃЌШкКЯШЗЖЈЮЛзЫЃЛЛиЛЗМьВтЃЌХаЖЯЛњЦїШЫЪЧЗёдјОЕНДяЙ§ЯШЧАЕУЮЛжУЃЛКѓЖЫгХЛЏЃЌНгЪмВЛЭЌЪБПЬЪгОѕРяГЬМЦВтСПЕФЮЛзЫКЭЛиЛЗМьВтЕУЕНЕУаХЯЂЃЌНјаагХЛЏЕУЕНШЋОжвЛжТЕУЙьМЃКЭЕиЭМЁЃSLAMСїГЬЭМШчЭМ2ЫљЪОЃК
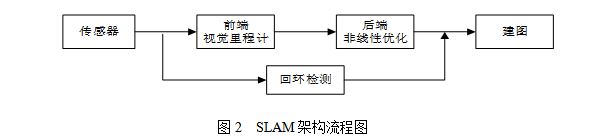
ВЩгУЕЅФПЪгОѕORB-SLAMЫуЗЈНјааИњзйЁЂЕиЭМЙЙНЈКЭБеЛЗПижЦЃЌИУЫуЗЈЩшМЦЕФОпЬхЪЕЪЉЙ§ГЬШчЯТЃК
ЂйЭЈЙ§ЭЈЙ§еХе§гбЦхХЬБъЖЈЗЈЖдЩуЯёЭЗЕФЛћБфВЮЪ§НјааБъЖЈЃЌгУБъЖЈКУЕФВЮЪ§ЖдУПвЛжЁЭМЯёНјааЛћБфаое§ЃЌШЛКѓЖдЭМЯёНјааИпЫЙТЫВЈЃЌЯћГ§дыЩљЃЌЮЊЬиеїЕуЬсШЁзізМБИЁЃ
ЂкЬсШЁЭМЯёЕФORBЬиеїЕуЃЌМДВЩгУОпгаЗНЯђаХЯЂЕФЖрГпЖШFAST ЬиеїЕуЃЌгУ32ИізжНк256ЮЛБШЬиЪ§ЕФBRIEFзїЮЊУшЪіЗћЃЌМДвЛИіЬиеїЕугУвЛИі256ЮЛЕФ0Лђ1БэЪОЃЌетбљОЭЙЙГЩСЫ256ЮЌПеМфЕФЬиеїЕуПеМфЁЃ
ЂлРћгУДЪДќММЪѕЖдЬиеїЕуПеМфНјааЗжРрЃЌЗжЮЊM*NВуЃЌЭЈЙ§ККУїОрРыОЭПЩвдАбЬсШЁЕФORB ЬиеїЕудкПеМфжаНјааЗжРрЁЃ
ЂмЧАКѓжЁЭМЯёжаЕФЬиеїЕуОЙ§ЗжРрОЭПЩвддкВЛЭЌЕФПеМфЮЛжУЩЯНјааПьЫйЦЅХфЃЌЭЈЙ§ЦЅХфЬиеїЕуТњзуЕФМЋЯпдМЪјЙиЯЕОЭПЩвдНЈСЂЧАКѓжЁЭМЯёМИКЮЙиЯЕЃЌДгЖјЕУЕНЯрЛњЕФЪЕЪБЮЛзЫаХЯЂЁЃ
ЂнЖдУПвЛжЁЭМЯёНјааЩЯЪіВйзїЃЌДцДЂЙиМќЕуКЭЙиМќжЁЃЌДгЖјЙЙНЈЛЗОГЕиЭМаХЯЂЃЌЖдаТдіМгЕФЙиМќЕуКЭЙиМќжЁдквбНЈСЂЕФЕиЭМжаЫбЫїЦЅХфЪЕЯжжиЖЈЮЛЛђепБеЛЗМьВтЁЃдкећИіSLAMЙ§ГЬжаЃЌЭЈЙ§ЙтЪјЦНВюЗЈВЛЖЯЖдЮѓВюНјаааое§ЃЌЕБМьВтЕНБеЛЗЪБЃЌЖдећИіЕиЭМНјаагХЛЏЃЌДгЖјЬсИпSLAMЖЈЮЛЕФОЋЖШЁЃ
ЃЈ2ЃЉгявхЗжИю
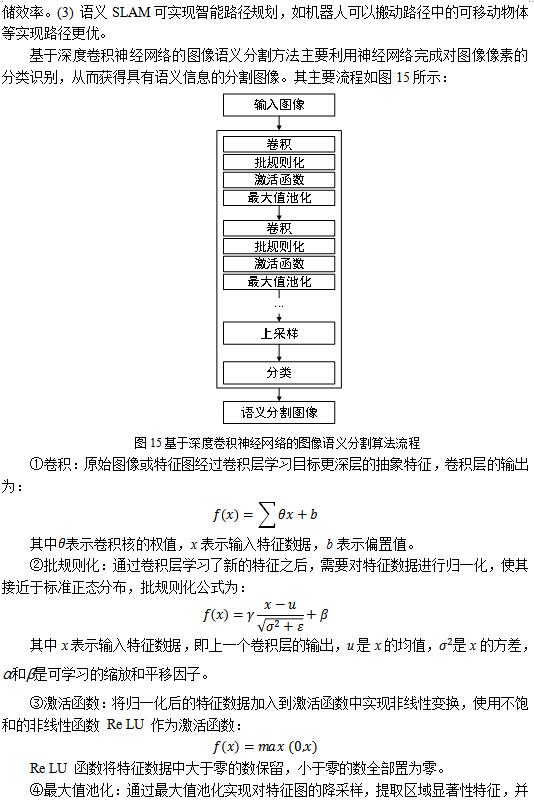
НЋвЛаЉвбжЊЮяЬхгыдБОКСЮовтвхЕФЕудЦЕиЭМЯрШкКЯЃЌЭЈЙ§злКЯЩЯЪіЭМЯёађСаЕФЕудЦКЭдЄЯШМЦЫуЕФФПБъФЃаЭРДЖдЕиЭМжаЫљАќКЌЕФФПБъНјаагявхБъзЂЁЃБОЯюФПВЩгУCNNНјааЭМЯёгявхЗжИюЁЃ
вЛАуРДЫЕЃЌCNN ЕФЛљБОНсЙЙАќКЌвдЯТМИИіВПЗжЃКОэЛ§ВуЃЌГиЛЏВуЃЌЗЧЯпадБфЛЛВуКЭШЋСЌНгВуЁЃCNN ЪЧвЛИіЖрВуЕФЩёОЭјТчЃЌЫќЕФУПвЛВуЖМгЩЖрИіЬиеїЭМ(Feature Map)зщГЩЃЌЖјУПИіЬиеїЭМжаЕФЕуДњБэвЛИіЩёОдЊЁЃ
ЂйОэЛ§ЃЈConvolutionsЃЉЃКдкУПИіОэЛ§ВужаЃЌЪфШыЬиеїЭМЭЈЙ§гыИУВуЕФОэЛ§КЫНјааОэЛ§ВйзїЕУЕНЪфГіЬиеїЭМЁЃ ЪфШыГпЖШДѓаЁЮЊ32*32ЕФЭМЯёОгЩ6ИіФЃАхДѓаЁЮЊ5*5ЕФОэЛ§КЫОэЛ§жЎКѓЃЌЕУЕН6ИіГпЖШДѓаЁЮЊ 28*28ЕФЬиеїЭМЁЃИУЙ§ГЬПЩвдПДзїЪЧвЛжжЭМЯёТЫВЈЃЌЪфШыЬиеїЭМжаЕФОжВПЩёОдЊвРОнОэЛ§ФЃАхжаЕФВЮЪ§НјааМгШЈЧѓКЭЃЌдйМгЩЯЦЋжУЕУЕНЪфГіЩёОдЊЕФЪ§жЕЁЃЯрБШгкШЋСЌНгЭјТчЃЌОэЛ§ЩёОЭјТчжаУПИіЬиеїЭМЩЯЕФЩёОдЊЙВЯэЭЌвЛзщШЈжЕЃЌвђЖјДѓДѓМѕЩйСЫЭјТчВЮЪ§ЃЌНЕЕЭСЫЭјТчФЃаЭЕФИДдгЖШЁЃ
ЂкГиЛЏЃЈPoolingЃЉЃКГиЛЏВуСЌНгдкОэЛ§ВужЎКѓЃЌЫќЕФЬиеїЭМИіЪ§гыЩЯвЛВуЕФЬиеїЭМИіЪ§БЃГжвЛжТЃЌВЂЧввЛвЛЖдгІЁЃгЩОэЛ§ВуЪфГіЕФ6ИіГпЖШДѓаЁЮЊ28*28ЕФЬиеїЭМЃЌОЙ§2*2ДѓаЁЕФГиЛЏФЃАхНјааНЕВЩбљЃЌЕУЕН6Иі14*14ДѓаЁЕФЬиеїЭМЁЃНЕВЩбљЕФЗНЪНвЛАуЪЧбЁШЁГиЛЏЧјгђФкзюДѓЕФЪ§ЃЈзюДѓжЕГиЛЏЃЉЃЌЛђепЧјгђФкЕФЦНОљЪ§ЃЈОљжЕГиЛЏЃЉЁЃДЫЭтЃЌвВгаЫцЛњГиЛЏКЭН№зжЫўГиЛЏЕШЗНЗЈЁЃГиЛЏВуЭЈЙ§НЕВЩбљВйзїВЛНіЬсШЁСЫПеМфВЛБфадЬиеїЃЌДяЕНСЫЖўДЮбЇЯАЕФаЇЙћЃЌЖјЧвМѕЩйЩёОдЊЪ§СПЃЌНЕЕЭСЫЭјТчФЃаЭЕФМЦЫуСПЁЃ
ЂлЗЧЯпадБфЛЛЃКОэЛ§ВйзїЪЧЖрЯюЪНМгШЈЧѓКЭЕФМЦЫуЗНЗЈЃЌЪєгкЯпадБфЛЛЁЃЖјИДдгЕФЗжРрЪЖБ№ШЮЮёЭљЭљашвЊЗЧЯпадКЏЪ§ФтКЯЃЌЫљвдОэЛ§ЩёОЭјТчдкУПИіОэЛ§ВужЎКѓЖМвЊМгШыЗЧЯпадБфЛЛКЏЪ§ЃЌвВГЦМЄЛюКЏЪ§ЁЃДЋЭГЕФCNNжаЫљЪЙгУЕФМЄЛюКЏЪ§ЪЧБЅКЭЗЧЯпадКЏЪ§ sigmoidКЏЪ§КЭtanhКЏЪ§ЁЃШЛЖјЃЌЯрНЯгкБЅКЭЗЧЯпадКЏЪ§ЃЌВЛБЅКЭЕФЗЧЯпадКЏЪ§ЃЌШчsoftplus КЏЪ§КЭReLUКЏЪ§ЕШФмЙЛЛКНтЭјТчбЕСЗЪБЬнЖШЯћЪЇЕФЮЪЬтЃЌМгПьЭјТчбЕСЗЫйЖШЁЃБОЩшМЦжаВЩгУReLUКЏЪ§зїЮЊМЄЛюКЏЪ§ЁЃ
ЂмШЋСЌНгЃЈFull connectionЃЉЃКгЩГиЛЏВуЪфГі120ЮЌЕФЬиеїЯђСПЃЌОЙ§84зщШЈжЕЯђСПНјааМгШЈЧѓКЭЃЌЕУЕН84ЮЌЕФЪфГіЬиеїЁЃШЋСЌНгВуЭЈЙ§гыЧАвЛВуЫљгаЩёОдЊЯрСЌЛёШЁЭМЯёЕФШЋОжаХЯЂЃЌвдДЫбЇЯАГіЭМЯёжаОпгаРрБ№ЧјЗжадЕФЬиеїЁЃдкзюКѓвЛИіШЋСЌНгВужЎКѓНгШывЛИіЗжРрВуЃЌЭъГЩЖдЭМЯёЕФЪЖБ№ЁЃ
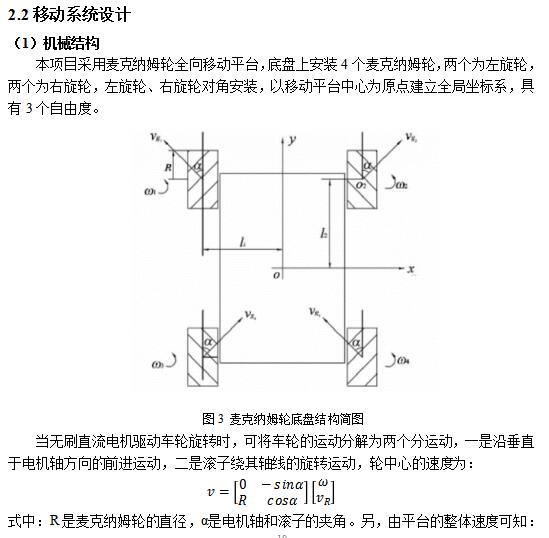

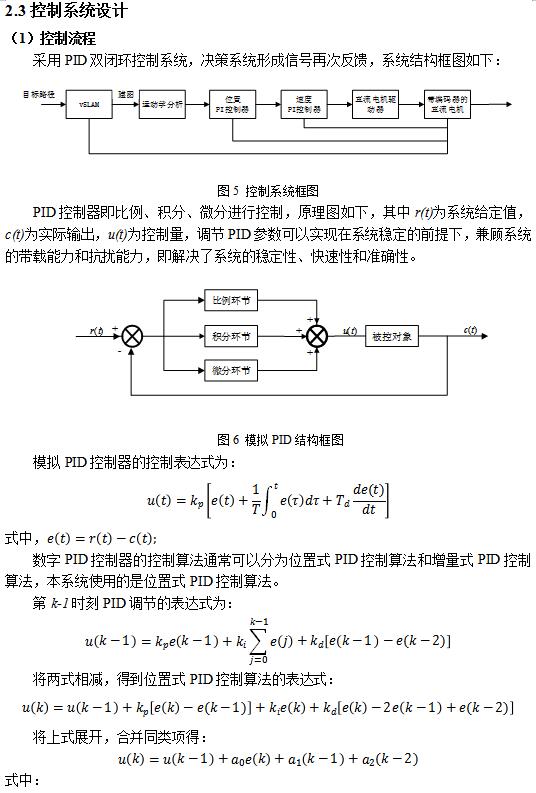
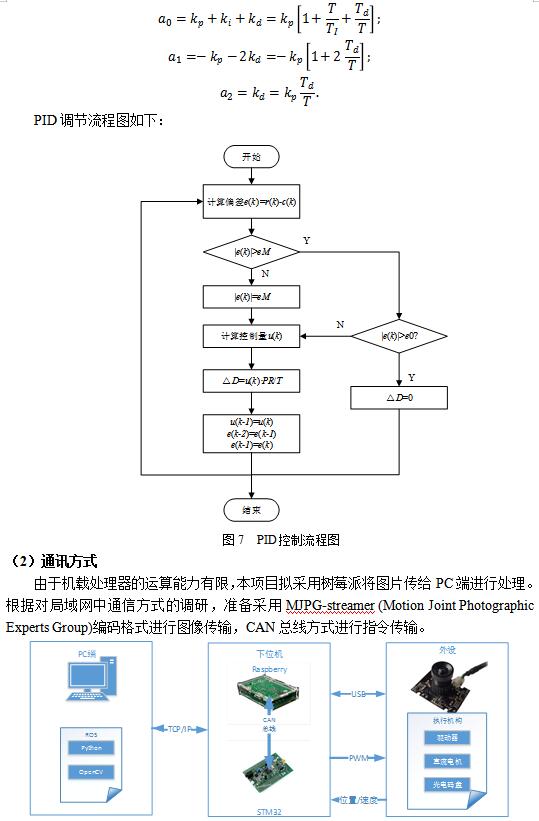
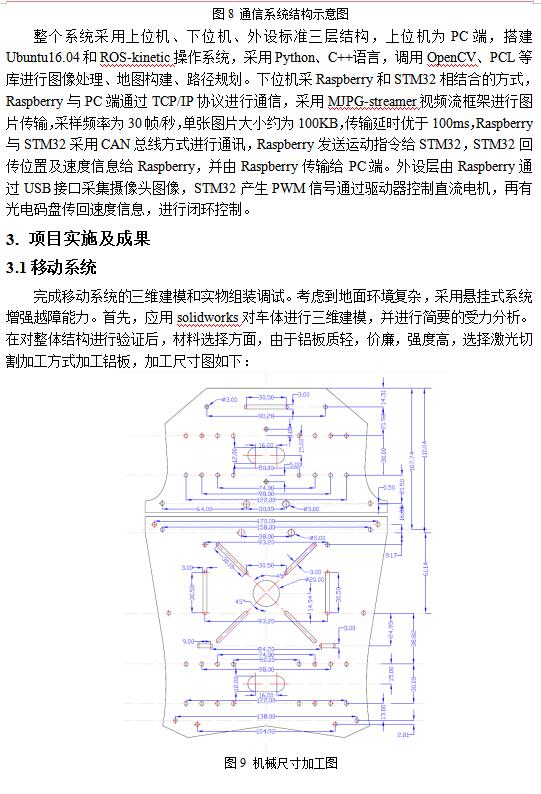

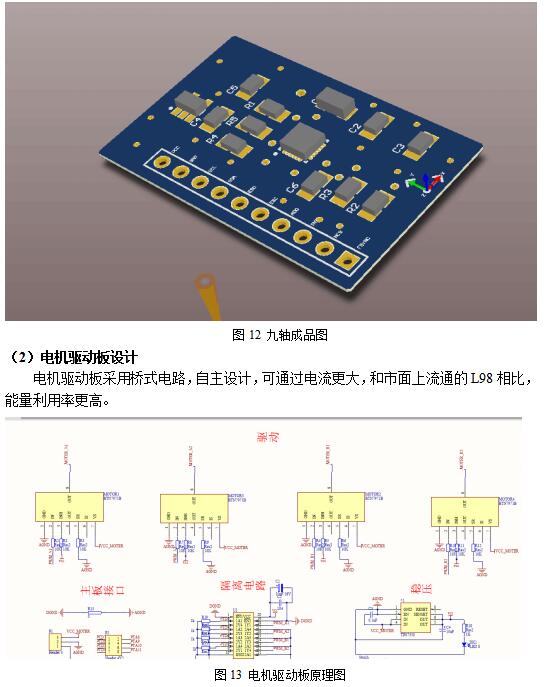


ЛљгкЩЯЪіЩшМЦКЭЪЕЪЉЃЌПЊеЙСЫВПЗжзлКЯбщжЄЪдбщЃЌШчЭМ16-18ЫљЪОЃЌЗжБ№ЪЧЕМКНТЗОЖЙцЛЎЁЂЕиЭМЙЙНЈКЭЪдбщЙ§ГЬЕФеЙЪОЁЃГѕВНЕФЪдбщНсЙћЛљБОЪЕЯжСЫдЄЦкФПБъЃЌПЩвдЭъГЩзджїНЈЭМЁЂЕМКНЁЂТЗОЖЙцЛЎКЭдЫЖЏПижЦЁЃгЩгкЫљВЩгУЕФДІРэЦїЫуСІгаЯоЃЌдкМЦЫуКЭвЦЖЏЫйЖШЗНУцЛЙгавЛЖЈЕФОжЯоЃЌЯТвЛВНЕФЙЄзїНЋЩюШыНјааЫуЗЈЕФгХЛЏЃЌВЂЭъЩЦгВМўЕФЩшМЦЃЌ
4. баОПНсТл
ОбаОПЃЌВЩгУШЫЙЄжЧФмММЪѕЕФЕМУЄЦНЬЈадФмЩЯФмЙЛДњЬцЯжгаЕФЕМУЄЪжеШЁЂЕМУЄШЎЕШЭъГЩЕМУЄШЮЮёЃЌФмЙЛдкБЃжЄАВШЋЕФЧАЬсЯТдіЧПНЛЛЅадЁЃ
ЩюЖШбЇЯАгыSLAM ЕФНсКЯдквЛЖЈГЬЖШЩЯИФЩЦСЫЪгОѕРяГЬМЦКЭГЁОАЪЖБ№ЕШгЩгкЪжЙЄЩшМЦЬиеїЖјДјРДЕФгІгУОжЯоадЃЌЭЌЪБЖдИпВугявхПьЫйзМШЗЩњГЩвдМАЛњЦїШЫжЊЪЖПтЙЙНЈвВВњЩњСЫживЊгАЯьЃЌДгЖјЧБдкЬсИпСЫЛњЦїШЫЕФбЇЯАФмСІКЭжЧФмЛЏЫЎЦНЁЃ
ЩюЖШбЇЯАЗНЗЈвђЦфСМКУЕФздЪЪгІЁЂздбЇЯАФмСІдкЕиЭМЙЙНЈЁЂЪЕЪБЖЈЮЛЁЂгявхЗжИюЕШЗНУцЖМгаКмКУЕФгІгУЃЌЕЋЪЧФПЧАжЛЪЧдкзгФЃПщЩЯНјаагІгУЃЌШчКЮНЋЩюЖШбЇЯАЫуЗЈгІгУЕНећИіSLAMЯЕЭГШдШЛжЕЕУЩюШыбаОПЁЃ
БОбаОПЭъГЩСЫЛљгкгявхVIO-SLAMЕФЖрДЋИаЦїШкКЯЕУЖЏЬЌНЈФЃзджїЕМУЄЦНЬЈЩшМЦКЭГѕВНЪЕЪЉЃЌГѕВНЕФЪдбщНсЙћжЄУїКЭЫљЬсЩшМЦЫМТЗЕФПЩааадЃЌдкЦНЬЈЫуСІЁЂЫуЗЈгХЛЏКЭгВМўгХЛЏЩшМЦЗНУцгаД§НјвЛВНЩюШыбаОПЁЃ
ЗжЯэШУИќЖрШЫПДЕН 
ЭЦМідФЖС
ДЋУНЭЦМі
 @УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад
@УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ
ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
ЯрЙиаТЮХ
- дЦжЊЩљЃКздШЛгябдДІРэЫуЗЈдквНСЦСьгђТЪЯШгІгУ
- ЬНбАЛљгкгявхМьЫїЪЕЯжжЊЪЖЗЂЯжЕФНтОіжЎЕР
- ЭЌЖмПЦММеХаТВЈЃКвдММЪѕЮЊКЫаФЭкОђжЧФмЗчПиаТМлжЕ
- жЧФмПЭЗўгІЕБЁАЩЦНтШЫвтЁБ
- КЃСПаТЮХаХЯЂДІРэжаЕФгявхНЧЩЋБъзЂбаОП
- ШУШЫБРРЃЕФжЧФмПЭЗўГЦЕУЩЯжЧФмТ№
- ШШЕугыФбЕуВЂДц зЈМвШШвщгябджЧФмЮДРДЗЂеЙ
- жЧФмВњЦЗЮЊОгМвбјРЯЬсЙЉШеГЃЩњЛюКЭНЁПЕЪ§Он
- ЛљгкШЫУёЭјаТЮХБъЬтЕФЖЬЮФБОздЖЏЗжРрбаОП
- ЛљгкK-MeansЫуЗЈЕФаТЮХЮФБОФкШнЙ§ТЫ
ПЭЛЇЖЫЯТди
ШЫУёШеБЈЩчИХПі | ЙигкШЫУёЭј | БЈЩчеаЦИ | еаЦИгЂВХ | ЙуИцЗўЮё | КЯзїМгУЫ | ЙЉИхЗўЮё | Ъ§ОнЗўЮё | ЭјеОЩљУї | ЭјеОТЩЪІ | аХЯЂБЃЛЄ | СЊЯЕЮвУЧ
ЗўЮёгЪЯфЃКkf@people.cn ЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-65363263 ОйБЈгЪЯфЃКjubao@people.cn
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170001 | діжЕЕчаХвЕЮёОгЊаэПЩжЄB1-20060139
ЙуВЅЕчЪгНкФПжЦзїОгЊаэПЩжЄЃЈЙуУНЃЉзжЕк172КХ | ЛЅСЊЭјвЉЦЗаХЯЂЗўЮёзЪИёжЄЪщЃЈОЉЃЉ-ЗЧОгЊад-2016-0098
аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0104065 | ЭјТчЮФЛЏОгЊаэПЩжЄ ОЉЭјЮФ[2020]5494-1075КХ | ЭјТчГіАцЗўЮёаэПЩжЄЃЈОЉЃЉзж121КХ | ОЉICPжЄ000006КХ | ОЉЙЋЭјАВБИ11000002000008КХ
ШЫ Уё Эј Ац ШЈ Ыљ га ЃЌЮД О Ъщ Уц Ък ШЈ Нћ жЙ ЪЙ гУ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЦРТл

-
ЙизЂ
ЮЂаХЮЂВЉПьЪж
 ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
 БЈЕРШЋЧђ ДЋВЅжаЙњ
БЈЕРШЋЧђ ДЋВЅжаЙњ
 ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
