




















基于人民网新闻标题的短文本自动分类研究
摘要:
自动文本分类技术将人类从繁琐的手工分类中解放出来,使分类任务变的更为高效,为进一步的数据挖掘和分析奠定基础。对于新闻来说,简短的新闻标题是新闻内容的高度总结,针对短文本的分类研究一直是自动文本分类技术的研究热点。本文基于人民网观点频道中的数据,采用深度学习中的卷积神经网络(CNN)和循环神经网络中的长短时记忆模型(LSTM)组合起来,捕捉短文本表达的语义,对短文本自动文本分类进行智能化实现,为新闻网站的新闻分类实现提供参考。
关键字:深度学习,LSTM,CNN,新闻,文本分类
一、引言
新闻,是人们获取信息,了解时事热点的重要途径,尤其是近年来,新闻行业数字化发展迅猛,新闻网络平台的普及,极大地满足了人们“足不出户而知天下事”的心愿。人民网率先建立了以新闻为主的大型网上信息交互平台,是国际互联网上最大的综合性网络媒体之一。网络平台上新闻报道、新闻评论、网友发声等文本数据快速增加。将这些文本数据正确归类,可以更好地组织、利用这些信息,因此快速、准确地完成新闻分类任务具有十分重要的意义。
面对规模巨大且不断增长的文本信息,依靠人工将海量的文本信息分类是不现实的。近些年来,借助机器学习技术完成分类任务已成为主流[1][2],计算机可以通过不断学习获得经验技能,对未知的问题可以给出一个正确的分类标签。因此,通过机器学习,可以对新闻平台上的大量数据进行自动化分类,帮助用户提高检索效率,提升用户阅读体验,同时可以在分类的基础上分析与挖掘有用的信息,协助网站运营人员了解用户需求,让信息更有效的被利用,这也是本文的研究意义所在。
二、研究背景及现状
文本分类是自然语言处理中一个重要的部分,其主要目的是将文本内容按照构建好的分类体系进行划分。随着机器学习和深度学习的发展,国内外兴起了借助分类算法进行自动文本分类研究的热潮,如支持向量机、朴素贝叶斯等。樊存佳[3]采用改进的KNN聚类算法来解决KNN分类速度与分类精度无法同时兼顾的不足,巧妙地采用改进的K-Medoids聚类算法裁剪对KNN分类贡献小得训练样本,从而减少KNN相似度的计算量,并定义代表度函数有差别地处理测试文本的K个最近邻文本。李锋刚[4]使用LDA-Wsvm模型的文本分类,将SVM算法处理高维数据的优势与LDA主题模型可以解决文本分类中的相似性度量和主题单一性问题的优势结合,提出一种新的LDA-Wsvm高效分类算法模型。覃世安[5]针对TF-IDF在待分类文本类的数量分布不均时提取特这个值效果差的问题,提出使用特征值在类间出现的概率比代替特征值在类间出现的次数比的改进的TF-IDF算法。吕超镇等人[6]针对中文短文本篇幅较短、特征稀疏性等特征,提出了一种基于隐含狄利克雷分布模型的特征扩展的短文本分类方法,他们使用LDA文本主题模型对短文本进行预测,得到对应的主题分布,把主题中的词作文短文本的部分特征,扩充到原短文本中的特征中,最后在利用SVM分类方法进行短文本的分类。与KNN算法、BP算法等相比,深度学习算法的引入使得自动文本分类模型的性能进一步提升,Yujun Zhou[7]提出了基于长期短期记忆(LSTM)的递归神经网络(RNNs)的混合模型,用来处理中文短文本分类任务,马双刚[8]将深层网络模型应用于特定领域文本分类。这也表明特定领域的文本分类逐渐成为学者们新的关注点。
而新闻文本分类问题,几乎是伴随着新闻本身而生的。从传统的报纸媒体开始,就有手工分类。但是随着网络化的普及以及新闻更新的高频性,新闻网络平台中出现了大量的新闻信息累积,手工分类已经难以满足目前的数据需求。新闻数据的文本分类是中文文本分类的重要的研究方向之一,网络平台上的新闻文本数据库,是研究中文本文分类的重要数据源。
因此,本文面向网络新闻平台本文数据,充分考虑短文本特征,提出了集成机器学习算法和深度学习算法的CNN+LSTM分类模型,力图解决新闻自动分类问题。
三、分类方法原理
3.1、文本分类算法
一般来说,文本分类模型需要提前标注好类别的语料作为训练集,属于有监督的学习,核心问题是选择合适的分类算法,构建分类模型。本文采用了随机梯度下降、在线被动攻击算法、线性支持向量分类、岭回归和梯度提升5种分类算法,集成构成模型。
随机梯度下降(SGD)通过一次只考虑单个训练样本来近似真实的梯度,算法在训练样本上遍历,用每一个样本对模型的权重参数进行一次更新。和梯度下降相比,SGD使用单个样本来近似,收敛速度快,对高维度特征适应性较好,但计算得到的并不是准确的一个梯度,容易陷入到局部最优解中。而梯度下降的代价函数计算需要遍历所有样本,每次迭代都要遍历,直至达到局部最优解。但是在面临训练集较大的情况,梯度下降的收敛速度比较慢,兼顾计算量和效率,SGD不失为一种折中的选择。
在线被动攻击算法是一种增量学习算法,在一段时间内内存中只存有少量数据,可以有效处理巨大的数据集。对于类目不均衡的问题,PA算法主要基于实例被错误分类时的实例损失来训练加权向量,能减少错误分类的数目。基于PA的线性分类起可以不断的整合新样本去调整分类模型,增强模型的分类能力,对每一个新的样本点进行分析,根据分析结果更新分类器。
线性支持向量分类(Linear SVC)是基于 liblinear 实现的线性支持向量分类器,它在惩罚和丢失函数的选择上具有更大的灵活性,计算效率高,可以更好的适应较大的训练集。
岭回归(Ridge Regression)是一种专门用于共线性数据分析的有偏估计方法,是一种改良的最小二乘估计法,它放弃最小二乘的无偏性,通过施加一个惩罚系数的大小解决了一些普通最小二乘的问题,以损失部分信息、降低精度为代价,获得更符合实际的回归系数,最大限度地减少了一个惩罚的误差平方和。
梯度提升(Gradient Boosting)。Boosting是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数。Gradient Boosting就是对Boosting思想的一种实现,它是以弱预测模型的集合的形式产生预测模型。通过调节决策树的数目、树的最大深度,叶子节点包含样本的最大数目等参数,可以调节模型的性能。
3.2 卷积神经网络(CNN)
本文采用了卷积神经网络作为深度学习模型,捕捉文本中邻接词的语义的特点,得到文本可能的邻接词语义组合序列。卷积神经网络是人工神经网络的一种,如图1,它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量,避免了传统识别算法中复杂的特征提取和数据重建过程。[9]
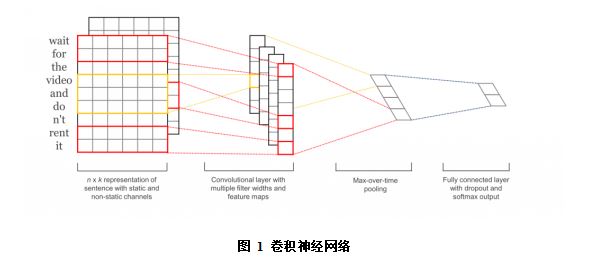
卷积神经网络中主要包括卷积层、池化/采样层、全连接层等结构。
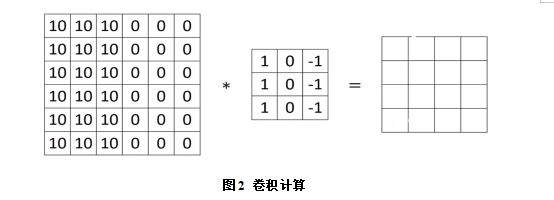
卷积层会将一个二维数据通过过滤器过滤,卷积计算如图2所示:

四、新闻分类模型
本文提出的新闻标题分类模型,首先选择了随机梯度下降、在线被动攻击算法、线性支持向量分类、岭回归和梯度提升5种机器学习算法集成训练,然后将深度学习中的卷积神经网络(CNN)和循环神经网络中的长短时记忆模型(LSTM)组合起来,综合考虑近邻信息和长序信息,下层利用 CNN 对邻接词的语义捕捉的特点得到文本可能的邻接词语义组合序列,上层利用 LSTM 来整体把握文本的上下文语义关系。然后进行模型集成,形成最终模型。
4.1 机器学习算法集成
SGD、PA、Linear SVC、Ridge Regression这些算法均是基于词袋模型,自变量是特征词典的大小,所以为了后期更方便地进行模型调优,在自变量的初步筛选中,按照特征工程的流程,对特征词典进行了分组测试,选取特征词典维度为[10000,45000]区间分8组进行试验。
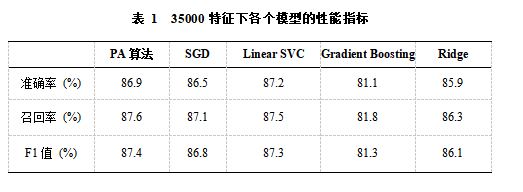
在自变量初步筛选的基础上,对各个算法进行参数调优,从而得到算法的初步调优结果。经实验对比发现,当特征数为35000时,各个模型的F1值达到最好,即当特征词典选取为35000时,可作为最终训练参数。当特征数目较少时,不能很好的对文本语义的完整度进行建模,当特征数目过多时,反而会引入较多的语义噪声。特征工程的目的在于能够找到一组超参数,找到二者的权衡点,达到模型既能对文本语义有很好的建模,又能最大程度的降低噪声的影响。如表1所示,是各个模型在特征参数为35000时的准确率、召回率和F1值:
为了提高整体模型的泛化能力和分类性能,本文采用了ensemble集成的思想,将上述5个机器学习算法集成使用,如图8所示。调优过程选取了比较常用的套袋算法(bagging),bagging 是bootstrap aggregating的缩写,是第一批用于多分类器集成算法,该集成方法包括在一个训练集合上重复训练得到的多个分类器。给定一个大小为N的训练集合,bagging方法构建了n个新的训练集合S1,S2...Sn,每个训练集合都是由随机抽取的N个样本进行训练得到的。
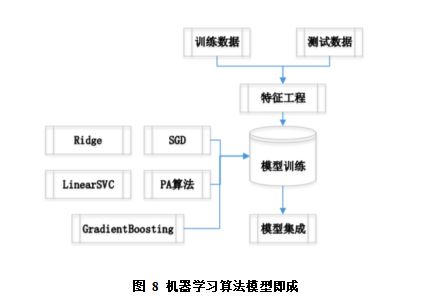
在分类预测的过程中,集成模型形成类似委员会机制,每个模型对待分类的文本都有一个预测标签,最后的输出标签根据所有分类器的统计投票确定。各模型的预测标签越一致,则分类的置信度越高,反之,各个模型的分类标签差别越大,分类的置信度越低。
4.2 深度学习算法集成
传统的机器学习算法召回率较高,但在上下文语义的理解上不如深度学习。深度学习是机器学习中一种基于对数据进行表征学习的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。至今已有数种深度学习框架,如深度神经网络、卷积神经网络和深度置信网络和递归神经网络已被应用计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。
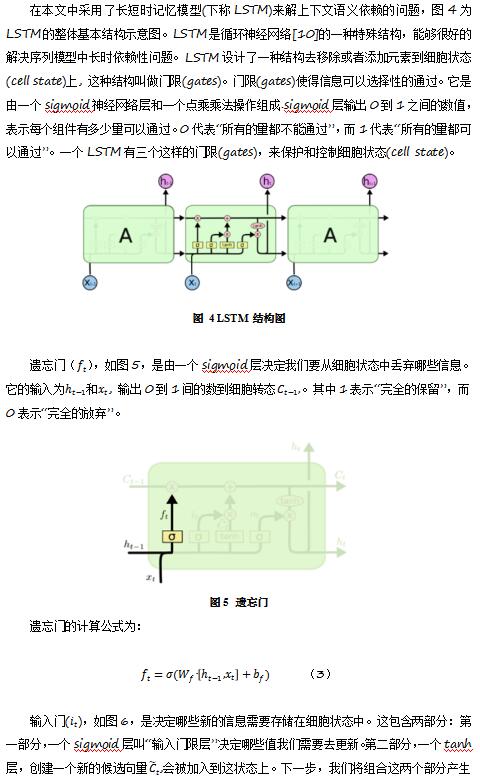
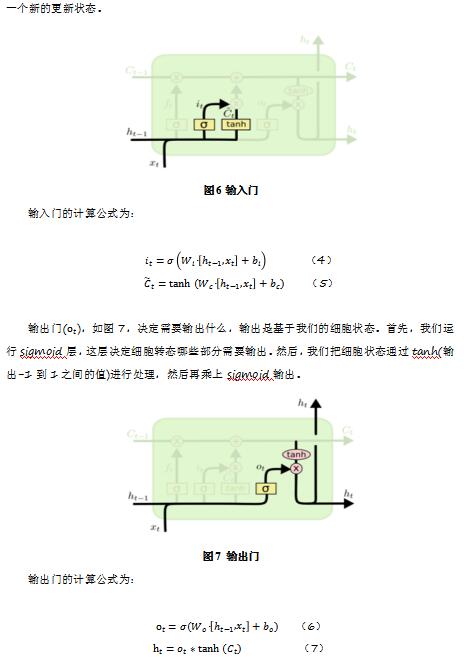
本文主要采用深度学习中的卷积神经网络(CNN)和循环神经网络中的长短时记忆模型(LSTM)组合起来,捕捉短文本表达的语义,并在语义识别效果上,要优于基于词袋模型的普通机器学习算法[11][12]。卷积神经网络(CNN)通过借助不同的滤波器尺寸(filter size)可以有效捕捉文本邻接组合词的语义;长短时序模型(LSTM)有利于解决上下文语义的长时依赖问题。
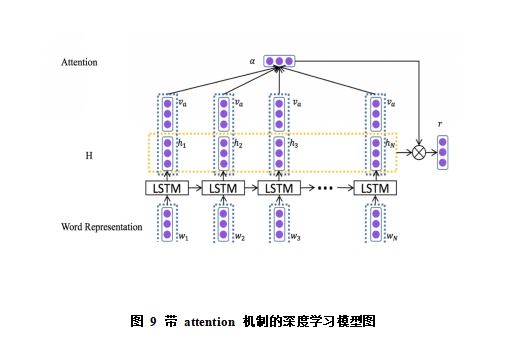
新闻标题多为短文本,因此为了更好的捕捉上下文语义,本文同时采用 CNN 和 LSTM 模型,借助 tensorflow 开源工具构建上述深度学习模型,下层利用 CNN 对邻接词的语义捕捉的特点得到文本可能的邻接词语义组合序列,上层利用 LSTM 来整体把握文本的上下文语义关系。同时尝试引用时下热门的attention机制(注意力机制),对LSTM的时序输出进行加权,最后通过全连接层进行类目预测。模型如图9:
4.3算法评价指标
算法评价矩阵一般指对于算法预测效果和实际值的比较在本文中,采用了常用的分类衡量指标准确率(Accuracy)、召回率(Recall)和基于二者的调和平均值的综合指标F1值。
 (8)
(8)
五、实验过程
5.1数据选择及数据预处理
本文的数据来源是人民网观点频道的新闻数据。文本预处理是文本分类常见且必须的步骤,通过清除不一致或无实体语义的字符,以及过滤分词后的停用词,都可以尽可能的降低文本噪声带来的分类性能上的影响。并且可以有效的降低模型占用的内存,提高模型的泛化能力。本文在文本数据预处理上主要采用了字符清洗、分词、去停用词。
字符在文本中并不具备具体的语义,只是起到语义停顿、连接、结束的作用,在文本分类上,经常作为无用字符处理。一般的处理方法是直接匹配过滤。因此,本文采用正则匹配的方法,对输入的文本数据进行全角半角转换、标点字符匹配过滤等操作。
中文文本并不像英文文本那样,带有空格作为各个单词的分隔符。在汉语表达中,词可以看作是语义的最小单元。中文文本分类中,经常采用分词操作对一段汉语文本进行切词处理,即将文本表示成多个中文词语的形式。文本分词,有利于后续采用向量空间模型进行算法模型训练。目前业界常见的分词工具包括jieba分词、清华的分词工具以及斯坦福的分词包。其中jieba分词在词性标注、分词准确率、分词粒度和性能上都相对较好,因此本文主要采用jieba(0.38版本)进行文本分词操作。
在自然语言处理中,处理数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为停用词。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具。甚至有一些工具是明确地避免使用停用词来支持短语搜索的。对于一个给定的目的,任何一类的词语都可以被选作停用词。通常意义上,停用词大致分为两类。一类是人类语言中包含的功能词,这些功能词极其普遍,与其他词相比,功能词没有什么实际含义,中文比如的“的”、“呢”、“吗”等。另一类词包括词汇词,比如'已经'等,这些词应用十分广泛,但是对这样的词搜索引擎无法保证能够给出真正相关的搜索结果,难以帮助缩小搜索范围,同时还会降低搜索的效率,所以通常会把这些词从问题中移去,从而提高搜索性能。由于新闻标题数据长度较短,语义表述较为简洁,因此不能采用全部的jieba停用词表,本文仅对一些非常常见的停用词进行了过滤,例如“呢”,“吗”、“的”等词,既最大程度的保证了语义的完整性,又尽可能的去掉了停用词。
5.2 文本表示
文本表示,也称为文本向量化,就是把文本表达为可以让计算机来理解的形式。常见的文本向量化手段包括词袋模型(bag of words)和文本分布式表示(如Word2vec)。本文中采用了多个机器学习算法和深度学习算法,其中在机器学习算法中,主要采用了词袋模型,即通过进行特征工程,筛选出主要贡献度大的特征和特征数目,构建特征词典,进而将文本词映射为词 ID;在深度学习模型中,主要采用文本分布式表示,本文采用了预训练的 Word2vec 向量,为保证预训练的语料尽可能正确的表示中文词的语义空间,采用了搜狗实验室3.5G 的全网语料,选取语义空间维度100进行无监督训练得到,每一维度用浮点型数据表示。
整个数据预处理过程及文本表示如表2所示。

5.3模型参数
本文将深度学习模型与机器学习模型集成在一起,各取所长,在分类效果上取得了更好的结果。在对文本进行相同方法的预处理以后,并非像机器学习那样,利用词袋模型构建文本向量,而是采用预训练的word2vec进行词到语义空间的映射。每个词 id 都被表征为语义空间的100维的向量,每条文本表示为sequence_len × 100的二维数组。训练采用 batch 的方式进行训练。表3是深度学习时的各个参数配置说明。

基于深度学习的模型在泛化能力上具有很大的优势,能够避免基于词袋模型的机器学习对部分词比较敏感的问题。当文本的长度低于一定值时深度学习模型可能存在较大的误差,为了解决超短文本带来的偏差,此项目采用了以深度模型为主,机器学习模型为辅助的集成模型,同时在部分类目上采用深度优先的原则,即深度模型具有一票否决权。
5.4实验结果示例
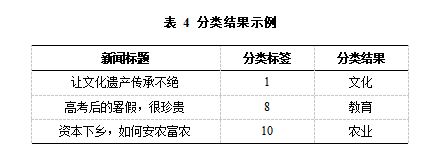
将人民网观点频道中的新闻标题,利用机器学习算法和CNN+LSTM深度学习算法集成的模型进行分类,正确预测的几种典型标题及对应的分类标签和结果如表4所示,其中标签1代表文化,标签8代表教育,10代表农业。
六、结论
针对中文短文本的特点,本文以新闻标题为实验数据,利用word2vec有效地提取新闻标题中语义信息,构建了基于机器学习和深度学习的分类模型,实现了网络新闻平台上新闻标题的自动分类,对新闻网站的建设及更深一步的信息挖掘,有一定的推动意义。未来,可以以此为基础,分析用户的阅读新闻的类型喜好,实现新闻个性化推荐,给用户带来更良好的体验与服务。
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
