




















ШЫЬхЙиМќЕуМьВтФЃаЭбаОП
еЊвЊЃКвРРЕгкЁАДѓЪ§ОнЁБММЪѕгыИпадФмДІРэЦїЕФХюВЊЗЂеЙЃЌЩюЖШбЇЯАвдЦфЧПДѓЕФТГАєадКЭгааЇадГЩЮЊСЫМЦЫуЛњЪгОѕЁЂздШЛгябдДІРэЕШШЫЙЄжЧФмЗжжЇСьгђжаеМОнжїЕМЕиЮЛЕФбаОПЗНЗЈЁЃШЫЬхЙиМќЕуМьВтЪЧМЦЫуЛњЪгОѕжавЛИіМЋОпЬєеНадЕФбаОПЁЃПЩгУгкЃКЖЏзїЪЖБ№ЃЌвьГЃааЮЊМьВтЃЌАВЗРЕШЁЃБОЮФжМдкЬсГівЛжжЛљгкЩюЖШбЇЯАЕФФЃаЭЃЌНтОіШЫЬхЙиМќЕуМьВтШЮЮёжаДцдкЕФжюЖрЮЪЬтЃЌЬсЩ§МьВтаЇЙћЁЃИУШЮЮёФПЧАжївЊДцдкШЫЬхЙиМќЕуГпЖШВювьадЮЪЬтЁЃБОЮФв§ШыФПБъМьВтСьгђжаСїааЕФЬиеїН№зжЫўЭјТчЃЈFeature pyramidnetworkЃЉЃЌЭЈЙ§дкЖрГпЖШЕФЬиеїЭМЩЯЬсШЁЬиеїВЂНЋИпВугявхЬиеїгыЕзВуЭМЯёЬиеїШкКЯЕФЗНЪННтОіДЫЮЪЬтЁЃБОЮФдкИФНјКѓЩшжУСЫЖдБШЪЕбщвдбщжЄМйЩшЁЃзюжеЬсГіСЫвЛИіаТФЃаЭЁЊЁЊЬиеїН№зжЫўзЂвтСІЩГТЉФЃаЭЃЌЦфдкMPIIКЭLSPШЫЬхЙиМќЕуМьВтЪ§ОнМЏЩЯШЁЕУСЫФПЧАзюКУЕФМьВтаЇЙћЁЃ
ЙиМќДЪЃКШЫЬхЙиМќЕуМьВтЃЛЬиеїН№зжЫўЭјТчЃЛзЂвтСІФЃаЭ
1 ПЮЬтБГОАгыбаОПвтвх
1.1 ПЮЬтБГОА
21ЪРМЭЪЧДѓЪ§ОнЕФЪБДњЃЌдЦМЦЫуЕФГіЯжЁЂвЦЖЏЩшБИЕФЦеМАЃЌЪЙЕУШЫУЧдкОйЪжЭЖзуМфОЭЛсВњЩњДѓСПЕФЪ§ОнЁЃетаЉЪ§ОнЕФаЮЪНЖржжЖрбљЃЌПЩвдЪЧЮЂаХжаЕФгявєаХЯЂЃЌПЩвдЪЧЮЂВЉжаЕФЮФзжаХЯЂЃЌвВПЩвдЪЧЬдБІЩЯЕФЖЉЕЅаХЯЂЁЃетаЉЪ§ОнЬхСПОоДѓЕЋЪЧНсЙЙИДдгЃЌШчКЮИпаЇЕФРћгУетаЉЪ§ОнГЩЮЊАкдкбаОПШЫдБУцЧАЕФвЛИіживЊЮЪЬтЁЃгыДЫЭЌЪБЃЌвдCPUЁЂGPUЮЊДњБэЕФИпадФмДІРэЦїЕФбИУЭЗЂеЙвВЮЊИпаЇРћгУетаЉЪ§ОнЬсЙЉСЫГфзуЕФЖЏСІЁЃ
ШЫЬхЙиМќЕуМьВтЪЧМЦЫуЛњЪгОѕжавЛИіОпгаживЊвтвхЕФШЮЮёЃЌ2014ФъвдЧАЃЌбаОПепНтОіИУШЮЮёЕФЗНЗЈжївЊЪЧЪЙгУSIFTЃЌHOGЕШЬиеїЫузгЬсШЁЬиеїЃЌНсКЯЭМНсЙЙФЃаЭРДМьВтЙиНкЕуЮЛжУЁЃЫцзХЩюЖШбЇЯАгыМЦЫуЛњЪгОѕжюЖрШЮЮёНсКЯВЂШЁЕУЯджјГЩЙћЃЌбаОПепПЊЪМГЂЪдНЋЦфгыШЫЬхЙиМќЕуМьВтШЮЮёНсКЯЁЃЩюЖШбЇЯАПЩвдЭЈЙ§бЕСЗЕУЕНИДдгЕФгГЩфЙиЯЕЃЌДгЖјЬсШЁИќИДдгЕФИпНзЬиеїДњЬцSIFTЃЌHOGЕШШЫЙЄЬиеїЁЃЩюЖШбЇЯАОпгаИќЧПЕФТГАєадКЭБэДяФмСІЃЌдкЮяЬхЪЖБ№ЃЌФПБъМьВтСьгђЫљШЁЕУЕФГЩЙћвбОгЁжЄСЫетаЉгХЕуЁЃЫљвдЩюЖШбЇЯАЧЁЧЁПЩвдНтОіЩЯЪіСНИіШБЕуЁЃБОЮФНЋЗжЮіЛљгкЩюЖШбЇЯАЕФШЫЬхЙиМќЕуМьВтЫуЗЈЕФЗЂеЙЃЌВЂЖдЦфНјааИФНјЁЃ
1.2 ШЫЬхЙиМќЕуМьВтМђНщМАвтвх

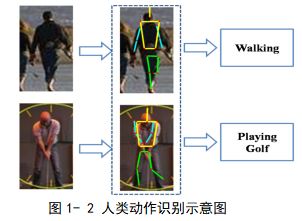
ШЫЬхЙиМќЕуМьВтвВГЦШЫЬхзЫЬЌЙРМЦЁЃШчЭМ1-1ЫљЪОЃЌШЫЬхзЫЬЌЙРМЦЕФШЮЮёЪЧвЊдкИјЖЈЕФЭМЦЌжаЖЈЮЛШЫЬхЕФЩэЬхЙиМќВПМўЃЌР§ШчЭЗВПЃЌОБВПЃЌМчВПЃЌЪжВПЕШЁЃдкВЛЭЌЪ§ОнМЏЩЯЃЌашвЊМьВтЕФОпЬхВПЮЛВЛЭЌЁЃР§ШчЃЌБОЮФжаЪЙгУЕФMPIIЪ§ОнМЏЩЯЖЈвхЕФЙиМќЕуЙВга16ИіЁЃЫќЪЧИќИпМЖБ№МЦЫуЛњЪгОѕШЮЮёЕФЛљДЁЁЃЦфгІгУГЁОАжївЊгаЃК
ЃЈ1ЃЉШЫРрааЮЊЪЖБ№ЃКШЫРрааЮЊЪЖБ№ЪЧжИдкИјЖЈЕФЭМЦЌЛђепЭМЦЌађСажаЪЖБ№ГіШЫЬхЕФЖЏзївтЭМЁЃШчЭМ1-2ЫљЪОЃЌИјЖЈвЛеХЭМЦЌвЊЧѓМЦЫуЛњЪЖБ№ГіЭМжаШЫРрЕФЖЏзїЃЌЩЯУцвЛааЕУЕНЕФНсЙћЮЊзпТЗЃЌЯТУцвЛааЕУЕНЕФНсЙћЮЊДђИпЖћЗђЁЃШЫРрааЮЊЪЖБ№ЪЧМЦЫуЛњЪгОѕСьгђвЛИіМЋЦфживЊЕФбаОПЗНЯђЁЃЦфБЛЙуЗКЕФгІгУгкМрПиЃЌгщРжЃЌШЫЛњНЛЛЅЃЌЭМЯёКЭЪгЦЕЫбЫїЕШСьгђЁЃ
ЃЈ2ЃЉШЫЛњНЛЛЅЃКШЫЛњНЛЛЅЪЧжИЩшМЦвЛжжМЦЫуЛњКЭгУЛЇНјаааХЯЂДЋЕнЕФНгПкГЬађЁЃШЫЛњНЛЛЅДІгкМЦЫуЛњПЦбЇЃЌааЮЊПЦбЇЃЌЩшМЦЃЌУНЬхбаОПЕФНЛВцЕуЁЃвЛИіГЃМћЕФР§згЪЧЃКбаОПШЫдБПЩвдЭЈЙ§ИјМЦЫуЛњАВзАЩуЯёЭЗЕФЗНЪНЪЙЦфПЩвдЛёШЁШЫРргУЛЇЕФЭМЯёаХЯЂЃЌдйЭЈЙ§ЖдЭМЯёаХЯЂЕФЪЖБ№ЪЙЕУМЦЫуЛњРэНтгУЛЇЕФвтЭМЃЌДгЖјДяЕННЛЛЅЕФФПЕФЁЃ
ЃЈ3ЃЉЗўзАНтЮіЃКЗўзАНтЮіЪЧжИдквЛеХЭМЯёжаНтЮіГіШЫЬхЩЯВЛЭЌЕФЗўзАЃЌШчЭМ1-3ЫљЪОЁЃНтЮіЗўзАЕФЪгОѕЫуЗЈОпгаИїжжИїбљЕФЧБдкгІгУМлжЕЃЌИќКУЕФРэНтЭМЯёЃЌШЫЮяЗўЪЮЪЖБ№ЃЌЛђЛљгкФкШнЕФЭМЯёМьЫїЕШЁЃЕЋЪЧЃЌгЩгкШЫЬхзЫЬЌЕФИДдгадЃЌНтЮіЗўЪЮЕФШЮЮёВЂВЛШнвзЁЃ

2 ЛљгкЬиеїН№зжЫўЭјТчЕФИФНјЗНЗЈ
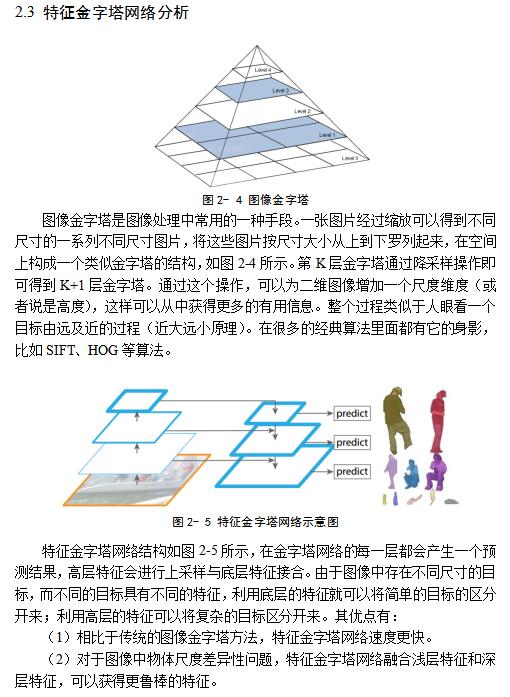
еыЖдЩЯвЛеТЬсГіЕФЙигкШЫЬхЙиМќЕуМьВтжаГпЖШВювьадЕФЮЪЬтЃЌБОеТЭЈЙ§НЋЬиеїН№зжЫўЭјТчЃЈFeature pyramid network, FPNЃЉШкКЯЕНЖбЕўЩГТЉФЃаЭНтОіетвЛЮЪЬтЁЃЬиеїН№зжЫўЭјТчдкВЛЭЌГпДчЕФЬиеїЭМЩЯЬсШЁЬиеїЃЌШЛКѓгжНЋВЛЭЌГпДчЕФЬиеїЭМНјааШкКЯЃЌПЩвдЬсШЁЕНЖрГпЖШЕФЬиеїЃЌДгЖјНтОіжЎЧАЬсЕНЕФГпЖШВювьадЮЪЬтЁЃБОеТЪзЯШЯъЯИУшЪіГпЖШВювьадЮЪЬтЃЌВЂЗжЮіЦфдвђЁЃШЛКѓЃЌИјГіОпЬхФЃаЭЩшМЦЯИНкКЭЪЕбщНсЙћЁЃ
2.1 ШЫЬхЙиМќЕуГпЖШВювьадЮЪЬт
ШЫЬхЙиМќЕуМьВтШЮЮёжавЛИіЭЛГіЕФЮЪЬтОЭЪЧгЩгкЪгНЧВЛЭЌКЭШЫЬхзЫЬЌЕФИДдгЖјв§Ц№ЕФЙиМќЕуГпЖШВювьадЮЪЬтЁЃОпЬхШчЭМ2-1ЫљЪОЁЃ

етСНеХЭМЦЌОљГіздгкLSPЪ§ОнМЏЃЌЕЋЪЧгЩгкЪгНЧКЭШЫЬхзЫЬЌЕФВЛЭЌЃЌдьГЩСЫШЫЬхЙиМќЕуЕФГпЖШВювьЃЌМДЪЙвбОЖдЭМЦЌНјааВУМєКЭЫѕЗХДІРэЃЌЪЙЕУШЫЬхЧјгђДѓжТЮЛгкЭМЯёжааФЃЌВЂЧвШЫЬхЕФГпДчНќЫЦЁЃЕЋЪЧвРШЛПЩвдЙлВьЕНЃЌЭМ2-1 (a)жаШЫЬхЭЗВПЕФГпДчдЖДѓгкНХВПЕФГпДчЃЌЭМ2-1 (b)жаШЫЬхЭЗВПЕФГпДчдЖаЁгкНХВПЕФГпДчЁЃетЖдгкМьВтШЫЬхЙиМќЕуЕФФЃаЭРДЫЕЪЧвЛИіЬєеНЃЌШчЙћФЃаЭВЛФмбЇЯАЕНетаЉГпЖШВювьадЯТЕФИпЮГЖШвЛАуадОЭЮоЗЈзМШЗЕФЖЈЮЛЙиНкЕуЁЃетИіЮЪЬтВЛНіЛсгАЯьCNNЩюВуЕФгявхаХЯЂЃЌЖјЧввВЛсгАЯьCNNЧГВуЕФЭМЯёЬиеїЁЃ
2.2 ЛљДЁФЃаЭЁЊЁЊЖбЕўЩГТЉФЃаЭЕФЗжЮі
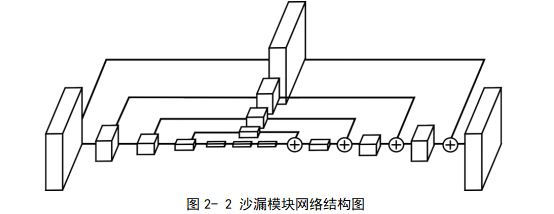
БОЮФдк1.2НкжаЬсЕНЃЌЪмResNetВаВюбЇЯАЫМЯыЕФЦєЗЂЃЌNewellЕШШЫгы2016ФъЬсГіСЫЖбЕўЩГТЉФЃаЭЃЈStacked HourglassЃЉЁЃЖбЕўЩГТЉФЃаЭЕФФПБъЪЧдкЭЦРэНзЖЮОЁСПдкЫљгаГпДчЕФЬиеїЭМЩЯВЖЛёаХЯЂЁЃЪзЯШЭЈЙ§ШєИЩИіГиЛЏВуКЭОэЛ§ВужДааЯТВЩбљЃЌВЂЭЈЙ§ЗДОэЛ§НјааЩЯВЩбљДІРэЁЃШЛКѓНЋетСНИіЙ§ГЬжаЯрЭЌГпДчЯрЭЌЕФЬиеїЭМЯрМгЃЌОЭЯёResNetжаЫљзіЕФЯрМгвЛбљЁЃжиИДетжжЁАЯШЯТКѓЩЯЁБДІРэРДНЈСЂЁАЖбЕўЩГТЉЁБЭјТчЃЌВЂдкУПИіЁАЩГТЉЁБКѓНјаажаМфМрЖНбЕСЗЁЃ
ИУФЃаЭдкЕБФъШЁЕУСЫзюКУЕФаЇЙћЃЌВЂЧвЦфНсЙЙЧхЮњЃЌНзЖЮЪНЕФЭјТчНсЙЙОпгаКмКУЕФПЩРЉеЙадЁЃЦфЛљДЁФЃПщЩГТЉФЃПщОпгаИпЖШЖдГЦадЃЌНсЙЙЧхЮњвзгкаоИФЁЃ2016ФъКѓаэЖрФЃаЭОљЪЧдкЦфЛљДЁЩЯНјаааоИФЕФНсЙћЁЃЫљвдБОЮФбЁШЁЖбЕўЩГТЉЭјТчЮЊЛљДЁЭјТчЃЌдкЦфЛљДЁЩЯНјааИФНјЁЃИУФЃаЭНЋЙсДЉБОЮФЕФЪМжеЃЌЯТУцЯъЯИНщЩмЦфЭјТчНсЙЙКЭбЕСЗЗНЗЈЁЃ
ЦфЭјТчНсЙЙШчЭМ1-11ЫљЪОЃЌЭМжаЕФУПИіЩГТЉаЮзДМДДњБэвЛИіЩГТЉФЃПщЁЃвЛИіЩГТЉФЃПщЕФЭјТчНсЙЙШчЭМ2-2ЫљЪОЃЌЦфжаУПвЛИіЗНПщДњБэСЫвЛИіВаВюФЃПщЃЌЗНПщЕФДѓаЁБэЪОЪфШыЬиеїЭМЕФГпДчЃЌВаВюФЃПщЭјТчНсЙЙШчЭМ2-3 (a)ЫљЪОЁЃ

ЩГТЉФЃПщОпгаЖдГЦадЃЌЪзЯШЪЧздЕзЯђЩЯЙ§ГЬНјааШєИЩДЮОэЛ§КЭзюДѓжЕГиЛЏВйзїЕУЕНзюаЁГпДчЕФЬиеїЭМЁЃдкУПДЮзюДѓжЕГиЛЏВйзїКѓЭјТчВњЩњвЛИіАќКЌШєИЩОэЛ§ЕФЗжжЇЃЌгУгкЯТвЛНзЖЮЕФЬиеїЭМШкКЯЁЃИУЗжжЇЕФЪфШыЪЧзюДѓжЕГиЛЏВйзїжЎЧАЕФЬиеїЭМЁЃЕУЕНзюаЁГпДчЭМКѓЃЌЭјТчПЊЪМНјааЕкЖўНзЖЮЕФздЖЅЯђЯТЙ§ГЬЃЌМДЩЯВЩбљКЭЬиеїШкКЯЙ§ГЬЁЃЩЯВЩбљЪЙгУЗДОэЛ§ВйзїЃЌНЋЩЯВЩбљКѓЕФЬиеїЭМгыЭјТчЗжжЇЩЯЭЌГпДчЕФЬиеїЭМНјаадЊЫиМЖЕФЯрМгЃЌЕУЕНШкКЯЕФЬиеїЭМЁЃВаВюФЃПщЪЙ1ЂЊ1КЭ3ЂЊ3ВНГЄЮЊ1ЕФОэЛ§ВуЃЌВЛИФБфЪфШыЬиеїЭМЕФГпДчЁЃЪфГіЬиеїЮГЖШКЭОэЛ§КЫДѓаЁШчЭМ2-3 (a)ЫљЪОЃЌЭМжаащЯпДњБэЬјВуСЌНгЁЃ
ЭМ2-3 (b)БэЪОЕФЪЧжаМфМрЖНЙ§ГЬЃЌЭМжаащЯпЪЧЬјВуСЌНгЃЌЩГТЉЭМаЮДњБэвЛИіЩГТЉФЃПщЃЌЭМжаРЖЩЋЕФЗНПщДњБэЩњГЩЕФHeatMapЃЌгУЦфгыground truthМЦЫуЗЖЪ§Ы№ЪЇЁЃЪЙгУ1ЂЊ1ЕФОэЛ§НЋHeatMapжиаТБфЮЊгыЬиеїгыЯрЭЌЕФЭЈЕРЪ§ВЂЧвЯрМгЪфШыЕНЯТвЛИіЩГТЉФЃПщЁЃ
дкзїепЕФЪЕЯжжаЃЌЪфШыЭМЦЌБЛВУМєКЭЫѕЗХГЩ256ЂЊ256ЕФЗжБцТЪЁЃЭМЦЌЪзЯШНјШывЛИіВНГЄЮЊ2ОэЛ§КЫДѓаЁЮЊ7ЕФОэЛ§ВуЃЌЫцКѓСЌНгвЛИіВаВюФЃПщКЭвЛИізюДѓжЕГиЛЏВуНЋЬиеїЭМЗжБцТЪНЕЕН64ЂЊ64ЁЃЫцКѓСЌНгШєИЩИіЩГТЉФЃПщЃЌУПИіЩГТЉФЃПщНјаажаМфМрЖНбЕСЗЁЃЫљгаЩГТЉФЃПщФкВПзюаЁЬиеїЭМГпДчЮЊ4ЂЊ4ЃЌЫљгаВаВюФЃПщЩњГЩЕФЬиеїЭМЭЈЕРЪ§ОљЮЊ256ЁЃ







ЗжЯэШУИќЖрШЫПДЕН 
ЭЦМідФЖС
ДЋУНЭЦМі
 @УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад
@УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ
ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
ЯрЙиаТЮХ
- ФъЕзЧАЫљгаЖўМЖзлКЯвНдКОпБИКЫЫсВЩбљКЭМьВтФмСІ
- ГжајНєЖЂетаЉЙиМќЕуЙиНкЕуЃЁРюЧПжїГжСьЕМаЁзщЛсвщбаХаГЃЬЌЛЏОЋзМЗРПи
- ЭјЙКгаОЊЯВЃЁгЂЙњИИЧзТђПжСњФЃаЭЫЭЖљзг ЫСЯОЙга6УзГЄ
- здЖЏИњзйВЂЛцжЦдЫЖЏЙьМЃ жЧЛлБљГЁЯЕЭГНёФъЖЌбЕЭЖгУ
- ИјCTМгЕубеЩЋ аТШэМўгажњОЋЯИГЪЯжШЫЬхЭМЯё
- ШЫЬхЯИАћжЦГЩПЩеЃблШ§ЮЌШЫблФЃаЭ
- БЧЮЦЪЖБ№ШУГшЮягЕгазЈЪєЩэЗнжЄ
- ББОЉКЃЕэЃКдЫгУШЫЬхЖЏЬЌЬиеїЪЖБ№ММЪѕЫјЖЈБЛИцШЫ
- НіЦОвЛеХееЦЌОЭФмЩњГЩ3DШЫЬхФЃаЭ
- ЛљгкЩчЛсЭјТчЕФНкЕугАЯьСІЖШСПФЃаЭбаОП
ПЭЛЇЖЫЯТди
ШЫУёШеБЈЩчИХПі | ЙигкШЫУёЭј | БЈЩчеаЦИ | еаЦИгЂВХ | ЙуИцЗўЮё | КЯзїМгУЫ | ЙЉИхЗўЮё | Ъ§ОнЗўЮё | ЭјеОЩљУї | ЭјеОТЩЪІ | аХЯЂБЃЛЄ | СЊЯЕЮвУЧ
ЗўЮёгЪЯфЃКkf@people.cn ЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-65363263 ОйБЈгЪЯфЃКjubao@people.cn
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170001 | діжЕЕчаХвЕЮёОгЊаэПЩжЄB1-20060139
ЙуВЅЕчЪгНкФПжЦзїОгЊаэПЩжЄЃЈЙуУНЃЉзжЕк172КХ | ЛЅСЊЭјвЉЦЗаХЯЂЗўЮёзЪИёжЄЪщЃЈОЉЃЉ-ЗЧОгЊад-2016-0098
аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0104065 | ЭјТчЮФЛЏОгЊаэПЩжЄ ОЉЭјЮФ[2020]5494-1075КХ | ЭјТчГіАцЗўЮёаэПЩжЄЃЈОЉЃЉзж121КХ | ОЉICPжЄ000006КХ | ОЉЙЋЭјАВБИ11000002000008КХ
ШЫ Уё Эј Ац ШЈ Ыљ га ЃЌЮД О Ъщ Уц Ък ШЈ Нћ жЙ ЪЙ гУ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЦРТл

-
ЙизЂ
ЮЂаХЮЂВЉПьЪж
 ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
 БЈЕРШЋЧђ ДЋВЅжаЙњ
БЈЕРШЋЧђ ДЋВЅжаЙњ
 ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
