




















Reducing and Balancing Flow Table Entries in Software-Defined Networks【2】
3.4 Cost Function
The cost function is a piecewise function used to simulate the nonlinear impact of a link load on the network congestion in internet traffic engineering [9][21]. As shown in [9], we can use the cost function (7) to simulate the nonlinear impact of the flow table usage increase on the controller's workload.:
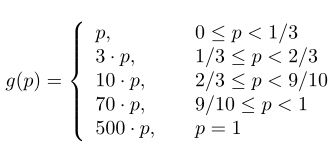
The cost function is used for all switches, and p is the utilization of the flow table on the switch. With the increasing number of the entries installed on the switches, the value p also increases.
3.5 Problem Formulation
The problem of reducing and balancing flow table entries in SDN switches when many new flows appear at the same time in SDNs is formulated below:
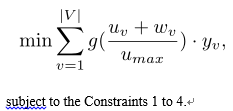
The Equation (8) is the objective function to reduce and balance the flow entries in SDN switches by minimizing the cost function for all switches. It should satisfy the Constraints 1 to 4.
3.6 Complexity Analysis
The cost function $g(p)$ is a integer linear function, then our problem can be reduced to the Mixed-integer programming problem. So our optimization problem is at least as hard as Mixed-integer programming problem. The Mixed-integer programming problem is an NP-hard problem, so the problem of reducing and balancing the flow entries in SDN switches is also NP-hard. The solution space of our problem is O(2^{|V||F|}), where |V| is the number of nodes in the network, |F| is the number of flows in the network.
Therefore, to efficiently solve the problem, we propose a greedy algorithm to get the approximate optimal results.
4 Heuristic Algorithms
Section 3 shows that the problem is an NP-hard problem. We propose the KSGT algorithm to get the approximate optimal results. In this section, KSGT firstly divides all flows into some clusters based on the coincidence degree of the forwarding paths of the flows. Secondly, KSGT greedily selects a small number of switches from the forwarding path to install entries. Moreover, KSGT just greedily enumerates the possible schemes of the flows in each cluster to achieve the optimal solutions of the cluster. So the KSGT does not have high time complexity since it does not enumerate all of the solution space. Finally, we use a phase function to balance the flow table entries of different switches. Hence, KSGT can effectively reduce and balance the flow table entries of switches even though many new flows arrive in the network at the same time...
4.1 The Outline Of The KSGT Algorithm

The cluster-k denotes the flows in the k-th cluster. The flows in the same cluster have high coincidence degree of forwarding paths. We use the scheme(c_f) to denote the two optimal schemes of installing flow entries for flow c_f, for example, s1 and s7 is a scheme for flow c_f in Fig. 1. We use scheme-cluster(k) to indicate some optimal schemes for flows in the k-th cluster. The inputs of KSGT algorithm are the network G = (V,E) and the node vector of each flow, the output is the number of entries to be installed for all flows and the corresponding nodes. The algorithm has four phases: the first phase is to classify the flows according to the number of overlapping nodes by K-Similar algorithm; the second phase is greedily select two schemes for each flow; the third phase is to use the cost function to evaluate the possible schemes of the flows in each cluster to achieve some optimal solutions for every cluster; the fourth phase is to combine each of the two clusters into one until only one remains. Then we can get the optimal results by the algorithms.
4.2 Phase 1: Flow Classification

The inputs of algorithm 2 are the network G = (V,E) and the flow set F. The outputs are $k$ clusters, and each cluster contains no more than 12 flows. The algorithm is similar to the k-means algorithm [10]. As shown in the algorithm 2, the center of each cluster is set in the line 3-4. The line 6-8 puts each flow into the corresponding cluster according to the number of overlapping nodes, and the functionnumber(f\bigtriangleup c_k) calculates the number of overlapping nodes between flows vector f and c_k. If flow f has the equal function value with the center vector of cluster j and k we map it to the smaller cluster. We recalculate each center vector of the clusters in line 9-11. Line 5 means that the algorithm breaks and returns the result when there is no significant change in the clusters.
4.3 Phase 2: Routing a Single Flow f

The input of the algorithm 3 is the node vector cf of the flow f, the output is two schemes of the flow. Line 4 means that it must select the first node to install an entry. Line 5 sets up MPLS headers that do not exceed 5. Line 6 insures that it selects two schemes whose nodes do not completely coincide. In line 7-10, it greedily selects one scheme to install flow entries for the flow f. In line 11, it records the scheme, and then the number of MPLS labels minus 1 in line 13. For example, in Fig. 1, the scheme nodes={s1,s7} is one scheme flow f.
4.4 Phase 3: Getting the Optimal Solution in the k-th Cluster
The inputs of algorithm 4 are the k-th (k in [1,K]) cluster and the number of iteration times. The output is some optimal schemes for each cluster. Just as an element in scheme(c_{number}) is one installing flow entry scheme for flow c_{number}, an element in scheme-cluster(k) is one installing flow entry scheme for all flows in the k-th cluster. In line 11-17 of the algorithm, we calculate the objective function for switches of a scheme in the k-th cluster. In line 18 we record the value of objective function and the corresponding switches of the flow entry installation scheme.
4.5 Algorithm Performance Analysis
We now analyze the complexity of the KSGT algorithm. In order to improve the performance, we have some technical implementation details in the algorithm. We usually set the while loop in the K-Similar(G) algorithm (Phase1) to calculate within five times, then it can meet other Phases demand. Therefore, the computational complexity of Phase 1 is O(5?(|F|?len(cf)+K ? len(cf))). The computational complexity of routing a single flow f (Phase 2) is O(|F|?len(cf)?steplengh). The computational complexity of getting the optimal solution in the k-th cluster (Phase 3) is O(|F|?len(cf)?K). The computational complexity of combine every two clusters to get the optimal solution (Phase 4) is O(K). Therefore, the total computational complexity of the KSGT algorithm is O(|F| ? len(cf) ? (K + steplengh)). As shown in the KSGT algorithm, the space complexity of which is O(|F|?len(cf)) because only the number of the flows and the vector of nodes that flows go through need to be saved..
 |  |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
