




















基于深度学习的新闻图像情感识别模型的设计与实现
【摘 要】现代媒体中,图片在新闻传播过程中发挥了越来越重要作用,随着受众视觉媒介依赖程度的提高,基于图像高级语义的组织分类成为现在迫切需要解决的问题。虽然每个人文化背景、评判标准都存在着个体主观差异,但整体方向存在相似性,能够准确分析新闻图像的情感语义对于提升图片与文字报道情感色彩的符合度以及避免图文相悖的报道对大众产生情感诱导具有重要意义。
图像情感识别准确率依赖于图像识别技术,本文对图像识别中经常会使用到经典的模式进行了概述,详细介绍了日趋重要的基于人工神经网络的深度学习算法,重点探究了深度学习在图像识别领域的一个重要网络模型――卷积神经网络(Convolutional Neural Network,CNN)。并提出了一种基于CNN的图像情感识别方法,该方法分为两个步骤:图像数据预处理和模型训练,采用该模型进行图像情感识别能够获取较高准确率。为了进一步验证模型准确率并对新闻图像情感进行分析,本文运用网络爬虫技术,随机获取了150篇含有图片的新闻报道及其阅读量进行分析对比。
实验结果表明机器识别与大多数人为感知大致吻合,但是也可以看到目前新闻报道中图片情感与文字情感符合度较低。由此可知,新闻图片选取时可能更重视图片内容本身,而忽略了图片情感语义与报道本身所要表达的情感是否相符。同时,通过对阅读量的粗略分析可知,新闻图片情感与文字报道情感吻合度与新闻报道的阅读量正相关。本文所提出的算法可用于人民网新闻图片的选取,用以提高图片与文字的情感吻合度,加强读者对新闻整体的接受感。
【关键词】卷积神经网络(CNN);图像情感识别;新闻图像
第一章 概述
1.1 图像识别
图像识别是按照所观测到的图像,通过计算机对图像自动进行处理、分析,理解图像的内容,以达到分类识别不同模式的目标和对象的效果。随着计算机计算能力的大幅提高和大数据时代的来临,图像识别技术正向着高级语义理解方向发展。
通常情况下,一个图像识别系统由三个部分组成:图像预处理、特征提取、分类器的识别[1]。其中图像预处理是为了减小图像对识别的干扰并提高后续算法效率,常见的预处理包括降噪、图像增强、分辨率归一化、颜色矫正等;特征提取是提取能够代表图像类别的特征,是图像识别中至关重要的步骤,直接影响识别性能的好坏,在一幅图像的众多特征中,需要提取区分能力强且可以抗干扰的特征,常用的特征有颜色特征、形状特征、纹理特征、能够稳定出现并具有良好区分点的局部特征信息(SIFT、HOG、LBP、MSER等)以及它们的组合;分类器的识别则是按照图像特征所提取的结果进行分类。
1.2 图像情感识别
近年来,随着计算机网络技术和数字媒体处理技术的发展,图像数据量越来越庞大。基于图像识别的多领域融合已成为研究热点。考虑到人们对所看的图像所产生的主观情绪,本文提出图像情感识别。虽然由于文化背景等差异,每个人对视听觉媒体的评判标准和感官存在着差异,特别是对媒体情感语义的理解。但对于图像的情感表现又有群体相似性。因此,如果能够准确分析图像的情感语义对于相关领域的发展具有重要意义。
目前图像识别技术试图用图像的视觉特征来代表图像,同时也包含图像自身包含的情感信息,但这部分特征往往被忽略。研究表明图像情感识别是一种重要的识别内容,它可以被认为是图像中蕴含的能引起人类某种情感反应的信息[2]。基于机器学习的方法用图像视觉特征识别个性化情感内容,来弥合视觉低层特征和人类情感高层语义之间的语义鸿沟。
近些年与图像情感分析相关工作的有图像受喜爱度分类(affection)[18]或情绪(emotions)分类[19]。Machajdik等人根据心理学和美学理论设计出较为细致的底层特征组合,这些特征更能代表图像的情感内容,具体颜色特征、纹理特征、复杂度、景深、三分构图法、动力学等图像结构特征,还有人脸和肤色的图像内容特征。最终在International Affective Picture System(IAPS)数据集上训练分类器,将图像分为快乐(Amusement)、生气(Anger)、敬畏(Awe)、满足(Contentment)、恶心(Disgust)、兴奋(Excitement)、恐惧(Fear)、悲伤(Sad)八个情绪类别。
第二章 图像识别技术
图像情感识别是图像识别的一个方向是将图片根据人类情感进行分类,属于模式识别的范畴[1]。模式识别是人类的一种基本认知能力,是人类智能的重要组成部分,几乎每个人都会在不经意间轻而易举地完成模式识别的过程。通过视觉信息识别文字、图片和周围的环境,通过听觉信息识别与理解语言等,在各种人类活动中都有着重要作用。但如果要让机器做同样的事情,决非这么轻松。
在对图像进行分类的过程中,其经常会使用到经典的模式进行识别,如:模板匹配模式识别、模糊模式识别、支持向量机的模式识别,以及目前越来越受到重视的基于人工神经网络的深度学习技术。
2.1 模板匹配模式识别
模板匹配是一项在图像识别领域非常重要的识别技术,这种方法的优点在于匹配算法较为简单,但计算量大,在图像变化不大的情况下识别率较高。模板匹配的原理是选择已知的对象作为模板,通过相关函数计算来找到它和被搜索图的坐标位置,与图像中选择的区域进行比较,从而识别目标[4]。
模板匹配主要应用于对图像中对象物位置的检测,运动物体的跟踪,不同光谱或者不同摄影时间所得的图像之间位置的配准等[3]。但如果图像和模板大到一定程度,就会导致计算机无法处理,也就失去了图像识别的意义。模板匹配的另一个缺点是光线变化能引起图像颜色值的漂移,尽管漂移没有改变颜色直方图的形状,但漂移引起了颜色值位置的变化,从而可能导致匹配策略失效。
2.2 模糊模式识别
模糊模式识别是以模糊理论和模糊集合数学为支撑的一种识别方法。它根据人辨识事物的思维逻辑,吸取人脑的识别特点,将计算机中常用的二值逻辑转向连续逻辑。模糊识别的结果是用被识别对象隶属于某一类别的程度即隶属度来表示的,一个对象可以在某种程度上属于某一类别[3]。基于模糊集理论的识别方法有:最大隶属原则识别法、择近原则识别法和模糊聚类法。
采用模糊推理的方法,用隶属函数作为样本和模板的度量,能反映模式的整体特征,针对样品中的干扰和畸变,有很强的剔除能力。但模糊规则往往是根据经验得出,准确合理的隶属函数往往难以建立,因此限制了它的应用。
2.3 支持向量机的模式识别
支持向量机(Support Vector Machine,SVM) 是由Vapnik领导的AT&Bell 实验室研究小组在1963 年提出的一种非常有潜力的分类技术[3],其基本思想是:先在样本空间或特征空间,构造出最优超平面,使得超平面与不同类样本集之间的距离最大,从而达到最大的泛化能力[6]。支持向量机结构简单,并且具有全局最优性和较好的泛化能力,自提出以来得到了广泛的研究。
支持向量机方法是求解模式识别和函数估计问题的有效工具。SVM能够寻找图像像素之间的特征的差别,即从像素点本身的特征和周围的环境(临近的像素点)出发,寻找差异,然后将各类像素点区分出来。用支持向量机的方法处理一些二值图像和灰度图像,能获得较好的统计结果[6]。
2.4 人工神经网络
人工神经网络(Artificial Neural Network,即ANN)是人类在对其大脑及大脑神经网络认识理解的基础上,人工构造的模拟人脑及其活动并能够实现某种功能的理论化数学模型。人工神经网络区别于其他识别方法的最大特点是它对待识别的对象不要求有太多的分析与了解,具有一定的智能化处理的特点[3]。神经网络具有大规模并行、分布式存储和处理、自组织、自适应和自学习的能力,特别适用于处理需要同时考虑许多因索和条件的、不精确和模糊的信息处理问题,因此它在图像识别领域应用广泛[7]。
2.5 深度学习
深度学习通过深度神经网络实现,相较于传统信息提取过程,深度学习的层次特征是一种由数据驱动的特征学习过程,该过程需要大量的数据来进行学习。大数据时代的来临正可以解决数据的来源问题[8]。因此,深度学习技术已经成为目前图像识别最为火热的领域之一。
深度学习在图像特征的分层提取中,低层可以提取到一些边缘纹理信息,中间层可以在边缘信息的基础上学习到部分区域特征,高层实现识别目标的语义信息[9]。通过深度学习,可以使用高级语义特征来实现对目标的识别,在物体分类、识别、检测等应用中具有明显优势。
2.5.1 卷积神经网络
卷积神经网络( CNN) 是一种前馈神经网络,是深度学习中处理数据非常著名的算法。卷积神经网络也被多数研究人员认为在图像识别领域有突出的优势。
卷积神经网络对图像的层级特征提取,主要通过卷积层后接下采样层这种循环结构来实现的[10]。通过卷积核和共享权值应用使卷积神经网络需要处理的数据量大幅减少,下采样层在一定程度上对输入的小型变化具有特征不变性,可以使特征更加的鲁棒。每一个卷积层后加上下采样层作为一个基本单元,提取图像特征,下一次这种单元将对已提取的特征进行更高级特征的提取。
2.5.2 卷积神经网络的发展
卷积神经网络可感知图像的局部特征,并对局部特征进行综合得到全局特征,在对大型图像进行分类时表现出色[11],这在ImageNet ILSVRC 图像分类任务挑战中有很好的体现。
2012年Hinton 的研究小组利用卷积神经网络将该测试集上的错误率由传统方法的26.172%大幅降到15.315%。与传统网络相比,它有采用了dropout 的训练策略,并使用整流线型单元作为非线性的激发函数,这不仅大大降低了计算的复杂度,而且各种干扰更加鲁棒。2014年深度学习又取得了重要进展, GooLeNet将top5 错误率降到6.656%。它大大增加了卷积网络的深度,超过20 层,这在之前是不可想象的。很深的网络结构给预测误差的反向传播带了困难。GooLeNet 采取的策略是将监督信号直接加到多个中间层,这意味着中间和低层的特征表示也需要能够准确对训练数据分类。
2.6 本章小结
本章对图像识别技术发展进行综述,以时间为线索的重要节点有:Vapnik等人于1995年在统计学习理论的基础上提出了支持向量机(SVM),它根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折衷,具有较好的泛化能力;神经网络一派的大师Hinton等人于2006年提出了神经网络的Deep Learning算法,使神经网络的能力大大提高,为图像识别的发展提供了新的思路,机器通过无监督学习自动识别图像特征;2012年在ImageNet ILSVRC挑战中卷积神经网络取得优异成绩,目前基于卷积神经网络的图像识别技术应用最为广泛。
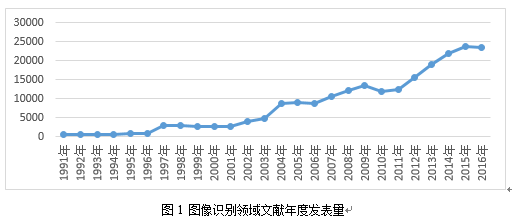
图1为Web of Science数据库中图像识别领域文献年度发表量,文献年度发表量在1997年、2004年、2007年-2009年、2012年-2015年有迅猛增长,与前文所述新技术的提出时间相吻合,从这个角度也可以反映出技术的每次发展都会引起图像识别领域研究的高潮。
 |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
