




















基于在线自适应多重外观模型的长期视频跟踪模型
摘要
如何构建被跟踪目标的外观描述是进行长期鲁棒的目标跟踪的基本挑战。在最近的研究中,许多跟踪方法更注重更新跟踪目标的当前外观,通过采用特殊的视觉特征和学习方法来构建一个在线外观模型。然而,单个外观模型总是不足以描述历史出现信息,且无法应对照明变化和目标被切割的情况,对于长期跟踪任务这些情况会出现的更多。在本文中,我们提出在线自适应多重模型以提高目标跟踪性能。通过构建基于Dirichlet过程混合模型(DPMM)的外观模型集合,其可以动态地且以无监督的方式将跟踪目标的不同外观进行分组。尽管DPMM具有如上有点,但DPMM依赖于吉布斯取样器这个计算密集的推断过程。由于目标跟踪对逐帧处理的效率要求较高,吉布斯取样器因为时间成本高不适合跟踪。所以在原有的DPMM模型基础上,我们提出了一种在线贝叶斯学习算法,通过以流的方式通过顺序逼近从头开始可靠和有效地学习DPMM以适应新的跟踪目标。在多个具有挑战性的基准公共数据集上进行的实验证明了所提出的跟踪算法优于现有技术。
关键词
目标跟踪;多重外观模型;在线Dirichlet过程混合模型(DPMM)
1. 引言
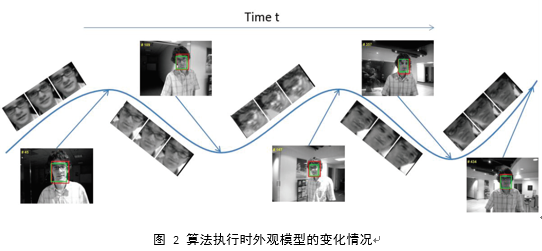
目标跟踪在许多视觉应用中起着重要作用,例如运动分析,活动识别,视觉监控和智能用户界面等。 然而,尽管近年来已经取得了很多进展,但是由于如视角转换,照明变化,相机切换等跟踪环境的变化,在真实世界中长期跟踪运动对象仍然是一个具有挑战性的问题。对于视觉跟踪问题,常使用外观模型来表示目标对象并预测未来帧中的跟踪目标的可能状态[1] [2] [3]。 然而,使用单个外观模型不适合描述所有的历史出现信息,特别是对于长期跟踪任务。 因此,我们将研究重点放在以无监督的方式动态地建立多个外观模型,以适应跟踪目标的变化外观。
在本文中,我们使用无参数贝叶斯聚类方法动态聚类多个具有较大差异的外观,这么做可以更好的概括不对象的不同外观,使得所提出的算法对于突然的外观变化更加鲁棒,并且得到的模型聚类个数也可以很好的得出。在不同的概率模型中,贝叶斯非参数方法具有适合于对象跟踪应用的几个属性。特别地,DPMM表示具有无限数量的分量的混合分布,其中模型的复杂度和观察到的数据相关。该特性对于动态建立多个外观模型是非常重要的,因为出现的外观数量通常不是先验已知的,不过可以合理地假定随时间改变。
然而,尽管DPMM在概括模型时,其特点是计算密集型推理程序,且通常基于吉布斯采样器[4]。虽然当执行时间不是一个问题时吉布斯采样可以作为一个非常合适的推断机制,但它并不适用于需要快速推理的视觉跟踪。[5]中有一个变分推理方法,在每次迭代之后其最大化真正的底层分布的下界,从中获得的参数定义一个分布,该分布以一个适当定义的方式逼近真正的底层分布。然而,变分推理法非常容易陷入非凸无监督学习问题的局部最优化,常常产生差的解决方案。
在视觉跟踪的相关文献中,基于无参数贝叶斯(简称:BNP)的外观模型方法不像参数化方法如[7]一般应用的那么广泛。 BNP跟踪方法的主要方法包括如下所示的三个方面:我们需要解决1)如何用贝叶斯非参数模型表示跟踪目标的观察结果,2)如何在不知道簇数和模型参数的情况下动态创建多个外观模型以适应跟踪环境变化,3)如何在跟踪过程中有效和可靠地更新多个外观模型。我们提出的算法灵感大多来自[6] [8],它们使用在线贝叶斯学习算法来估计DP混合模型。此方法不需要像Gibbs采样器那样的随机初始化。相反,它可以通过在单次运行中的顺序近似可靠和有效地从头学习DPMM。该算法以流的方式接收数据,并且因此可以容易地适应于新的跟踪目标。

本文的其余部分组织如下:第2节回顾一些相关的算法。第3节回顾了算法所基于的贝叶斯非参数模型。 第4节介绍多重外观建模和表示,并提出可以描述跟踪特征生成过程的相关概率分布。第5节介绍了一种在线顺序贝叶斯方法来构建多重外观模型。提出的跟踪算法的主框架在第6节中介绍。第7节展示实验结果。本文在第8节进行总结。
2. 相关工作
目标跟踪的文献非常的丰富[11] [12]。作为跟踪算法的主要组成部分,跟踪目标外观建模在跟踪性能中起着关键作用。良好的外观表示应具有强烈的描述能力以及辨别力,以区分目标与背景。为了在跟踪期间适应目标的外观变化,目前已经提出了许多自适应外观模型用于包括生成和区分方法的对象跟踪。
对于生成外观建模方法,Jepson等人[13]通过在线期望最大化算法来学习高斯混合模型,以考虑跟踪期间的目标外观变化。增量子空间方法也被用于在线对象表示[32]。该方法使用在线获得的目标观测值来学习用于对象表示的线性子空间。由于目标在长时间间隔中的出现可能完全不同,这些生成模型可能不能很好的描述目标外观变化。对于辨别外观建模方法,Avidan等人[17]使用在线提升方法进行跟踪。他们提出了一套跟踪框架来构建一个强分类器来区分目标和背景。 Babenko等人[16]使用多实例学习(MIL)而非传统的监督学习,以避免自学习造成的不准确性积累问题。在这些方法中,跟踪通常被视为二进制分类问题,并且它们通常需要正确标记的样本来训练和更新分类器,这在许多真实跟踪应用中可能是不可用的。
与我们的模型最相关的是我们以前的工作[41],其提出了原始自适应多外观模型(AMAM)框架维护多个外观模型以记录在长期跟踪任务中描述跟踪的所有历史外观目标的外观模型集合。这种方法使用DPMM建立多个外观模型无监督处理漂移问题,在几个公共数据集上完成的实验表明,该跟踪器与其他几个其他最先进的方法相比具有高跟踪性能。为了推断之前观察的不同外观的数量,该跟踪器使用吉布斯采样器[4]进行近似推理,该过程需要组件进行随机初始化。然而,因为吉布斯采样器需要保持随机初始化,这个跟踪器的计算复杂性相当高,这限制了其在真实情况下该方法的应用。
与上述跟踪方法相比,我们提出的方法在处理目标的外观变化方面有三个主要特征。首先,我们的方法可以动态聚集多个不同的外观,并且可以从跟踪观察中推断聚类的数量。其次,在我们的方法中,不同种类的跟踪目标出现可以通过新的模型或构造的外观模型来覆盖各种目标外观,使得所提出的方法对于突然的外观变化更加鲁棒。最后,我们的方法从一个空模型开始,随着目标跟踪后的观察逐步细化模型,在需要时添加新的外观模型。
3. 无参数贝叶斯模型
[10]中引入的Dirichlet过程(DP)是一种非参数随机过程,其定义了概率分布的分布。DP被具有对应密度函数h(μ)的基本分布H和正缩放参数α> 0来参数化。我们将DP定义如下:
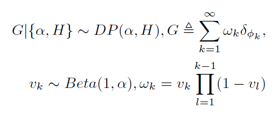
当混合成分的个数先验未知时,DP最常用作混合模型的参数先验分布。这样的模型被称为Dirichlet过程混合模型(DPMM),其可以被指定为:
![]()
令z_i表示与第i次观察相关的子集或聚类,DP混合模型也可以使用DP的中国餐厅过程(CRP)[17]来建模,引出以下:
![]()
从而,一个使用CRP的DPMM等价模型可以用如下形式表示:
![]()
4. 多重外观模型和其表示
在本节中,我们的目标是开发一种概率方法来无监督地聚集多个不同的外观,这样可以覆盖被跟踪目标外观的各个方面。为了这样做,我们使用直方图表示运动特征(例如HOG,颜色特征等),然后将跟踪观察的运动特征值量化到20个或更多个级别,这是类似的基于直方图的特征的常见做法(如[9])。因此,考虑N个跟踪观测结果X=〖{X_i}〗_(i=1)^N,其可以被聚类成K个簇或不同的外观,并且每个X=〖{X_i}〗_(i=1)^D表示量化的D维运动特征,X_i是对应的直方图量化的二进制计数,其是量化的整数。随着新的跟踪观测结果送达,群集的数量会发生变化。给定针对每个观察X_i的簇的分配,其对于该簇的似然性为F(X_i |θ_k),而θ_(1:K)从DPMM的基本分布得出。
4.1 指数族分布于足够的统计量
为了描述作为直方图的小整数集合和直方图二进制计数的运动特征X,我们采用作为指数族分布的成员的分量分布。DPMM的基本测量是共轭先验,因为它具有许多可以接受有效推断算法的性质。因此,在本文中,我们考虑如下分布:
![]()
其中a是对数配分函数。 我们将H置于相应的共轭族中:
![]()
其中统计值由向量(θ^T,-α(θ))给出, 又有λ=(λ_1^T,λ_2)。
4.2 模型表示
具体地,我们选择多项分布F(X_i |θ),其表示Mult(θ_k;n) θ_k=(p_1,…,p_D)是D维非负整数向量X_i=(x_1,…,x_D)其中∑_(i=1)^D?x_i =n。 概率质量函数给出如下:
![]()
聚类先验H(θ|λ)由与F(X_i |θ)共轭的Dirichlet分布表示。我们将聚类先验H(θ|λ)表示如下,其是Dirichlet分布并且与F(X_i |θ)共轭。
![]()
其中归一化常数是多项式β函数。 由于H(λ)与F(θ)共轭,则边边缘分布可以通过整合 (p_1,…,p_D)得到如下:
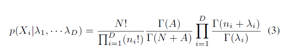
![]()
4.3 多重外观模型
对于我们的模型,当类别K的数量随观察结果而变化时,多重外观模型遍顺利建立。考虑所有模型参数,其服从于模型参数θ_(1:K)和聚类指标Z_(1:N),非参数贝叶斯混合模型的联合分布可以写成公式(4)。

这里,z_i ?{1…K}, i?{1…N}表示观察X_i的类标签,θ_k是第k个外观模型的参数。我们提出的方法的目标是无监督和动态推断联合后验分布p(θ_(1:K),z_(1:N) |X_(1:N)),然后我们可以得到多个外观模型的参数θ_(1:K)。
5. 在线顺序方法
为了推断联合后验分布p(θ_(1:K),z_(1:N) |X_(1:N)),我们可以随机初始化分量,然后像我们以前的工作[41]一样使用吉布斯取样器进行近似推断。然而,该方法需要维护全局,因此该跟踪器的计算复杂度相当高,这限制了其在实时情况下的应用。受工作[6]的启发,在本文中,我们使用在线顺序变分近似法改进我们以前的工作,不需要随机初始化; 相反,其可以通过以流传输方式的顺序逼近可靠和有效地从头学习DPMM,因此可以容易地适应新的观察结果。

 |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
