




















ЛљгкгУЛЇЩчНЛЙиЯЕЕФИіадЛЏЭЦМі
еЊвЊЃКЭЦМіЯЕЭГЪЧЮЊСЫЭЦМігУЛЇПЩФмИааЫШЄЕФВњЦЗЃЌЭЦМіЦНЬЈЩЯЕФФкШнЮЊгУЛЇЬсЙЉИіадЛЏЗўЮёж№НЅГЩСЫКмЖрЦНЬЈЕФживЊШЮЮёЁЃЕЋЪЧКмЖрЦНЬЈжЛФмЛёШЁЕНгУЛЇЕФвўЪНЗДРЁаХЯЂ,ЖјЧвУПвЛИігУЛЇжЛдкЩйСПЕФЩЬЦЗЩЯВњЩњааЮЊЃЌЕМжТЦНЬЈЛёШЁЕНЕФЪ§ОнМЏЪЧЗЧГЃЯЁЪшЕФЁЃДЋЭГЕФЭЦМіЫуЗЈдкУцЖдетСНИіЮЪЬтЕФЪБКђаЇЙћВЂВЛКУЁЃдкетЦЊЮФеТжаЃЌЮвУЧЬсГіСЫвЛИіЛљгкЩчНЛжаЯрЫЦКУгбЕФБДвЖЫЙИіадЛЏХХађЫуЗЈ(SFSBPR)ЃЌЛКНтСЫдкЛљгкгУЛЇвўЪНЗДРЁЕФЭЦМіжаЕФЪ§ОнЯЁЪшадЮЪЬтЁЃЪЕбщНсЙћБэУїЮвУЧЕФЗНЗЈБШЦфЫћЭЦМіЫуЗЈдкЯжЪЕЪРНчЕФЯЁЪшЪ§ОнМЏЩЯаЇЙћИќКУЁЃ
ЙиМќДЪЃКИіадЛЏЭЦМіЃЌЩчНЛЙиЯЕЃЌвўЪНЗДРЁЃЌЯЁЪшЪ§ОнМЏ
AbstractЃКThe goal of recommender system is recommending products users may be interested in. Recommending content is an important task in many platforms. But many platforms only have implicit feedback information from users. Each single user generates behavior on only a few products lead to sparse datasets from users. And traditional recommending algorithms show poor performance when face the two problems. In this paper, we present a social bayesian personalized ranking based on similar friends (SFSBPR). We alleviate the sparsity problem when recommend by usersЁЏ implicit feedback. Experiment on real-world sparse datasets show that our method outperforms current state-of-the-art recommendation method.
Key WordsЃКPersonalized Recommendation, Social Relationship, Implicit FeedbackЃЌ Sparse Datasets
1.в§бд
ИіадЛЏЭЦМіЯЕЭГдкКмЖраХЯЂЯЕЭГжаЗЂЛгзХдНРДдНживЊЕФзїгУЁЃДѓЖрЪ§ЕФЕчЩЬЭјеОЃЌЯёAmazonЃЌeBay КЭЬдБІЖМдкВЛЭЌГЬЖШЩЯВЩгУСЫИїЪНИїбљЕФЭЦМіЯЕЭГЁЃЛЙгаКмЖраТЮХЭјеОЛЙгаФкШнЩчЧјЃЌЯёЭЗЬѕЃЌжЊКѕЃЌЖЖвєвВЖМгУЭЦМіЯЕЭГРДЮЊгУЛЇЬсЙЉгХжЪЕФИіадЛЏЗўЮёЁЃШЫУёЭјФмЭЈЙ§ИіадЛЏЭЦМіММЪѕРДЖдгУЛЇЬсЙЉЭЦМіЃЌШУгУЛЇФмИќКУЕиЛёЕУЫћУЧИааЫШЄЕФФкШнЁЃ
ПЩЪЧЃЌдкКмЖрЦНЬЈЕФЭЦМіжагаСНИіжївЊЮЪЬтЁЃЕквЛИіЮЪЬтЪЧКмЖрЦНЬЈжЛДггУЛЇФЧРяЛёЕУСЫвўЪНЗДРЁаХЯЂЃЌЯдЪНЕФЗДРЁашвЊгУЛЇШЅИјЭЦМіЕФФкШнДђЗжЃЌетбљЖдгУЛЇВЂВЛгбКУЁЃЕкЖўИіЮЪЬтЪЧЛёШЁЕФЪ§ОнЕФЯЁЪшадЃЌетаЉЦНЬЈЕФЪ§ОнСПЪЧЗЧГЃОоДѓЕФЃЌЕЋЪЧУПИігУЛЇЫљФмПДЕНЕФЪЧгаЯоЕФЁЃУПИігУЛЇзюжебЁдёЪЙгУЛђЙКТђЕФВњЦЗвВжЛеМзмСПЕФКмаЁвЛВПЗжЁЃ
ЭЦМіЯЕЭГЛсЖдгУЛЇУЛгаИјгшЦРМлЕФВњЦЗзіГідЄВтЃЌДѓЖрЪ§ЕФдЄВтЖМЪЧЭЦМіЯЕЭГвРОнЯдЪНЗДРЁ(гУЛЇЖдЩЬЦЗЕФЦРЗж)РДзіГіЕФЁЃПЩЪЧЃЌдкКмЖрЦНЬЈЃЌЯёНёШеЭЗЬѕЃЌЮЂВЉЃЌЬдБІжаЃЌвўЪНЗДРЁЕФЪеМЏЛсИќМђЕЅЃЌВЂЧвЖдгУЛЇИќгбКУЁЃвўЪНЗДРЁАќРЈгУЛЇЕуЛїЃЌфЏРРЃЌбЁдёЪеВиЕШааЮЊЁЃЮвУЧМИКѕФмдкЫљгаЦНЬЈжаЭЈЙ§МЧТМгУЛЇЕФааЮЊРДЛёЕУе§ЗДРЁЃЌЕЋЪЧгУЛЇЕФИКЗДРЁОЭКмФбЛёШЁЕНЁЃДђБШЗНЫЕЃЌвЛИігУЛЇЕуЛїдФРРвЛЦЊЮФеТПЩФмДњБэзХгУЛЇЖдетИіЮФеТгаКУИаЃЌЕЋЪЧУЛгабЁдёЕуЛїетЦЊЮФеТВЂВЛДњБэгУЛЇЖдЦфУЛгаКУИаЁЃ
СэвЛИіЮЪЬтЪЧУПвЛИігУЛЇжЛдкЩйСПЕФЩЬЦЗЩЯВњЩњааЮЊЃЌЕЋЪЧзмЕФЩЬЦЗЪ§СПЪЧОоДѓЕФЃЌЕМжТгУЛЇбЁдёЕФЙЋЙВЩЬЦЗБШНЯЯЁЩйЃЌгУЛЇЖдЩЬЦЗЕФЗДРЁЪ§ОнвВЪЧМЋЦфЯЁЪшЕФЁЃ
дкЭјТчЩчЧјжаЃЌгУЛЇЕФЩчНЛЙиЯЕЭљЭљЪЧБШНЯШнвзЛёШЁЕНЕФЁЃЪТЪЕЩЯЃЌгУЛЇЕФЦЋКУГ§СЫПЩвдДгздЩэЕФааЮЊжаЛёШЁЭтЃЌЛЙПЩвдДгЫћУЧЕФКУгбЕФааЮЊжаЛёШЁЁЃОпгаЯрЫЦаЫШЄЕФХѓгбЖдБЫДЫгаИќЧПЕФгАЯьЃЌИќШнвзВњЩњЯрЭЌЕФааЮЊ[10]ЁЃ
дкетЦЊЮФеТжаЃЌГЂЪдзХв§ШыСЫгУЛЇМфЕФЩчНЛЙиЯЕвдДЫРДЛКНтЭЦМіЯЕЭГжаЕФЪ§ОнЯЁШБЮЪЬтЃЌвЛИіЛљгкSBPRЕФЭЦМіЫуЗЈБЛЬсСЫГіРД[5]ЁЃSBPRЕФжївЊЫМЯыЪЧРћгУБДвЖЫЙзюДѓКѓбщЙРМЦРДДгевЕНЩЬЦЗЖджЎМфЕФШЋађХХСаЙиЯЕЁЃ
етЦЊТлЮФжаЕФжївЊЙБЯззмНсШчЯТЃК
1.ЮвУЧзХблгкЭЦМіЯЕЭГжаЕФЪ§ОнЯЁЪшЮЪЬтКЭЕЅРраЭЌЙ§ТЫЮЪЬт[8]ЃЌЬсГіСЫвЛИіаТгБЕФУћЮЊSFSBPRЕФЛљгкЯрЫЦКУгбЕФBPRЃЈBayesian Personalized RankingЃЉЫуЗЈЃЌгааЇЕФЛКНтСЫЭЦМіжаЕФетСНИіЮЪЬтЁЃ
2.дкЯЁЪшЪ§ОнМЏЩЯЦРЙРСЫЬсГіЕФЗНЗЈЃЌЪЕбщНсЙћБэУїЬсГіЕФЗНЗЈМЋДѓЕФЬсИпСЫЭЦМіаЇЙћЁЃ
2. ЯрЙиЙЄзї
дкЭЦМіЯЕЭГжаЃЌзюБЛЙуЗКЪЙгУЕФЪЧKNNаЭЌЙ§ТЫ[1]ЁЃЦфжаАќРЈСНжжаЭЌЙ§ТЫЃЌЛљгкгУЛЇЕФаЭЌЙ§ТЫКЭЛљгкЮяЦЗЕФаЭЌЙ§ТЫЁЃетСНжжЗНЗЈЕФДѓжТЫМЯыЪЧевЕНКЭгУЛЇЯрЫЦЕФШЫЃЌШЛКѓетаЉШЫЕФЦЋКУвВИњИУгУЛЇЯрЫЦЁЃ
НєЫцЦфКѓЕФЪЧвўвђзгФЃаЭЃЌвўвђзгФЃаЭвРППбЇЯАУЛгажБНгЙлВьЕНЕФВЮЪ§РДВЙГфгУЛЇ-ЮяЦЗОиеѓжаЕФжЕЁЃвўвђзгФЃаЭБЛЙуЗКдЫгУдкЭЦМіЯЕЭГжа[3]ЃЌКмЖрбЇЯАЬиеїОиеѓЕФЫуЗЈБЛЬсСЫГіРДЁЃЦцвьжЕЗжНт(SVD)ЪЧЦфжажЎвЛ[2]ЃЌВЂЧвдкЭЦМіЯЕЭГжаЕУЕНСЫКУЕФдЫгУаЇЙћЁЃЕЋЪЧгУSVDРДбЇЯАОиеѓЗжНтФЃаЭШнвзЙ§ФтКЯЃЌЫљвдSVD++БЛЬсГіРДНтОіетИіЮЪЬтЁЃЕЋЪЧЕБЪ§ОнМЏЗЧГЃЯЁЪшЕФЪБКђЃЌетаЉЗНЗЈОЭВЛЪЧКУЕФбЁдёСЫЁЃ
ЛљгкЩчНЛЭјТчЕУЭЦМіЫуЗЈвВБЛЬсСЫГіРД[11]ЃЌЯёЛљгкИХТЪОиеѓЗжНтЕФЩчНЛЛЏЭЦМі(SoRec) [7]ЃЌНЋгУЛЇЖдЩЬЦЗЕФЦРЗжОиеѓгыгУЛЇЩчНЛЙиЯЕЭјТчЕФаХЯЂШкКЯЃЌНјааИХТЪОиеѓЗжНтЁЃетИіЫуЗЈЛКНтСЫЪ§ОнЯЁШБадЮЪЬтКЭРфЦєЖЏЮЪЬтЁЃПЩЪЧетИіЗНЗЈжЛЪЪгУгкЦРЗждЄВтЮЪЬтЃЌЫќдкНтОіЕЅРраЭЌЙ§ТЫЮЪЬтЕФЪБКђаЇЙћБШНЯВюЁЃШЛКѓвЛаЉДІРэЕЅРраЭЌЙ§ТЫЮЪЬтЕФЗНЗЈОЭгІдЫЖјЩњСЫ[8, 12].ЁЃ
ЭЦМіЯЕЭГжївЊЕФФПЕФЪЧдЄВтгУЛЇЦЋАЎЕФTop-kЩЬЦЗЃЌШЛКѓНЋетаЉЩЬЦЗЭЦМіИјгУЛЇЁЃИіадЛЏХХађЕФЗНЗЈОЭПЩвдОЭИќЪЪКЯетИіЙ§ГЬЃЌетвЛРрЫуЗЈВЛЪЧгХЛЏгУЛЇЖдЩЬЦЗЕФЦРЗждЄВтЃЌЖјЪЧжБНггХЛЏгУЛЇЖдЩЬЦЗЕФХХађдЄВтЁЃдкЭЦМіЯЕЭГжаЕФвўЪНЭЦМіЃЌЯёBPRетжжРраЭЕФЫуЗЈОЭгаИќГіЩЋЕФБэЯж[4]ЁЃЫцзХгУЛЇКЭЩЬЦЗЪ§СПЕФдіГЄЃЌЛљгкХХађЕФЭЦМіЫуЗЈПЩвдИќзМШЗЕиЗДгГгУЛЇЕФЦЋКУЁЃ
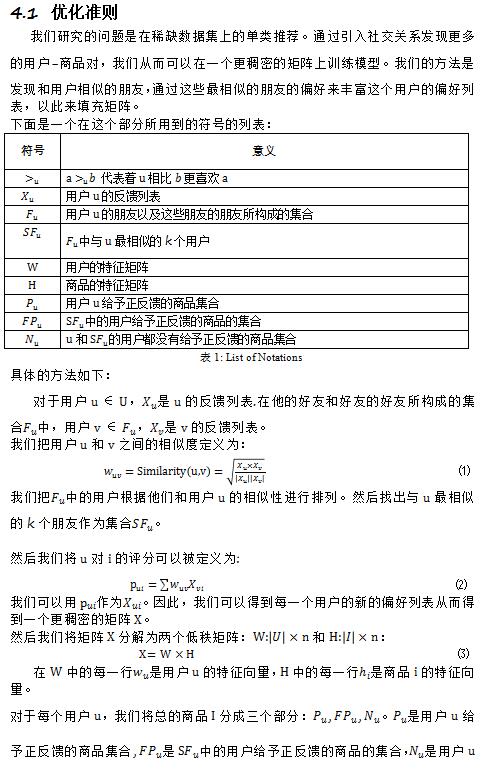
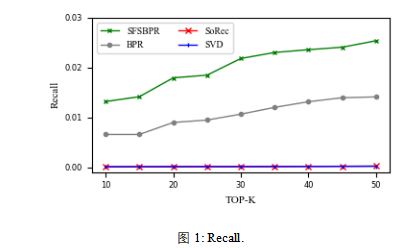
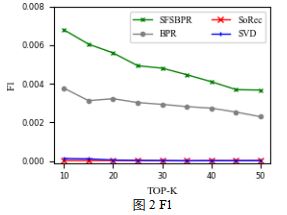
ЙигкSFSBPRЃЌSVDКЭSoRecКЭДЋЭГЕФBPRетМИжжЗНЗЈЕФЖдБШЬжТлЛсдкКѓУцЯъЯИИјГіЁЃЖдБШЩЯУцетаЉЗНЗЈЃЌдкЕЅРрЭЦМіжаЃЌЪ§ОнМЏЗЧГЃЯЁЪшЕФЪБКђЃЌЮвУЧЕФЗНЗЈФмЙЛВњЩњИќКУЕФдЄВтНсЙћЁЃ





6. НсТлКЭЮДРДЕФЙЄзї
дкетИіЙЄзїжаЃЌЮвУЧв§ШыСЫЩчНЛЙиЯЕРДЛКНтЪ§ОнЯЁЪшЮЪЬтВЂЧвЬсИпСЫдкЕЅРрЭЦМіЮЪЬтжаЕФаЇЙћЁЃдкЯЁЪшЪ§ОнМЏЩЯЕФЪЕбщБэУїЮвУЧЕФЗНЗЈгааЇЕФЬсИпСЫЭЦМіЕФзМШЗадЁЃдкЮДРДЕФЙЄзїжаЃЌЮвУЧНЋзХжигкЛљгкгУЛЇвўЪНЗДРЁЕФЭЦМіЁЃЮвУЧЛсЬНОПИќЖрЕФвђЫиРДЛКНтЪ§ОнЯЁШБЮЪЬтВЂЧвгУИќЖрЕФЬиеїРДЖдгУЛЇЦЋКУНЈФЃЁЃЮвУЧЛсЬНЫїИќЖрЗНЗЈРДЖдгУЛЇЦЋКУНЈФЃКЭНтОіРфЦєЖЏЮЪЬтЁЃ
ЗжЯэШУИќЖрШЫПДЕН 
ЭЦМідФЖС
ДЋУНЭЦМі
 @УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад
@УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ
ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
ЯрЙиаТЮХ
- 2020вЦЖЏЛЅСЊЭјРЖЦЄЪщЃКвЦЖЏЩчНЛГЩЮЊЕчЩЬЗЂеЙаТЗчПк
- ЮтГПЙтЃКЫуЗЈЪБДњЃЌзмБрМЛсЯћЪЇТ№ЃП
- ЧЛѕГіКЃдЦжБВЅ НЋЭЦМі61жжЩЬЦЗ
- ЛёШЁаХЯЂеЙЯжздЮвгЊЯњЭЦЙу ЩчНЛЦНЬЈОКЯрЧРеМаТШќЕР
- МгЧПаХЯЂЫибјНЬг§ЃЌДгШнгІЖдИіадЛЏЭЦМіЕФаТЩњЬЌ
- AIЫуЗЈгыДѓЪ§ОнЕФзщКЯШЪЕЯжИіадЛЏНЬбЇ
- ИіадЛЏаТЮХЭЦМіЯЕЭГжаЫуЗЈАбЙиЕФЫМПМ
- ЁАКНАрЩчНЛЁБвЊМсГжгУЛЇзддИддђ
- жїСїМлжЕЕМЯђЃКЩчЛсЛЏЭЦМіЕФЙиМќЮЌЖШ
- 5GЪжЛњЪзХњгУЛЇЛЯёЦиЙт ФаадОгЖр ФъЧсЖрН№
ПЭЛЇЖЫЯТди
ШЫУёШеБЈЩчИХПі | ЙигкШЫУёЭј | БЈЩчеаЦИ | еаЦИгЂВХ | ЙуИцЗўЮё | КЯзїМгУЫ | ЙЉИхЗўЮё | Ъ§ОнЗўЮё | ЭјеОЩљУї | ЭјеОТЩЪІ | аХЯЂБЃЛЄ | СЊЯЕЮвУЧ
ЗўЮёгЪЯфЃКkf@people.cn ЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-65363263 ОйБЈгЪЯфЃКjubao@people.cn
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170001 | діжЕЕчаХвЕЮёОгЊаэПЩжЄB1-20060139
ЙуВЅЕчЪгНкФПжЦзїОгЊаэПЩжЄЃЈЙуУНЃЉзжЕк172КХ | ЛЅСЊЭјвЉЦЗаХЯЂЗўЮёзЪИёжЄЪщЃЈОЉЃЉ-ЗЧОгЊад-2016-0098
аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0104065 | ЭјТчЮФЛЏОгЊаэПЩжЄ ОЉЭјЮФ[2020]5494-1075КХ | ЭјТчГіАцЗўЮёаэПЩжЄЃЈОЉЃЉзж121КХ | ОЉICPжЄ000006КХ | ОЉЙЋЭјАВБИ11000002000008КХ
ШЫ Уё Эј Ац ШЈ Ыљ га ЃЌЮД О Ъщ Уц Ък ШЈ Нћ жЙ ЪЙ гУ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЦРТл

-
ЙизЂ
ЮЂаХЮЂВЉПьЪж
 ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
 БЈЕРШЋЧђ ДЋВЅжаЙњ
БЈЕРШЋЧђ ДЋВЅжаЙњ
 ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
