




















跨平台的音乐推荐算法【2】
4. 实验描述
4.1 数据集
首先,我们先建立了一套完整的用于进行跨平台音乐推荐研究的数据集,不同于以往的单独的新浪微博数据或网易云音乐数据,我们构造了一组微博-音乐联合数据集。我们通过爬取新浪微博和网易云音乐上的数据,从中选取了1,425个同时拥有新浪微博和网易云音乐的原始用户,为保证用户是活跃用户,我们要求被选取的用户至少有2页微博数据(90条以上微博)和20首以上听过的歌曲,然后提取这些用户的前5页微博数据和他们喜欢听的前10首歌曲(网易云音乐对每个用户有一个按听歌次数排序的功能),并把它们共同作为一个用户的描述,最终得到了1,257个活跃用户。在这份数据集中,我们的数据总量是超过220,000条新浪微博的数据和9,271首歌曲,微博数据大小达到了4G以上,音乐数据达到了28G以上,基本满足了整个实验的数据要求。
4.2 特征提取过程
对于每个用户我们要提取出它的文本特征(即新浪微博)和音频特征(即喜欢听的歌曲),文本特征我们选取了经典的TF-IDF文本特征[4],特征向量共有6,000维,这其中去除了相对比较常用的词和不常用的词,选取了一些比较有代表性的词频中等的词语。我们把每个用户的全部微博数据通过TF-IDF特征提取后作为该用户的文本特征向量。
音频特征我们选取了IS10特征集[7],可以用opensmile软件提取出来,共有1582维。这其中包含了音频的音色、音调、旋律、节奏、响度各个方面的数据,1582维的具体含义这里不再赘述,具体可参见opensmile说明文档。
这样,对于每个用户,我们获得了他文本特征的6000维数据和他喜欢的每首歌曲的1582维音频向量,这些数据会被输送到下一环节作为训练集。
4.3 算法训练过程
本实验使用的算法是线性CCA算法,整个算法的流程可以描述如下:将每个用户喜欢的每首歌作为一个训练样本,每个样本包括6000维文本向量和1582维音频向量,将这两组向量共同投影到同一个隐空间中,我们的学习目标就是这两组向量投影到隐空间的投影矩阵。学习过程结束后,我们对于一个新用户的微博数据,我们先将其投影到这个隐空间中,然后找到这个投影向量最近的几个音频投影向量,这里我们使用余弦相似度计算隐空间中向量间的距离。它们对应的歌曲就是最终我们要推荐给用户的歌曲。这就完成了整个训练和预测的过程。在整个实验过程中,我们将选取900个用户作为训练集,357个用户作为测试集用于检验算法的准确程度。
4.4 算法评测指标
本实验算法评测的指标共有3个:平均命中率(Average Hit Rate),加权平均准确率(Mean Average Rate,MAP),召回率(Recall Rate),具体做法如下:首先选择N首歌作为音乐全集,将这N首歌和每一位用户喜欢的前10首歌共同做一个推荐给该用户,排出系统的推荐顺序,然后按照这个顺序计算上述三种指标,其中,平均命中率是计算推荐给用户的前10首歌中有几首是用户原本就喜欢的,召回率是计算推荐给用户的前k首歌中用户原本喜欢的前10首歌的数目,本实验中k=20, 30,加权平均准确率相对定义比较复杂,它是对每个用户i喜欢的前10首歌的顺序(1,2……10)与它们在推荐结果中的顺序(r_1,r_2,……r_10)的比值做平均,计算出每个用户i的平均准确率〖AP〗_i,然后对每个用户的AP再做平均获得全体用户AP的平均值。这个指标越接近1说明推荐的越好。这三个指标各自反映出推荐算法的一方面:平均命中率反映了算法推荐的正确程度,MAP反映了算法推荐的精度,召回率反映了算法推荐在各个层次上的正确程度,比平均命中率预测的范围更广。另外,在本实验中N=10, 50。
4.5 实验结果
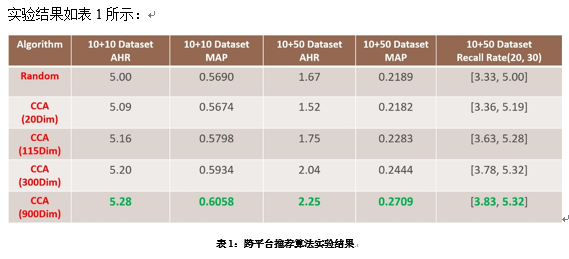
在这里对表格中的内容做一个简要的说明,本次实验共包含了5个算法,第一个是完全随机预测,第二个到第五个都是CCA算法,隐空间维度由20维逐渐增加到训练矩阵的秩900维。我们也同时采用了5组指标,前两个是10首公共歌曲+10首用户最喜欢的歌曲共20首歌曲推荐的平均命中率(AHR)和加权平均准确率(MAP),后三个是50首公共歌曲+10首用户最喜欢的歌曲共60首歌推荐的AHR, MAP和召回率Recall Rate。
从表中可以看出,最好的算法是高维隐空间的CCA算法,在50+10数据集中推荐成功的歌曲数可以比随机算法高出0.6首歌,MAP和Recall Rate也达到了相对比其他算法更高的标准。
4.6 原型系统
本实验采用了CCA算法作为原型系统,隐空间维数为200维,这是考虑到了一个算法运行速度和精确程度的平衡而确定的算法。本系统分为两个后端和一个前端。两个后端分别为:用Java(Tomcat)搭建的网站响应后端和用Python(Flask)搭建的数据处理后端。当用户输入一个微博uid时,网站响应后端响应用户输入,并将该数据传递给数据处理后端,数据处理后端获取到用户的微博数据,经过分词和TF-IDF处理获得文本向量,将其投影到隐空间后,找到与之距离相近的前N首歌,用字符串形式返回给网站响应后端,最后,网站响应后端访问网易云音乐获取这N首歌返回给用户,完成整个推荐过程。
本系统主要由主界面(图1)和推荐音乐界面(图2)组成。

只需要在输入框中输入你的微博uid,然后点击“授权”按钮,即可为你推荐出你可能喜欢的前10首歌曲:
本系统只是一个简单的demo,展示了本项目最基本想要实现的功能,距离商业化还需要一些用户设计上的支持。
5. 总结与展望
在音乐推荐领域,目前做的相对较好的是豆瓣FM,然而,我们也同时注意到,豆瓣FM的推荐也未能完美的解决的冷启动问题,依然是采用基于传统的音乐推荐算法的改进。而相比之下,本文所使用的算法不仅能够解决冷启动问题,还能够依靠用户的微博数据来为其做更加个性化和更加精准的推荐。另外,本系统还是一个十分灵活的应用,无论我们的音乐总量有多少,无论音乐库中的歌曲是新歌还是老歌,算法都能够平稳的运行,为用户做出精准的推荐,这在音乐推荐领域是一个创新。另外,在本实验中,我们构造了一组微博-音乐联合数据集,专门用于做跨平台的音乐推荐,这对于跨平台推荐系统的发展有重要的科研价值。然而,本次实验的成果还有这诸多的不足。这些可以在后续的研究中逐步的加强与改进。总结需要改进的地方主要有以下几点:
(1)特征提取可以得到加强。本次实验目前采用了相对比较简易的TF-IDF文本特征和IS10音频特征,由于特征数量太多,产生了过拟合的现象,导致CCA算法的精确程度并未达到一个理想的状态。在后续实验中,可以尝试LDA文本特征和mirtoolbox提取的音频特征以期达到更好的效果。
(2)事实上正如2.3节中提到的那样,除了CCA还有其他一些算法可以被用于音乐推荐,后续实验可以尝试更多种多样的算法,比如Corr-AE和Hypergraph方法等等。另外还可以将传统的基于用户历史数据的推荐算法与跨平台算法结合起来以提升推荐算法的准确程度。
(3)目前的系统只是一个简单的demo,还并不能真正的成为一个商业化的应用,在后续的实验中可以对这个系统进行改进,提升用户体验。
未来的推荐系统一定是支持跨平台的,而且是一种趋势。因为只有跨平台才能够对用户的兴趣爱好有一个更加全面准确的了解,这样推荐系统才能为用户提供更加精准的推荐。
6. 参考文献
[1] Xu C, Tao D, Xu C. A survey on multi-view learning[J]. arXiv preprint arXiv:1304.5634, 2013.
[2] Feng F, Wang X, Li R. Cross-modal retrieval with correspondence autoencoder[C]// Proceedings of the ACM International Conference on Multimedia. ACM, 2014: 7-16.
[3] Andrew G, Arora R, Bilmes J, et al. Deep canonical correlation analysis[C]//Proceedings of the 30th International Conference on Machine Learning. 2013: 1247-1255.
[4] Ramos J. Using tf-idf to determine word relevance in document queries[C]//Proceedings of the first instructional conference on machine learning. 2003.
[5] Xianyu H, Xu M, Wu Z, et al. Heterogeneity-entropy based unsupervised feature learning for personality prediction with cross-media data[C]//Multimedia and Expo (ICME), 2016 IEEE International Conference on. IEEE, 2016: 1-6.
[6] Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th international conference on World Wide Web. ACM, 2001: 285-295.
[7] Yang Y H, Chen H H. Machine recognition of music emotion: A review[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2012, 3(3): 40.
[8] Bu J, Tan S, Chen C, et al. Music recommendation by unified hypergraph: combining social media information and music content[C]//Proceedings of the international conference on Multimedia. ACM, 2010: 391-400.
[9] Cui P, Wang F, Liu S, et al. Who should share what?: item-level social influence prediction for users and posts ranking[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. ACM, 2011: 185-194.
[10] Jiang M, Cui P, Liu R, et al. Social contextual recommendation[C]//Proceedings of the 21st ACM international conference on Information and knowledge management. ACM, 2012: 45-54.
[11] Adomavicius G, Tuzhilin A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions[J]. Knowledge and Data Engineering, IEEE Transactions on, 2005, 17(6): 734-749.
[12] Cui P, Wang Z, Su Z. What Videos Are Similar with You?: Learning a Common Attributed Representation for Video Recommendation[C]//Proceedings of the ACM International Conference on Multimedia. ACM, 2014: 597-606.
 |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
