




















社交网络中基于群组的个性化位置推荐
摘要:本文提出了基于群组的个性化位置推荐系统,这个系统可以为用户提供基于其个人偏好的在一定地理范围内的位置推荐,通过位置的聚类解决数据稀疏性问题,通过用户的聚类解决推荐效率的问题。本系统分为离线计算和在线计算两部分:离线计算部分通过将用户和位置分别聚类为群组的方法来缩小求解空间,使用加权分类层次结构和迭代的机器学习方法为每个用户建立偏好模型;在线计算部分结合用户的社交关系并根据加权分类层次结构推测出用户的偏好进行个性化位置推荐,使用R树来快速地在大规模的地点中找到一定范围内的位置,结合协同过滤算法计算得到排名前N的位置推荐给用户。
关键词:基于位置的社交网络;基于位置的服务;位置推荐系统;聚类算法;协同过滤
第1章 引言
1.1 研究背景
截至2015年6月底,中国网民规模达到6.68亿,其中手机网民数量为5.94亿,互联网普及率达到48.8%[1]。飞速发展的移动互联网使得移动设备的用户可以为自己的活动添加“位置”这个维度,扩展了用户在互联网上的表达方式,因此,基于位置的社交网络如雨后春笋般出现,比如国外的Facebook、Foursquare和Twitter等,以及国内的新浪微博、大众点评和人人网等。
用户的位置记录是对用户做出位置推荐的重要依据,但是如何使用它们来推测一个位置对于用户的重要性是一个非常有挑战性的问题。例如,在本文实验所使用的Foursquare数据集中,纽约用户的位置记录如图1.1 a)所示,洛杉矶用户的位置记录如图1.1 b)所示,可以看到纽约用户在纽约地区的位置记录有96082条,而在洛杉矶地区的位置记录仅有5965条,同样,洛杉矶用户在洛杉矶地区的位置记录有130507条,而在纽约地区的位置记录仅有18238条,因此,为纽
约用户推荐洛杉矶的位置和为洛杉矶用户推荐纽约的位置都是很有挑战性的。
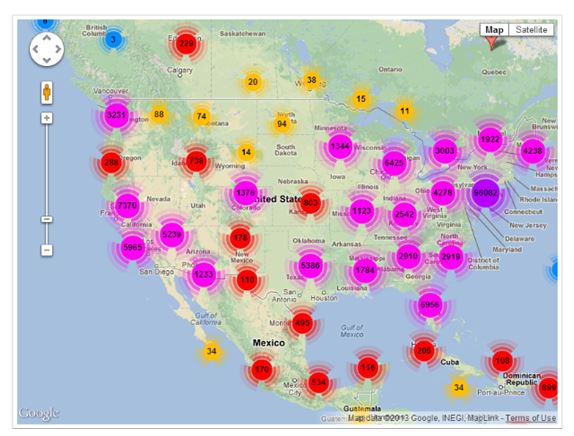
a) 纽约用户的位置记录
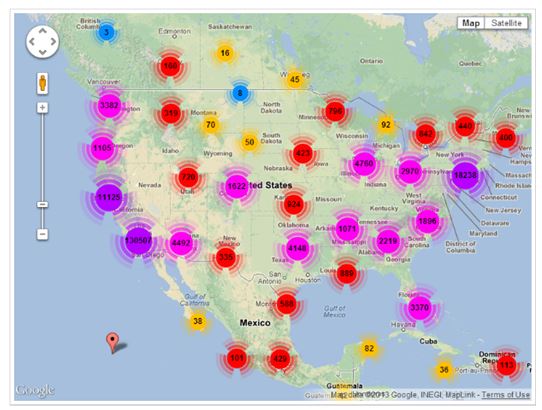
b) 洛杉矶用户的位置记录
图1.1 纽约和洛杉矶用户的位置记录
1.2 技术路线
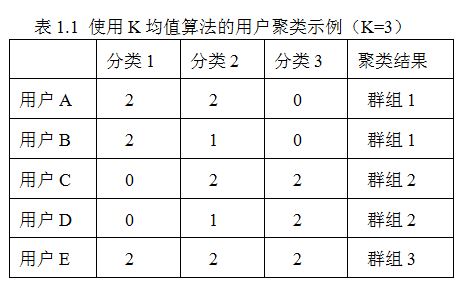
本文提出了基于群组的个性化位置推荐算法,群组的含义有两个:一是位置群组,即将位置聚类为群组,在位置聚类中,层次聚类方法是最好的选择。二是用户群组,即将用户聚类为群组,在用户聚类中,K均值算法是比较好的选择,因为一般来讲用户的兴趣是多元的,K均值算法可以使得拥有最多相似兴趣的人聚类成为一个群组,比如表1.1所示的情况。个性化是指通过构造加权分类层次结构(Weighted Category Hierarchy,简称WCH)分析用户的真正的兴趣点。所谓位置推荐是指在用户指定的地理范围内为用户推荐距离较近且与用户相关性较大的位置。
本论文的主要贡献如下:
第一,设计了一个基于群组的个性化位置推荐模型,可以在基于位置的社交网络中为用户推荐实时并且个性化地位置,且该模型比较简洁,具有良好的通用性和扩展性。
第二,使用层次聚类方法对位置进行聚类,并使用加权分类层次结构学习用户的兴趣,这可以有效地解决实际数据集中的数据稀疏性问题。
第三,使用K均值聚类方法对用户进行聚类,并使用协同过滤模型计算一个位置的得分和排名,将用户聚类为群组的方法兼顾了效率和准确性。
第四,使用基于Foursquare的一个数据集对本文提出的推荐系统进行实验,实验结果表明本系统比现有的推荐系统更加高效和有效。
第2章 系统概览
2.1 问题定义
位置推荐的问题定义和普通的推荐模型不同,普通的推荐模型只需要项目的集合即可进行推荐,但是位置推荐还要结合用户的社交关系和位置记录,并且可以根据一定的地理范围推荐位置。位置推荐的问题定义如下:
输入:用户集合U,每个用户ui的位置记录v的集合V,用户关系集合R
输出:为用户u在地理范围r内推荐的前N个没有去过的位置的集合Vk

图2.1是位置推荐的问题定义的一个简单示例,a)图表示输入,比如本例中用户1去过位置A共3次,去过位置B共1次,用户1和用户2、3是好友关系;2)图表示输出,假设A、B、C三个位置都在地理范围r内,比如本例中为用户4推荐了两个位置B和A,其排序是根据用户与位置的相似度来进行的,位置B排在A前面的原因是用户4只与用户3是好友关系,用户3去过位置B,没有去过位置A,所以认为用户4与位置B的相似度较大,由于用户2去过了所有的地方,根据问题定义,不会为他推荐本例中的三个位置。
2.2 系统架构
本章介绍基于群组的个性化位置推荐系统架构,如图2.2所示,本系统分为离线计算和在线推荐两部分。
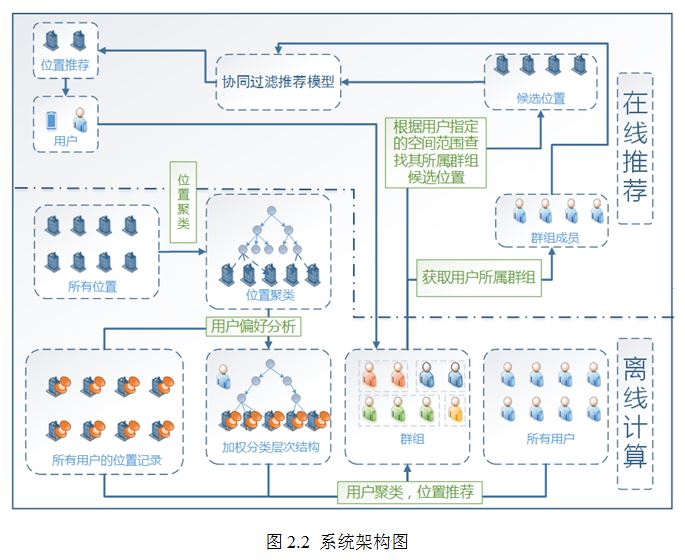
本系统主要具有如下特点:
1)有效克服数据稀疏问题。由于本系统采用了对位置进行聚类的方法组织位置,所以用户-位置矩阵被用户-分类矩阵所替代,矩阵维数大大减少,可以克服由数据稀疏性带来的矩阵维数大且非常稀疏,不利于计算的问题。
2)推荐效率高。由于本系统采用了对用户进行聚类并为群组推荐位置的方法,所以求解空间比传统的推荐系统要小,尤其在对效率影响最大的协同过滤算法上,由于通过群组获取到的候选位置集数目比通过传统方法获取到的要少很多(这主要取决于群组的数目),而且质量差不多,所以推荐效率要比传统方法高。
3)通用性和扩展性好。本文提出的推荐系统框架是基于对现有的推荐系统的研究基础上的,并且加入了一些新的优化策略,比如用户聚类、位置聚类等,之所以说本系统的通用性和扩展性好是因为系统中的很多策略都是可以个性化定制的,因为不同的基于位置的社交网络的定位不同、用户习惯不同,我们不能用同一组参数为不同的社交网络中的用户作推荐,但是可以使用同一个推荐系统框架,在其中设置更适合该社交网络的方法和参数。
第3章 离线计算
3.1 位置聚类
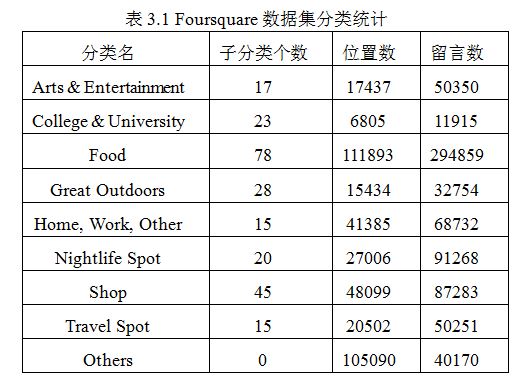
对位置进行聚类的方法很多,最简单也是最准确的就是用目录结构对位置进行聚类,因为目录可以反映用户的兴趣,比如爱好看电影的人就会在“电影”目录下签到很多次;也可以采用基于用户访问相似度的K均值方法进行位置聚类,但是这样的坏处是不够直观,聚类得到的结果不能准确地反映用户在现实世界中的兴趣。比如本文实验中使用的Foursquare数据集中的位置的分类如下:
3.2 用户偏好分析
进行用户偏好分析首先要构建加权分类层次结构(Weighted Category Hierarchy,简称WCH),WCH是在对位置进行聚类的基础上对用户的位置记录进行归类得到的树状结构,WCH的每个节点代表位置分类结构中的一个分类,用户去过一个分类中的位置的次数作为该节点的初值,这里需要注意的问题是分类的粒度,即用户去过一家中餐馆A,那么A属于中餐馆这一分类,而中餐馆又属于食物这个分类,那么用户去过A的这一记录会被加到中餐馆、食物这两个分类中。
构建好初始WCH后就可以用TFIDF方法对WCH进行再计算了,TFIDF方法是信息检索领域使用较多的方法,它通过统计一个词在文档中出现的频率和这个词在所有文档中出现的频率的倒数之积来衡量一个词在一篇文档中的重要性,而应用到用户偏好分析中,可以把分类看作词,把用户的历史记录看作文档,通过计算TFIDF值就可以得到一个分类在用户的历史记录中的重要性,进而可以获知用户的偏好,这样一来,用户访问过的最多的分类就不一定是用户真正的偏好了,比如一个用户的WCH如下,通过计算TFIDF,我们可以发现食物目录的访问次数虽然最多,但是其TFIDF值小于艺术,可以认为用户更喜欢艺术。
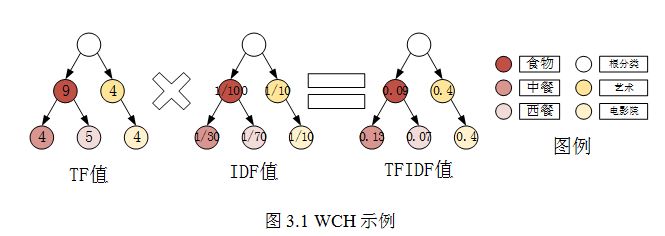
图3.1仅仅是一个非常简单的示例,实际操作中,一般采取更复杂的TFIDF方法来计算WCH中的用户偏好的得分,比如本文采用的是公式(3-1)所示的计算方法。
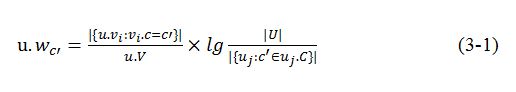
其中 是用户u访问分类c'的次数, 是用户总访问的次数, 记录了在系统里所有用户U中访问过分类c'的用户的数量。
3.3 用户聚类
对用户进行聚类是本文提出的新的方法,它可以有效地提高推荐效率,同时保持较高的有效性。典型的聚类过程主要包括数据准备、特征选择和提取、相似度计算、聚类等步骤,本文所采用的用户聚类方法也遵循此步骤。
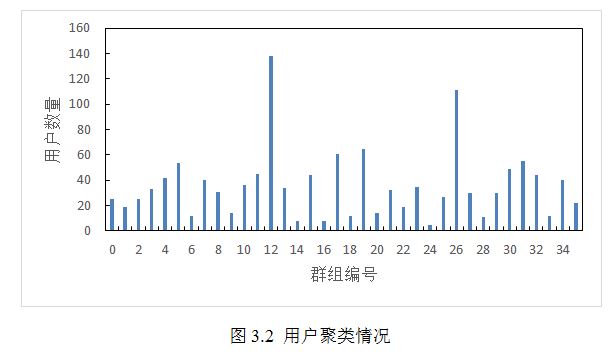
本系统采用的用户聚类方法是K均值算法,使用用户WCH中一级分类的值(该值表示用户对这个分类的偏好程度)作为特征值,本实验数据中一级分类有9个(参见表3.1),用户对于每个分类都有一个特征值,此特征值就是用户对于该分类的偏好程度(参见3.2节),相似度计算方法采用经典的欧拉距离,聚类个数K取一个大于9的数(本文取36),这样运行K均值聚类算法就可以得到用户的群组,且每个用户只属于一个群组,如图3.2所示。将用户聚类为群组之后就可以为该群组推荐位置了。
3.4 为群组推荐位置
为群组推荐位置是一个相对独立的研究方向,比如[2]和[3]都提出了有效的群组推荐模型,但是它们都是计算了所有位置与群组中所有用户的相似度之后,甚至还要计算群组中所有用户的相似度和不相似度之后,才能够使用群组推荐模型对群组进行位置推荐,这样的做法的效率是很低的,而且由于本文的目的在于研究个体的个性化位置推荐,所以使用过于复杂的群组推荐算法是没有必要的。本文提出了一个简单但是有效的解决方案:使用群组成员去过的所有位置作为为群组推荐的位置,另外加上评价很高的一些位置。使用前者的原因是群组成员的兴趣比较接近,可以认为其他成员去过的位置也会是待推荐用户喜欢的位置;使用后者的原因是一些评价很高的位置也可能是用户所喜欢的。
本文使用 来表示一个位置的得分,初始值是该位置被访问的次数,使用 来表示一个用户的得分,初始值是该用户去过的位置的总次数,可以使用公式(3-2)和公式(3-3)来迭代地计算位置和用户的得分:
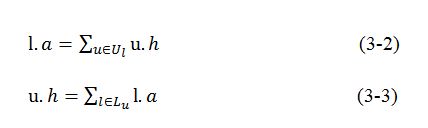
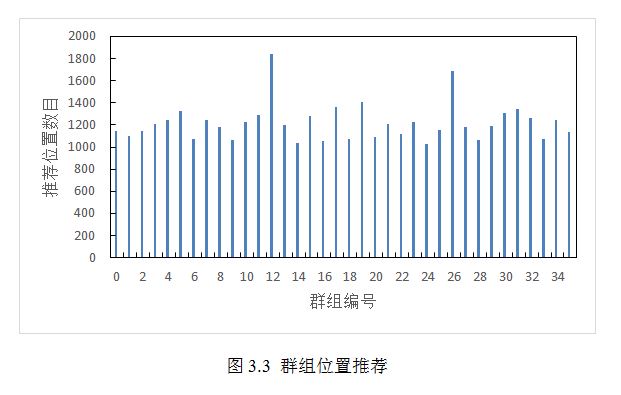
通过这个迭代算法就可以筛选出评价较高的位置,将这些位置也加入对每个群组的推荐之中对于一个实际的推荐系统来说非常重要,对于本文实验而言会影响系统的有效性和效率。图3.3展示了为每个群组推荐的位置的数量分布。
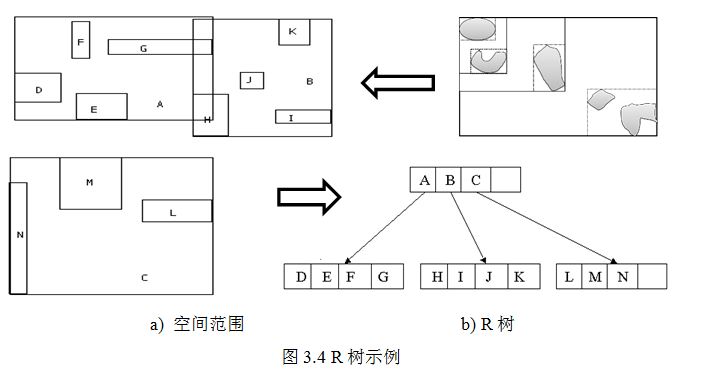
为了在线推荐部分可以高效地搜索到在一定地理空间范围内某个群组的候选位置,本系统使用了R树结构来对群组的所有候选位置建立索引结构,R树是Guttman[15]在1984年提出的一种空间索引结构,它类似于B+树,是一种高度平衡的树,R树是由一系列元组(tuple)组成的,每个元组有一个唯一的标识符,代表了一个空间对象,而标识符可以用来检索这个元组。图3.4展示了一个简单的R树示例。
本系统中,由于用户群组的存在,在线推荐部分进行位置搜索时无需搜索用所有的位置构建的R树,只需要搜索相应群组的所有的候选位置构建的R树即可,这样做的好处是既实现了只在相应群组的候选位置集中选择候选位置的设计,又因为R树规模变小而加快了搜索效率。
第4章 在线推荐
4.1查找用户所属群组
在3.3节中将用户聚类为群组之后,可以把用户所属群组的标号加入到用户的属性中,这样就可以在在线推荐部分快速找到一个用户都属于哪些群组。另一种方案是使用倒排索引,将用户作为主键,将用户所属群组作为值,通过哈希方法对主键进行排序,当一个用户发起位置推荐请求后,可以通过倒排索引快速地找到该用户所属的群组。
4.2查找用户所属群组的在一定范围内的候选位置
在确定了用户属于哪个群组之后,就需要在用户指定的地理空间范围内搜索该群组的候选位置,如3.4小结所介绍的,本系统使用R树来为位置作索引,所以只需要在群组对应的R树上进行搜索即可。
R树的搜索算法是一种迭代算法,如3.4节所述,极端情况下算法的性能可能很差,但是通常情况下算法可以较快地搜索到指定范围内的所有位置。但是通过该搜索算法获取到的候选位置可能非常多,其中有一些是用户显然不会访问的,应该过滤掉这些候选位置,3.2节的用户偏好分析为我们提供了一种过滤方法,即分析每个候选位置所属的分类,如果该用户对这个分类没有兴趣(对应该用户的WCH中该目录所对应的节点的值为0),则认为这个候选位置是不必要的,可以被过滤掉,在实验中通常可以过滤掉20%以上的候选位置。筛选后的候选位置将与该群组的所有成员一起被协同过滤算法计算,获取每个候选位置与发起推荐的用户之间的相似度。
4.3协同过滤算法
如1.2节所述,协同过滤算法可以为用户没去过的位置打分,分为基于用户的协同过滤算法、基于项目的协同过滤算法和基于模型的协同过滤算法。基于用户的协同过滤算法首先需要找到与发起推荐的用户兴趣相近的一组用户,然后计算这组用户对于待推荐的位置的得分的和作为该用户对于该位置的得分,这种方法的缺点是随着用户数量的增加,算法的计算时间会变长,为了解决这个问题,基于项目的协同过滤算法被提出来。该方法认为能够让用户感兴趣的项目一定与该用户之前评分高的项目相似,因此可以通过计算两个项目之间的相似度来计算用户与项目之间的相似度,这种方法虽然可以解决用户数量增加带来的计算量的增加的问题,但是仍无法解决数据稀疏性、冷启动等问题。基于模型的协同过滤算法是指通过历史资料得到一个模型,然后利用此模型进行预测。
在基于位置的社交网络中,用户之间的关系是一种非常重要的关系,同时位置与位置之间的关系也非常重要,而构建模型不是一种有良好通用性和扩展性的方法,所以本系统采用了基于用户的协同过滤算法和基于位置的协同过滤算法,并在实验中对两个方法的性能进行了对比。
基于用户的协同过滤算法可以用公式(4-1)来简单表示:

其中,u’是u所在群组中访问过位置v的用户, 表示发起搜索的用户u与群组中用户u’的相似度,计算这一相似度的方法将在下文介绍; 表示用户u’访问过位置v的次数。通过公式(4-1)的计算,我们就可以得到用户u和位置v的相似度,也就是用户u可能对位置v的评分。
那么,如何计算两个用户的相似度呢?如第三章所述,衡量用户之间相似度的方法有很多,比如考虑两个用户共同好友相似度(记为Sim1)、关系深度相似度(记为Sim2)、位置记录的相似度(记为Sim3)、常用词的相似度(记为Sim4)、加权分类层次结构的相似度(记为Sim5)等。本文采用的是它们的加权和作为两个用户的相似度评分,并会在实验中加以讨论使用不同评分方法对于推荐效果的影响。下面分别介绍如何单独计算这些相似度,再介绍把它们的加权和作为总相似度的公式,需要注意的是,除了加权分类结构相似度使用了余弦相似度计算方法,其他相似度都没有使用余弦相似度,因为余弦相似度的计算量较大而且实验结果表明本文使用的相似度计算方法更加有效。
在计算两个用户的相似度(记为Sim)时,需要为以上5种相似度选择合适的权值,分别记为a1、a2、a3、a4、a5,这五个权值需要满足公式(4-2)所示的关系。
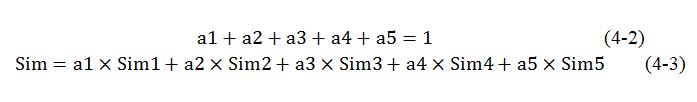
公式(4-3)是最终计算用户相似度的公式,这是一个加权和公式,具体的权值可以根据数据集的不同特性来选择,本文实验部分将讨论权值的选择问题。
计算两个用户的相似度之后就可以利用公式(4-1)对用户与位置之间的相似度进行计算了,本系统采用的方法是一种简化的策略,因为没有迭代过程。事实上,公式(4-1)可以变形为公式(4-1’)以获得更好的协同过滤效果。
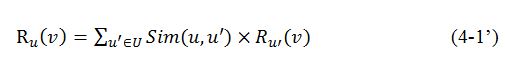
公式(4-1’)是一种迭代计算模型,初始可以令 ,即用户与位置的相似度的初值是用户去过此位置的次数,然后通过公式(4-1’)可以迭代地计算用户与位置的相似度,这样计算得到的结果更符合基于用户的协同过滤算法的原则。但是本系统没有采用这个模型,原因在于在线推荐部分对效率要求很高,而迭代模型效率很差,所以公式(4-1’)只适合做离线计算,而不适合在线推荐。
基于位置的协同过滤算法可以用公式(4-4)来简单表示:
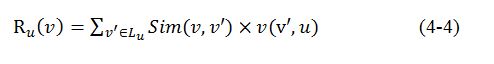
其中,v’是用户u访问过的位置, 表示位置v与v’的相似度,计算这一相似度的方法将在下文介绍; 表示用户u访问过位置v’的次数。通过公式(4-4)的计算,我们就可以得到用户u和位置v的相似度,也就是用户u可能对位置v的评分。
4.4 将推荐结果返回给用户
在计算了用户与所有候选位置的相似度之后,对这些候选位置根据相似度排序,将前N个结果作为推荐位置返回给用户即可。本文没有采用Top-k算法作位置推荐,第5章的实验表明,即使没有Top-k,本文提出的推荐方法依然能够极其高效地工作。
 |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
