




















ЛЅСЊЭјаТЮХБъЬтЩњГЩЗНЗЈбаОП
еЊвЊЃК
НќФъРДЃЌЭјТчаТЮХЕФЁАе№ОЊЬхЁБЮФВЛЖдЬтЯжЯѓВуГіВЛЧюЃЌЮЊБЃжЄИќМгИпаЇзМШЗЕФаХЯЂМьЫїМАгУЛЇЬхбщЃЌБОЮФЬНЬжЭМНсЙЙЁЂБрНтТыЦїЁЂзЂвтСІЛњжЦЯТБрНтТыЦївдМАжИеыЩњГЩЦїЫФжжЗНЗЈгІгУгкаТЮХБъЬтЩњГЩШЮЮёжаЕФПЩааадЁЃжИеыЩњГЩЦїФЃаЭИљОндЮФДЪЯШбщЗжВМГщШЁМАИпЮЌгявхаХЯЂЩњГЩСНжжЗНЪНСЊКЯЫљЩњГЩЕФаТЮХБъЬтдкгявхЩЯНЯЮЊЭъећЃЌБэДяНЯЮЊзМШЗЁЃ
ЙиМќДЪЃКЁАе№ОЊЬхЁБЃЌздШЛгябдЩњГЩЁЂаТЮХБъЬтЁЂБрНтТыЦї
вЛЁЂв§бд
ЫцзХweb2.0ЕФПьЫйЗЂеЙЃЌвдШЫУёЭјЁЂЮЂаХЁЂЮЂВЉЮЊДњБэЕФаТаЫУНЬхМгЫйсШЦ№ЁЃДЫЧАЃЌЙњМваТЮХГіАцЙуЕчзмОжгЁЗЂЕФЁЖЙигкНјвЛВНМгПьЙуВЅЕчЪгУНЬхгыаТаЫУНЬхШкКЯЗЂеЙЕФвтМћЁЗЬсГівЊДѓСІЭЦЙуДЋЭГЙуЕчУНЬхгыаТаЫЛЅСЊЭјУНЬхЩюЖШШкКЯЁЂвЛЬхЙВЩњЁЃдкетбљЕФЪБДњБГОАКЭеўВпЕМЯђв§ЕМЯТЃЌШЫУЧЗЂВМКЭЛёШЁаТЮХФкШнЕФЭООЖЗЂЩњСЫЬьЗЕиИВЕФБфЛЏЃЌж№НЅгЩДЋЭГУНЬхзЊЯђЭјТчаТаЫУНЬхЁЃЭЌЪБДѓСПЕФаТаЫУНЬхЕФЦеМАвВв§ЗЂСЫЛЅСЊЭјУНЬхЩЯЕФаТЮХФкШнБЌеЈЪНдіГЄЁЃ
ШЫУёЭјзїЮЊЪРНчЪЎДѓБЈжНжЎвЛЁЖШЫУёШеБЈЁЗНЈЩшЕФвдаТЮХЮЊжїЕФДѓаЭЭјЩЯаХЯЂЗЂВМЦНЬЈЃЌУПШеЪеИхСПОоДѓЁЃШЛЖјЃЌетаЉИхМўаТЮХФкШнжЪСПСМнЌВЛЦыЃЌЦфжаВЛЗІвЛаЉбЁШЁЛЊРіБъЬтШДШБЗІЪЕжЪФкШнЕФЁАБъЬтЕГЁБЮФеТРЫЗбСЫЩѓИхШЫдБДѓСПЕФЪБМфОЋСІЃЌШчКЮПьЫйЕФЛёШЁЮФеТЕФецЪЕжїжМГЩЮЊСЫЩѓИхШЫдБЕФживЊФмСІЁЃГ§СЫШЫЙЄЕФМгЧПЩѓИхФмСІЭтЃЌШЫЙЄжЧФмММЪѕЃЌгШЦфЪЧздШЛгябдДІРэММЪѕНЋМЋДѓЕФжњСІаТЮХжїжММьЫїЁЃБОЮФЬжТлЭЈЙ§БъЬтдйЩњГЩЕФЗНЗЈЃЌЩњГЩзюЬљЧааТЮХЮФеТФкШнЕФаТЮХБъЬтЃЌЮДРДЯЃЭћЭЈЙ§ДЫЗНЗЈРДМѕЩйШЫЙЄХХВщЁАБъЬтЕГЁБЕФЪБМфЁЃ
ФПЧАЕФаТЮХМьЫїДѓЖрВЩгУЫбЫїв§ЧцМгЙиМќзжШЈжиЕФЗНЗЈЃЌКіТдСЫЮФеТЕФФкКЁЃвђДЫЃЌШчКЮИљОнаТЮХФкШнЩњГЩбдМђвтърЕФаТЮХБъЬтЪЧвЛЯюОпгаЬєеНадЕФбаОППЮЬтЁЃНќФъРДЃЌЫцзХЙњФкЭтбЇепдкздШЛгябдДІРэСьгђЕФВЛЖЯЩюШыбаОПЃЌЯрЙиРэТлЬхЯЕКЭЪЕзїЗНЗЈТлЕФВЛЖЯНјВНЃЌЪЙЕУЖдЮФБОЕФжЧФмРэНтКЭЭкОђММЪѕгњМгГЩЪьЁЃЮФБОеЊвЊОЭЪЧвЛРрдЫгУздШЛгявхДІРэЗНЗЈЃЌАяжњЛњЦїРэНтШпГЄздШЛгябдЮФБОФкШнЃЌВЂЩњГЩвЛаЉМђЖЬЁЂОЋСЖИпЖШИХРЈЮФБОФкКЕФОфзгЕФММЪѕЁЃГ§СЫжБНгГЪЯжЮФБОеЊвЊНсЙћИјгУЛЇдФЖСЭтЃЌЮФБОеЊвЊММЪѕЛЙдкКмЖрЯТгЮШЮЮёжаГфЕБзХживЊНЧЩЋЃЌШчГЄЮФБОЧщИаЗжЮіЁЂЫбЫїв§ЧцЁЂЭЦМіЯЕЭГЕШЁЃЯрБШгкжБНгЪЙгУдЮФЃЌЪЙгУКУЕФеЊвЊФмЙЛдкЬсЩ§адФмЕФЭЌЪБгжОЁЩйЕФдьГЩаХЯЂЫ№ЪЇЁЃаТЮХБъЬтЩњГЩПЩвдПДГЩЮФБОеЊвЊММЪѕЕФвЛжжгІгУГЁОАЁЃгЩгкаТЮХНсЙЙЕФЬиЕуЁЂБъЬтвЛАуЖјбдЖМЪЧЗЧГЃМђСЗЁЂЩѕжСгаЕуГщЯѓЁЂИпЖШИХРЈЮФеТФкШнЕФОфзгЁЃЮФБОеЊвЊММЪѕзїЮЊвЛжжживЊЕФздШЛгябдДІРэММЪѕЃЌЖдгкПьЫйЛёШЁКЭИќКУеЙЪОаТЮХФкШнОпгаживЊЕФвтвхЃЌетвВЪЧБОЮФЕФбаОПвтвхЫљдкЁЃ
ЖўЁЂбаОПЯжзД
ЫцзХздШЛгябдДІРэММЪѕЕФНјВНЃЌдНРДдНЖрЕФбаОПдкздШЛгябдЩњГЩШЮЮёЃЈNLGЃЉЩЯШЁЕУСЫУїЯдНјВНЁЃИљОнЪфШыаХЯЂЕФВЛЭЌЃЌNLGПЩЗжЮЊЃКЪ§ОнЕНЮФБОЕФЩњГЩЁЂЮФБОЕНЮФБОЕФЩњГЩЁЂвтвхЕНЮФБОЕФЩњГЩЁЂЭМЯёЕНЮФБОЕФЩњГЩЕШЁЃ вђБОЮФвтдкЬжТлИљОнаТЮХЮФБОЩњГЩаТЮХБъЬтЕФNLGММЪѕЃЌЪєгкЁАЮФБО-ЮФБОЁБЩњГЩЃЌЙЪЯТЮФзХжиЬжТлДЫММЪѕЯрЙиЗНЗЈЁЃЮФБО-ЮФБОЩњГЩММЪѕгУгкжЧФмСФЬьЁЂЮФеТздЖЏеЊвЊЁЂЮФеТздЖЏЩњГЩБъЬтЕШЮЪЬтЖМгазХЙуРЋЧАОАЁЃНќФъРДЃЌаэЖргХауЕФбаОПзХСІгкЬсЩ§ЮФБОЩњГЩЕФзМШЗЁЂСїГЉГЬЖШЁЃЮФеТБъЬтЪЧОЋСЖЕФЮФеТФкШнЃЌЦфЪЙгУзюМђЖЬЕФгябдзюДѓЯоЖШЕФЗДгІЮФеТЕФжївЊФкШнЁЃБъЬтздЖЏЩњГЩЫуЗЈИљОнЦфбЁдёЁЂзщжЏгябдЕФЗНЪНПЩЗжЮЊГщШЁЪНЗНЗЈКЭЩњГЩЪНЗНЗЈЁЃ
ГщШЁЪНЗНЗЈвРОнЮФБОЕФЭГМЦаХЯЂЬсШЁЙиМќЕФДЪЁЂОфЕФХХађВЂжиаТзщКЯГЩЮЊБъЬтЃЌLuhn[1]ЪЧзюдчЪЙгУжїЬтДЪЗЈЕФбаОПдБжЎвЛЃЌЫћУЧЪЙгУЦЕТЪуажЕРДЖЈЮЛЮФЕЕжаЕФУшЪіадДЪгяВЂБэЪОЮФЕЕжїЬтЁЃDunning[2]ЬсГіСЫвЛИіИќИпМЖЕФИХФюЃЌЫћУЧЪЙгУЖдЪ§ЫЦШЛБШМьбщРДЪЖБ№НтЪЭадДЪгяЃЌдкзмНсЮФЯзжаГЦжЎЮЊЁАжїЬтЧЉУћЁБЁЃРћгУжїЬтЧЉУћДЪзїЮЊжїЬтБэЪОЗЧГЃгааЇЃЌЬсИпСЫаТЮХСьгђЖрЮФЕЕеЊвЊЕФзМШЗад[3]ЁЃVanderwendeЕШШЫ[4]ЬсГівЛИіУћЮЊsumbaicЕФЯЕЭГЃЌИУЯЕЭГНіЪЙгУЕЅДЪИХТЪШЈжиЕФж№ВНЕќДњЗНЗЈРДШЗЖЈОфзгЕФживЊадЃЌНјЖјЩњГЩБъЬтЁЃTFIDFШЈжидкЕЅДЪИХТЪЛљДЁЩЯНјааИФНјЃЌРћгУДЪЦЕКЭЗДзЊДЪЯђСПМЦЫуживЊадЃЌОпгаМЦЫуМђЕЅЁЂПьЫйЕФгХЕуЁЃЙЄзї[5-7]ЕФЙВзщЛљгкетжжЗНЗЈШЁЕУСЫВЛДэЕФаЇЙћЁЃGongЕШ[8]ЬсГіСЫвЛжжЛљгкlsaЕФаТЮХСьгђЕЅЮФЕЕКЭЖрЮФЕЕеЊвЊИпХХУћОфзгбЁдёЗНЗЈЃЌИУЗНЗЈЖдУПИіжїЬтЖМбЁШЁвЛИізюИпЕУЗжЕФОфзгЃЌзюКѓИљОнЫљашвЊЩњГЩЕФЯоЖЈГЄЖШБЃСєжїЬтЕФЪ§СПЁЃHenningЕШШЫ[9] ЬсГівЛжжНЋОфзггГЩфЕНБОЬхИХФюЕФОфзгЬсШЁЗНЗЈЁЃЭЈЙ§ПМТЧБОЬхЬиеїЃЌПЩвдЬсИпОфзгЕФгявхБэДяЃЌгаРћгкзмНсОфзгЕФбЁдёЁЃ
ЩњГЩЪНЗНЗЈдђЪЧЭЈЙ§ЖдШЋЮФЕФгявхЗжЮіЃЌОгЩЬиеїБфЛЛЕУЕНДЪЁЂОфЁЂЖЮЕФИпЮЌБэЪОЃЌНјЖјвРОнгявхЩњГЩЯргІЕФБъЬтЃЌЧјБ№гкГщШЁЪНЗНЗЈЃЌЩњГЩЪНЗНЗЈЖдБъЬтЕФбЁДЪПЩФмЪЧЮФеТжаДгЮДГіЯжЙ§ЕФаТДЪЁЃЦфжаДЋЭГЫуЗЈЃЌАќРЈЛљгкЪїНсЙЙЁЂЛљгкФЃАхЁЂЛљгкгявхЁЂЛљгкЭМЕШЕФЗНЗЈЖМШЁЕУСЫНЯКУЕФНсЙћЁЃдкЛљгкЪїНсЙЙЗНЗЈПђМмжаЃЌЫуЗЈИљОнШчЮНДЪ-ТлОнНсЙЙ[10]ЁЂвРРЕЪї[11]ЕШЗНЪНЬсШЁеЊвЊвЊПМТЧЕФживЊЮФБОЁЃШЛКѓЃЌЪЙгУЧГВуНтЮіЦїДгЮФБОжаЪЖБ№ГіЯрЫЦЕФОфзгЁЃРрЫЦЕФОфзгБЛЬюГфЕНЪїзДНсЙЙжаЁЃдкЛљгкФЃАхЕФЗНЗЈжаЃЌвРРЕгкЮФБОЩюВуЕФОфЗЈКЭгявхЗжЮі[12]ЃЌЪЙгУдЄЖЈвхЕФФЃАхНсЙЙгажњгкДДНЈМђНрЁЂСЌЙсЕФеЊвЊЁЃЕЋЪЧЃЌгЩгкЙцдђКЭФЃЪНЪЧЪжЖЏЖЈвхЕФЃЌвђДЫетРрЗНЗЈЗЧГЃКФЪБЃЌЛЙашвЊДѓСПЪжЖЏВйзї[13]ЁЃЛљгкгявхЕФздШЛгябдЩњГЩЗНЗЈЪзЯШЭЈЙ§ВщеваХЯЂЯюЁЂЮНДЪВЮЪ§НсЙЙЛђДДНЈгявхЭМРДЛёЕУЮФБОЕФгявхБэЪОЁЃЭЈЙ§БрМЮНДЪ-ТлОнОрРыЖШСПЕШЯрЫЦадЖШСПДгжаЗЂЯжгявхЯрЫЦЕФНсЙЙЃЌВЂЭЈЙ§k-ОљжЕЛђВуДЮОлРрЕШЗНЗЈНЋгявхЯрЫЦЕФНсЙЙКЯВЂдквЛЦ№[14]ЁЃШЛКѓЃЌНЋДЫБэЪОаЮЪНЪфШыздШЛгябдЩњГЩЯЕЭГЁЃЛљгкгявхЭМЕФЗНЗЈЭЈЙ§АбЮФБОЗжИюГЩШєИЩзщГЩЕЅдЊ(ШчЕЅДЪЁЂОфзгЕШ)ВЂНЈСЂЭМЃЈНкЕу-БпЃЉФЃаЭ, РћгУЭЖЦБЛњжЦЖдЮФБОжаЕФживЊГЩЗжНјааХХађ, НіРћгУЕЅЦЊЮФЕЕБОЩэЕФаХЯЂМДПЩЪЕЯжЙиМќДЪЕФЬсШЁЁЂЮФеЊЁЃЫцзХЩюЖШбЇЯАЕФаЫЦ№ЃЌвдSequence-to-sequenceЩёОЭјТчНсЙЙЮЊПђМмЕФЩюЖШбЇЯАФЃаЭПЊЪМдкЮФеТБъЬтЁЂЮФеТеЊвЊЕШЗНЯђеИТЖЭЗНЧЁЃChopra[15]ЕШШЫЪЙгУRNNМАЦфБфжжLSTMЙЙГЩБрТыЦї-НтТыЦїНсЙЙРДЩњГЩЮФеТзмНсЃЌJobson[16]ЕШШЫЃЌдкЪЙгУБр-НтТыЦїНсЙЙЕФЭЌЪБРћгУзЂвтСІЛњжЦЬсШЁживЊДЪЃЌШЁЕУСЫИќгХауЕФНсЙћЁЃSong[17]ЕШШЫвдЖЬгяЬцДњЕЅДЪзїЮЊЪфШыЃЌОгЩLSTMзщГЩЕФБрНтТыНсЙЙРДЩњГЩЮФеТМђНщ.Abigail[18]ЕШШЫдкНтТыЦїЖЫНјааСЫИФНјЬсГіСЫpointer-generaerЭјТчЃЌЭЈЙ§жИеыДгдДЮФБОИДжЦЕЅДЪЃЌЬсИпСЫOOVЕЅДЪЕФзМШЗадКЭДІРэФмСІЃЌЭЌЪББЃСєСЫВњЩњаТДЪЕФФмСІЁЃ
Ш§ЁЂЯрЙиФЃаЭ
3.1ЁЂ ЛљгкЭММЦЫуЕФздШЛгябдЩњГЩЗНЗЈ
TextRank ПЩвдБэЪОЮЊвЛИігаЯђгаШЈЭМ G =(V, E)ЁЃИУЭМгЩЕуМЏКЯ VКЭБпМЏКЯ E зщГЩЃЌЦфжаЃЌE ЪЧV ЁС VЕФзгМЏЃЌЭМжаШЮвтСНЕу Vi , Vj жЎМфБпЕФШЈжиЮЊ wji ЁЃ ЖдгкШЮвтвЛИіИјЖЈЕу Vi ЃЌIn(Vi) ЮЊ жИ Яђ ИУ Еу ЕФ Еу МЏ КЯ , Out(Vi) ЮЊЕу Vi жИЯђЕФЕуМЏКЯЁЃЕу Vi ЕФЕУЗжЖЈвхШчЯТ:
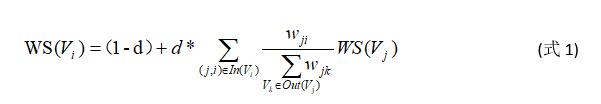
Цфжа, d ЮЊзшФсЯЕЪ§, ШЁжЕЗЖЮЇЮЊ 0 ЕН 1, ДњБэДгЭМжаФГвЛЬиЖЈЕужИЯђЦфЫћШЮвтЕуЕФИХТЪЁЃЪЙгУTextRank ЫуЗЈНјааЭММЦЫуЪБЃЌЖдЭМжаЕФНкЕуЕУЗжНјааЫцЛњГѕЪМЛЏЃЌВЂЕнЙщМЦЫужБЕНЪеСВ(ЭМжаШЮвтвЛЕуЕФЮѓВюТЪаЁгкИјЖЈЕФуажЕЃЉ
3.2ЛљгкЩюЖШбЇЯАЕФздШЛгябдЩњГЩЗНЗЈ
(1) БрТы-НтТыЦїЃЈencoder-decoderЃЉНщЩм:
encoder-decoderЪЧвЛжжОЕфЕФseq2seqНсЙЙЁЃЫќФмЙЛЪЕЯжНЋвЛИіађСазЊЛЛЕНСэвЛИіађСаЃЌВЂЧвВЛвЊЧѓзЊЛЛЕФСНИіађСаЕШГЄЃЌЪЎЗжЪЪКЯЮФБОеЊвЊШЮЮёЁЃЖјРрЫЦздШЛгябдЮФБОетжжађСаЪ§ОнЖМДцдкетЪБађЙиЯЕЃЌвђДЫseq2seqГЃГЃЪЙгУLSTMЃЌGRUетжжФмЙЛгааЇЛКНтЬнЖШЯћЪЇЮЪЬтЕФЩёОЭјТЗНсЙЙРДНЈФЃЁЃОпЬхЭјТчНсЙЙШчЭМ1ЫљЪОЃК
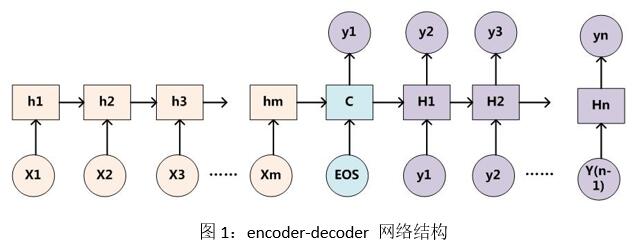
дкетЗљЭМжаЃЌencoderЖЫНгЪеЮФБОађСа[x1:xm]ЕФДЪЯђСПБэЪОзїЮЊЪфШыЃЌДЪЯђСППЩвдгЩword2vecЁЂgloveЁЂBERTЕШгябдФЃаЭбЕСЗЕУЕНЁЃencoderЖЫАбЮФБОФкШнБрТыГЩвЛИіЙЬЖЈДѓаЁЕФРэТлЩЯАќКЌШЋЮФаХЯЂЕФвўВуЯђСПCЃЌCЕФМЦЫуЙЋЪНШчЪН2ЫљЪОЁЃ

вЊевЕНзюгХзюДѓИХТЪЕФеЊвЊађСаYЃЌгаСНжжЗНЗЈПЩвдбЁдёЃЌвЛжжЪНЛљгкЬАаФЫбЫїЫуЗЈЃЌМДдкУПвЛВНЖМбЁШЁИХТЪзюДѓЕФЕЅДЪзїЮЊЪфГіЁЃетЪЧвЛжжзюЕЭГЩБОЕФЗНЗЈЃЌЕЋЪЧетжжЗНАИЕУГіЕФНсЙћЮДБиЪЧзюгХЕФЁЃвђЮЊЕБЧАЪБМфВНЕФНтТыЪфГіЛсгАЯьжЎКѓЕФНтТыЪфГіЁЃРлМЦГЫЛ§ПЩФмВЂЗЧзюИпЁЃСэвЛжжЗНЗЈдђЪЧУЖОйЫљгаЪфГіађСаВЂМЦЫуЕУЗжЃЌетжжЗНЗЈвЛЖЈФмевЕНШЋОжзюгХНтЃЌЕЋЪЧЪБМфИДдгЖШКЭПеМфИДдгЖШЙ§ИпЃЌЪЕгУадВЛЧПЁЃвђДЫSeq2SeqЪЙгУСЫвЛжжетжжЕФЗНЗЈbeam searchЁЃетжжЗНЗЈЪЧЬАаФЫбЫїКЭБЉСІУЖОйЕФетжжЗНАИЁЃдкУПИіЪБМфВНФкБЃСєtopkИізюгХКђбЁНсЙћЃЌЫќБОжЪЛЙЪЧЪєгкЬАаФЫуЗЈЕФЗЖГыЃЌжЛВЛЙ§дкЬАаФЕФЙ§ГЬжаБЃСєСЫИќЖрПЩФмЁЃ
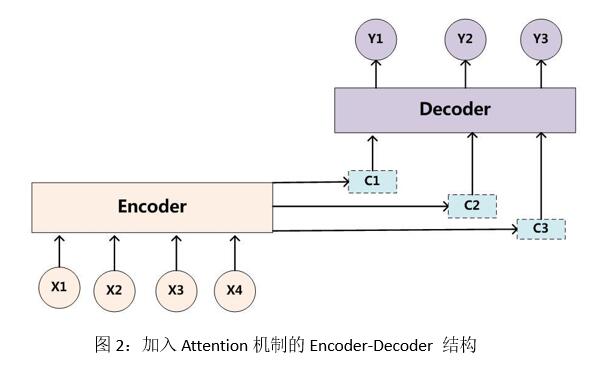
ЃЈ2ЃЉзЂвтСІЛњжЦЯТЕјЕФБрТыНтТыЦїНсЙЙЃЈAttention based encoder-decoderЃЉ
ЕЅДПЕФБр-НтТыЦїНсЙЙгавЛИіЯджјЕФШБЕуЃЌОЭЪЧећИіБрТы-НтТыЙ§ГЬЙВЯэвЛИіЕЅЖРВЛБфЕФгявхБрТыCЃЌЖдгкВЛЭЌЕФЩњГЩДЪЖМЪЙгУЭЌвЛИіCдьГЩЕФНсЙћОЭЪЧФЃаЭВЛЛсИљОнЕБЧАЩњГЩДЪЮЛжУЕФВЛЭЌЖјВЩШЁВЛЭЌЕФВЩбљЗНЪНЁЃЖјAttentionЛњжЦдкећКЯencoder-RNNВЛЭЌЪБМфВНЩњГЩencoderЕФвўВизДЬЌЕФађСаЪБЃЌЪфГіНтТыЕФзДЬЌStЁЃМАЯргІattentionШЈжиІСЁЃ

жСДЫЃЌЫуЗЈПЩДяЕНЪеСВЁЃЦфФЃаЭНсЙЙШчЭМ2ЫљЪОЃК
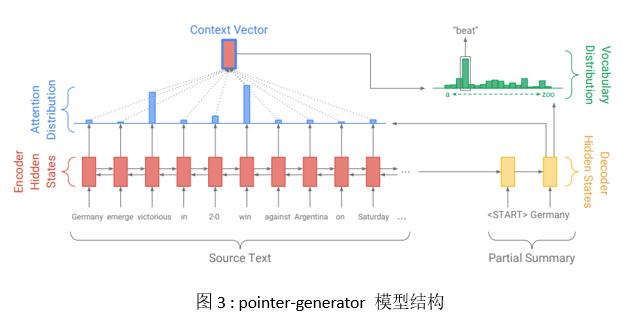
(3) pointer-generator
ДЋЭГЕФSeq2seqдкЩњГЩеЊвЊЕФУПвЛИіЕЅДЪЪБЃЌЭЈЙ§вЛИіsoftmaxВуМЦЫуДЪЛуБэжаУПвЛИіЕЅДЪЕФЕУЗжЁЃМДЩњГЩЕФеЊвЊвЛЖЈЪЧРДздгкДЪБэРяУцгаЕФЕЅДЪЃЌЖјдкФЃаЭбЕСЗжЎЧАЃЌетИіДЪБэвбОЪЧШЗЖЈСЫЕФЁЃвђДЫбЕСЗГіРДЕФФЃаЭдкЮФжагіЕНДЪБэжаУЛгаЕФДЪШДгжЪЧЗЧГЃЙиМќЕФЯИНкДЪЪБЛсГіЯжЯИНкБэЪіВЛЧхЕФЮЪЬтЁЃетвВОЭЪЧМЏЭтДЪЃЈOOVЃЉЮЪЬтЁЃДЫЭтЃЌгЩгкНтТыЪБжЛПДМћЧАвЛИіЪБПЬЕФНтТыГіРДЕФЕЅДЪЃЌвђДЫЗЧГЃШнвзЩњГЩжиИДЕФеЊвЊЦЌЖЮЁЃеыЖдДЋЭГЮФБОеЊвЊФЃаЭДцдкЕФетСНИіЮЪЬтЃЌAbigail SeeЕШЛљгкДЋЭГЕФattention-based encoder-decoderФЃаЭНсЙЙзіСЫаоИФЬсГіСЫpointer-generatorФЃаЭЃЈвдЯТМђГЦPGФЃаЭЃЉЁЃвЛЗНУцЃЌPGФЃаЭв§ШыpointerжИеыРДАДвЛЖЈИХТЪДгдЮФжаИДжЦФГаЉЕЅДЪзїЮЊеЊвЊЁЃСэвЛЗНУцЃЌв§ШыcoverageЛњжЦЃЌдкЩњГЩДЪЪБЃЌдіМгЖдУПИіДЪРњЪЗРлМЦattentionЕУЗжЕФГЭЗЃЁЃзїепШЯЮЊжЎЧАГіЯжЙ§ДЪдкеЊвЊжадйДЮСЌајГіЯжЕФИХТЪгІИУвЊНЕЕЭЁЃPGЕФФЃаЭНсЙЙШчЭМ3ЫљЪОЃК

ЫФЁЂЪЕбщЗНЗЈ
БОЮФЛљгкЛЅСЊЭјЩЯЙЋПЊЕФБъзМаТЮХЪ§ОнЁЃЭЈЙ§РћгУЩЯЪібаОПЕФЮФБОеЊвЊФЃаЭЃЌНјаажЧФмЛЅСЊЭјаТЮХБъЬтЩњГЩЪЕбщЃЌЮЊаТЮХФкШнЕФПьЫйЛёШЁКЭгааЇеЙЪОЬсЙЉПЩааЕФЗНАИЁЃ
4.1 Ъ§ОнМЏЙЙНЈ
ЮвУЧЪЙгУЙЋПЊЪ§ОнМЏION dataset[19]ЃЌгЩгкIONЪ§ОнМЏдЮФВПЗжЪЙгУдЮФurlСДНгЖјЗЧдЮФЮФБОЃЌЮвУЧзёЪиurlСДНгЭјеОrobotsавщХРШЁСЫЯрЖдгІЕФЮФБОЁЃаТЮХЮФеТ-БъЬтЙВМЦ66518ЬѕЃЌИёЪНШчБэ1жаЫљЪОЃК

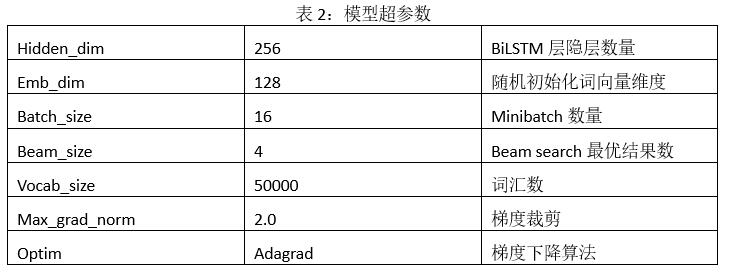
4.2 Ъ§ОнДІРэ
Ъ§ОндЄДІРэЪЧЛњЦїбЇЯАСьгђЯрЙиЙЄзїБиВЛПЩЩйЕФЛЗНкжЎвЛЃЌдкЮФБОЪ§ОндЄДІРэжаЃЌжївЊЙЄзїЪЧЯћГ§ЮовтвхЕФЬиЪтзжЗћЁЂГЃМћЕФЮовтвхЛђЧЗвтвхЕФДЪЃЈa, the ЕШЃЉвдМАЗжДЪРДНЕЕЭЪ§ОнжаЕФдыЩљвдДяЕНзюгХЕФФЃаЭаЇЙћЁЃдкБОЮФЙЄзїжаЃЌвђЮФБОжївЊЭЈЙ§ХРГцХРШЁЃЌЦфжаАќКЌгааэЖрHTMLвГУцжаЕФБъМЧЗћКХвдМАБэЧщЗћКХЃЌЮвУЧЪЙгУе§дђЦЅХфЕФЗНЪННјааСЫдыЩљЙ§ТЫЁЃЗжДЪдкжаЮФСьгђЪЧЗЧГЃживЊЕФЛЗНкЃЌЕЋгЩгкБОЮФЪЙгУгЂЮФЙЋПЊЪ§ОнМЏЃЌгЂЮФЕЅДЪгЩПеИёЧаЗжЃЌЮоашНјвЛВНЩшМЦЗжДЪЫуЗЈЁЃ
зюДѓНиЖЯОфГЄЪЧNLPШЮЮёжаЮЊСЫБЃжЄЪфШыЕФХњДЮЪ§ОнвЛжТадЖјВњЩњЕФГЌВЮЪ§жЎвЛЃЌМДЩшЖЈзюДѓНиЖЯОфГЄКѓЃЌЫљгаЮФБОжаДѓгкНиЖЯОфГЄЕФВПЗжашвЊЩсЦњЁЃдкБОЮФбЁгУЕФЪ§ОнМЏжаЃЌЮФеТЦЊЗљЦЋГЄЃЈ2000-3000зжзѓгвЃЌШчЭМ4ЫљЪОЃЉ,ЗНВюЦЋДѓЃЈзюДѓжЕ30000зжЃЉЁЃдкЩюЖШбЇЯАЫуЗЈЕФФЃаЭЪфШыЪ§ОнжаЃЌХњСПЕФНсЙЙЛЏЪ§ОнвдОиеѓЕФаЮЪНЪфШыЕНФЃаЭжаЃЌУПвЛХњДЮжаЕФИїЬѕЪ§ОнБиаыЗћКЯЯрЭЌЕФаЮзДЃЈshapeЃЉВХФмЙЛМЏЬхдМЪјФЃаЭЪеСВЁЃЫљвдКЯРэЕФзюДѓНиЖЯОфГЄЗжЮіЪЧБиВЛПЩЩйЕФЃЌЭМ4жаеЙЪОСЫвдвЛИіЕЅДЪЮЊ1ЕЅЮЛМЦЫуЕФЮФеТГЄЖШКЭБъЬтГЄЖШЕФЖдБШЗжЮіЃЌвдИВИЧ95%ЕФНиЖЯВпТдРДЫЕЃЌзюМбНзЖЮГЄЖШгІдк5000ИННќЃЌЕЋПМТЧЕНаТЮХЮФБОЕФЬиЪтад--аТЮХЮФБОЦеБщдкЮФеТПЊЭЗВПЗжжБШыжїЬтЃЌЮвУЧЖдзюДѓГЄЖШЕФНиЖЯВпТдНјааСЫБфЛЏЃЌбЁдёвдЦНОљжЕИННќЕФОфГЄРДНјааНиЖЯЃЌЦфжаЃЌЮФеТзюДѓГЄЖШЮЊ2000, БъЬтзюДѓГЄЖШЮЊ25ЁЃ

ЮФБОЯђСПЛЏЗНЗЈНЋЮФБОаЮЪНЕФЪ§ОнзЊЛЛГЩОпгагявхаХЯЂЕФЯђСПаЮЪНгУвдНјааНЈФЃМЦЫуЃЌгаone-hotЁЂtf-idfжЕЁЂword2vecЫуЗЈЁЂgloveЫуЗЈЕШНјааБрТыЕФЗНЪНЁЃЕЋЪЧЃЌOne-hotБрТыВЩгУДЪДќФЃаЭЃЌВЛПМТЧДЪгыДЪжЎМфЕФЫГађЃЌВЂМйЩшДЪгыДЪЯрЛЅЖРСЂЃЌЫ№ЪЇСЫВПЗжгявхаХЯЂЃЌЛЙЛсЕУЕНвЛИіРыЩЂЯЁЪшЕФЬиеїОиеѓЃЌЪЎЗжРЫЗбФкДцЃЌtf-idf, word2vec,gloveЫуЗЈЖМПЪЭћЭЈЙ§ЩшМЦвЛЬзЫуЗЈРДЕнЙщЕФМЦЫуГізюФмДњБэДЪЕФЯђСПЃЌЕЋШЫЮЊЩшМЦЕФЫуЗЈМЦЫуГіЕФЯђСПНсЙћБэЪОФмСІЪмЯогкЫуЗЈдРэЃЌЙЪдкБОЮФжаЃЌЮвУЧВЩгУдкФЃаЭжаЩшжУПЩбЕСЗЕФЁЂЫцЛњГѕЪМЛЏВЮЪ§ЕФДЪЧЖШыВуЕФЗНЪНЃЌРћгУФЃаЭздЖЏбЕСЗГівЛИіОпгазюМбБэЪОФмСІЁЂзюЬљКЯБОЮФбЁШЁЕФгяСЯЕФДЪЯђСПЪфШыЁЃ
4.3 ФЃаЭВЮЪ§
4.4 ЪЕбщНсЙћ
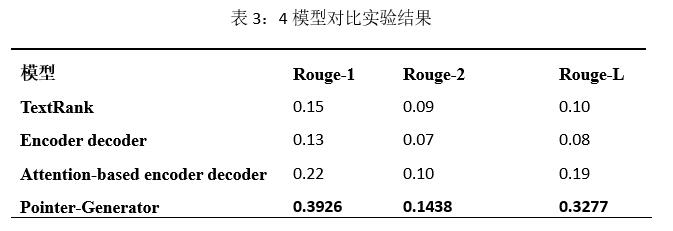
НсЙћБэУїPointer-GeneratorдкаТЮХБъЬтЩњГЩШЮЮёжаОпгаЯджјЕФгХЪЦЁЃ

ЭМ5ЪЧPGЩњГЩеЊвЊЕФУПИіЕЅДЪЖдгІШЋЮФЕФattentionЗжВМЃЌвдМАУПИіЕЅДЪЕФP_genИХТЪЁЃДгЭМжаПЩвдПДГіЃЌЕБЩњГЩеЊвЊЕФЕквЛИіДЪPhotographerЪБЃЌФЃаЭНЋОјДѓВПЗжзЂвтСІЗХдкдЮФжаЕФphotographerЁЂrussianЁЂphotographerЁЂnickетЫФИіЕЅДЪжаВЂвд0.189ЕФP_genИХТЪЩњГЩСЫеЊвЊЕФЕквЛИіДЪЁЃетБэУїPGФЃаЭОпБИЗЂЯжЮФБОЯИНкЕФФмСІЃЌВЂФмЙЛРэНтЮФеТФкШнжЎМфЕФЙиСЊДгЖјФмЙЛДяЕНзюМбЕФБъЬтЩњГЩФмСІЁЃ

ЮхЁЂНсТл
БОЮФЧаШыЕБНёЛЅСЊЭјаТЮХСьгђЮФВЛЖдЬтЃЌаТЮХПьЫйЛёШЁКЭИхМўЩѓКЫРЇФбЕФЭДЕуЁЃНсКЯЕБЯТЕФздШЛгябдММЪѕЗЂеЙЯжзДЃЌбизХЮФБОеЊвЊММЪѕЕФЗЂеЙТіТчЃЌНщЩмСЫЮФБОеЊвЊФЃаЭЕФСНРрЛљБОЗНЗЈТлМДЛљгкЭМНсЙЙФЃаЭКЭЛљгкЩюЖШбЇЯАЕФФЃаЭЁЃВЂНщЩмСЫЛљгкЩюЖШбЇЯАЕФЮФБОеЊвЊФЃаЭЕФМИДІБШНЯаТгБЕФИФНјЁЃзюКѓЭЈЙ§ХРШЁаТЮХЭјеОЩЯЕФецЪЕЛЅСЊЭјаТЮХЪ§ОнЃЌНјааСЫЖрФЃаЭЕФаТЮХБъЬтЩњГЩЖдБШЪЕбщЁЃзюКѓЕФЪЕбщНсЙћБэУїЛљгкpointer-generatorФЃаЭЕФаТЮХБъЬтЩњГЩНсЙћзюЮЊРэЯыЃЌФмЙЛгааЇЕигІгУЕНКЃСПЛЅСЊЭјаТЮХЕиБъЬтЩњГЩгІгУжаЁЃЭЌЪБЃЌЯжгаЕФЮФБОеЊвЊММЪѕШдШЛДцдквЛаЉВЛЬЋЭъЩЦЕФЮЪЬтЃЌШчФЃаЭИќвзгкЩњГЩГЄОфЃЌЧвжиИДЯжЯѓШдШЛДцдкЁЃ
гІгУаТЮХБъЬтЩњГЩЗНЗЈЩњГЩЕФЁАгааЇБъЬтЁБФмЙЛНЯЮЊИпаЇЕФМѕЩйШЫЙЄЩѓКЫИхМўЪБМфЃЌШЛЖјЃЌЮЊСЫГЙЕзНтОіЁАе№ОЊЬхЁБЯжЯѓХХВщЗБЫіЕФЮЪЬтЃЌЁАгааЇБъЬтЁБгыЁАе№ОЊЬхБъЬтЁБЕФЖдБШМьВтБиВЛПЩЩйЃЌБОЮФднЪБзХжиЬжТлгааЇБъЬтЕФЩњГЩЗНЗЈЃЌдкКѓајЙЄзїжаЃЌНЋзХжиЬНЬжЖдСНжжБъЬтЕФМьВтВПЗжЁЃ
ВЮПМЮФЯз
[1] Hans Peter Luhn. 1958. The automatic creation of literature abstracts. IBM Journal of research and development 2, 2 (1958), 159ЈC165.
[2] Ted Dunning. 1993. Accurate methods for the statistics of surprise and coincidence. Computational linguistics 19, 1 (1993), 61ЈC74.
[3] Sanda Harabagiu and Finley Lacatusu. 2005. Topic themes for multi-document summarization. In Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 202ЈC209.
[4] Lucy Vanderwende, Hisami Suzuki, Chris Brockett, and Ani Nenkova. 2007. Beyond SumBasic: Task-focused summarization with sentence simplification and lexical expansion. Information Processing & Management 43, 6 (2007), 1606ЈC1618.
[5] Rasim M Alguliev, Ramiz M Aliguliyev, Makrufa S Hajirahimova, and Chingiz A Mehdiyev. 2011. MCMR: Maximum coverage and minimum redundant text summarization model. Expert Systems with Applications 38, 12 (2011), 14514ЈC14522.
[6] Rasim M Alguliev, Ramiz M Aliguliyev, and Nijat R Isazade. 2013. Multiple documents summarization based on evolutionary optimization algorithm. Expert Systems with Applications 40, 5 (2013), 1675ЈC1689.
[7] GЈЙnes Erkan and Dragomir R Radev. 2004. LexRank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res.(JAIR) 22, 1 (2004), 457ЈC479
[8] Yihong Gong and Xin Liu. 2001. Generic text summarization using relevance measure and latent semantic analysis. In Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 19ЈC25
[9] Leonhard Hennig, Winfried Umbrath, and Robert Wetzker. 2008. An ontologybased approach to text summarization. In Web Intelligence and Intelligent Agent Technology, 2008. WI-IATЁЏ08. IEEE/WIC/ACM International Conference on, Vol. 3.IEEE, 291ЈC294.
[10] Sunitha, C., Jaya, A., & Ganesh, D. A. (2016). A study on abstractive summarization techniques in indian languages. In Fourth international conference on recent trends in computer science and engineering (pp. 25ЈC31).
[11] Barzilay, R., & McKeown, K. R. (2005). Sentence fusion for multidocument news summarization. Computational Linguistics, 31(3), 297ЈC327.
[12] Oya, T., Mehdad, Y., Carenini, G., & Ng, R. (2014). A template-based abstractive meeting summarization: Leveraging summary and source text relationships. In Proceedings of the 8th international natural language generation conference (pp. 45ЈC53).
[13] Alshaina, S., John, A., & Nath, A. G. (2017). Multi-document abstractive summarization based on predicate argument structure. In International conference on signal processing, informatics, communication and energy systems (SPICES) (pp. 32ЈC37). doi:10.1109/SPICES.2017.8091339.
[14] Alshaina, S., John, A., & Nath, A. G. (2017). Multi-document abstractive summarization based on predicate argument structure. In International conference on signal processing, informatics, communication and energy systems (SPICES) (pp. 32ЈC37). doi:10.1109/SPICES.2017.8091339.
[15] Chopra, Sumit, Michael Auli, and Alexander M. Rush. "Abstractive sentence summarization with attentive recurrent neural networks." Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016.
[16] Jobson, E., & Gutirrez, A. (2018). Abstractive text summarization using attentive sequence-to-sequence rnns. Stanford Reports.
[17] Song, S., Huang, H., & Ruan, T. (2018). Abstractive text summarization using lstmcnn based deep learning. Multimedia Tools and Applications, 1(6), 53ЈC57. doi:10. 1007/s11042-018-5749-3.
[18] See, Abigail, Peter J. Liu, and Christopher D. Manning. "Get to the point: Summarization with pointer-generator networks." arXiv preprint arXiv:1704.04368 (2017).
[19] Hollink L , Bedjeti A , Vanharmelen M , et al. A corpus of images and text in online news[J]. 2016.
ЗжЯэШУИќЖрШЫПДЕН 
ЭЦМідФЖС
ДЋУНЭЦМі
 @УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад
@УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ
ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
ЯрЙиаТЮХ
ПЭЛЇЖЫЯТди
ШЫУёШеБЈЩчИХПі | ЙигкШЫУёЭј | БЈЩчеаЦИ | еаЦИгЂВХ | ЙуИцЗўЮё | КЯзїМгУЫ | ЙЉИхЗўЮё | Ъ§ОнЗўЮё | ЭјеОЩљУї | ЭјеОТЩЪІ | аХЯЂБЃЛЄ | СЊЯЕЮвУЧ
ЗўЮёгЪЯфЃКkf@people.cn ЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-65363263 ОйБЈгЪЯфЃКjubao@people.cn
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170001 | діжЕЕчаХвЕЮёОгЊаэПЩжЄB1-20060139
ЙуВЅЕчЪгНкФПжЦзїОгЊаэПЩжЄЃЈЙуУНЃЉзжЕк172КХ | ЛЅСЊЭјвЉЦЗаХЯЂЗўЮёзЪИёжЄЪщЃЈОЉЃЉ-ЗЧОгЊад-2016-0098
аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0104065 | ЭјТчЮФЛЏОгЊаэПЩжЄ ОЉЭјЮФ[2020]5494-1075КХ | ЭјТчГіАцЗўЮёаэПЩжЄЃЈОЉЃЉзж121КХ | ОЉICPжЄ000006КХ | ОЉЙЋЭјАВБИ11000002000008КХ
ШЫ Уё Эј Ац ШЈ Ыљ га ЃЌЮД О Ъщ Уц Ък ШЈ Нћ жЙ ЪЙ гУ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЦРТл

-
ЙизЂ
ЮЂаХЮЂВЉПьЪж
 ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
 БЈЕРШЋЧђ ДЋВЅжаЙњ
БЈЕРШЋЧђ ДЋВЅжаЙњ
 ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
