




















人工智能技术在文化产业中的应用与影响研究
摘要:人工智能技术的发展为文化产业提供了诸多应用性机遇;其中一些关键性技术点与文化产业相结合,可以实现文化内容产生、创意资讯传播以及文化市场管理方面的创新。本文拟从几种主要的人工智能技术出发,介绍在技术与产业相结合过程中形成的代表性应用,同时探讨分析目前的人工智能应用带来的“信息茧房”“机器歧视”等社会问题,从而为我国文化产业发展提供相应的经验。
关键词:人工智能;文化产业;算法公平;信息茧房
人工智能(Artificial Intelligence,AI)本质上是对人的意识与思维的信息过程的模拟,是指使用机器代替人类完成认知、识别、分析和决策等功能。在《人工智能:一个现代路径》[ STUART J. RUSSELL & PETER NORVIG, ARTIFICIAL INTELLIGENCE: A MODERN APPROACH 1034 (3d ed. 2010), supra note 7, at 4.]一书中,“人工智能”被定义为:行为是为了获得最好的结果,或者在不确定的情况下,获得期待的最好结果,这是一种“理性行为”选择。在过去的十余年中,人工智能技术在以深度学习为代表的机器学习、语音识别、自然语言生成与处理、计算机视觉等领域取得不少成果,引得全球广泛关注。
世界各国都在积极部署关于人工智能的战略规划,2016年10月,美国和英国双双出台国家人工智能战略。就我国而言,2017年,国务院印发《新一代人工智能发展规划》,其中提出到2030年,人工智能理论、技术与应用总体达到世界领先水平,成为世界主要人工智能创新中心。人工智能核心产业规模超过1万亿元,带动相关产业规模超过10万亿元[ 国务院:新一代人工智能发展规划[J].重庆与世界,2018(02):5-17.]。
基于此,本文重点关注人工智能技术在文化产业――即新闻出版、发行、广播电视、电影、文化艺术、文化信息传输、广告服务和文化休闲娱乐等领域中的应用现状、存在的问题及对策,从而为我国文化产业发展提供可借鉴思路。
一、人工智能的主要技术类型与文化产业中的典型性应用
在美联社于2017年发布的《人工智能工作手册》中,人工智能在新闻业应用最频繁的技术主要有5类,包括机器学习、自然语言技处理术、语音识别技术、机器视觉和机器人技术[余婷,陈实.人工智能在美国新闻业的应用及影响[J].新闻记者,2018(04):33-42.]。在整个文化产业当中,目前应用最为广泛的技术类型是以深度学习为代表的机器学习,其他4类技术类型也均有不少应用落地。
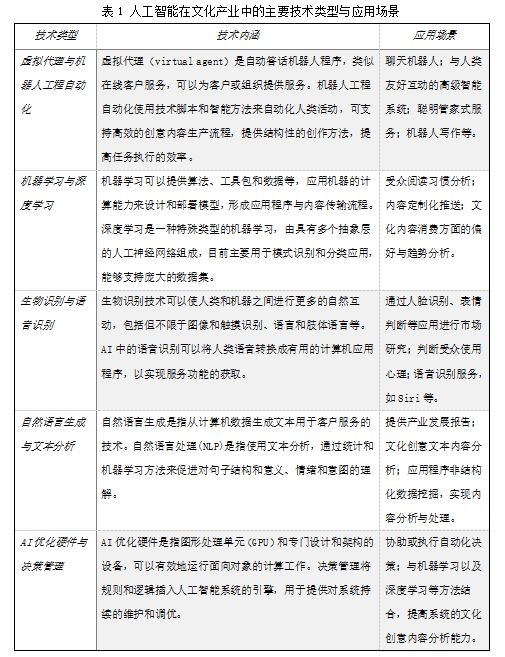
通过上表可知,人工智能中的虚拟代理、机器人自动化、机器学习、深度学习、生物与语音识别、自然语言生成与处理(NLP)、硬件优化与决策管理等技术可以与文化产业中的信息采集、内容生产、信息传播和受众管理等有效结合,提供诸如内容个性化算法、受众目标与偏好识别、自动新闻内容生产等方面的服务,也可以提供在客户管理与市场调研方面的有力手段。
目前,国外一些先进的文化媒体机构对于上述技术的应用已经形成一定的有益经验与有效做法。
首先,在内容生产中,人工智能可以实现自动写作与自动摘要、抽取式新闻写作,并试图使机器像人类一样阅读与思考。
美联社是最早运用AI技术进行自动化写作的媒体之一。2014年,美联社与美国Automated Insights公司合作,使用该公司开发的自动化写稿程序Wordsmith来自动编发企业财报新闻。该程序几分钟内可写出150-300字的快讯,每季度能生产4000篇财报新闻,是过去数量的10倍。2015年之后,国内腾讯新闻、新华社和今日头条等也陆续推出了写稿机器人。
其次,在信源数据收集中,人工智能可以基于传根器应用生成内容,实现信息传播的可视化追踪。
News Tracer是路透社使用的新闻追踪系统,这一系统每天可以对5亿条Twitter信息进行分析,从假新闻、广告和杂音,以及众多的人名、机构和地点中找到真的新闻事件与线索,这让记者能够从社交媒体的众多信息中脱身,把更重要的时间用来挖掘故事。
第三,在文化创意视频类服务中,人工智能可以实现文本和视频之间的转换、高效寻找视频片段与资源以及优化视频内容搜索等。
Zorroa是美国的一家视觉资产管理公司,2017年,公司推出企业可视化智能平台(EVI),帮助用户对大型数据库中的可视资产进行搜索和运行分析。在与索尼影业的合作中,EVI通过面部识别、图像分类、机器学习等方式整理、分析了索尼多年来积累的数百万小时的视觉资产。使用该平台后,平时需要27小时才能搜索到的特定视频资源,仅需3分钟即可检索到,为索尼影业的视频资源开发带来极大的便利[ https://zorroa.com/case-studies/]。
第四,在文化信息传播中,人工智能可以通过受众的好奇点与文化传媒内容进行匹配、通过信号源获取受众的兴趣点,并且精准分析受众,预测其内容消费需求,实现精准投放。
Netflix是在用户个性化分发业务上较为成熟的视频网站。2016年年报显示,Netflix拥有9300万全球会员,每天流媒体播放超过1.25亿小时的电视节目和电影。预测用户想要观看的内容是其公司业务模式的关键部分。2016年,Netflix开发名为Meson的应用程序,构建、培训和验证个性化算法,提供视频推荐建议。类似的企业还有IRIS.TV等,该公司曾在三个月的时间内运用个性化分发,将其客户所在公司的观众存留率提高了50%[ https://www.techemergence.com/ai-in-movies-entertainment-visual-media/]。
最后,在市场调研与客户管理方面,人工智能可以获知受众对内容消费的使用特点、通过深度神经网络技术来感知受众对文化内容的情感参与和变化,从而进行有效的客户管理与市场营销。
2016年,日本广告公司MaCann Erickson Japan聘用了全球第一个使用人工智能开发的机器人创意总监AI-CD?。当年9月,机器人创意总监与人类创意总监以同一个广告主题各自开发了10分钟的广告片,并交由全国民意调查评判。尽管人类创意总监以8%的微弱优势险胜,AI在受众分析与市场营销方面的潜力不容小觑。
可见,人工智能已经显著改变了媒体格局――包括观众发现和参与内容的方式,以及内容创建和分发给观众的方式。目前,算法不仅会影响受众在不同平台上看到的内容,还会首先影响平台生产和创建的内容。人工智能从根本上改变了受众行为和创作过程。
二、人工智能应用对文化产业发展的影响与启示
尽管统计显示,就目前的全球文化产业而言,仅有8%的文化企业已经部署并使用了人工智能技术应用[ https://www.ibc.org/tech-advances/the-future-is-artificial-ai-adoption-in-broadcast-and-media/2549.article],但人工智能技术对文化产业乃至整个社会的影响已经有所显露。
就其积极意义而言,人工智能技术在提高内容生产效率、提升用户留存率以及优化文化产业资产管理等方面存在重要意义、毋庸置疑的高效率和部分的不可替代性。而就其消极影响而言,内容分发的局限性开始受到社会关注;人工智能算法的公平化、透明化一度遭受质疑;算法带来的偏见与歧视又引发社会伦理问题;人工智能应用背后的商业力量或许是造成这一系列问题的原因之一……
不少科技界声名显赫的人物也因此表达了对人工智能未来发展的担忧,如特斯拉创始人埃隆・马斯克曾说:“我们应该十分小心地看待人工智能。我越来越倾向于认为,在国际或者国家层面上应当有相应的人工智能监管措施,以防人类做出不可挽回的事情来。”微软创始人比尔・盖茨、物理学家史蒂芬・霍金等也表达了类似的看法。未来人工智能应用将在何种程度上造福于人类,部分取决于今天我们在何种程度上理解并解决人工智能可能产生的问题与自有弊端。
具体而言,本文将从如下三方面阐述人工智能应用的问题、影响与对策:
(一)内容分发的局限性:“信息茧房”
如今的网络文化空间,从某种意义上说,是一个算法帮助公众做决定的环境。如果说曾经的传统媒体为公众搭建了一个“拟态环境”,不同的编辑部依托各自的编辑方针、新闻判断原则,以“议程设置”的方式决定着每日媒体内容的生产加工,那如今,在网络媒体中这一权力部分地转交给了算法。算法可以决定人们阅读哪些新闻,观看哪些视频,收到哪些广告,人们的数字存在(Digital Existence)日益受到算法左右。
文化传媒企业使用算法决定内容推荐的初衷是在于解决信息过载的问题,提高用户获取信息的效率,更希望借此增加用户的沉浸时长,提高应用的用户忠诚度和留存率。因此,企业利用大数据主动搜集用户信息,根据用户自身兴趣,为用户定制个性化内容,形成一整套精确的内容分发模式。Facebook信息流产品Newsfeed、对话式新闻产品微软小冰和Quartz、今日头条以及Netflix、IRIS.TV等一系列人工智能应用均属于此类型。
这一初衷是好的,但问题出在“精确”上。信息越精确,代表着信息涉及的范围越狭窄。人工智能研究者已经发现,仅仅关注推荐系统的精确度远远不够,这会导致用户难以获取足够的信息增量,视野越来越狭隘。美国学者桑斯坦在其著作《信息乌托邦》[ 凯斯・R・桑斯坦.信息乌托邦:众人如何生产知识[M].法律出版社,2008:206-208.]中指出,人们借助网络平台和技术工具,在海量的信息中,完全根据自己的喜好定制报纸和杂志,进行一种完全个人化的阅读。在信息传播中,因公众自身的信息需求并非全方位的,公众只注意自己选择的东西和使自己愉悦的通讯领域,久而久之,会将自身桎梏于像蚕茧一般的“信息茧房”中。
学术界不少学者指出“信息茧房”问题的危害,将“信息茧房”与群体极化、证实性偏见等议题关联起来。学者陈昌凤认为,信息的个人化偏向容易产生詹姆斯・斯托纳(James Stoner)1961年提出的群体极化现象,即团体成员从开始只是有某些偏向,通过协商、讨论,逐渐朝偏向的方向继续移动、形成极端的观点,甚至引发社会波动,如散播错误信息、形成极端性社会团体、公共理性批判缺失等[ 陈昌凤,张心蔚.信息个人化、信息偏向与技术性纠偏――新技术时代我们如何获取信息[J].新闻与写作,2017(08):42-45.]。与此同时,人们总是倾向于寻找、阅读自己认同的信息来佐证自己的认知,加深了信息的个人化偏向。对垂直细分领域内容的追逐,弱化了公共事务领域内容的传播,网络社会中传统媒体讲求的“社会公器”意义式微,一个对公共事务冷漠、毫无参与感与同理心的社会将会是“信息茧房”之下最极端也最为悲剧性的结局。
对此,文化传媒企业和公众这两个主体都需要采取一定的对策。对于文化企业而言,应当在推荐的精确度指标之外,加入新的算法推荐考量指标,如多样性、覆盖率、新颖性等;另外,有研究表明,基于关联规则的推荐方法要优于基于内容规则的推荐方法,更易为用户发掘新的兴趣点,现有的障碍在于关联规则难以抽取、耗时长[ 刘辉,郭梦梦,潘伟强.个性化推荐系统综述[J].常州大学学报(自然科学版),2017, 29(03):51-59.]。
而对于公众而言,文化传媒企业设置算法推荐的初衷就有迎合用户喜好的意味,用户越是喜欢哪一类内容,平台就越是推荐哪一类内容。因此用户想要逃离“信息茧房”,第一个步骤就是反省自身,提升自身的媒介素养。平台可以帮助用户实现媒介素养提升,如每周发布用户阅读周报,告知用户在阅读中各类型信息的占比情况,提示用户哪一类信息了解匮乏等,起到一定的督促作用。
(二)从算法偏见到机器歧视――算法的公平与透明化困境
当我们在日常生活中的决策权部分地交给算法之后,我们本能地期待着一个更加公平、透明的环境。但是,一个不容忽视的问题是:算法或者机器真的能够做到公平、公正、不偏不倚吗?算法的规则是否本身就带有人类固有的偏见呢?
2015年5月,Google的照片应用加入自动标签功能,应用更新不久,一位黑人程序员发现自己的照片竟然被Google打上“大猩猩”的标签。Flickr类似的自动标签系统也犯过大错,曾把人标记为猿,把集中营标记为健身房。2016年3月,微软公司的人工智能聊天机器人Tay上线。可是上线不到一天,Tay就被网民“教育”成为一个集反犹太人、性别歧视、种族歧视等于一身的“坏孩子”,被强制下线。此外,有研究称谷歌广告服务会默认为女性用户推送比男性用户薪水更低的广告。这些事件一方面反映出现有的人工智能、机器学习技术的不成熟,另一方面,机器歧视(Machine Bias)问题开始进入公众视野。
2017年,Pew研究中心曾在研究报告《算法时代》[ Lee Rainie, Janna Anderson: Code-Dependent: Pros and Cons of the Algorithm Age, http://www.pewinternet.org/2017/02/08/ code-dependent-pros-and-cons-of-the-algorithm-age/]中指出:“算法的客观中立仅仅是理想,创建算法的人即使尽量做到客观中立,也不可避免地受到自身成长环境、教育背景、知识结构和价值观的影响。此外,创建算法所依赖的底层数据的有限性也会导致算法偏见。”
那么,算法偏见的来源在哪里?首先,存在错误、不准确和无关的数据可能导致偏见。输入不完美、甚至有错误的数据,自然会得到错误、有偏见的结果。
其次,机器学习的过程可能是偏见的另一个重要来源。例如,一个用于纠错的机器学习模型在面对大量姓名的时候,如果某姓氏极为少见,那它在全部数据中出现的频率也极低,机器学习模型便有可能将包含这个姓氏的名字标注为错误,这对罕见姓氏拥有者和少数民族(姓氏与非少数民族不同)而言就会造成歧视[曹建峰.人工智能:机器歧视及应对之策[J].信息安全与通信保密,2016(12):15-19.]。这类歧视的来源并非程序人员有意识的选择,具有难以预料、无法估计的特点。
再者,正如Pew报告所指出的,算法可能先入为主地默认了算法创建者或者底层数据中带有的价值判断,从而产生了性别、宗教和种族方面的歧视。这类歧视主要是由于产品设计(Discrimination by Design)的局限性。
种种算法偏见与机器歧视的案例让我们不禁怀疑,“公平”这一社会理念到底是否可以被操作化,成为被准确量化的算法规则。而与此同时,机器自动化决策的不透明性使得准确量化公平难上加难。机器决策是经由算法这一“黑箱”(Blackbox)完成的,也就是说,不论是普通人还是熟悉公平原则的社会学者,均无法了解算法的内在机制、原理,更无法监督机器的决策过程。因此,当算法的编程人员不清楚或者未能统一“公平”的内涵与规则时,他们自身的偏见就会在一定程度上影响算法,同时他们也可能会忽视算法可能产生的偏见,不公平的人工智能应用随之产生。
正如学者Danielle K.Citron在《技术正当程序》中所说,对于关乎个体权 益的自动化决策系统、算法和人工智能,考虑到算法和代码,而非规则,日益决定各种决策工作的结果,人们需要提前构建技术公平规则,通过设计保障公平的实现,并且需要技术正当程序,来加强自动化决策系统中的透明性以及被写进代码中的规则的准确性。
日前,美国弗吉尼亚大学学者Ahmed Abbasi等在《让“设计公平”成为机器学习的一部分》(Make “Fairness by Design” Part of Machine Learning)一文[ https://hbr.org/2018/08/make-fairness-by-design-part-of-machine-learning]中指出,可以通过将数据科学家与社会科学家组队、谨慎打标签、将传统的机器学习指标与公平度量相结合、平衡代表性与群聚效应临界点(critical mass constraints)以及保持意识等方法减少算法形成歧视的可能性。其中,“平衡代表性与群聚效应临界点”是指在对数据进行采样时,应既考虑数据的整体特征,同时不忽略某个特定少数群体或者极端数据情况。只有这样,机器学习模型在预测一个普通人和一个特殊群体时,才能都给出更为准确的答案。
另外,谷歌也开始倡导“机会平等”,试图将反歧视纳入算法。还有学者引入“歧视指数”的概念,为设计“公平”的算法提供具体方法。我们必须清楚,人工智能总是通过一个快速且脱离人类社会与历史的学习来完成自我构建,因而一个未经完善的机器学习模型必然存在“道德缺陷”。在人工智能应用的构建中,人类与人类长久以来葆有的道德与社会规则不能缺席。
(三)人工智能应用背后的力量
“信息茧房”的形成不是由于信息广度不足,内容生产不够,而是由于信息推荐固定地集中在某一特定领域造成了信息的窄化;算法偏见的形成不是由于机器学习具有天生的弊端,而是由于人类未将公平公正的原则纳入算法考量之中。人工智能应用背后存在着的,是人的力量与符合经济社会的商业逻辑。
为了迎合消费者,信息推荐系统会将消费者的阅读“口味”作为依据。当搜索引擎通过机器学习意识到,搜索八卦新闻的人愿意在日后更多地看到八卦新闻,为了提升用户留存度,搜索引擎会相应地减少其他类型新闻推荐。
为了满足商家,人工智能产品会把更昂贵的产品卖给用户忠诚度高的用户,即“大数据杀熟”现象。同时,为了更加精准地进行广告投放,人工智能偶尔也会忽视公平原则,例如女性用户通常会收到比男性用户薪资低的推荐广告。这样的现象发人深省,未来是否有必要通过一定的法律手段,要求包括文化企业在内的商家作出“不作恶”的商业承诺。
整体而言,我们的社会正被人工智能推向一个新的发展节点。正如[金兼斌.人工智能将给传媒业带来什么?[J].中国传媒科技,2017(05):1.]学者指出,社会和传媒技术的发展,从来都不是线性和匀速的。从工业革命到信息技术革命,每一次社会巨变都伴随着这样一个临界时刻。今天,我们已经能够感受到,我们的日常生活――包括媒介生活中的许多基础性的东西,正在被人工智能应用所搅动。在这样的时刻,只有紧抓机遇、规避风险、解决弊病,才能真正实现行业和社会的跨越式发展。我国的文化产业走到了一个崭新的路口,新的机遇在等待着它。
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
