




















基于用户画像与新闻词向量的个性化新闻推荐模型【2】
4.1 基于指数衰减模型的词向量训练框架
指数衰减模型的CBOW+Hierarchical Softmax训练框架根据上下文词与目标词之间词的数量来构造指数衰减模型的权重因子,此时投影层为 中所有词向量的叠加,其公式为


4.2 新闻向量特征融合
对于新闻文本而言,特征提取方法主要是在整个文档集中进行选择,包括TF-IDF,信息增益等特征,其忽略了不同领域以及同领域之间的特征词的分布情况[9]。往往不能有效的选择出具有较好区分能力的特征,难以发现用户对新闻的潜在偏好。
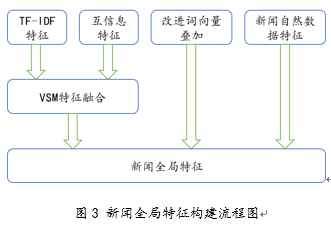
本模型采用新闻特征词的向量空间模型特征与词向量叠加相融合的特征,并将新闻的额外信息,包括发布时间,点击次数等信息,共同形成对应新闻的融合特征。
对于向量空间模型特征,本模型主要采用TF-IDF以及互信息特征。虽然TF-IDF简单快速,结果比较符合实际情况,但是单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种特征无法体现词的位置信息,同时未能考虑特征项在新闻领域间和领域内的情况。然而,互信息作为特征词和类别之问的测度,如果特征词属于该类的话,它们的互信息量最大。由于该方法不需要对特征词和类别之问关系的性质作任何假设,因此非常适合于文本分类任务。对于每一领域来讲,特征的互信息越大,说明它与该领域的共现概率越大,因此,以互信息作为提取特征的评价时应选互信息最大的若干个特征。将互信息与TF-IDF特征相结合,弥补了TF-IDF未考虑新闻领域间和领域内的问题,能够有效的对新闻进行表达和特征提取。
本文采用基于指数衰减模型的词向量训练框架对新闻语料库进行训练,在对新闻进行分词并去掉停用词之后,可以得到表示新闻的特征词词向量集合。在使用词向量集合表示方面,如果将特征词词向量首尾相接作为新闻文本特征向量,此时向量的维度等于特征个数与词向量维度的乘积。由于每个词的词向量维度普遍在100~300之间,若新闻特征词选择较少,无法对新闻进行有效的表示,选择较多则会造成词向量维度灾难,文本特征维度过高、增加计算资源开销。因此,本文选择将所有特征词词向量进行叠加,从而获得新闻表示的词向量特征。
对于新闻其他属性,例如浏览数、热度、评论人数等等,在融合向量空间模型和词向量特征时,同时将其与融合特征首尾连接构造成能够表达新闻内容与自然特征的全局特征,从而对新闻进行有效的表达。
5、分类算法
在得到用户画像特征和新闻全局特征后,模型可以采用高效并行的分类算法对用户的行为进行预测,例如深度森林(gcForest)、Xgboost等。
深度森林是一种全新的决策树集成算法,使用级联结构让深度森林来做表征学习[6]。通过对比分析,gcForest使用相同的参数设置,在不同的领域中都获得了突出的效果,并且无论是大规模还是小规模的数据,都能得到很好的泛化。此外,相对于神经网络,gcForest整体是基于树的结构,更加容易分析和解释。
XGBoost在基于梯度提升的框架下,其对目标函数进行二阶泰勒展开,使用了二阶导数加快了模型收敛速度,并使用正则化的目标函数,控制模型的复杂度。不仅如此,XGBoost算法借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,同时在进行完一次迭代后,会将叶子节点的权重乘上缩减系数,削弱每棵树的影响,让后续迭代有更大的学习空间。
这两种分类算法都是基于树的算法,都能够有效的实现并行化,在保证模型效果的基础上,提升学习速率。
分类算法在预测某一用户对众多新闻的点击概率后,通过Softmax归一化方法进行处理,获得用户点击概率较高的新闻,并推荐给用户。
6、总结
本文就目前推荐模型中存在的用户行为数据的高维稀疏特点、新闻文本特征相似性衡量两方面,从分类的角度考虑用户对新闻的行文,提出一种融合用户画像和内容词向量特征的个性化新闻推荐模型,通过构建用户画像模型,挖掘用户的潜在偏好,并使用指数衰减模型的Word2Vec算法进行词向量训练,结合向量空间模型特征对新闻进行表示,并采用基于树的集成算法进行预测评估,获取用户可能点击阅读的新闻,将其推荐给用户。
本文提出的模型有效的避免了对高维稀疏的用户行为数据进行相似性衡量,并采取融合特征对新闻全局特征进行表示,能够较好的区别新闻之间的差异,挖掘用户的潜在新闻偏好,提高推荐效果,可广泛应用于新闻门户推荐网站,例如人民网、网易新闻等。
 |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
