




















你为何而转:微博用户转发行为预测模型的构建与影响因素探究
摘要:微博用户的转发行为已成为信息扩散的关键机制。本研究旨在构建模型对转发行为进行预测,并分析其影响因素。首先根据“5W模型”,提取微博作者、微博文本、微博接受者和相互关系四个一级维度特征,并细分为39个二级维度特征,利用支持向量机构建预测模型,再通过新浪微博数据,对模型进行评估。预测模型的查全率为58.67%,精确率为82.19%,F1值为68.46%,这表明预测模型的表现令人满意。本研究还利用信息增益算法计算39个二级维度特征的影响力,并以此对其进行排序。结果表明,“微博作者活跃度”、“微博作者和接受者标签相似度”、“接受者活跃度”、“微博主题与接受者标签相似度”四个因素对转发行为的影响最大。本研究结论在微博营销与舆情分析等领域将有很多潜在应用。
关键词:微博转发、预测模型、影响力排序、支持向量机、信息增益
一、引言
微博因其简单性和随意性,吸引了越来越多的网民参与其中,获取信息,分享生活[[1]]。中国最大的微博平台是新浪微博,它允许用户发布文字贴(不超过140个汉字)[[2]],内容涉及广泛话题。截至2013年12月底,中国微博网民规模为2.81亿,网民中微博使用率为45.5%[1]。微博已经成为网民获取信息的重要途径[[3]]
在微博平台上,用户行为主要包括发布信息、转发、评论、添加关注等几种。其中,转发被看作是最重要的行为之一。通过转发,微博信息能够以指数级的方式进行扩散。微博用户因为利他或自我提高等原因转发微博[[4]]。例如他们通过转发特定信息,构建自己的微博形象、分享感兴趣的信息、公开赞成或反对某个观点等。转发行为的实践有助于建立起一个会话生态系统。在此系统中,会话是通过用户基于共享上下文而进行交流的。同时,转发行为也使得新的,原作者陌生的用户参与特定的话题讨论[[5]]。
虽然转发行为被看作是微博平台上信息扩散的关键机制,但目前仍不清楚为什么有些微博比另一些更容易被转发。本研究的第一个研究目的,即构建模型对用户转发行为进行预测。通过预测模型,可以引导舆情、筛除谣言,优化微博中信息扩散等。同时,在影响用户转发行为的因素中,理清他们的影响力大小,将促进商家个性化推荐信息和精准营销,引发巨大经济效益。因此,本研究的第二个目的是对影响转发行为的因素的影响力大小进行排序。
本文接下来分为以下部分:第二章讨论和梳理的已有文献。第三章描述本研究所构建的预测模型。第四章介绍本研究所使用到主要方法。第五章介绍本研究的实验并给出实验结果。第六章对实验结果进行讨论。第七章将给出本研究的结论和以后的研究方向。
二、文献综述
持续增加的微博用户使得研究者开始关注他们的行为。微博用户能自由地选择关注其他用户,这种关注行为是单向的,并不需要被关注用户确认[[6]]。正是这种单向关注行为,促进了微博上信息的广泛传播。在Twitter中,人际交互大多数发生在线下,而事件传播大多发生在线上[[7]]。实验发现,被试可以通过阅读Twitter用户所发布的内容判断他们的大五人格类型[[8]]。另外,随着线上对社会热点问题的讨论和影响愈发频繁,越来越多的学者开始关注Twitter上的信息传播及其模式。但Twitter用户对于信息并不是完全不加思考的接受,研究者发现,有过低或过高的粉丝数和关注数的用户均容易被认为有较低的信息可信性[[9]]。
面对信息在微博平台上迅速传播和扩散的现状,研究者们将转发行为看作是其关键机制之一。然而,目前和转发行为相关的研究主要局限在转发的动机和内容两方面。因此探索其传播和扩散的机制变得尤为重要[[10]]。研究者通过实验证明了Twitter用户倾向于转发与自己粉丝兴趣相关的和信息价值高的内容[[11]]。更多的研究则试图通过建立预测模型,对转发行为进行预测。研究者选择了内容特征和情境特征作为自变量,构建了基于泛化线性模型的预测模型。他们发现,Tweet包含超链接和话题标记与否,对其转发率有直接影响;Tweet作者的粉丝数、关注数和账户的年龄对其转发率有间接影响;Tweet作者已有的Tweet数与转发率基本无关[[12]]。也有学者认为转发的主要原因是个人兴趣与满意程度,他们提出了一个能够有效从Tweet内容中提取潜在主题的模型来预测用户的转发行为[[13]]。其他学者选择了基于社会、基于内容、基于Tweet和基于用户等四个维度的特征构建模型,确定了与用户转发行为联系最紧密的特征[[14]]。还有学者提取内容相关、拓扑学相关、时间相关、元数据相关等四大类特征,预测给定的Tweet是否会被转发及转发的程度[[15]]。Petrovic和Sasa等利用被动攻击算法,选择了社会性特征和Tweet特征两大类构建预测模型。同时还构建了时间敏感性模型,以适应发布时间对转发行为的影响[[16]]。
虽然已有研究提出了多种对Twitter用户的转发行为进行预测的模型,但是多数研究通常没有说明预测模型自变量的来源。他们不能解释为什么有些因素可以影响用户的转发行为而另外一些因素则不能,因此也就没有办法判断其预测模型的自变量是否包含了所有可能对转发行为产生影响的因素。另一方面,作为自媒体的代表,微博本身不仅是作为大众传播的媒介,还具备人际传播的特点。在微博平台上,每个人都拥有话语权,传播模式日趋扁平化和网络化[[17]]。因此,在研究微博平台上的转发行为时,作为接受者的用户特征不能忽略。事实上,微博转发过程可被视为信息传播过程,用户是否转发即为此过程的传播效果。著名传播学家Lasswell提出了著名的“5W模式”[[18]]:“谁(Who)”,“说什么(say What)”,“通过什么渠道(through Which channel)”,“对谁说(to Whom)”,“有什么效果(With what effect)”。“5W模式”描述了信息经由传播渠道从传播者到达接受者的过程,为传播效果研究提供了清晰的分析框架。因此,本研究采用“5W模式”作为预测模型构建的理论基础,并提取能够影响用户转发行为的潜在因素。
三、预测模型的构建
根据“5W模式”,传播过程中需要考虑的因素包括传播者、传播内容、传播渠道、接受者、传播效果。本研究中,传播者为微博作者,传播内容为微博文本内容,传播渠道为微博平台,接受者指所有看过此微博的用户,传播效果为此微博是否被转发。转发行为预测模型,即在确定传播渠道为微博平台的前提下,构建一个独立预测模型,其中,自变量应包括微博作者特征,微博文本特征,微博接受者特征三大类因素。同时,微博用户不仅可以通过评论、转发等行为,建立与他人的联系,构建自己的社交关系网;同时也会被其他用户的行为影响。因此,预测模型中还应当考虑微博作者、微博接受者、微博文本三个因素之间的相互关系。
然而上述的四大特征(微博作者特征,微博文本特征,微博接受者特征,相互关系特征)仍然过于宽泛,它们仅适合作为预测模型的一级维度特征。对于每个一级维度特征,还需要细化为二级维度特征,如图1所示。下面将对重点二级维度特征进行介绍。
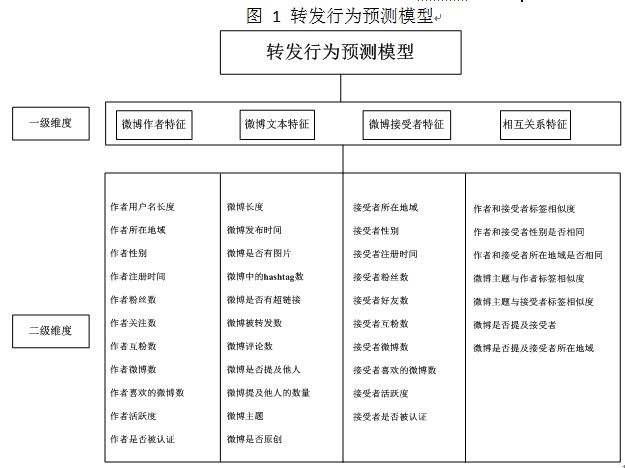
1、微博作者特征
微博作者即发布微博的用户。本研究提取了11个因素作为微博作者特征的二级维度。需要说明的是,微博作者的地域是以省为分析单位。用户可能倾向于转发与自己所在省相关的微博。
2、微博文本特征
微博文本即微博的具体内容,包括文字、符号、超链接等。对于微博用户来说,微博内容将在很大程度上影响其是否转发。本研究选择了11个因素作为微博文本特征的二级维度,包括微博主题、微博中含有的hashtag数等。需要说明的是,微博含有的hashtag数,即指微博文本中含有的“#”的数量。在微博中,hashtag通常成对出现,并且两个hashtag之间的内容,通常为此条微博的主要内容。另外,微博主题需要通过对微博文本进行分类处理后才能确定。
3、微博接受者特征
微博接受者即除微博作者之外,所有浏览过指定微博的用户。作为“5W模式”中的组成部分,微博接受者在研究中却常常被忽略。在微博平台上,每个人既可以是信息的发布者,又可以是信息的接受者。传统大众媒体中关于传播者和接受者的界限,在微博里变得越来越模糊,传播者和接受者的地位也越来越平等。所以本研究将微博接受者与微博作者置于同等重要的地位。
但是对于给定微博,很难判断接受者未转发的原因是因为真的不想转发,还是仅仅因为没有看到微博。为了避免后者,本研究将微博作者的所有粉丝作为接受者,并提取了10个因素作为微博接受者特征的二级维度。其中接受者地域和微博作者地域一样,是以省为分析单位。
4、相互关系特征
相互关系特征指微博作者、微博文本、微博接受者三者之间相互联系的特征因素。在微博用户决定其是否转发过程中,这些相互关系会影响用户的决策。本研究选择了7个因素作为相互关系特征的二级维度。需要说明的是,本研究采用用户自定义的标签来表征用户的兴趣,这主要是基于一个假设,即用户为自己添加的标签,通常表示用户本身对于标签内容的认可和喜爱。
通过对影响用户转发行为的特征分析,本研究将所用到的数据样本定义为d = (a, t, r, c),其中a表示微博作者特征,t表示微博文本特征,r表示微博接受者特征,c表示相互关系特征。同时将微博用户是否转发某条微博定义为y。因此,预测模型即为寻找到一种关系f,通过f建立起由39个二级维度特征构成的数据样本d到因变量y之间的对应关系,即f (d) → y。因变量y可能的取值及意义由式(1)给出。

因为因变量y只有两个可能的取值,因此预测模型的任务也可以看作是对给定的数据样本进行分类。分类的结果只有两种,类别为C1(微博被转发)或C2(微博未被转发)。所以本研究中的预测模型,是一个根据给定的自变量进行二分类的模型。
四、方法
本章将介绍本研究所使用的分类方法。同时,针对39个二级维度特征进行排序,需要计算每个特征的影响力,所以本章还将给出特征影响力的计算方法。
1、分类方法
目前常用的分类方法包括基于关联规则的分类[[19]],有监督的机器学习[[20]],支持向量机[[21]]等。其中对于二分类问题,以支持向量机最为有效。支持向量机是由Vapnik提出的一种大有前景的方法[[22]]。它是一种新的统计学习算法,具有基于结构化风险最小原则之上的良好理论基础和泛化性能[[23]]。它可以最小化训练误差,通过不太复杂的边界实现分类或回归[[24]]。支持向量机已被广泛用于有监督的学习技术,特别是在数据样本较少时,它能得到较理想的分类结果[[25]]。另外,已有研究也表明支持向量机的分类性能,尤其是泛化能力好于传统的分类方法[[26]],[[27]]。因此本研究选择它作为分类来完成预测过程。
除了预测转发行为是一个分类问题外,确定微博主题这个二级特征维度时,也涉及到文本分类问题。经典文本分类方法包括:Rocchio法、决策树法、朴素贝叶斯分类、K近邻算法等[28]。其中朴素贝叶斯分类器,作为最直接和最广泛使用的概率分类方法,在模式识别领域已经有了很长时间的应用[[29]]。同时,它也是用于解决许多现实世界分类问题的重要方法。贝叶斯分类器具有四大优点:易使用,对所需训练集只需一次扫描,善于处理缺失值以数据具有连续性[[30]]。所以本研究采用贝叶斯分类器来确定微博主题。
2、影响力计算方法
除了预测转发行为,本研究还将对39个二级维度特征的影响力大小排序。信息增益是在选择特征相关的变量中做出贡献的基础上,不考虑特征交互的单变量方法[[31]],它利用了信息熵的概念[[32]],研究者发现,信息增益算法是最有效的特征选择方法之一[[33]]。在本研究中,39个二级维度特征之间存在一定的相关性,并不相互独立,因此选择不考虑特征交互的信息增益方法,可以保留二级维度特征彼此相关性,得到较准确的结果。
因为预测模型处理的是二分类问题,只有C1(微博被转发)和C2(微博未被转发)两类,所以在运用信息增益算法计算特征的影响力时,计算过程将大大简化。计算方法由式(2)给出。
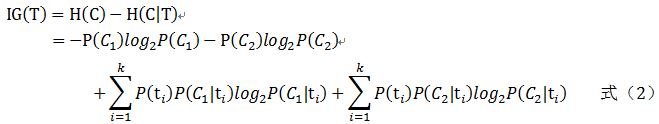
其中,P(Cj)表示类Cj出现的概率,j=1,2,其计算方法由式(3)给出。

P(ti)表示特征T取值为ti的概率,i=1,2,3, …, k,其计算方法由式(4)给出。

P(Cj|ti)表示类别Cj中特征T取值为ti的概率,j=1,2, …, n,i=1,2,3, …, k,其计算方法由式(5)给出。

在本研究中,选择信息增益方法,利用式(2)计算出每个二级维度特征的信息增益值,便可对每个二级维度特征的影响力进行排序。
五、实验
1、数据描述
本研究利用新浪微博官方API,从中随机抽取数据作为研究样本。首先随机抽取15000条微博,并获取每条微博的作者信息。在剔除了非中文微博、同一作者发布的多条微博、粉丝数为零的作者发布的微博之后,最终得到14421条微博及14421位微博作者信息。然后,随机从每位作者的粉丝中抽取一定数量的用户作为微博接受者,由此组成数据样本。最终,一共得到208747条数据样本,其中男性用户占48.92%,认证用户占10.37%。这表明所获取的数据样本很好的符合新浪微博平台上的真实情况。
2、实验过程
(1)构建特征向量
假设每条数据样本d有n个特征,ni是d的第i个特征,i = 1,2,3,…,n,用数字xi来表征,则可以用向量x = (x1, x2, x3, …, xn)来表示d,称向量x为d的特征向量。在本研究中,每条数据样本d中包含39个特征,即n为39。构建特征向量的目的,是为了将每条数据样本向量化,从而有利于分类计算。
本研究构建特征向量的方法主要包括编码和计算两类。编码即用预先规定的方法将文字、数字或其他信息转化成特定形式。本研究需要将微博作者地域,微博是否包含图片,用户活跃度等特征转化为数字形式,其中用户活跃度通过式(6)计算得到。

计算则主要针对微博主题和相互关系特征。对于微博主题,采用贝叶斯分类器。首先对微博文本进行分词处理。为保证分词结果的准确性,本研究采用成熟分词系统――中科院的汉语词法分析系统ICTCLAS[[34]]――进行分词。分词完成后,剔除其中的停用词,得到微博文本的词集。接下来,利用事先准备好的训练集进行训练,并根据训练结果对微博文本分类,得到主题。需要注意的是,因为样本中微博文本并不确切的知道其所属类别,所以机器学习中常用的将数据样本分为训练集和测试集的方法对确定微博主题并不适用。本研究使用数据堂网站[2]提供的微博文本分类语料库作为训练集。该语料库包含了微博文本常见的财经、传媒等21个主题,每个主题中包含几百条微博文本,样本来源广,数量充足。在分类完成后,还需要通过编码的方式处理分类结果。
三种相似度(作者和接受者标签相似度、微博主题与接受者的标签相似度、微博主题与作者的标签相似度)的计算,可以转换为两个词语之间相似度的计算。本研究采用HowNet提供的方法来求解词语间的相似度。
微博用户的标签通常不只一个,因此在计算相似度特征时,假设微博作者标签词集SW1 ={W11, W12, W13, …, W1n},微博接受者标签词集SW2={W21, W22, W23, …, W2m},则微博作者和微博接受者标签相似度由式(7)给出。
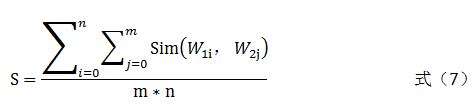
(2)模型验证
本研究采用简单、易用和快速有效的支持向量机模式识别与回归的软件包libsvm来进行基于分类运算[[35]]。208747条数据样本被分为训练集(130000条数据样本,62.28%)和测试集(78747条数据样本,37.72%)两类。根据预测结果和测试集中样本的真实情况,建立混淆矩阵如表1所示。


 |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
