




















Learning Chinese-Japanese Bilingual Word Embedding by Using Common Characters
Abstract. Bilingual word embedding, which maps word embedding of two languages into one vector space, has been widely applied in the domain of machine translation, word sense disambiguation and so on. However, no model has been universally accepted for learning bilingual word embedding. In this work, we propose a novel model named CJ- BOC to learn Chinese-Japanese word embeddings. Given Chinese and Japanese share a large portion of common characters, we exploit them in our training process. We demonstrated the effectiveness of such exploitation through theoretical and also experimental study. To evaluate the performance of CJ-BOC, we conducted a comprehensive experiment, which reveals its speed advantage, and high quality of acquired word embeddings as well.
Keywords: Bilingual word embedding・Distributed representation・Common characters・Chinese-Japanese
1 Introduction
Due to the boost of social network, massive text data are generated every day, reaching an enormous bulk beyond human’s reading ability. Therefore, there is now an urgent need of high-quality knowledge extraction from text, which is often associated with natural language processing (NLP) techniques. Word embedding, originally referred as distributed representation, was proposed by Hinton [1], whose basic idea is to denote word as low-dimension and real-valued vector. A favorable feature of word embedding is that the trained vectors can reflect the similarity among words. Such merit led to the popularity and thus broad applications of word embedding, in which Word2Vec by Google has been extensively used in text mining, text segmentation, synonym discovery, etc.
Bilingual word embedding, as a specific form of word embedding, maps vectors of two different languages into the same vector space. Bilingual word embedding directly depicts the internal relatedness among words of two different languages, and is therefore believed able to facilitate many NLP tasks. Actually many research efforts have strengthened such belief, as bilingual word embed- ding has been successfully applied in machine translation [2], word sense disambiguation [3] and so on. Despite its advantages, bilingual word embedding is still at its initial stage, without commonly accepted approaches.
In this paper, we propose a model CJ-BOC for learning Chinese-Japanese word embedding, based on CBOW (short for continuous bag-of-words), one of the two models given in [2]. The exploitation of common Chinese characters shared by Chinese and Japanese is the main difference distinguishing CJ-BOC from CBOW, whose validity is well demonstrated according to both theoretical and empirical study. In our experiment, CJ-BOC significantly outperformed sentence-aligned approaches in terms of the quality of word embedding.
The contributions of our work are: 1. We analyze and demonstrate why com- mon characters shared by Chinese and Japanese are effective for learning word embedding, from a view of information theory; 2. Based on the exploitation of common characters, we design a novel model for learning Chinese-Japanese word embedding; 3. We conduct a comprehensive experiment to verify the effectiveness and efficiency of our approach.
The rest of this paper is structured as follows: Sect.2 reviews the related work, Sect.3 introduces common characters, and Sect.4 elaborately introduces our model CJ-BOC. In Sect.5, we present our experimental results. Finally in Sect. 6, we conclude this paper and give the future work.
2 Related Work
Distributed representation, now commonly referred as word embedding, was firstly proposed by Hinton [1]. Compared with the one-hot representation in early works of NLP and information retrieval, distributed representation can better reflect the relatedness among words. Due to this unique merit, recent years have seen vast research efforts on word embedding.
One typical framework for learning word embeddings is neural network language models (NNLM) proposed by Bengio et al. [4], which uses back propagation to train each word embedding and parameter of the model. NNLM has been widely applied [5]. As an open source framework, Word2Vec provides multiple models, including H-Softmax, NEG, CBOW, and Skip-Gram, and is known for its fast training speed, as well as the quality word embeddings learned from it. By exploiting the advantages of both global matrix factorization and local context window methods, Pennington et al. [7] proposed a model named GloVe.
In 2013, Mikolov et al. presented a work [2] which obtained English and Spanish word embedding separately, and then generated English-Spanish embeddings using a linear mapping between vector spaces of both languages. Compared with traditional monolingual word embedding, bilingual word embedding is still at its initial stage. On the other hand, bilingual word embedding directly depicts the internal relatedness among words of two different languages; theoretically, such merit enables bilingual word embedding to facilitate machine translation, or even fully replace word mapping matrix or dictionary in traditional machine translation approaches. The experiment result of [2] provided solid proof, which achieved an accuracy of around 90 % for English-Spanish word translation, with the help of bilingual word embedding. In light of this, bilingual word embedding has recently been applied successfully to machine translation [2], named entity recognition, word sense disambiguation [3], etc.
BilBOWA by Gouws et al. [8] is a model for learning bilingual word embed- dings. An outstanding advantage of BilBOWA is it eliminates the need of word alignments or dictionaries; and in an English-German cross-lingual classification task, BilBOWA achieved a speedup as high as three orders of magnitude.
As for non-alphabet-based languages like Chinese and Japanese, word embed- ding (and other NLP research as well) is also basically studied at the word level. But the individual character of a word actually often has semantical meaning itself. By taking the rich internal information of composing characters into consideration, Chen et al. [9] proposed a new model called character-enhanced word embedding model (CWE), and outperformed approaches that neglect such internal information. Another interesting fact of Chinese and Japanese is: both languages share a large portion of common characters. Through these common characters, Chu et al. [10] successfully constructed a Chinese-Japanese parallel corpus, which is highly accurate.
3 Common Character
3.1 Chinese and Japanese Characters
Chinese characters were invented over 4000years ago, and have been spread with Chinese culture to neighboring countries like Korea, Japan, Vietnam, etc. Combined with the native languages of these countries, Chinese characters have become part of their writing systems. Early Japanese writing system was copied from Chinese characters, which made both countries able to understand the literature of each other. Through the years, Chinese characters were gradually integrated with Japanese native languages, and later formed a writing system with Chinese characters (kanji), hiragana and katakana combined.
There are three Chinese character systems currently, including traditional Chinese (in Hong Kong, Macau, Taiwan), simplified Chinese (in mainland China, Singapore, Malaysia, etc.), and Japanese Kanji. The latter two were independently simplified from traditional Chinese. Most Chinese characters in these three systems can be reciprocally corresponded, with the same shape or slight variances only. In Table1 we can see 4 groups of corresponding Chinese characters with basically the same meanings. Therefore in real-world applications, most Chinese characters in a specific system can find their corresponding characters in other systems. For example, Chu et al. [11] proposed a Chinese character table involving traditional Chinese, simplified Chinese and Japanese.
Japanese vocabulary is categorized into several types: kango, wago, gairaigo, etc. Kango was either borrowed from Chinese or constructed from Chinese roots. As for wago, some of them are purely made up of Chinese characters, and there are also some mixed by Chinese characters and kana (hiragana and katakana), also a few wholly formed by kana. According to the Shinsen Kokugo Jiten Japanese dictionary, kango comprises 49.1% vocabulary and wago makes up 33.8 %.

Table 1. Examples of common characters in Simplified Chinese, Traditional Chinese, and Japanese Kanji.
Hence roughly 80 % of Japanese words contain Chinese characters. A plausible conjecture is that the meanings of these Chinese characters are equivalent or somehow related to their meanings in Chinese. Sufficient works have been done to compare Chinese and Japanese words formed by common Chinese characters, which provide solid proof for this conjecture. Due to space limits, we skip these details here, but there can be totally 4 cases: wzh = wja, wzh > wja, wzh < wja, and wzh ≈ wja, in which wzh and wja denote the meaning count in Chinese and Japanese. An example for wzh ≈ wja is that the word “意见” means “opinion” in both Chinese and Japanese. Moreover, it also means “dissatisfied” in Chinese, and “suggest” in Japanese.
3.2 From a View of Information Theory
From the above comparison between common characters in Chinese and Japanese, we can figure out the difference between Chinese/Japanese and western writing system. To be more specific, in Chinese or Japanese, a word can be constructed either by multiple Chinese characters, or by only one, since every Chinese character can solely make sense. Take the Chinese character “天” to illustrate, which can be either a word itself or part of a word in both Chinese and Japanese. In either case, “天” means one of “sky”, “heaven”, “day”, and so on.
Word embedding essentially vectorizes the semantics of a word, and actually has been studied on Chinese characters. Consider a Chinese character Czh in a Chinese article, and its corresponding character Cja in Japanese; the semantic difference of Czh and Cja in their respective contexts can be depicted using mutual information, a concept measuring the dependency among random variables. Mutual information is defined as follows:
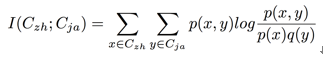
Mutual information is non-negative and symmetric; given a condition Z about the distribution between Czh and Cja, conditional mutual information is:
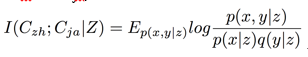
In this paper, we let the condition Z be Czh ∈ Szh, Cja ∈ Sja, in which Szh and Sja are a Chinese and Japanese sentence respectively in Chinese-Japanese translation. Through qualitative analysis, we can conclude that for common Chinese characters in corresponding Chinese and Japanese sentences, the probability of semantic equivalence is notably high. In subsequent experiments, to prove this conclusion, we will estimate the conditional mutual information of some Chinese characters within a certain amount of translated sentences.
4 Model
In this section, we first introduce the widely used model CBOW, and also some extensions on it. Then we present our own model named CJ-BOC.
4.1 CBOW
Mikolov et al. in [12] proposed continuous bag-of-words model (CBOW), where the optimization goal is to maximize a probabilistic language model as follows:
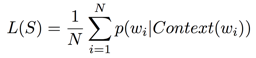
We use Context(wi) to denote the context of wi here:
![]()
K is the window length here, which can be tuned in the model. The probability of each word in a given context can be computed using a softmax function:
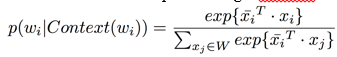
in which ![]() is the average word embedding of the context:
is the average word embedding of the context:
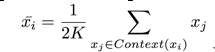
To better illustrate CBOW, we present its sketch as shown in Fig. 1. In the sentence “我们/的/祖国/像/花园” (Our homeland is like garden), we set the window length to 2; when learning the word “祖国”, there are totally 4 words used for updating it, two of which following it and the other two before it.
In addition, CBOW can also be combined with Skip-gram, negative sampling and other methods for improvement. Such combination can be found in Word2Vec, and hence we do not elaborate here.
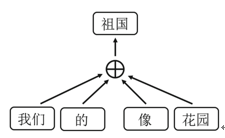
Fig. 1. An example of CBOW, in which the windows length is 2.
 |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
