




















新媒体环境下的短视频推荐模型及算法研究
2013年,短视频分享应用开始进入人们的视野,不同于传统“文字+图片”的社交模式,此类应用通过手机拍摄到10秒左右的视频,并将该视频进行上传和分享。因此,本文所提及的短视频是指播放时长在5-15秒的视频。相对于微电影、播客等媒体形式来说,短视频具有生产简单化、传播即时化、内容碎片化和分享社会化的突出特点。短视频的时间特性决定了其依附性,需要依靠社交网络的媒介获得庞大的观看群体。对于各大社交网络平台和媒体来说,如何对用户进行高效准确的短视频推荐,是提高自身活跃度的一个关键因素[1]。
短视频的产生是伴随着移动联网技术产生的新媒体,更是多种价值的融合。一方面,短视频能够极大的满足人们的精神需求。在当今娱乐碎片化的时代下,文字形式的心灵鸡汤已经不能满足人们的精神世界。人们更渴望轻松娱乐和随意的分为。网络短视频正好迎合了人们娱乐和分享的心里,通过几秒钟的视频,和朋友一起娱乐消遣。另一方面,短视频在丰富人们的生活的同时,也潜在着巨大的商业价值。由于短视频的播放时间短,内容丰富而多样的特性,能够产生较大的浏览量。因此,进行广告投放将会是短视频的一大趋势,有针对性的内容植入和广告投放会是巨大的视频营销机会。最后一点,便是短视频能够满足人们的新闻需求。网络短视频的及时性和新闻的及时性具有高度一致性,其在新闻业的应用将带领新闻业走向多元化的发展。国外的NOW THIS NEWS在2012年即推出了短视频新闻应用,为政府和多种机构提供传播支持。
在国内来看,以人民网为例。人民网是国内主流的新闻媒体之一,其新闻业务涉及到多个领域。为了更好的服务社会,人民网于2010年构建了人民电视平台。该平台是人民网的视频品牌,官方视频新闻频道,目前已经形成以新闻类视频节目为主,同时囊括文化、娱乐、体育、生活、社会等各类综合内容的业务格局。该平台的视频以三分钟以内的小视频为主,用户在查看某个视频时,会在网页上同时得到相关视频的推荐信息。这些信息方便了用户的浏览,提高了用户体验,但同时也存在推荐效率不高,同一个视频会在一个网页被多次推荐等问题。同时,人民网还推出了微视频平台,该平台的主旨是“让用户在平台在分享原创视频,帮助用户记录生活经典微瞬间”,目前已经具有很大的用户群体。这足以说明短视频已经开始在国内的多个领域崭露头角。在短视频日益普及的情况下,如何从大量的短视频中挖掘更有效的信息,提高短视频的推荐效率和准确度,将会是一个具有巨大实用价值的研究热点。
2 研究现状
对于一个短视频网站来说,短视频推荐系统是必不可少的一环。推荐系统根据用户的相关信息,从视频源里检索过滤,最后将与用户兴趣匹配度较高推荐给用户。这种推荐系统在大型互联网站点YouTube,Amazon,Netflix等都得到了成功应用。
推荐系统的开发是具有挑战性的,多种多样的方法被提出来。方法被划分为以下三类:协同过滤[2],基于内容[3],以及融合前两者的混合模型。
基于内容的推荐系统:根据历史信息(如评价、分享、收藏过的文档)构造用户偏好文档, 计算推荐项目与用户偏好文档的相似度, 将最相似的项目推荐给用户.例如,在视频推荐中,我们首先由用户的观看记录或者评价收藏信息提取重要字段(如视频标签,视频分类等),从而获取用户的兴趣标签。之后再将新视频与用户兴趣比对,从而产生推荐。
基于内容推荐方法的优点是:1)不需要其它用户的数据,没有冷开始[4]问题和稀疏问题。2)能为具有特殊兴趣爱好的用户进行推荐。3)能推荐新的或不是很流行的项目,没有新项目问题。4)通过列出推荐项目的内容特征,可以解释为什么推荐那些项目。5)已有比较好的技术,如关于分类学习方面的技术已相当成熟。缺点是:要求内容能容易抽取成有意义的特征,要求特征内容有良好的结构性,并且用户的口味必须能够用内容特征形式来表达,不能显式地得到其它用户的判断情况。
协同过滤推荐技术是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后 利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐。协同过滤最大优 点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。
虽然协同过滤作为一种典型的推荐技术有其相当的应用,但协同过滤仍有许多的问题需要解决。最典型的问题有稀疏问题和可扩展问题。
混合模型考虑到了基于内容推荐以及协同过滤推荐两者的不足和缺点,将两者融合。根据具体的混合方式不同,混合模型的性能也有所区别。
国内外各个方向都有涉及推荐系统的研究,有些集中于探索混合算法从而得出更高效的混合模型。例如在论文”OSCAR: an Online SCalable Adaptive Recommender for Improving the Recommendation Effectiveness of Entertainment Video Webshop”[5]中,研究人员就提出了一种混合模型,根据用户的行为和数据的具体特征选择最合适的推荐算法给用户。
还有对于目前协同过滤进行改进的,比如在:”Slope One Predictors for Online Rating-Based Collaborative Filtering”[6]中,研究人员提出Slope One这种方法。它旨在利用其它用户用户对资源的评分来预测用户对资源的评分。还有些侧重于研究社交网络,从而更好地为协同过滤得出相似的用户,研究结果也表明,朋友之间的兴趣相似度较高,社交网络可以很大程度上帮助推荐系统提升性能。
基于以上推荐方法的研究,结合视频的特点,在普通视频推荐领域已经有很多研究成果。以YouTube为例,在论文“The YouTube video recommendation system”[7]中详细介绍了相关推荐方法在YouTube视频网站上的应用,同时取得了很好的反馈效果。但是针对短视频的推荐方法的研究还比较少。由于短视频自身的生产简单化、传播即时化、内容碎片化和分享社会化的突出特点,如果只是将应用在普通视频上的方法简单的迁移到短视频上,将必然会带来效率低下的缺陷,同时推荐效果也会大打折扣。因此,需要根据短视频的真实情况进行深入研究,探索出切实可用并且高效的短视频推荐方法。
3 推荐方法的初步建立和效果评估
在视频推荐领域,目前理论和实践界面临的主要问题首先是由于数据量较大引起的计算的复杂性。云技术发展所采用的分布式计算模式以及推荐系统中的用户模型相关技术可以应用来解决这一问题。我们的模型基于以上技术,但又对其进行了改进。
3.1 理论基础
设想一下真实的推荐系统运行场景,我们就会发现这个计算量的巨大以及实施的困难性。
如果是基于内容的推荐系统,首先假设我们已经抽取了用户的特征值向量(假设用户有n个),视频的特征值向量(假设视频数目有m个)。接下来就是计算在已有视频中和每个用户的相似度分值。显然,这个算法的时间复杂度是两个的乘积,即O(m*n)。我们采用余弦相似度来计算两个特征向量的匹配分值:
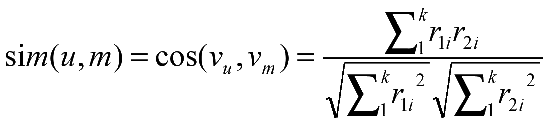 式(3-1)
式(3-1)
其中,![]() ,
,![]() 分别表示用户u,视频m的特征值向量;
分别表示用户u,视频m的特征值向量;![]() ,
,![]() 分别表示用户u,视频m的第i个特征的分值;k表示特征值数目。
分别表示用户u,视频m的第i个特征的分值;k表示特征值数目。
这样一个策略忽略了抽取特征值所用的时间。即使是这样,只完成最终这个相似度计算,也会花费大量的时间。实验数据 :处理1000个用户 1000个电影大约10小时 (MovieLens数据集,CPU 2.67ghz,内存4G)
如果是基于协同过滤的算法进行推荐,首先,我们需要维持一张巨大的“用户-视频”评分矩阵,如图2-1所示。仅仅是维持这张表就会占用大量的内存空间。假设我们的评分数据占2字节,1000个用户以及1000个电影的这张表,将占用大约2G的内存空间,更何况目前的短视频网站的用户量以及电影量远远超过这一数目。
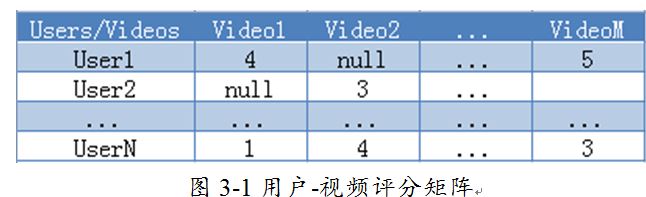
根据用户的浏览记录,我们可以用余弦相似度计算的方法计算出与指定用户相似的用户。这种计算比起基于内容的方法是巨量的,会消耗很大的内存和cpu时间。即使我们采用缓存或者分步骤计算的策略,要完成这种大量的数据处理,也是会消耗大量的资源。
正是由于这种复杂性,我们需要采取一些措施来实现高性能计算的需求。我们知道常用的提高性能的方式比如增加一层缓存或者利用并行计算的思想将计算分布开来。在这个问题中最好的选择就是分布式系统。”分布式系统是一个组件分布在网络计算机中,并且组件之间值通过传播消息通信和协作的系统。这个定义也就使分布式系统产生了以下尤其明显的特征: 组件之间的并行性,缺少全局时钟调控以及组件故障不相关性。”[10]
影响推荐系统性能的一个重要因素, 就是用户模型的准确建立. 用户的兴趣度模型能够反映用户的兴趣偏好, 然而用户的兴趣不是一成不变的, 是随着时间推移逐渐积累的, 因此个性化推荐系统需要不断地更新用户的兴趣度模型。值得指出的是用户的个性化信息需求是相对稳定的、时间相对长久的信息需求, 与那些随机的、临时的查询有所区别. 因为它是比较稳定的需求, 所以需要保存这种需求, 并可以根据用户对于所推荐的信息的感兴趣程度加以修改, 以便于获得更好的效果。
对于用户兴趣模型的建立来源于用户数据的收集,所收集数据的类型和质量将会直接决定用户兴趣建模和推荐所采用的方法以及可达到的质量。对于抽取用户反馈信息的反馈技术,有两种不同的技术来记录用户的反馈信息。一种是系统直接要求用户评价项目,这种技术被称为显式反馈,如评分评论等;另一种技术是隐式反馈,反馈过程并不需要用户主动参与,这些反馈信息来源于系统对用户行为的监控和分析,如浏览历史,搜索历史,点击数量等。
对于用户兴趣模型的表示,目前主要有基于关键词的向量空间模型表示法、概率主题模型表示法、基于本体论(Ontology)的概念表示法等。本文中采用的方法以空间向量为基础,之后根据存在问题进一步优化。
要完成分布式计算的功能,我们的用户兴趣模型必须要能支持分布式的工作模式。标签云模型可以很好的实现这一功能。用标签来去抽象出用户的特征值和视频的特征值。标签集是依附在网络内容上用来描述这些内容的关键字集合。近年来,标签集成为了阐释多媒体资源的一种广泛使用的方法。
对于特征项的抽取,常用的有文档频率法,开发法,信息增益法,互信息法以及文档频率等数十种,由于视频网站一般提供自由地标签编辑功能,所以特征项提取这一部分我们不再考虑。
对于标签权值的计算,常见的方法有布尔权重,词项频率权重,TF-IDF权重[8]。本文的权重计算基于TD-IDF权重。
(1)布尔权重: 布尔权重中,只统计特征项在文本中出现与否。如果特征项![]() 在文本
在文本![]() 中出现过,则
中出现过,则![]() 赋予1,否则
赋予1,否则![]() 赋予0,即:
赋予0,即:
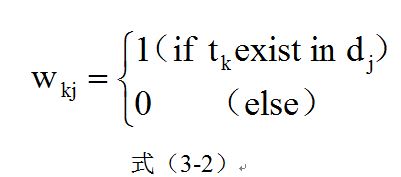
布尔权重表示的优点是计算、查询速度快,但是布尔权重中忽略了可对文档意义起重要作用的词频,对于任意特征项,只统计出现与否,而不关心出现次数。此外,由于在布尔权值中,只有0/1两种权重,无法进行模糊匹配。
(2)词项频率权重: 与布尔权重法只根据特征词出现与否不同,词频(Term Frequency,TF)权重是根据词项在文档中的频率来给词项赋权值的。在词频权重法中,用![]() 表示
表示![]() 在文本
在文本![]() 中出现的词频,
中出现的词频,![]() 定义为:
定义为:
![]() 式(3-3)
式(3-3)
与布尔权值法相比,词频权值法精准度有所提升,但是无法体现出低频特征项的区分能力。有些低频词有很强的区分能力,而有些词尽管频率很高,但是几乎没有或者只有很少的区分能力。
(3)TF-IDF权重: TF-IDF权重由两部分组成,词项频率![]() 以及逆文档频率
以及逆文档频率![]() ,计算公式如(3-4)所示
,计算公式如(3-4)所示
![]() 式(3-4)
式(3-4)
逆文档频率可以有效地防止某些没有区分度的抽象词汇被赋予过高权值,比如在一场足球比赛的专栏中,“足球”一词不具有区分度,但是词频较高。逆文档频率能有效降低这类词条权值,计算公式如(3-5)所示,其中M表示视频总数,![]() 表示特征项
表示特征项![]() 在M中出现次数,
在M中出现次数,![]() 表示特征标签
表示特征标签![]() 的逆文档词频。
的逆文档词频。
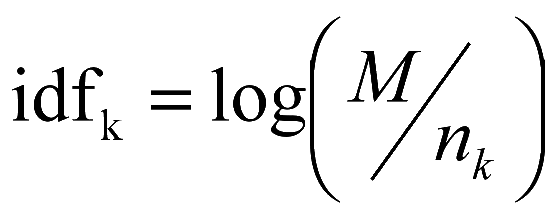 式(3-5)
式(3-5)
因为考虑到词条数目,所以最终权值计算公式如(3-6)所示
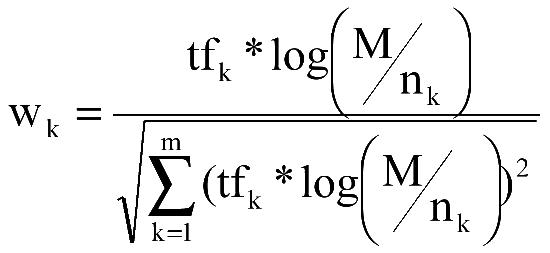 式(3-6)
式(3-6)
我们所提出的模型基于上文所提到的分布式计算模型以及用户兴趣模型,但又对其进行了改进:
与普通的大数据应用不同,一个短视频推荐系统有以下几个特点:(1)安全性要求低。对于普通短视频网站来说,最新的视频信息是网页公开的,不是商业机密性数据(2)单元用户计算量小。对于每一个用户而言,与之相关的数据计算量不会很巨大。(3)实时性较强。对于短视频而言,每天都会有新的视频涌入,用户对新视频的关注度要大于对旧视频的关注度。
考虑到以上的特点,本文提出一种新的分布式计算的方案:客户端计算。把计算的任务交由客户端来进行处理,服务器只做简单的数据传输和操作。这种模式就好比ad-hoc网络对传统通信网络的革新一样,将集中的控制权分布开来。这种方案在更大程度上实现了分布式计算,也更充分地利用了空闲资源,也就把服务器从繁忙的计算中解脱出来。
3.2 数据集
推荐算法实验所采用的数据集一般都是从实际业务系统中积累起来的,使得推荐技术学术研究尽量与行业实际情况接轨。目前已有不少实际的业务系统公开了自己采集的数据集供研究者们使用。下面简单介绍两个本文后续章节的实验中采用的数据集,它们在视频推荐技术研究中也最为常用。
(1) Netflix 电影评分数据集
Netflix 公司在 2005 年底开启 Netflix Prize 比赛的同时,公布了用于比赛和学术研究的 Netflix 电影评分数据集。该数据集包含了 Netflix 系统从 1999 开始的 6年间记录的近50 万用户对 17000 多部电影的评分数据。系统使用 5 分评分制,评分值可为:1、2、3、4 和 5。数字越大则代表用户对电影评价越高。Netflix 电影评分数据集包含了一下几个文件:
1、MOVIE TITLE:包含数据集中所有影片的一些基本信息,如影片名称,上映时间等。
2、TRAINING DATASET:作为提供给参赛者或者研究者进行推荐算法实验的训练集,包含了用户 ID、电影 ID 和用户评分等关键信息。
3、QUALIFYING DATASET:未包含评分的测试数据集合,提供给参赛者作其设计系统的评分预测对象。
4、PROBE DATASET:上个数据文件的包含用户真实评分的版本,以让学术研究者对评分预测结果进行准确度评测。
(2)MovieLens数据集
电影推荐系统 MovieLens 由 Minnesota 大学开发。MovieLens 电影评分数据集包括了该电影推荐系统中用户对电影的评分等相关数据,评分值同样为 1 到 5 的整数,该数据集按数据规模的不同,存在 3 个版本:
・A. MovieLens 10M:规模最大的版本,记录了 72000 个用户对 10000 部电影的一千万条评分及相关数据,总大小为 10M 左右。
・B. MovieLens 1M:中等规模版本,记录了 6000 个用户对 4000 部电影的一百万条评分及相关数据,总大小为 1M 左右。
・C. MovieLens 100K:规模较小的版本,记录了约 1000 个用户对近 1700 部电影的十万条评分及相关数据,总大小超过 100K。
在本文中,由于时间的有限和资源的有限,我们采用离线实验的方法,并且采用MovieLens数据集10M的版本。这主要是因为,在10M的版本中,MovieLens数据组提供了标签数据,利用这些标签数据我们可以省去标签特征向量抽取的过程。
3.3 短视频推荐方法
在确定好要使用的数据后,我们采用Matlab来进行模型验证。
首先,我们的实验数据验证方式是:将视频数据集划分为两部分(90%训练数据,10%测试数据),通过对于这两部分数据的划分,用户对于视频的浏览记录也将分为两部分。对于有些用户的数据完全在训练集里,完全在测试集里或者在测试集里数目过于少,这些用户将被过滤掉。我们的训练集模拟在特定时间点用户的过去浏览历史,我们的测试集模拟用户未来将会感兴趣的电影集。视频推荐算法通过对于训练集里用户浏览记录的学习,得到用户的Profile,再经过测试集内部全部视频相似度计算,得到推荐视频,之后我们将我们产生的推荐视频与用户在测试集里实际数据进行对比,产生结果。
为了在Matlab上完成上述,我们必须分步骤地进行,因为数据量实在巨大(视频数据条数10681条,浏览历史个数10000054条)分步骤可以很大程度上减轻计算复杂度。我们的实验分为以下四步骤进行:(1)pre预处理(2)step1完成用户的profile提取(3)step2对用户产生推荐结果。
1、pre预处理。首先,因为MovieLens数据格式是他们固有格式的,我们需要把这些数据导入到Matlab中,以便于后续数据处理。我们将MovieLens的原数据三个文件ratings.dat,movies.dat,tags.dat转换为ratings.mat.movies.mat,tags.mat;接着,我们将tags和movies两张表进行联合在一起,产生movies_tags表格,因为我们的标签是绑定在movie上的;再然后,我们要从电影数据里面抽取实验组所用的实验集,我们通过Matlab的随机数函数产生1000个视频id为实验组视频id。由于视频被划分为了实验组,那么用户的评分数据也就需要将对于对应电影的评分数据纳入实验组中。其余的视频以及评分数据均为训练集。
2、step1完成用户的profile提取。首先,不是所有的用户数据都是有用的数据。比如有些用户的浏览数据全部集中在训练集或者测试集,以及有些用户的测试集数据数目过少,这些无用用户数据要全部过滤掉;接着,在有用的用户数据里,我们需要从他们的训练集浏览记录中获取所观看电影的标签,将这些标签加入用户的标签集,并且计算这些标签的TF-IDF权值。由于这个计算量过于巨大,我们将权值计算函数进行了性能优化,加入哈希算法来提升了它的时间复杂度。图3-7为我们的权值计算流程图。
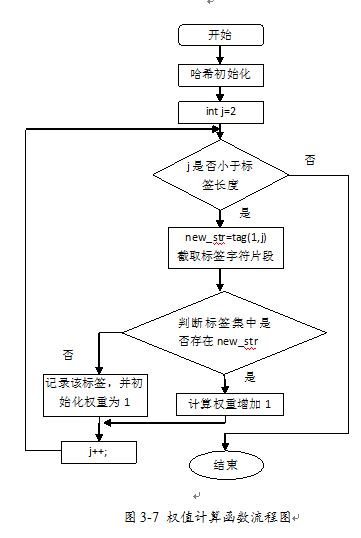
3、step2对用户产生推荐结果。在这一步中,我们需要将电影的标签向量和用户的标签向量进行余弦相似度计算,从而得出两者匹配分值。由于Matlab丰富的数学计算能力,这个模块很容易实现,之后我们使用简单的排序算法去计算出用户的推荐视频排名。
 |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
