




















��������ģ�͵������ȵ������ݻ������о�
ժ Ҫ��������ý��Ŀ��ٷ�չʹ����ÿ�ս����ź��������š������ȵ����Ų������ݻ����ƽ����ھ��������ý��������ŷ���Ͷ���ϲ�ã��������û��ͳɱ���ȫ��λ���˽������¼�������ȥ����ý����վ��ͨ��ʵʱ��ȡ���Ų������ı����������þ��������ʱ�������ھ���㷨�����˽��ȵ������¼����ݻ����ơ����Ľ������ھ������ṩ��һ�ֻ�������ģ�͵��ȵ������ݻ������ھ��������ƣ�����Ͼ���������¼����з�����
�ؼ��ʣ��ȵ����ţ����࣬����ģ�ͣ��ı��ھ������ݻ�
1�������
���Ż������ķ�չ�����������ѳ�Ϊý�巢�����š��û��Ķ����ŵ���Ҫ��������Web2.0ʱ���������е���Ϣ��������Ѹ�ٱ�ݣ����������������������������˸����ȵ����ŵĵ����������е��ȵ�������ָ��ӳ��ᷴ��Ƚϴ�����ȽϹ�ע���������ݣ����д����졢Ӱ������ע�ȸߵ��ص㡣�����е��ȵ�����һ��ᾭ������������仯�����������Σ���ͬ�ε������в�ͬ���ȶȺͻ��⡣�������Ķ��������Ϻ�������ʱ�������ص��עijЩ������������ţ�����ϣ���˽����ŵ����ŵ�����ȥ���ȷ�����Ϣ��
�������ȵ������¼����ھ�������㻥�����û������Ķ����������и�����ϢԴ��ͬ�����Ƶ������¼��ۼ���һ����ۼ���һ��������¼�����ʱ���Ⱥ�˳��������к�ͳ�ƣ��������ܹ��ó������¼�������չ�Լ������һϵ�й��̣���ͨ��ͳ����Ϣ�������õ��¼���ע�ȱ仯���ߡ��ھ�����ʹ�û��������ݵ�ȥ�˽�������������Ϣ�ݻ����ƺ�״����ͬʱҲ�����û�ȥ��ע���������е�һЩ�������š�
���û��Ƕȿ�,���ȵ������ݻ����Ƶ��ھ�������û��ṩ�˸�Ϊ�����ݵķ���,���ܹ�ʹ�û�����С�Ĵ��ۻ�ȡ�����ȫ�������,���ܹ������û���ȷ����Ѹ�ٵ��˽�һ���¼�������ȥ����������չ�����Լ���������Ը��¼�������Ϳ�������ý�����վ�����߶���,�ӶԻ������������¼����о���������Ч�ĵó����������ȵ����ŵ�Ǩ�ƣ��������û���Ϊϰ�߱仯�Լ������������۵���[1]������ý����ݶ���ϲ�ú��ȵ�������ű����������Ϳ������ŷ�չ��
2���ȵ������ھ������о����
2.1 �ȵ������ھ���ؼ�����״
�ڶ��ȵ����ŵ��ݻ�״�������ھ�ʱ����Ҫ��ʹ�õ��мල��ѧϰ���ල��ѧϰ�Լ�������������ȷ������ؼ�����
��1�����ž��༼��
��ͳ�����������������һ����������ռ�ģ������ʾһ�������ĵ���Ȼ��ͨ�����ƶȹ�ʽ�������ĵ�֮��ľ��룬�������������ʶ����Ҫ��������������㷨��ʵ�֣�ͨ�������ȡ�����������Բ�ͣ�����ɡ��ܽ��γ��µ���������[2]����������·���������˶������ž��������Ron Papka[3]��ѧ���������һ�ֻ��ʽ����������㷨���������־����㷨���л�ϴ��䣬���ݲ�ͬ�����㷨֮����ص㣬��ȡ�ں�������������������ࡣSayyadi[4]���о���Ա�������������罻�����������������һ�ֻ��ڹؼ���ͼ��������������㷨����ֵ���������������ϵͳ�е��������罻������Ϣ��ȡ���˲�����Ч����
��2�����ŷ��༼��
������վ�������Ž��з���ʹ�ö��߿��Ը�ȷ���ҵ��Լ�����Ȥ�ķ��ಢ�����ڹ����Ķ��Ľ���, ����Ŀǰ����ҳ���·��������Ƽ�, ����ʹ���߱�ݵ��Ķ����뵱ǰ�Ķ�������ص���������ҳ�档Ŀǰ������ѧϰ�������缼���ķ�չʹ�����ŷ������죬��֧����������SVM������������KNN�ȷ����㷨�����ŷ��������Ͼ��в����ı��֡�
��3�������ھ���
�Ǽල��ѧϰ�е�����ģ�ͣ����������ٺͼ�������ȵ㻰�⡣ͨ������ģ�ͽ������ı��е����� ��ȡ�����ٽ��з���������ģ��Ҳ�ǽ������ı��ھ� ������ȵ㡣����ģ����Դ��Deerwester[5]��1990���������������������M. Blei��2003��[6]�����LDAģ�ͣ���չ�����������������õ�һ����Ϊ��ȫ�ĸ�������ģ�͡������������ض���Ӧ�ó������ϣ�������Խ��Խ��Ļ���LDA�ĸ���ģ�͡�
��4�������ݻ��ھ���
���Ż����ݻ������ھ�[7]��������ij���ض��������ر����ѱ����ٵ�ǰ���£���������֮�������ϵ���Զ���֯�ɷ��������¼���չ�켣���������о���һ���ص㼯����������֮�������Զ���������ǿ�ȣ����棬���о��������ŷ�չ�켣�����϶��µģ�����ʱ����ڡ��¼�Ҫ�ع������ԣ������¼������ݹ���ǿ�ȡ�ʱ���ϵ���Թ�������Ż����ݻ�������[8]��
2.2 �ȵ������ݻ������ھ���
��������е��ȵ������ݻ����Ʒ�����Ҫ��Ϊ����ģ�飺���Ż�ȡģ�飻�ȵ�����ʶ��ģ����ȵ������ݻ�����ģ�顣�������Ż�ȡģ����Ҫ������ݵļ�ʱ�Ի�ȡ�����ȵ�����ʶ��ģ����Ҫ�������ı���Ϣ����Ԥ���������þ��༼�������Ž��о۴أ��ھ������ȶȼ��¼���ǩ���ȵ������ݻ�����ģ����Ҫ�Դ���������ʱ�������Ͻ��������ھ��ھ���������ݻ�������ӻ�չʾ��
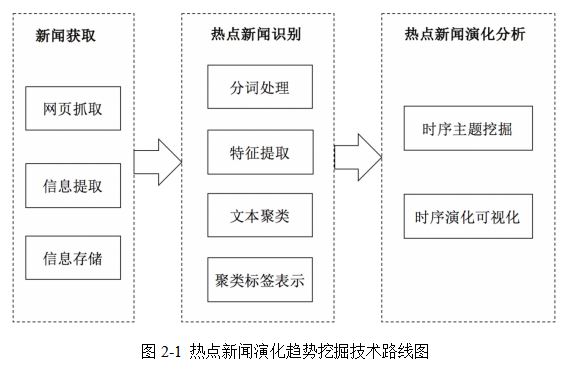
3�����Ż�ȡ
�ڻ�ȡ���ŽΣ���ҪĿ����ʵʱ�Եû�ȡ������վ�ĺ����������ݣ�����������ݻ����Ʒ���������Ҫ���ڸýΣ�һ�������Ϊ����ҳץȡ����ҳ��������Ϣ��ȡ����Ϣ�洢��
��1����ҳץȡ
������ҳ��ץȡ�ǻ�ȡ���ݵĻ�������������ھ�ץȡ�����ҳҪ���������ص㣺��ʱ�Ͷ���ʱץȡ����ָΪ�˱�֤���ŵ�ʱЧ��,��Ҫ��ʱ��ÿ�졢ÿ�ܻ�ÿСʱ��ץȡ����վ�������ҳ�档����������վ��ÿ�춼�д������Ų�������ʱץȡ�������Ų�������������ݻ����Ƶ��ھ���ץȡ����Ϊ�˷�ֹץȡ�����ŷֲ����ڷ�ɢ���ɴ�������վ��ר��ҳ������ҳ����ץȡ����������Ϊ�����ɴӹ�������ģ�����ÿ��0��ץȡ���ţ���֤ץȡ�ļ�ʱ�Ժ�ץȡ���ݵķḻ�ԡ�
��2����ҳ��������Ϣ��ȡ
��ҳ�Ľ���,�ܹ��õ���ҳ�бȽϵ�һ�̶���Ԫ��,������ҳ���⡢�����⡢������Ϣ���ı���Ϣ�ȣ�python��java���Ի������г���Ĺ��߰�����ʹ�á�SST��Site Style Tree���㷨�ṩ��һ�ָ���Web��ҳDOM���ڵ���Ϣ����ȡ��Ч��Ϣ�ķ��������Թ�����ҳ�е��������������Ϣ�������ȡ��Ϣ����Ч�ԡ�
��3����Ϣ�洢
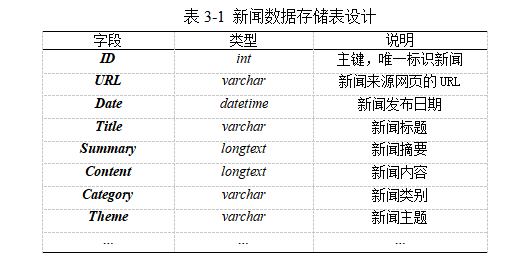
Ϊ���ڰ���ʱ���߶����Ž��з�����Ҫ��¼�洢��ҳ��ʱ�䡢���ű��⡢�������ݵ���Ϣ���洢��ҳ������Ϣ����ϵͳ��ʹ��SQL-Server���ݿ��Oracle���ݿ�洢������������ݶ��̲߳�����ѯ��������ҳ���Ŵ洢�����ֶ�������3-1��ʾ���ֶ���Ҫ����ԭʼ��ҳ�е�������Ϣ�ʹ�����Ĺؼ���Ϣ��Ϊ������ѯ�ٶȣ��ɶԲ����ֶ�����������
4���ȵ�����ʶ��
��ȡ����������������֮������ı��������ķִʡ�ȥͣ�ô���ͼ�ֵ�ʡ��ı�������ʾ��Ԥ��������������������ķ���Ҫ���������ȶ�ʶ��ģ�飬��Ҫ���þ����㷨�����ı����о��࣬�ھ������ı����ϵ����������⣬�����ȵ����Ż��⼯Ⱥ������
��1���ı��ִ��봦��
����ԭʼ�����ı������Խ���ʹ�þ����㷨���з����������ı��ִ��DZز����ٵĻ��ڡ�Ŀǰ������Jieba��THULAC��ICTCLAS�Ƚ�Ϊ��������ķִʹ��ߣ���ʵ�ֶ��������Ͻ��зִʡ����Ա�ע���´�ʶ��Ȳ�����Ϊ�����ı��������ִʺ�ɶԷִʽ������ȥͣ�ôʲ�����
��2���ı�������ʾ
�ִʺ�Ĵ��O�Ͽ���ʹ�û��ڴ����۵������ռ����ڸ���ͳ�Ƶ��ı�ģ�ͽ��б�ʾ�������ռ�ģ����Ҫ�ǰ��ı������һ��������, �Ǵʿ���Ψһ���ڵĴʣ���ȡֵȷ���˸ô�������ĵ�������ǿ�����������˴������ĵ��е���Ҫ��ͨ��������ʹ��TF-IDF����Ƶ-�����ĵ�Ƶ�ʣ�ֵ��ʾ�����������Ȩ�أ��ڴˣ����ٶ�TF-IDF�㷨��������ܡ�����ͳ��ģ�Ϳ����˴����е�������ϵ������������ռ�ģ�ͣ���������ĵ����ɵĿ۹��ɣ������㡢ͳ��������ʶ���Ϊ���ӣ���Ҫ�����������Ż��������ĸ���ͳ��ģ����n-gramģ�ͺ�����������Ʒ�ģ�͵ȡ�

��ʵ�ʲ����У��������ż��ϰ����Ĵ�����Ŀ�࣬���������������ռ��ά���㣬�����ģ�ϴ�Ϊ����������Ч�ʣ����Զ��ı����������ռ����ѹ�����ڼ����ı���������ʱ��ֻ�洢��ʹ�������ĵ������������Ȩ�أ���������������ά����
��5�������ǩ��ʾ
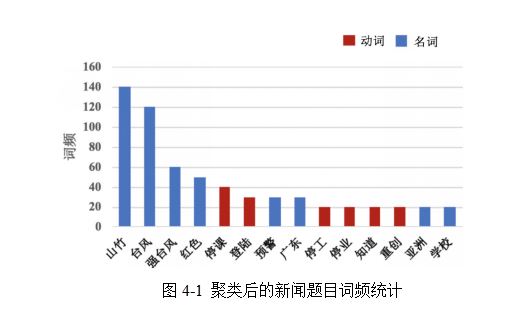
�����ij�༯���µ������������Ա�ʾ�������ŵ��ȶȡ����ݾ��༯���µ������������������ĸ���Ⱥ�µ����ű���������ߡ���������Խ�ߣ��ý�������Ŵ������¼���Խ���š�������ʹ��һ�������Ա�ǩ����ӳ����������ŵĻ��⣬��ʾ�������ż��ϵ����ڽ�ʲô�¼������ھ�������������������ֱ��ѡȡ�������ĵĴ�������Ϊ�����ǩ��Ϊ�����Զ��ھ����ż��ϵĻ��⣬����������Ȼ���Դ����ķ��������ı����ݽ��й����ܽᡣ����Դ��������ı����ھ���������Ӵ��������һ��ʹ�����ű��⼯�ϲ�����ǩ�ľ������ͨ�������ű��⼯�Ͻ����з֡���Ƶͳ�ƺʹ��Ա�ע��ѡ���Ƶ��Ŀ��ǰ�����ʺͶ�����Ϊ�����ǩ�����磺�ھ����õ���һ������̨������ŵļ��ϣ����ü����µ����ű�����д�Ƶͳ�ƣ�ȡ���ʺ������д�Ƶ����ǰ��λ�Ĵ�����ɴ��O��{ɽ��̨�磬ͣ�Σ���½}���ô��O�����㹻��Ӧ�������ŵ����⡣
5���ȵ����������ݻ�����
�����Դ��������ı��ľ�����Ѿ����ÿ������ż��Ϻͼ�Ҫ�ļ��ϱ�ǩ���������������Զ�ͬһ�������ż��Ͻ��������ȡ���ݻ�������
5.1 DTM����ģ��
�����ı��������ھ�ģ���кܶ࣬�ʹ�õ��ǻ���LDA�������ھ�ģ�͡�LDAģ����һ�ֻ���DZ�ڵ������ֲ�����������ģ�͡����������ģ����, һϵ�������Է��Ӷ���ʽ�ֲ�����ʽ����ÿ���ı�, �ٴ���Щ������ͬ���Է��Ӷ���ʽ�ֲ��ķ�ʽ������ÿ������, �ɴ˹��ɸ�ģ�͡�����ͳ��LDAģ�ͺ������ı�֮������ʱ���ϵ�ij�ֹ�������Ծ����ݻ�ʱ���ǩ���ȵ����ż��ϣ����뿼�����Ż�����ʱ���ϵı仯�����
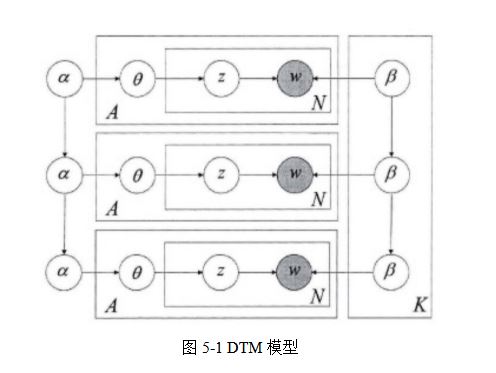
DTMģ������Blei��2006��[6]�����ģ�ͣ�����LDA�Ļ����ϼ���ʱ�������Ϣ��ѵ����ʱ����ص�ģ�ͣ��Ӷ�����������ʱ���ϵı仯����ͳ��LDA����ģ���������ĵ�ʱ����Ϊ�ĵ��е�ÿ�����ʶ�Ӧ�������ǿ��Խ����ش�һϵ�е������в����õ��ģ�������ʵ�����У��ĵ���ʱ��˳��Ӱ��������ļ���������⡣DTM�����ı�������ʱ��˳���Ϊ������ϣ����簴�꣬��ôʱ��Ƭt�������Ǵ�ʱ��Ƭt-1�������ݻ��õ��ġ�ʱ��Ƭt-1��ģ�Ͳ�����ʱ��Ƭt��ģ�Ͳ�������Ӱ�졣ͼ5-1չʾ��������ʱ��Ƭ��DTMģ�ͣ�����ͼģ�͵IJ����������5-1��ʾ��


5.2 ���������ھ�
�������ʵ���У�ʡ�����ž���Ļ��ڣ���������ֱ��ץȡ��3�·����������¼����еĹ��ڡ��ε�˳�糵����ص����ţ�ʹ������ģ�ͽ������������ھ����ھ��������Ի�����ż��ϵ��������⣬��ϴ������֮����ظ������ÿ��������5�����ʹ��ɡ���������ģ�͵��ھ��Ѿ��ܹ���������Ĵ��º��塣���磺topic3��ָ������Ů�Գ����ε�˳�糵���ѡ���һ�¼���topic6��ָ���ειر�ҹ������¼�������Ӧ��
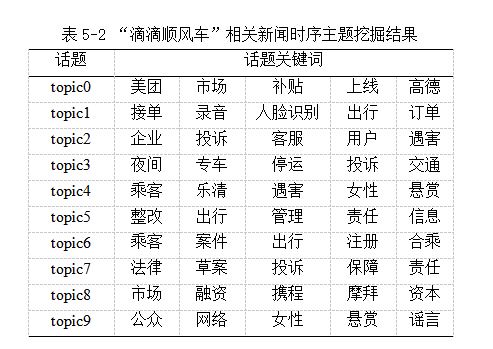
5.3 ����ʱ���ݻ�����
���Ż����ݻ������ھ���Ҫ��һ��������֡���չ���߳���ƽ���������������������١�һ�����ӵ����Ż�����������������¼������¼�֮��Ҳ������һЩ����ʱ���ϵĹ�����ͨ����Щ�¼�֮��Ĺ�ϵ�����Եõ����Ż����µ��¼��ݻ����磬�����û��������ŵ�����ȥ����
����ʹ�á��ε�˳�糵���¼�������ʵ������ʶ������Ż����������������������仯������ʱ���������ϱ�ʾ���������Է��ָ���������ʱ����ݻ�����Ͳ�ͬ�¼��ԡ��ε�˳�糵���¼������IJ��ص㣬��ͼ5-2��ʾ�����ӻ���������ݻ�����ͼ����������չʾij���⼰���ӻ�����֡���չ���߳���ƽ���ķ�չ���ơ�
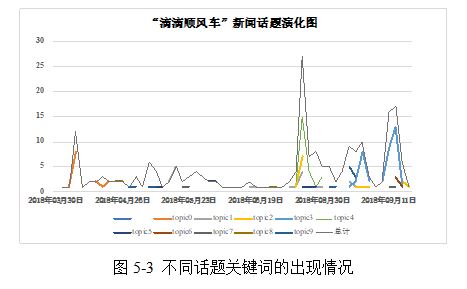
ͨ��ͼ5-2���Կ�����Topic4��������-Ů��-�˿�-����-���͡��ı�����������2018��8��26�����ұ������ﵽ���壬����ϸ��¼�ʵ�ʱ������ݻ������Topic3���⡰ҹ��-ר��-ͣ��-Ͷ��-��ͨ���ı�����������2018��9��11�����������½�������ε��ڸ�ʱ����ھ���ҹ��ͣ��ר��ҵ��һ�����Ǻϣ�Topic0���⡰����-�г�-����-����-�ߵ¡���������2018��4�·ݿ�ʼ���ֲ����࣬������ʱ����ý����ڵεδľ����������Ŵ����ߵ����Ž϶࣬��Ҳ����ʵ�����
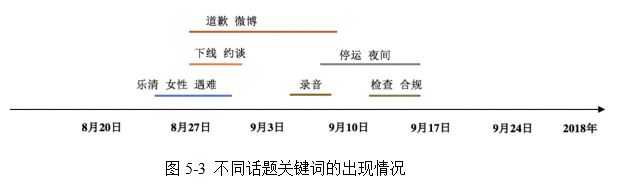
�����������ھ�Ļ����ϣ�ѡȡ��������ʣ���ÿ����Ƶ����ʵĴ��������ʾ��ʱ�������ϣ���ͼ5-3��ʾ�������¼��ķ�չ���ݻ�����һĿ��Ȼ��
6���о�������չ��
��1����������������¼�����
���ྡ�ܿ��Խ���ͬ�����ͬ�¼��µ������¼��۴أ�������������ѡ�����������ȵ����ŵ����¼����룬Ϊ�����������ݻ������������㡣����Ż��ı����ƶȵļ��㷽����������Ŀ���㷨Ŀ�꺯������һ�����⡣
��2��ʱ�����Ĵ����ظ�
Ӧ��ʱ������ģ���ھ���IJ�ͬ�����µ�����ʴ��ڽ�������Ȼ������ͬ����ӵ�����Ƶ�����ʣ�������ͬ���༯Ⱥ�£�����Ҫ���ǻ�ò�ͬ����������������ȵ������¼��Ķ�̬��չ��ת�ۡ��������ھ�֮�ɽ���ͬ����ʼ��ϼ�Դ�����ж���ɸѡ��
��3��ʱ���������ϵ��δʶ��
����ʱ�������ھ�������ʼ��Ͻ�Ϊ������δ���γ������������¼��ݻ����������������û������Ķ����ɳ��Թ��������¼���IJ�νṹ����Ͼ��༯Ⱥ��ǩ���ͺ�����ʼ��ϣ����������¼���չ�����������
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
- AI����Ͼ䣿���ķִ���ģ�Ͱ�������
- �˹��������ˡ�ɱ�������� �����߲����㷨ģ�Ͱ�ȫ��
- ��ҽ��Ԥ��ģ�ͷ�����Ԥ�ư���ʡ���ش�ʩ�����·��¹ڷ���3500����
- 1.24����ǰ��һ�Ρ����֡����ò��鶯��Եø���
- ��������ϸ����ģ�ͽ���
- �����ȵ�������о�Ժ���� ��רעý�崫�������ݺ����о�
- �й���Ⱥ����������¡�ṹ���ݻ�ģʽ����
- ίԱ����յ�357�� �����ȵ㻰�����ܹ�ע
- ���ڻ���ѧϰ����������¼��ھ�
- ����K-Means�㷨�������ı����ݹ���
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
