




















�������ĵ����ݷ�Χ�����㷨�����ʵ��
ժҪ
���Ŵ����ݵķ�չ�����ģ������Խ��Խ��������ĵ���ʽ�洢���Ʒ������С������ص����������Ʒ������У���ζ��Ѽ��ܵ����ݽ��п��ٵķ�Χ�������������ε����ݳ����߽����ܵ������ϴ����Ʒ��������Ʒ�����֧�ִ������û��������ݣ����ڲ��ɽ������ݼ����ҷ�Χ��ǰ���£��������������о�ȷ��ƥ�䡣���������ͨ��������ȫ�����ķ�ʽ��һά����ά���ݽ��з�Χ��ѯ��ģ�ͣ����ð����������֤�˷����Ŀ���������ȷ�ԡ�
�ؼ��� ��˽���� ��Χ��ѯ HMAC���� ��������
ABSTRACT
With the vigorous development and progress of big data, cloud server plays an important role in the data storage and processing.The paper focuses on fast range query based on the encrypted data . When trusted data owner upload the encrypted data to the cloud server, a large amount of users can search data from cloud server. The cloud server should accurately match the data range and return to the users .This paper established a fast range model based on encrypted data. With one million Twitter site data experimental verification, we prove that our model is feasible and efficiency.
KEY WORDS Privacy-Preserving Range Query HMAC Data Index
��һ�� ����
1.1 �����
Ϊ���������еĸ߿ɿ��ԡ����������ܺͿ��ٵļ�������������Խ��Խ��������Ʒ����������������Լ�����������Ƽ����У���˽�����Ϊ�ؼ���
�Ƽ���ģ�����漰����ʵ�壬���ݳ����ߺͿͻ����ǿ����εģ��Ʒ������Dz������εģ�������ݳ����ߺͿͻ��������Լ���ѯ��Χ�������ĵ���ʽ�����Ʒ�������
1.2 �����
��ǰ���Ʒ�������֧�ּ����������������������Ʒ������м��������������⽫�Ἣ��ĸ������ݰ�ȫ���Ⲣ��Ӧ��������ʵ�ʳ����У��������о������Ƿdz���ҪҲ�ǽ������������⡣����ǰ�ķ���[1,2,3,4]�������Ա�����˽���Ҹ�Ч������������������㷨������˽����������������ϣ����һ���µķ�Χ����ģ�͡�
1.3 ��Ҫ����
������Ҫ�������¹��ף�
1��������һά��������ģ�ͻ�����������µĶ�ά��������ģ�͡�
2���Զ�ά����ģ�������˴����͵��Ż���ʹ����Ч������������ߡ�
3������˽���ά����ģ��Ӧ�õ�KNN[5,6]��K�ڽ�����������ʵ��Ӧ�ó����У������ʵ�ʵ��������⡣
1.4 ����ģ��ϵͳ�ܹ�
����һά���ݺͶ�ά���ݣ����Ƕ�������ͼ1-1��ʾ������ģ�ͣ����ģ����Alex�������[7]��
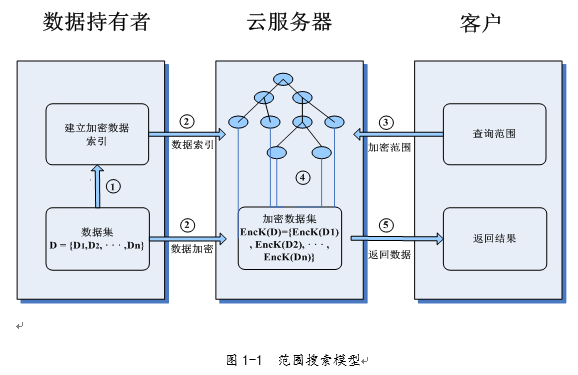
������������ͼ�б�����
�������ݳ���������ԭʼ���ݼ�����һ����������������
�����ݳ������öԳ���ԿK��ԭʼ���ݼ����м��ܣ��õ��������ݼ��������������ݼ��Լ���һ���õ������������ϴ����Ʒ�������
�ۿͻ��˽����ҷ�Χ����HMAC���ܺ��ϴ����Ʒ�������
���Ʒ������ü�������������������Χ���в��ҡ�
���Ʒ���������ѯ���ļ������ݷ��ظ��ͻ����ͻ����öԳ���ԿK�Լ������ݽ��н��ܣ��õ�ԭʼ���ݡ�
�ڶ��� һά��������ģ��
��Ӧ����һ�µ�ϵͳ�ܹ������¶�һά��������[7]��Ҫ�����ݳ����߽��������������ͻ����ϴ�������Χ���Ʒ��������з�Χ��ѯ����������������ۡ�
2.1 ���ݳ����߽�����������
��������������Ҫ�����������裺
1.����ǰ���룺��ԭʼ���ݱ�ʾ�ɶ�������ʽ��������������������е�ǰ���ǰ���뼯�ϡ�
2.����ƽ�����������������������һ���е�ǰ���뽨��һ��ƽ���������������ʽ�����ݴ�С˳���أ��Ӷ���֤�����ṹ���ɷֱ��ԡ�
3.����HMAC����[8]��ӳ�䵽Bloom Filter[9]��������һ���н�����ƽ��������ڵ�Ԫ�أ����ݵ�ǰ���룩����HMAC���ܡ����ڸ��ڵ㣬ʹ��H����ͬ��Կ��ԭʼ���ݽ��м��ܣ�����������ÿһ������һ��v.R����������ж��μ��ܣ��Ӷ������ڵ����ͬԪ�ص�����ԡ��������ܵ�ֵӳ�䵽һ��Bloom Filter��λ�����У��Ӷ���С���������Ŀռ��С��
2.2 �ͻ����ϴ�������Χ
�ͻ����������ݳ�������ͬ��ǰ���뷽�������ݷ�Χ����ǰ���룬����ѯ��Χת��Ϊ��С��ǰ���뼯S(a,b)��ʹ������ϵ�ǰ�����٣��ҿ��Ա�ʾ�����Χ����S(a,b)ͬ���������ݳ�������ͬ����Կ����H��HMAC���ܣ������ܵ����ݼ��ϴ����Ʒ�������
2.3 �Ʒ��������з�Χ��ѯ
���ڿͻ��˴����ļ���������Χ���Ʒ�������ÿһ����������������������ÿһ���ڵ����Bloom Filter��ƥ�䣬��ƥ������жϸýڵ��µ�Ҷ�ӽڵ��д������㷶Χ�����ݣ����������������ֱ��������Ҷ�ӽڵ㣬�Ʒ�������Ҷ�ӽڵ�ָ������ݴ����ͻ��ˣ�����������̡�
������ ��ά��������ģ��
��ͬ��һά���ݵ�ǰ���룬���ڶ�ά���ݱ��IJ���դ���������ݽ���ת����
3.1 ���ݳ����߽�����������
��άģ���н�����������Ҳ��Ҫ�������裺
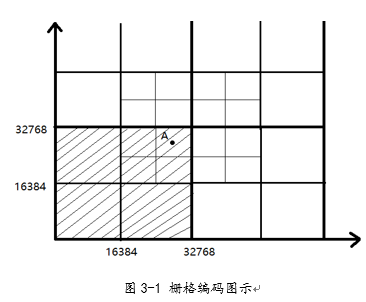
1.դ�����[10]��
���ڶ�ά���ݣ����Ľ���ά����ӳ�䵽һ��ƽ�棬�������ƽ�����դ��Ļ��֣���ͼ3-1����ÿһ������K����դ�������б�ʾ�����Ķ���դ����ø������ĵ���������ʾ�˸��ӵı��룩�������դ����롣
2.����ƽ���IJ�������������,�����ڶ�άƽ��������դ�֣�ÿһ��դ��ƽ���Ϊ�ĸ����֣�������Dz���ƽ���IJ������洢���ݵ�����������������һάģ���з�����ͬ��
3.����һ����������������HMAC���ܲ�ӳ�䵽Bloom Filter �У����巽����һά����ģ�ͷ�����ͬ��
3.2 �ͻ����ϴ�������Χ
��һά���ݲ�ͬ����ά���ݣ������λ�ã������ϴ��ķ�Χһ�����Կͻ������ڵĵ���λ��ΪԲ�ģ���rΪ�����뾶��һ��Բ��������Χ����ͼ3-2���ڿͻ���ͬ������դ�����ķ������������άƽ�����դ��Ļ��֡����Բ�ε�������Χ��������ͼ����ɫ����Щդ������Щդ������ʾ�ͻ���������Χ��

��һ������Բ��������Χ�����ǵ�դ��������HMAC���ܣ��������ܵ������ϴ����Ʒ�������
3.3 �Ʒ��������з�Χ��ѯ
�Ʒ������Զ�ά��������������һάģ�ͽ��ܷ���������ͬ���˴���������
3.4 ��ά�����������Ż�
���IJ���դ�����ķ����ѽ�������Χת��Ϊһ����Ч�ı�ʾ������Ϊ������������ʣ�������Ҫ�����������Ľṹ�����������Ż���������ͨ���Ż����������Ľṹ������Ż����Լ��������̣�����Ż����Ӷ�������������ʡ�
����Ż�ָ�����ڵĵ㾡�����䵽����������ͬһ�������У��������Լ��ٲ�ѯ��������Ϊ�����ݰ�ȫ��������ֵT����һ���ڵ������ݸ�������Tʱ���ſɽ��й���Ż���
����Ż���ָ����һ���ڵ���Ԫ��ȫ�����㷶Χʱ����ֱ�ӷ���������������Ҷ�ӽ�㡣�����Ҫ������������ʱ������ÿ���ڵ��ڵĹ���դ����룬�Ӷ�ʹ��ѯʱ���ٲ�ѯ����ȡ�
������ ʵ����֤
4.1 ʵ�����ݼ�
���Ĵ�������վ���ռ���һ������û���λ�����ݣ����ݰ����û���ID���û�λ�õ�x������y���ꡣ�����Ծ��Ⱥ�γ�ȵĸ�ʽ�洢�����Ƿֱ��������ʵ�飬ʵ��һ���ö�ά����ģ�ͽ��ж�ά���ݷ�Χ��������ʵ����Dz����Ż��Ķ�ά����ģ�ͶԶ�λ���ݷ�Χ����������ʵ�����Dz���Alex�����һά����ģ�ͽ��ж�ά���ݷ�Χ������������¼ÿ��ʵ�������������Ľ���ʱ�䣬���������Ŀռ��С����Χ������ʱ�䣬��Χ�����Ľ�����ȣ���ͨ��ʵ���ĶԱ���������ͬģ�͵���ȱ�㡣
4.2 ʵ��������
4.2.1 ����ʱ�����
������ʵ�����������ͬ������£�ͨ���ı�������Χ���ж��ʵ�飬ʵ�����������������Ż��Ķ�ά����ģ�ͽ���������Ч�ʴ�������������Ա�ʵ�飬��һά����ģ�͵�ʵ��������ʱ������ġ�
����ʵ�������֤�����������䣬�ı䰲ȫ��ֵT����TֵԽ��ʱ�������Ż��̶�Խ�ͣ�ʵ��������ʱ��Խ������T���������ݸ���ʱ������δ�����Ż�����ʵ�������ʱ����ʵ��һ��ͬ��
4.2.2 ������������ʱ�����
ʵ���У�ͨ����¼���������Ľ���ʱ���֪���Ż��Ķ�ά����ģ�͵�������������ʱ��Զ������������ʵ�����������������ʱ�䣬��������ʵ���齨��ʱ�����������һ��������ݣ��Ż��Ķ�ά����ģ�ʹ�Լ��Ҫ����7000s������������ʵ���齨����Լ3000s��
4.2.3 ����������
�����ᵽ�������Զ�ά������Χ����դ�����ʱ�����Ǵ洢��դ����������Χ��ȫ���ǵ�դ����˶��ڸ���һ���ֵ�դ�����Ǻ��ԣ���Ͳ����������������������ʵ��һ����ʵ�飬ͨ���ı�դ������������ʵ����������դ����Խ�����ԽС����դ����Ϊ15��ʱ�����Ϊ�ٷ�֮����
������ ������
�������������һάģ�ͻ������������Զ�ά���ݷ�Χ������ģ�ͣ�ʹ��ά�ļ������ݿ����Ժܸߵ�Ч�ʽ�������������ͬʱ��֤�����ݵİ�ȫ�ԡ��ڶ�ά���ݷ�Χ����ģ�͵Ļ����ϣ������ֶԶ�ά����ͬʱ����������Ż��Լ�����Ż������������ʴ��Ľ��͡�
���ڶ�ά�������ݵ�����������ʵ������Ҳ�кܶ�Ӧ�õij�������KNN��������ȣ���˱������۵�������кܶ�ʵ�ʵ�Ӧ�ü�ֵ��
�����
[1] B. Hore, S. Mehrotra, M. Canim, and M. Kantarcioglu. Secure multidimensional range queries over outsourced data. The VLDB Journal, 21(3):333�C358, June 2012.
[2] B. Hore, S. Mehrotra, and G. Tsudik. A privacy-preserving index for range queries. In VLDB, pages 720�C731, 2004.
[3] A. Boldyreva, N. Chenette, Y. Lee, and A. O��Neill. Order-preserving symmetric encryption. In EUROCRYPT, pages 224�C241, 2009.
[4] A. Boldyreva, N. Chenette, and A. O��Neill. Order-preserving encryption revisited: Improved security analysis and alternative solutions. In CRYPTO, 2011.
[5] N. Li, T. Li, and S. Venkatasubramanian. t-closeness: Privacy beyond k-anonymity and l-diversity. In Data Engineering, 2007. ICDE 2007. IEEE 23rd International Conference on, pages 106�C115, April 2007.
[6] W. K. Wong, D. W.-L. Cheung, B. Kao, and N. Mamoulis. Secure knn computation on encrypted databases. In SIGMOD, pages 139�C152, July 2009.
[7]Rui Li, Alex X. Liu, Ann L. Wang, Bezawada Bruhadeshwar:Fast Range Query Processing with Strong Privacy Protection for Cloud Computing. PVLDB?7(14): 1953-1964(2014)
[8] Praveen Gauravaram, Shoichi Hirose, Suganya Annadurai.An Update on the Analysis and Design of NMAC and HMAC Functions.International Journal of Network Security, 2008, Vol.7 (1), pp.49.
[9] Kumar A,Xu J.Space-Code bloom filter for efficient per-flow traffic measurement. Proc.of the IEEE INFOCOM2004.
[10] Hien To, Gabriel Ghinita, Cyrus Shahabi:A Framework for Protecting Worker Location Privacy in Spatial Crowdsourcing. PVLDB?7(10): 919-930 (2014).
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
