




















Learning Chinese-Japanese Bilingual Word Embedding by Using Common Characters��2��
4.2 Bilingual CBOW
Now we consider CBOW in the scenario of bilingual word embedding. Generally, training bilingual word embedding requires a large corpus for each language, and also a relatively small parallel corpus acquired from strict translation and sentence-level alignment. The two monolingual corpora are trained to obtain the relatedness among words within a language, while the parallel corpus is used to calibrate the trained vectors between two languages.
Word-Aligned Method. The original CBOW can be extended to cater the bilingual scenario, with some extent of modifications. Two approaches are commonly used for such extension, one of them based on machine translation. This approach uses toolkit like ![]() to align parallel sentence-pairs on word level; by doing this, for each word, we can find its corresponding word. When two words reciprocally corresponded are trained, their respective contexts are used. For example, for sentence-pair
to align parallel sentence-pairs on word level; by doing this, for each word, we can find its corresponding word. When two words reciprocally corresponded are trained, their respective contexts are used. For example, for sentence-pair![]() a pair of aligned words is
a pair of aligned words is![]() and the objective function for training
and the objective function for training![]()
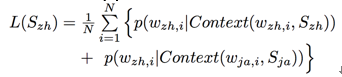
Using existing tools, the advantage of this approach is context can be optimally selected; this ensures an optimal training result, when data and other components of the model are fixed. However, a severe drawback of this approach is running the machine translation tools usually takes long time. Therefore, the training of model is unacceptably slow, leading to intractability in applications.
Sentence-Aligned Method. A simple modification can be made to avoid the above problem:
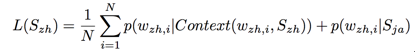
In other words, all words in Sja are introduced as the context of![]() in training, which obviously brings a large portion of noise in. However, based on this idea, some works have achieved satisfying results. One of them is BilBOWA [8], which reached a comparable level with state-of-the-art approaches after some modifications on the aggregation process. More importantly, the model is trained comparably fast with training monolingual word embedding.
in training, which obviously brings a large portion of noise in. However, based on this idea, some works have achieved satisfying results. One of them is BilBOWA [8], which reached a comparable level with state-of-the-art approaches after some modifications on the aggregation process. More importantly, the model is trained comparably fast with training monolingual word embedding.
4.3 Our Model: CJ-BOC
As has been mentioned, common Chinese characters of Chinese and Japanese are semantically similar or related. Inspired by the above extensions, we further exploit this feature and propose a CBOW-like model: Chinese-Japanese Bag of Characters model (CJ-BOC). In our proposed model, the objective function is:
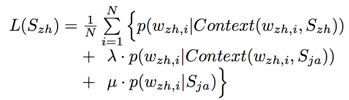
�� and �� here are both parameters of the model, and Context![]() can be acquired via common character matching:
can be acquired via common character matching:

CC(?) here is character matching, which means:
![]()
We use c to denote common character, and the function CC(?) is to find all words sharing common characters in Sja for wzh,i. Then the contexts of all these words are used for training wzh,i. We illustrate an example in Fig.2. ������/��/��/ӣ��/��/�ˡ�and ����/��/�ʤ�/��/�@/��/�D��/�ޤ��� are a parallel sentence-pair, meaning ��Spring is coming, and cherry blossom is coming out��. The model detects the Chinese character ��ӣ�� in ��ӣ��(cherry blossom)��, which is identical to ���@(cherry blossom)�� in Japanese. Therefore, these two characters share their respective context during training.?
Our method is apparently better than sentence-aligned method, which can be verified through qualitative analysis. Theoretically, our method introduces extra noise compared with word-aligned method, since multiple common Chinese characters with different meanings may co-exist even in the same sentence. But according to our subsequent experiments on mutual information, we can see that the noise ratio is actually minor, owing to the intrinsic nature of parallel sentence-pair. We also introduce the character information as auxiliary, which, to some extent, provides more information than word-aligned method.
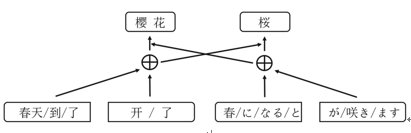
Fig. 2. An example of CJ-BOC, window length is 4, common character is ��ӣ(�@)��.
5 Experiments and Analysis
5.1 Datasets and Experiment Settings
In our experiment, the parallel corpus is from [10], which includes Chinese- Japanese sentence-pair generated from wikipedia (both Chinese and Japanese version). We mainly used train.ja and train.zh in this dataset, both including 126811 lines of text. In both files, each line is a complete sentence, which is parallel to the sentence in its corresponding line of the other file. As preprocessing, we performed word segmentation on the two files using MeCab for Japanese and Jieba for Chinese before experiments. Parameters were tuned to ensure the segmentation on both languages were almost equally grained.
In our experiment, we took sentence-aligned method (Sen-AM) as the base- line, to comparably demonstrate the performance of our CJ-BOC. Both methods were implemented in C language . Suppose there are N sentences in total, each of which containing k words, and each word consists of p characters; if the window length is w, and training a word costs O(M) time, the theoretical worst-case time complexity of Sen-AM should be![]() while our CJ-BOC has a worst-case time complexity of
while our CJ-BOC has a worst-case time complexity of![]() Since p, k and w are typically small, there is no notable difference between CJ-BOC and Sen-AM in terms of asymptotic worst-case complexity. To improve learning, we turned on both hierarchical softmax and 10-word negative sampling, which Mikolov proposed in Word2Vec. We set the window length to 5; �� and �� in CJ-BOC were 0.7 and 0.3 respectively. We used a Linux PC to run the experiment, which has a 2.6GHz CPU and 8 G memory. Using Sen-AM and CJ-BOC to train the above parallel corpora, the time consumptions are 112.962s and 178.022s respectively; we can see that using CJ-BOC here only brought 63.5% extra training time, compared with Sen-AM. Both methods finally generated 25219 word embeddings in Chinese and 22749 in Japanese, which will be used in subsequent experiments in Subsects. 5.3 and 5.4.
Since p, k and w are typically small, there is no notable difference between CJ-BOC and Sen-AM in terms of asymptotic worst-case complexity. To improve learning, we turned on both hierarchical softmax and 10-word negative sampling, which Mikolov proposed in Word2Vec. We set the window length to 5; �� and �� in CJ-BOC were 0.7 and 0.3 respectively. We used a Linux PC to run the experiment, which has a 2.6GHz CPU and 8 G memory. Using Sen-AM and CJ-BOC to train the above parallel corpora, the time consumptions are 112.962s and 178.022s respectively; we can see that using CJ-BOC here only brought 63.5% extra training time, compared with Sen-AM. Both methods finally generated 25219 word embeddings in Chinese and 22749 in Japanese, which will be used in subsequent experiments in Subsects. 5.3 and 5.4.
5.2 Estimating Mutual Information
Before evaluating the effect of word embedding, we first conducted an exper- iment to estimate the mutual information of common Chinese characters. We did this experiment, hoping to support our method from an information theory perspective. The process was as follows:
(1) Select a Chinese character ch, and retrieve its meaning in Chinese and Japanese according to Xinhua and Kojien dictionary respectively. Suppose ch has respectively n and m meanings in Chinese and Japanese, which are denoted as (x1,...,xn) and (y1,...,ym).
(2) Randomly choose M sentences with ch in both languages independently, and count the frequency of it with each meaning: (a1,...,an) and (b1,...,bm). The meaning of ch in each sentence is acquired using manual annotation. If ch appears k times in a single sentence, each of the appearance is deemed to contribute![]() frequency to its corresponding meaning.
frequency to its corresponding meaning.
(3) Take the frequency of each meaning as the estimation of its appearance probability:![]()
(4) For the conditional probability![]() extract N parallel sentence pairs both of which include ch, and mark its semantics. Similar to steps 2 and 3, frequency is taken as an estimation of probability.
extract N parallel sentence pairs both of which include ch, and mark its semantics. Similar to steps 2 and 3, frequency is taken as an estimation of probability.
(5) Exploit the above information to calculate conditional mutual information:
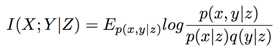
(6) Given the unconditional joint probability:

where |Z|=N and |Z|+|Z ? |=N^2. We assume in this unconditional situation, a Chinese sentence may correspond to any Japanese sentence in the corpus, and vice versa. To be more specific, given this independency, we can thus compute p(x_i,y_j��Z ? )= p(x_i )p(y_j ).
(7) The unconditional mutual information can be computed using the above information.
To illustrate, we selected two representative common characters ����(means sky, heaven, etc.)�� with M = 78 and N = 54, and ����(means ground, earth, etc.)�� with M = 83 and N = 51. The results are show in Table 2.?
An intuitive conjecture, based on experiences, is that conditional mutual information should be greater than unconditional mutual information. Table2 somehow provides evidence for this conjecture, as we can see that conditional mutual information of these two representative characters are significantly larger than the corresponding unconditional mutual information. This indicates in a sentence-pair of parallel corpus, a pair of common Chinese characters are likely to be equivalent semantically. Therefore, in our CJ-BOC, the extraction of context using common Chinese characters is rooted in solid theoretical base.

Table 2. Mutual information.
5.3 Cross-Lingual Synonym Comparison
In translation, some word in the source language can actually correspond to multiple words in the target language, and we can also find one-to-one correspondence of words between source and target language. To avoid ambiguity, we randomly selected 15 one-to-one corresponding word-pairs ?wzh,wja?, and for each pair, we: (1) compute the cosine distance d between wzh and wja; (2) compute the cosine distance between wzh and every Japanese word in the corpus Cja, and obtain the rank of d among them; (3) conduct similar operations as in (2) on wja and every Chinese word in the corpus Czh.
Some of the selected words have common characters, while some do not. Two examples are given in Table 3.

Table 3. Examples of word-pairs and their experimental results.
For the rank of each word, we compute its relative rate among all words as below:
![]()
None of the words in these word-pairs is ambiguous, which makes it apparent that both cosine distance and the rate are favorable to be large. The averaged results for all word-pairs are shown in Table 4. From Table 4, we can see obvious superiority of CJ-BOC compared with Sen-AM.

Table 4. Average of cosine distances and rates of 15 word-pairs.
5.4 Cross-Lingual Analogical Reasoning
Analogical reasoning [13,14] tries to figure out the potential analogy among word embeddings. Take a frequent question in IQ test as an example, what is the answer of ������(father):ĸ��(mother)::�к�(boy):X��? The expected answer is ��Ů��(girl)��, which is deduced as: x=v(ĸ��)-v(����)+v(�к�) according to analogical reasoning. The closest word embedding to x is retrieved as the answer, which indicates a single successful task if it is v(Ů��).
Given several related words from different languages, cross-lingual analogi- cal reasoning works as follows: y=v(�Ϥ�)-v(����)+v(�к�), we hope that the relatedness between Japanese words ���Ϥ�(mother)�� and ������(father)�� could help us find the Chinese character ��Ů��(girl)�� through ���к�(boy)��.
Among the 4 words in cross-lingual analogy tasks, the number of Chinese word to the number of Japanese word can be 2 to 2, 1 to 3 or 3 to 1. For the 2 to 2 case, Mikolov in [2] mentioned that, even the word embeddings were trained independently within their own language (i.e., not in a cross-lingual manner), the trained embeddings could still capture good features. So we do not consider this case in our experiment. Instead we selected 72 groups of 1 to 3 or 3 to 1 cross-lingual analogy tasks, with the input format being {A:B::C:D}. We computed the vector V = B ? A + C, and just as we did in experiment 2, we calculated the cosine distance d between V and D; besides, we also figured out the cosine distance between every pair ?V, D��? (D�� is from the corpus of D), obtained the rank of d among them, and then transformed its rank to the corresponding rate. We averaged the results to make them comparable: the average Cosine distance of Sen-AM and CJ-BOC is 0.2309 and 0.3882 respectively; while Sen- AM has a rate of 85.8%, roughly 10% lower than that of CJ-BOC, which is 95.3. Based on these results, we can conclude that the quality of our word embedding is obviously higher than that of Sen-AM.
6 Conclusion and Future Work
In this work, we first reviewed the background of word embedding and bilingual word embedding, and then demonstrated the semantical equivalence and relatedness among common characters of Chinese and Japanese. In addition, we performed theoretical derivation and empirical study on the common character, from a perspective of information theory. In light of the feature of common character, we proposed our CJ-BOC model based on CBOW, which can learn Chinese-Japanese word embedding efficiently. According to our experiments on task of bilingual analogical reasoning, the word embeddings generated using CJ-BOC were obviously better than those of sentence-alignment methods.
As for future work, our research could possibly move on towards two directions: (1) the exploitation of common character should not be limited by the model. In other words, apart from the NNLM-based Word2Vec, we can also use methods like GloVe instead. (2) [9] actually provided a promising idea, which is to train word embeddings and character embeddings at the same time. And such combination could further verify the characteristics of common characters.
References
1. Hinton, G.E.: Learning distributed representations of concepts. In: Proceedings of the Eighth Annual Conference of the Cognitive Science Society ?
2. Mikolov, T., Le, Q.V., Sutskever, I.: Exploiting similarities among languages for machine translation (2013). arXiv:1309.4168 ?
3. Guo, J., Che, W., Wang, H., Liu, T.: Learning sense-specific word embeddings by exploiting bilingual resources. In: Proceedings of COLING, pp. 497�C507 (2014) ?
4. Bengio, Y., Ducharme, R., Vincent, P., Janvin, C.: A neural probabilistic language ?model. J. Mach. Learn. Res. 3, 1137�C1155 (2003) ?
5. Mnih, A., Hinton, G.E.: A scalable hierarchical distributed language model. In: ?Advances in Neural Information Processing Systems, pp. 1081�C1088 (2009) ?
6. Mikolov, T., Yih, W.T., Zweig, G.: Linguistic regularities in continuous space word ?representations. In: HLT-NAACL, pp. 746�C751 (2013) ?
7. Pennington, J., Socher, R., Manning, C.: Glove: global vectors for word representation. In: Conference on Empirical Methods in Natural Language Processing ?(2014) ?
8. Gouws, S., Bengio, Y., Corrado, G.: BilBOWA: fast bilingual distributed representations without word alignments (2014). arXiv:1410.2455 ?
9. Chen, X., Xu, L., Liu, Z., Sun, M., Luan, H.: Joint learning of character and word ?embeddings. International Conference on Artificial Intelligence. AAAI Press (2015) ?
10. Chu, C., Nakazawa, T., Kurohashi, S.: Constructing a Chinese-Japanese parallel ?corpus from Wikipedia. In: Proceedings of the Ninth Conference on International ?Language Resources and Evaluation (LREC 2014), Reykjavik, Iceland, May 2014 ?
11. Chu, C., Nakazawa, T., Kurohashi, S.: Chinese characters mapping table of Japanese, traditional Chinese and simplified Chinese. In: Proceedings of the Eighth Conference on International Language Resources and Evaluation (LREC 2012), pp. ?2149�C2152, Istanbul, Turkey, May 2012 ?
12. Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. arXiv:1301.3781 ?
13. Veale, T.: An analogy-oriented type hierarchy for linguistic creativity. Knowl. ?Based Syst. 19(7), 471�C479 (2006) ?
14. Veale, T., Li, G.: Analogy as an organizational principle in the construction of ?large knowledge-bases. In: Prade, H., Richard, G. (eds.) Computational Approaches to Analogical Reasoning: Current Trends. SCI, vol. 548, pp. 83�C101. Springer, Heidelberg (2014). doi:10.1007/978-3-642-54516-0 4
 |
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
