




















ЛљгкЦРТлЕФИіадЛЏЦРЗждЄВт
ЁОеЊвЊЁП: ШчНёЃЌгУЛЇКЭЩЬЦЗжЎМфЕФдкЯпЛЅЖЏБфЕУЖрбљЛЏЃЌАќРЈЮФБОЦРТлКЭЪ§зжЦРЗжЁЃЦРТлБэДяСЫИїжжвтМћКЭЙлЕуЃЌПЩвддквЛЖЈГЬЖШЩЯЯћГ§ЭЦМіЕФЯЁЪшадЮЪЬтЁЃдкБОЮФжаЃЌЮвУЧЬжТлЛљгкИіадЛЏЛљгкЦРТлЕФдЄВтЮЪЬтЃЌМДРћгУгУЛЇЕФРњЪЗЦРТлКЭЯргІЕФЦРМЖРДдЄВтЫћУЧЮДРДвЊТђЕФЮяЦЗЕФЦРЗжЁЃЫфШЛКмЖрШЫЖМжТСІгкНтОіетвЛЬєеНЮЪЬтЃЌжївЊЪЧЮЊСЫбаОПШчКЮЖдздШЛЮФБОКЭгУЛЇИіадЛЏНјааНЈФЃЃЌЕЋДѓЖрЪ§ШЫКіТдСЫвўВидкгУЛЇЦРТлКЭЦРЗжађСажаЕФСЌајЬиеїЁЃЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧЬсГіСЫвЛжжаТгБЕФЛљгкЛьКЯЦРТлЕФЫГађФЃаЭРДВЖзНгУЛЇКЭЮяЦЗЕФаХЯЂЁЃетЪЧЭЈЙ§НЋгУЛЇКЭЮяЦЗЕФађСаЬсЙЉИјВЖЛёЖЏЬЌЕФГЄЖЬЦкМЧвфЃЈLSTMЃЉЩёОЭјТчРДЪЕЯжЕФЃЌГ§ДЫжЎЭтЃЌЮвУЧЛЙРћгУЛљгкДЋЭГЕФЕЭжШвђзгЗжНтЛёЕУЕФгУЛЇБэЪОвдМАЮяЦЗБэЪОЁЃдкЪЕМЪЙЋЙВЪ§ОнМЏЕФЪЕбщНсЙћБэУїЃЌЮвУЧЕФФЃаЭгХгкЦфЫћБШНЯФЃаЭЁЃ
ЁОЙиМќДЪЁП: ЭЦМіЯЕЭГ, ЦРМЖдЄВт, ЦРЙРЗжЮі, ЪБађФЃаЭ
1 МђНщ
ЫцзХЛЅСЊЭјЕФПьЫйЗЂеЙЃЌУПЬьЖМЛсгПЯжГіДѓСПЕФаХЯЂЃЌДјРДЛњгіКЭЬєеНЁЃ дкаэЖрВЩгУЕФММЪѕжаЃЌЭЦМіЯЕЭГвЛжБАчбнзХдНРДдНживЊЕФНЧЩЋЃЌгаРћгкМѕЧсЦеЭЈгУЛЇЕФаХЯЂЙ§диВЂдіМгЕчзгЩЬЮёЙЋЫОЕФЯњЪлЁЃ ЬиБ№ЪЧдкЭЦМіЯЕЭГСьгђЃЌЦРЗждЄВтЪЧвЛИіЛљБОЮЪЬтЃЌздNet?ix Prize Competition1ЕФГЩЙІвдРДБИЪмЙизЂЁЃ ИјЖЈРњЪЗЦРЗжЃЌашвЊЦРЗждЄВтРДдЄВтгУЛЇЖджЎЧАЮДЦРЙРЕФЮяЦЗЕФЦРЗжЁЃвўвђзгФЃаЭ [5] [9] [10] БэЯжСМКУЃЌЙуЗКгІгУгкЦРЗждЄВтЮЪЬтЁЃетаЉФЃаЭЕФжївЊФПБъЪЧЮЊгУЛЇКЭЮяЦЗбЇЯАЕЭЮЌБэЪОЃЌЗДгГЫќУЧЕФНгНќГЬЖШЁЃSalakhutdinovЕШ [9] ДгИХТЪЕФНЧЖШГіЗЂЃЌЪзЯШЬсГіСЫвђзгФЃаЭЁЃГ§СЫЛљБОЕФвўвђзгФЃаЭЃЌKorenЕШШЫ[4] в§ШыСЫЖюЭтЕФгУЛЇКЭЮяЦРЗжЦЋвЦгУРДЬсИпдЄВтадФмЁЃ ШчНёЃЌгУЛЇКЭЩЬЦЗжЎМфЕФдкЯпЛЅЖЏБфЕУЖрбљЛЏЃЌЦфжаАќРЈГ§СЫЦРЗжжЎЭтЕФЮФБОЦРТлЁЃ ИљОн[10] ЃЌЦРТлаХЯЂзїЮЊвЛжжИЈжњаХЯЂЕФЦРТлЖдгкЭЦМіЯЕЭГЪЧгаМлжЕЕФЁЃ
ЛљгкЦРТлЕФЦРЗждЄВтЮЪЬтдквўвђзгжїЬтЃЈHFTЃЉ[7] ЕФФЃаЭжаЕУЕНКмКУЕФВћЪіЃЌжМдкРћгУРДздЦеБщДцдкЕФЦРТлЕФжЊЪЖРДЬсИпЦРЗждЄВтадФмЁЃгЩгкЦРТлПЩвдБЛЪгЮЊгУЛЇКЭЮяЦЗжЎМфЕФНЛЛЅЃЌвђДЫЫќУЧАќКЌгыгУЛЇКЭЮяЦЗЧБдквђЫиЯрЙиЕФаХЯЂЁЃФПЧАИУЮЪЬтЕФНтОіЗНАИПЩЗжЮЊСНжжЗНЪНЁЃвЛжжЪЧЪЙгУжїЬтФЃаЭИљОнЫћУЧЕФЦРТлЮФБО[7] [1] [2] [6] [11] ЮЊгУЛЇКЭЮяЦЗЩњГЩвўвђзгЁЃСэвЛжжЗНЗЈЪЧРћгУаТЕФЩёОЭјТчЖдЦРТлЮФБОжаЕФЕЅДЪЛђОфзгЕФгявхБэЪОНјааНЈФЃ[12] [14] ЁЃШЛЖјЃЌФПЧАДѓЖрЪ§ЛљгкЦРТлЕФФЃаЭжївЊВржигкбЇЯАЦРТлЕФгявхБэЪОЃЌКіТдЦРТлжаЕФЪБађЬиеїЃЌетЪЧЮвУЧТлЮФвЊНтОіЕФФкШнЁЃСэЭтЃЌЛљгкЦРТлЕФЦРЗждЄВтШЮЮёгыЧщаїЗжРрЕФШЮЮёВЛЭЌЁЃЮвУЧЕФШЮЮёжиЕуЪЧРћгУгУЛЇЕФРњЪЗЦРТлКЭЯргІЕФЦРЗжРДдЄВтЫћУЧжЎЧАЮДЙКТђЕФЦРЗжЁЃЕЋЪЧЃЌЧщИаЗжРрШЮЮёЪЧЖдЕБЧАЕФЮФБОЦРТлЧщаїНјааЗжРрЃЌЦфбЇЯАгявхБэЪОЕФЗНЗЈПЩвддкЮвУЧШЮЮёЕФЛљБОзщГЩВПЗжжав§гУЁЃ
ЮЊСЫЭЛГіЮвУЧЬсГіЕФФЃаЭЕФЧјБ№ЃЌЮвУЧЪзЯШНщЩмСЫМђвЊПМТЧЪБМфЮЌЖШЕФЪБађФЃаЭЁЃ гЩгкгУЛЇЕФЦЋКУЧуЯђгкЫцЪБМфБфЛЏВЂЧвЪмЕНаТЩЬЦЗЕФгАЯьЃЌвђДЫЪБађНЛЛЅРњЪЗзїЮЊвЛжжРрЫЦгк[10] жаЬсЕНЕФЦРТлЕФИЈжњаХЯЂЃЌПЩФмГЩЮЊдЄВтЦРМЖЕФживЊвђЫиЁЃ Г§СЫгУЛЇжЎЭтЃЌЯюФПЕФЬиеївВПЩФмЪмЕНзюНќЦРЗжгУЛЇЕФгАЯьЁЃ ШЛЖјЃЌЛљгкОиеѓЗжНт[15] ЛђЩюЖШЩёОЭјТч[13] ЕФЯжгаЗНЗЈжївЊгУгкЭкОђЦРЗжЕФЪБМфаХЯЂЃЌвђДЫЫќУЧВЛФмжБНггУгкЖдЦРТлжаЕФЪБађЬиеїНјааНЈФЃЁЃ
ДгЩЯУцЕФНщЩмжаЃЌЮвУЧЗЂЯжДѓЖрЪ§ЕБЧАЛљгкЦРТлЕФФЃаЭКЭађСаФЃаЭжЛПМТЧЦРТлаХЯЂЛђЪБМфаХЯЂЁЃ ЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧЬсГіСЫвЛжжаТгБЕФЛљгкЦРТлЕФЫГађФЃаЭЃЈHRSMЃЉРДВЖзНгУЛЇКЭЮяЦЗЕФНЛЛЅаХЯЂЁЃ вўВидкЮФБОЦРТлжаЕФЪБађаХЯЂПЩвдАяжњЮвУЧНвЪОгУЛЇЦЋКУКЭЮяЦЗЬиеїЕФЖЏЬЌБфЛЏЁЃ дкЮвУЧЬсГіЕФФЃаЭжаЭЌЪБВЖЛёетСНжжИЈжњаХЯЂЃЌМДЦРТлКЭЪБМфадЁЃ ДЫЭтЃЌгЩвўвђзгФЃаЭЩњГЩЕФгУЛЇКЭЯюФПЕФЙЬЖЈвўвђзгПЩФмдкКмГЄвЛЖЮЪБМфФкБЃГжЙЬгаЬиеїЁЃ ЮвУЧНЋетаЉОВжЙзДЬЌгыгУЛЇКЭЮяЦЗМЏГЩдквЛЦ№ЁЃДгЦРТлађСажабЇЯАЖЏЬЌзДЬЌвдЙВЭЌдЄВтЦРЗжЁЃ ЮвУЧЬсГіЕФФЃаЭгыЦРЗждЄВтШЮЮёжаЕФДњБэадФЃаЭжЎМфЕФЙиМќВювьЃЌАќРЈPMF [9] ЃЌBMF [4] ЃЌHFT [7] ЃЌDeepCoNN [14] ЃЌRRN[13] ЃЌзмНсдкБэ1жаЁЃ
Бэ 1ЃКВЛЭЌФЃаЭЕФЖдБШ

змжЎЃЌЮвУЧЙЄзїЕФжївЊЙБЯзШчЯТЃК
ЮвУЧЬсГіСЫвЛжжЛљгкЦРТлЕФЦРЗжЪБађдЄВтФЃаЭЃЌЭЈЙ§РћгУЦфРњЪЗЦРТлЃЌПЩвдВЖзНгУЛЇКЭЯюФПЕФЪБМфЖЏЬЌЃЛ
ЮвУЧНЋгУЛЇКЭЯюФПЕФЙЬгавўзДЬЌБэЪОгыЖЏЬЌзДЬЌЯрНсКЯЃЌДгЪБађЮФБОађСабЇЯАДгЖјФмЙЛЙВЭЌгыВтЦРЗжЃЛ
ЖдецЪЕЙЋЙВЪ§ОнМЏНјааЕФДѓСПЪЕбщБэУїЃЌЮвУЧЕФФЃаЭгХгкзюЯШНјЕФЛљзМФЃаЭЃЌВЂЧвУїЯдЪмвцгкВЩгУЪБађЦРТлФкШнЁЃ
2 ЧАЦкзМБИЃК
2.1 ЮЪЬтЖЈвх
МйЩшгУЛЇМЏКЭЯюМЏЗжБ№БэЪОЮЊUКЭV. ЮвУЧНјвЛВННЋЦРМЖОиеѓБэЪОЮЊRЃЌНЋЦРТлЮФБОЕФМЏКЯБэЪОЮЊD.ЖдгкuЁЪUКЭvЁЪVЃЌruvЁЪRБэЪОгУЛЇuЗжХфИјЯюФПvЕФЦРМЖжЕЃЌЖјduvЁЪDБэЪО гЩгУЛЇuаДШыЯюФПvЕФЯргІЦРТлЮФБОЁЃИјЖЈРњЪЗвбжЊЦРМЖКЭЦРТлЃЌЛљгкИіадЛЏЦРТлЕФЦРЗждЄВтЕФЮЪЬтЪЧдЄВтЦРЗжОиеѓRжаЕФШБЪЇЦРЗжжЕЁЃ
2.2 ЦЋЯђОиеѓЗжНтЃЈBMFЃЉ
ЮЊСЫбщжЄЪБађаХЯЂКЭЦРТлЮФБОЕФЙЄзїдРэЃЌЮвУЧЪзЯШМђвЊНщЩмвЛИіОВЬЌФЃаЭЁЃ ЦЋЯђОиеѓЗжНтЃЈBMFЃЉ[4] ЪЧЭЦМіЯЕЭГЕФаЭЌЙ§ТЫФЃаЭЁЃ ЫќЪЧдкИїжжГЁОАжагІгУЕФОЕфЕФЛљзМФЃаЭЁЃ гУЛЇuЖдЯюФПvЕФдЄВтЦРМЖ![]() ПЩвдМЦЫуЮЊЃК
ПЩвдМЦЫуЮЊЃК

ЦфжаЃЌPu КЭqvЮЊгУЛЇгыЮяЦЗЕФОВЬЌвўзДЬЌБэЪОЃЌbuКЭbuЮЊЫћУЧЕФЦЋвЦСПЃЌgвЛАуЪЧЦРЗжЕФЦНОљЗжЁЃ
3 ФЃаЭПђМм
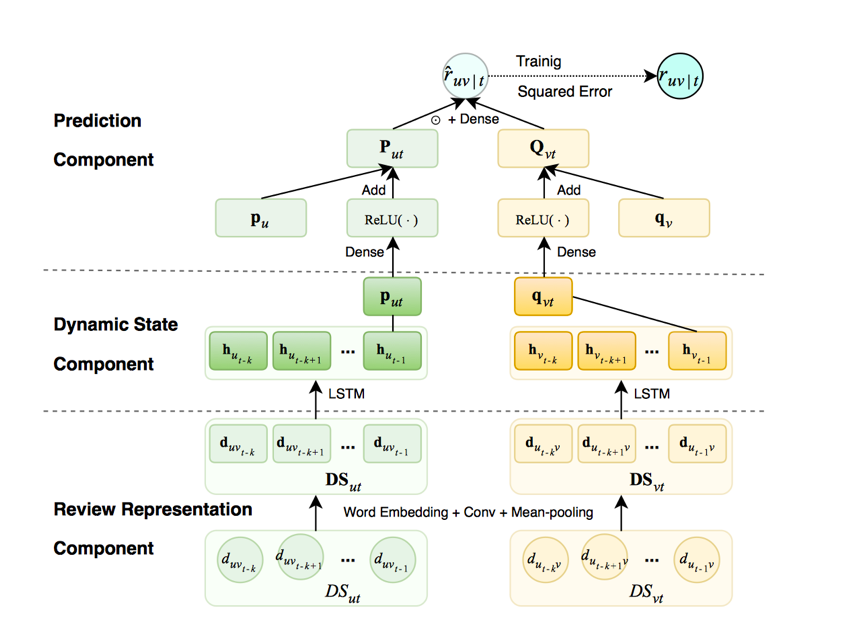
ЭМ 1ФЃаЭПђМм
дкБОЮФжаЃЌЮвУЧЬсГіСЫвЛжжаТЕФЛљгкЦРТлЕФЪБађФЃаЭЃЈHRSMЃЉЁЃ ЮвУЧЬсГіЕФФЃаЭЕФзмЬхПђМмШчЭМ1ЫљЪОЁЃОпЬхЖјбдЃЌЮвУЧЪзЯШЭЈЙ§ж№ВННЋЦфФкВПЕЅДЪЬсЙЉИјCNNРДЛёЕУУПИіЦРТлЕФБэЪОЁЃ ШЛКѓЪЙгУLSTM [3] ЖдЦРТлађСаЕФЪБађЪєадНјааНЈФЃЃЌДгЖјЛёЕУгУЛЇКЭЮяЦЗЕФЖЏЬЌзДЬЌЁЃ ЮвУЧНјвЛВННЋЖЏЬЌзДЬЌгыгУЛЇКЭЮяЦЗЙЬЖЈвўЯђСПЯрНсКЯЃЌвдНјаазюжеЦРЗждЄВтЁЃ
3.1 ЦРТлБэЪО
жкЫљжмжЊЃЌЦРТлАќКЌЗсИЛЕФаХЯЂЁЃ ЦРТлжаЕФЧщИаДЪгяЃЌР§Шче§УцЛђИКУцДЪгяЃЌБэЪОгУЛЇЖдЮяЦЗЫљЯдЪОЕФЦЋКУЁЃ дкЬНЫїЦРТлжЎМфЕФЪБађЙиЯЕжЎЧАЃЌЮвУЧЪзЯШашвЊЛёЕУУПИіИјЖЈЦРТлЕФБэЪОЁЃ УПИіЦРТл![]() гЩвЛЖЈЪ§СПЕФЕЅДЪзщГЩЃЌЦфжаУПИіЕЅДЪwЁЪWРДздДЪЛуБэWЁЃдкНјаагыДІРэЕФЪБКђЃЌПЩвддкЦРТлЬюГфСуБЃГжОфЪНЕШГЄадЃЌУПИіЦРТлЖМПЩвдзЊЛЛЮЊЙЬЖЈГЄЖШЕФОиеѓЃЌУПИіЕЅДЪЖМгадЪМЕФБэЪОЁЃ дкЭЈЙ§EmbeddingВузЊЛЛжЎКѓЃЌЦРТлФкЕФУПИіЕЅДЪБЛБэЪОЮЊЧЖШыwЁЃ ЖдгкУПИіЦРТлЃЌЮвУЧВЩгУОэЛ§ВуРДЬсШЁОжВПЬиеїЃЌШЛКѓВЩгУОљжЕГиРДЖдЦфФкВПДЪНјааЦНОљОжВПЬиеїЁЃ зюКѓЃЌЪфГіЯђСПdБЛЪгЮЊЕБЧАЪфШыЦРТлЕФБэЪОЁЃ
гЩвЛЖЈЪ§СПЕФЕЅДЪзщГЩЃЌЦфжаУПИіЕЅДЪwЁЪWРДздДЪЛуБэWЁЃдкНјаагыДІРэЕФЪБКђЃЌПЩвддкЦРТлЬюГфСуБЃГжОфЪНЕШГЄадЃЌУПИіЦРТлЖМПЩвдзЊЛЛЮЊЙЬЖЈГЄЖШЕФОиеѓЃЌУПИіЕЅДЪЖМгадЪМЕФБэЪОЁЃ дкЭЈЙ§EmbeddingВузЊЛЛжЎКѓЃЌЦРТлФкЕФУПИіЕЅДЪБЛБэЪОЮЊЧЖШыwЁЃ ЖдгкУПИіЦРТлЃЌЮвУЧВЩгУОэЛ§ВуРДЬсШЁОжВПЬиеїЃЌШЛКѓВЩгУОљжЕГиРДЖдЦфФкВПДЪНјааЦНОљОжВПЬиеїЁЃ зюКѓЃЌЪфГіЯђСПdБЛЪгЮЊЕБЧАЪфШыЦРТлЕФБэЪОЁЃ
ЩЯЪіЙ§ГЬПЩвдБэЪіШчЯТЃК
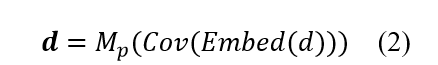
ЦфжаЃЌEmbedБэЪОДЪЧЖШыЙ§ГЬЃЌCovБэЪООэЛ§ЩёОЭјТчЃЌMpБэЪОЦНОљГиЛЏВуЁЃ
ЮвУЧзЂвтЕНЃЌЛЙПЩвдгІгУLSTMЭМВуРДбЇЯАЯрЙиЙЄзїВПЗжжаЬсМАЕФЦРТлБэЪОЁЃ ЕЋЪЧдквдЯТЙ§ГЬжаЃЌЮвУЧЪЙгУСэвЛИіLSTMВуРДЖдВщПДађСаНјааНЈФЃЁЃ гЩетСНжжLSTMВузщГЩЕФЧЖЬзНсЙЙНЋЪЙећИіФЃаЭЙ§гкИДдгЃЌдкЪдЭМЪдбщжаБэЯжСМКУЁЃ вђДЫЃЌЮвУЧбЁдёCNNВузїЮЊЬцДњЗНАИЁЃ
3.2 ЛљгкЦРТлЕФгУЛЇгыЮяЦЗЕФвўзДЬЌбЇЯА
вђЮЊвдРрЫЦЕФЗНЪНбЇЯАЛљгкЫћУЧЕФЦРТлРДбЇЯАгУЛЇКЭЮяЦЗЕФЖЏЬЌзДЬЌБэЪОЕФЙ§ГЬЃЌЫљвдЮвУЧНіНіЫЕУїШчКЮЮЊгУЛЇИќЯъЯИЕиНЈСЂЛљгкЦРТлЕФзДЬЌЕФФЃаЭЁЃ ЮЊСЫФЃФтгУЛЇЕФЖЏЬЌзДЬЌЃЌЮвУЧгІИУПМТЧЦРТлЕФЪБМфДСЁЃ
МйЩшЕБЧАгУЛЇвбОгыnИіЮяЦЗНјааСЫНЛЛЅЁЃдкАДЪБМфДСХХађНЛЛЅКѓЃЌЮвУЧЕУЕНвЛИіЯюФПБрКХађСаЃЌБэЪОЮЊ![]() КЭвЛИіБэЪОЮЊЦРТлађСа
КЭвЛИіБэЪОЮЊЦРТлађСа![]() ЁЃгывдЭљЕФбаОПФкШнВЛЭЌЕФЪЧ: ЮвУЧИљОнЦРТлађСа
ЁЃгывдЭљЕФбаОПФкШнВЛЭЌЕФЪЧ: ЮвУЧИљОнЦРТлађСа![]() ЖјВЛЪЧЮяЦЗађСа
ЖјВЛЪЧЮяЦЗађСа![]() РДФЃФтгУЛЇгУЛЇuЕФЖЏЬЌБфЛЏЃЌвђЮЊЦРТлБэЪОЕБЧАгУЛЇuКЭЦфЫћЯюФПжЎМфЕФЯрЛЅЙиЯЕЃЌВЂЧвЧуЯђгкАќКЌгУЛЇЕФЧуЯђвдМАЮяЦЗЕФЬиеїЁЃЖдгкгУЛЇuвдМАЮяЦЗvдкЪБМфtЕФзДЬЌЃЌЫќУЧЕФЦРЗжБэЪОЮЊ
РДФЃФтгУЛЇгУЛЇuЕФЖЏЬЌБфЛЏЃЌвђЮЊЦРТлБэЪОЕБЧАгУЛЇuКЭЦфЫћЯюФПжЎМфЕФЯрЛЅЙиЯЕЃЌВЂЧвЧуЯђгкАќКЌгУЛЇЕФЧуЯђвдМАЮяЦЗЕФЬиеїЁЃЖдгкгУЛЇuвдМАЮяЦЗvдкЪБМфtЕФзДЬЌЃЌЫќУЧЕФЦРЗжБэЪОЮЊ![]() ЁЃ ЯдШЛЃЌ
ЁЃ ЯдШЛЃЌ![]() НігыtжЎЧАЕФЯрЛЅзїгУЯрЙиСЊЁЃ ЖдгкЦРЗж
НігыtжЎЧАЕФЯрЛЅзїгУЯрЙиСЊЁЃ ЖдгкЦРЗж![]() ЃЌгЩuжИЖЈЕФзюаТkИіЯрЛЅзїгУЃЈvБОЩэБЛХХГ§ЃЉгЩ
ЃЌгЩuжИЖЈЕФзюаТkИіЯрЛЅзїгУЃЈvБОЩэБЛХХГ§ЃЉгЩ![]() ЕФзгађСазщГЩЃЌБэЪОЮЊ
ЕФзгађСазщГЩЃЌБэЪОЮЊ![]() ЁЃдкОЙ§EmbedВуКѓЃЌЪБађЕФЦРТлаХЯЂБЛЧЖШыЕНЕЭЮЌЕФЯђСППеМфБэЪОЮЊ
ЁЃдкОЙ§EmbedВуКѓЃЌЪБађЕФЦРТлаХЯЂБЛЧЖШыЕНЕЭЮЌЕФЯђСППеМфБэЪОЮЊ![]() ЦфжаlБэЪОЦРТлЯђСПЕФЮЌЖШЃЌk БэЪОађСаГЄЖШЛђепДАПкЕФДѓаЁЁЃЕБЪБМфДАПкдкећИіЪБађађСа
ЦфжаlБэЪОЦРТлЯђСПЕФЮЌЖШЃЌk БэЪОађСаГЄЖШЛђепДАПкЕФДѓаЁЁЃЕБЪБМфДАПкдкећИіЪБађађСа![]() ЩЯБЃГжЛЌЖЏЪБЃЌЩњГЩЖрИі
ЩЯБЃГжЛЌЖЏЪБЃЌЩњГЩЖрИі![]() ЃЌЦфБЛЪгЮЊLSTMВуЕФЪфШыЪЕР§ЁЃ ЮЊСЫЪЙLSTMЕФЪфШыађСаОпгаЯрЭЌЕФГЄЖШЃЌЮвУЧМйЩшЕБЧАвЊдЄВтЕФУПИіЦРМЖУїШЗЕиРДздЦфзюаТЕФkИіЯрЛЅзїгУЁЃ ЖдгкОВЬЌФЃаЭЃЌЮвУЧЭЈЙ§ЙЋЪН1жаЫљЪОЕФОиеѓЗжНтРДЛёЕУгУЛЇКЭЯюФПЕФОВЬЌзДЬЌЁЃ ВЛЭЌгкжЎЧАЕФФЃаЭЃЌЖдгкЪБађФЃаЭЃЌЮвУЧгІгУLSTM [6]ДгЦфЦРТлађСажабЇЯАгУЛЇЕФЖЏЬЌзДЬЌЁЃ дкађСа
ЃЌЦфБЛЪгЮЊLSTMВуЕФЪфШыЪЕР§ЁЃ ЮЊСЫЪЙLSTMЕФЪфШыађСаОпгаЯрЭЌЕФГЄЖШЃЌЮвУЧМйЩшЕБЧАвЊдЄВтЕФУПИіЦРМЖУїШЗЕиРДздЦфзюаТЕФkИіЯрЛЅзїгУЁЃ ЖдгкОВЬЌФЃаЭЃЌЮвУЧЭЈЙ§ЙЋЪН1жаЫљЪОЕФОиеѓЗжНтРДЛёЕУгУЛЇКЭЯюФПЕФОВЬЌзДЬЌЁЃ ВЛЭЌгкжЎЧАЕФФЃаЭЃЌЖдгкЪБађФЃаЭЃЌЮвУЧгІгУLSTM [6]ДгЦфЦРТлађСажабЇЯАгУЛЇЕФЖЏЬЌзДЬЌЁЃ дкађСа![]() ЕФУПИіЪБМфВНжшtЃЌLSTMЕФвўВизДЬЌ
ЕФУПИіЪБМфВНжшtЃЌLSTMЕФвўВизДЬЌ![]() ЕФИќаТЛљгкЕБЧАЕФЦРТлБэЪО
ЕФИќаТЛљгкЕБЧАЕФЦРТлБэЪО![]() КЭЯШЧАвўВиЕФзДЬЌ
КЭЯШЧАвўВиЕФзДЬЌ![]() ЭЈЙ§ФГИіКЏЪ§fРДИќаТЁЃетжжЙиЯЕЪЧгУЙЋЪН3БэДяЕФЁЃ КЏЪ§fФкЕФШ§ИіУХЃЌМДЪфШыУХЃЌЭќМЧУХКЭЪфГіУХЃЌаЭЌПижЦаХЯЂШчКЮЭЈЙ§ађСаДЋВЅЁЃ вдетжжЗНЪНЃЌећИіЦРТлађСажаЕФУПИіЦРТлБЛвЛЦ№ПМТЧЃЌвђЮЊЕБвўВизДЬЌЭЈЙ§ађСаДЋВЅЪБЃЌЕБЧАЦРТлПЩвдгАЯьЫљгаКѓајЦРТлЁЃ ЕБЮвУЧНЋађСа
ЭЈЙ§ФГИіКЏЪ§fРДИќаТЁЃетжжЙиЯЕЪЧгУЙЋЪН3БэДяЕФЁЃ КЏЪ§fФкЕФШ§ИіУХЃЌМДЪфШыУХЃЌЭќМЧУХКЭЪфГіУХЃЌаЭЌПижЦаХЯЂШчКЮЭЈЙ§ађСаДЋВЅЁЃ вдетжжЗНЪНЃЌећИіЦРТлађСажаЕФУПИіЦРТлБЛвЛЦ№ПМТЧЃЌвђЮЊЕБвўВизДЬЌЭЈЙ§ађСаДЋВЅЪБЃЌЕБЧАЦРТлПЩвдгАЯьЫљгаКѓајЦРТлЁЃ ЕБЮвУЧНЋађСа![]() РЁЫЭЕНLSTMВуЪБЃЌзЊЛЛКЏЪ§fзмЙВНјааkДЮЁЃ ЮвУЧЛљгкЦфзюНќЕФЩѓВщађСаЛёЕУзюКѓвўВизДЬЌзїЮЊгУЛЇЖЏЬЌзДЬЌБэЪО
РЁЫЭЕНLSTMВуЪБЃЌзЊЛЛКЏЪ§fзмЙВНјааkДЮЁЃ ЮвУЧЛљгкЦфзюНќЕФЩѓВщађСаЛёЕУзюКѓвўВизДЬЌзїЮЊгУЛЇЖЏЬЌзДЬЌБэЪО![]() ,ЦфМЦЫуЗНЪНМћЙЋЪН4ЁЃ
,ЦфМЦЫуЗНЪНМћЙЋЪН4ЁЃ
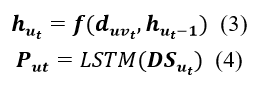
вдРрЫЦЕФЗНЪНЃЌЖдгкЕБЧАЮяЦЗvЃЌЮвУЧПЩвдЛёЕУгЩmИігУЛЇаДЕФЦРТлзщГЩЕФЦРТлађСа![]() ЃЌЖдгк
ЃЌЖдгк![]() ЃЌЮяЦЗ vвВгавЛИізгађСа
ЃЌЮяЦЗ vвВгавЛИізгађСа![]() ЁЃ ЧызЂвтЃЌИљОнЖЈвхЃЌОЁЙм
ЁЃ ЧызЂвтЃЌИљОнЖЈвхЃЌОЁЙм![]() КЭ
КЭ![]() ЕФГЄЖШЯрЭЌЃЌЕЋЫќУЧЕФЦРТлЮФЕЕВЂВЛЭъШЋЯрЭЌЁЃ дкгІгУLSTMВужЎКѓЃЌЮвУЧЛЙПЩвдЛљгкЦфВщПДађСаЛёЕУЯюvЕФЖЏЬЌ
ЕФГЄЖШЯрЭЌЃЌЕЋЫќУЧЕФЦРТлЮФЕЕВЂВЛЭъШЋЯрЭЌЁЃ дкгІгУLSTMВужЎКѓЃЌЮвУЧЛЙПЩвдЛљгкЦфВщПДађСаЛёЕУЯюvЕФЖЏЬЌ![]()
3.3 СЊКЯЦРЗждЄВт
ЕНФПЧАЮЊжЙЃЌЮвУЧвбОИљОнЫћУЧЕФЦРТлЫГађЛёЕУСЫгУЛЇКЭЮяЦЗЕФЖЏЬЌзДЬЌЁЃ жЕЕУзЂвтЕФЪЧЃЌгУЛЇКЭЮяЦЗЖМОпгавЛаЉВЛЫцЪБМфБфЛЏЕФЙЬгаЬиеїЁЃ Р§ШчЃЌгУЛЇОпгаЙЬЖЈЕФадБ№ЃЌВЂЧвЮяЦЗОпгаЮШЖЈЕФЭтЙлЁЃ вђДЫЃЌНЋЖЏЬЌКЭОВЬЌзДЬЌзщКЯдквЛЦ№НјааЦРЗждЄВтЪЧБивЊЕФЁЃ ОпЬхЖјбдЃЌЮвУЧв§ШыСЫвЛИіЭъШЋСЌНгВуЃЌЫќгЩвЛИіШЈжиОиеѓW1 ЃЈзїЮЊВЮЪ§АќРЈЕФЦЋВюЃЉКЭвЛИіReLUМЄЛюКЏЪ§[8] зщГЩЃЌвдНЋЖЏЬЌзДЬЌгГЩфЕНгыОВжЙзДЬЌЯрЭЌЕФЯђСППеМфЁЃ ЮвУЧгУШчЯТЕФЙЋЪНБэЪОгУЛЇКЭЮяЦЗЕФзюжезДЬЌЃК
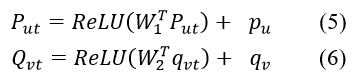
вдЧАЕФЙЄзїШчBMF [10]БШШчЙЋЪНЃЈ1ЃЉЃЌМђЕЅЕиНјааСНИівўЯђСПЕФЕуЛ§ЃЌвдВњЩњБъСПзїЮЊдЄВтЦРМЖЁЃ дкетжжЧщПіЯТЃЌгУЛЇКЭЯюФПЕФЧБдкЯђСПжаЕФВЛЭЌЮЌЖШБЛШЯЮЊЪЧЭЌЕШживЊЕФЁЃ ЮЊСЫИФНјЗКЛЏЃЌЪЙгУШЈжиОиеѓW_3НјааЯпадБфЛЛвдЧјЗжЯдзХЕФГпДчЁЃ зюКѓЃЌЮвУЧЕФФЃаЭВЩгУвдЯТЕШЪНРДдЄВтЦРМЖ![]() ЃК
ЃК
![]()
ЦфжаЃЌЁбБэЪОБэЪОСНИіЯђСПЕФдЊЫиГЫЛ§ЁЃ
3.4 Ы№ЪЇКЏЪ§
ЮвУЧЭЈЙ§зюаЁЛЏдЄВтКЭецЪЕдЄВтжЕжЎМфЕФе§дђЛЏЦНЗНЮѓВюЫ№ЪЇРДЖЈвхЮвУЧЕФФПБъКЏЪ§ЃК
![]()
ЦфжаReg(ІШ)БэЪОЖдФЃаЭВЮЪ§зіе§дђЛЏЁЃ
4 ЪЕбщ
дкБОНкжаЃЌЮвУЧНЋУшЪіЮвУЧЕФЪЕбщЩшжУВЂЖдЪЕбщНсЙћНјааЯъЯИЗжЮіЁЃ
4.1 Ъ§ОнМЏ
ЮвУЧЛљгкбЧТэбЗЪ§ОнМЏНјааЪЕбщЁЃЮвУЧЭЈГЃВЩгУСНИіДѓЕФзгМЏЃКЁАCDs and VinylЁБ (hereinafter called CD)ЃЈвдЯТГЦЮЊCDЃЉКЭЁАMovies and TVЁБЃЈвдЯТГЦЮЊЕчгАЃЉЁЃ CDЪ§ОнМЏгывєЦЕЪѕгяИќЯрЙиЃЌЖјMovieЪ§ОнМЏгыЪгЦЕЪѕгяИќЯрЙиЁЃ
ЮЊСЫЛёЕУзуЙЛЕФађСаЪЕР§ЃЌЮвУЧЩОГ§Ъ§ОнМЏЩЯГіЯжДЮЪ§Щйгк20ДЮЕФгУЛЇКЭЯюФПЁЃдкЙ§ТЫжЎКѓЃЌCDКЭЕчгАЪ§ОнМЏЩЯЕФзмНЛЛЅЃЈЦРЗжЛђЦРТлЃЉШдЗжБ№ГЌЙ§ЁМ10ЁН^5КЭ4ЁС105ЁЃЯъЯИеЊвЊЯдЪОдкБэ2жаЁЃгЩгкЮвУЧЕФађСаФЃаЭНЋРњЪЗЦРТлзїЮЊЪфШыЃЌЮЊСЫШЗБЃгыЦфЫћЙЬЖЈФЃаЭЕФЙЋЦНБШНЯЃЌВтЪдМЏЪЙгУУПИігУЛЇЕФзюКѓЦРЗжЙЙНЈЃЌЦфЫћЯюФПЙЙГЩбЕСЗМЏЁЃДЫЭтЃЌЮвУЧЪЙгУЯрЭЌЕФВпТдЖдбЕСЗМЏНјааЗжЧјвдЛёЕУбщжЄМЏЃЌИУбщжЄМЏгУгкЕїећГЌВЮЪ§ЁЃОљЗНЮѓВюЃЈMSEЃЉБЛгУзїгУгкВтСПФЃаЭадФмЕФЦРЙРЖШСПЁЃ
Бэ 2 Ъ§ОнМЏЛљБОаХЯЂ
![]()
4.2 ЛљзМФЃаЭ
ЮвУЧЕФФЃаЭHRSMгыШ§жжДЋЭГФЃаЭКЭШ§жжзюЯШНјЕФФЃаЭНјааСЫБШНЯЃЌАќРЈGloAvgЃЌPMFЃЌBMFЃЌHFTЃЌDeepCoNNКЭRRNЁЃ ОпЬхЖјбдЃЌЧАШ§жжЗНЗЈЪЙгУЪ§зжЦРМЖЃЌвдЯТСНжжЗНЗЈбЇЯАжїЬтФЃаЭЛђЩёОЭјТчЕФЦРТлБэЪОЃЌзюКѓвЛжжЗНЗЈЮќЪеЪБМфаХЯЂЁЃ Бэ1змНсСЫБШНЯЗНЗЈЃЈВЛАќРЈGloAvgЃЉЕФВЛЭЌжЎДІЁЃ
? GloAvgЁЃ GloAvgжЛЪЙгУЙЋЪНЃЈ1ЃЉжаЕФШЋОжвђзгgНјаадЄВтЁЃ
? PMF [9] ЁЃ PMFДгИХТЪЩЯМЦЫуОиеѓЗжНтЃЌУЛгаЦРЗжЦЋМћЁЃ
? BMF[4] ЁЃ BMFЪЙгУОиеѓЗжНтПМТЧЖюЭтЕФгУЛЇКЭЮяЦЗдкPMFЛљДЁЩЯЕФЦЋвЦЁЃ
? HFT [7] ЁЃ HFTЪЧНЋЦРТлгыЦРЗжЯрНсКЯЕФОЕфЗНЗЈЁЃ ЫќНЋОиеѓЗжНтгыжїЬтФЃаЭЯрНсКЯЃЌЧАепбЇЯАЧБвђЫиЃЌКѓепбЇЯАЦРТлВЮЪ§ЁЃ
? DeepCoNN [14] ЁЃ етЪЧЛљгкЦРТлЕФЦРЗждЄВтЮЪЬтЕФзюЯШНјЗНЗЈЃЌЦфЮоЗЈЧјЗжЕиНЋУПИігУЛЇЛђЯюФПЕФЫљгаЦРТлКЯВЂЕНаТЕФДѓЮФЕЕжаЃЌШЛКѓЪЙгУCNNРДбЇЯАЦРТлБэЪОЁЃ
? RRN [13] ЁЃ етЪЧгУгкЦРЗждЄВтЮЪЬтЕФзюЯШНјЕФЫГађФЃаЭЃЌЦфЪЙгУLSTMЭЈЙ§ЖдгУЛЇКЭЮяЦЗЕФБрКХађСаНЈФЃЖјВЛПМТЧЦРТлРДВЖЛёЖЏЬЌЁЃ
4.3 ГЌВЮЪ§ЩшжУ
ЮвУЧЕФФЃаЭдкKeras жаЪЕЯжЃЌетЪЧвЛИіИпМЖЩёОЭјТчAPIПђМмЁЃ ЮвУЧЪЙгУAdam РДгХЛЏЩёОЭјТчВЮЪ§ЁЃ ЮЊСЫЛёЕУЮвУЧФЃаЭКЭБШНЯЛљЯпЕФЮШНЁадФмЃЌЮвУЧгУВЛЭЌЕФжжзгГѕЪМЛЏУПИіФЃаЭЃЌВЂжиИДЪЕбщЮхДЮЃЌВЂЪЙгУЫќУЧЕФЦНОљНсЙћВЂЪЙгУЭјИёЫбЫїдкбщжЄМЏжаЕїећГЌВЮЪ§ЁЃ ЮвУЧетЪЧЯђСПЕФЮЌЖШЮЊ40 ЁЃ ЕЅДЪЕФЯђСПГЄЖШЪЧ100ЃЌLSTMЕФЮЌЖШДѓаЁЮЊ40 ЁЃ ХњСПДѓаЁЩшжУЮЊ256ЃЌбЇЯАТЪЩшжУЮЊ0.001ЁЃ ЮвУЧЪЙгУL2е§дђЛЏЃЌЦфВЮЪ§дкCDЪ§ОнМЏЩЯЩшжУЮЊ![]() ЃЌЖјдкMovieЪ§ОнМЏЩЯЩшжУЮЊ
ЃЌЖјдкMovieЪ§ОнМЏЩЯЩшжУЮЊ![]() ЁЃ
ЁЃ
4.4 НсЙћЗжЮі
СНИіЪ§ОнМЏЩЯЕФФЃаЭЕФадФмдкБэ3жаЁЃДгНсЙћжаЃЌЮвУЧЕУЕНвдЯТЙлВьЃКЃЈ1ЃЉGloAvgЪЧзюШѕЕФФЃаЭЃЌвђЮЊЫќЪЧвЛжжЗЧИіадЛЏЕФЗНЗЈЁЃгыPMFЯрБШЃЌBMFдкв§ШыЖюЭтЕФЦРЗжЦЋВюБэЯжИќКУЁЃ ЃЈ2ЃЉГ§СЫЪЙгУЦРЗжОиеѓЕФPMFКЭBMFжЎЭтЃЌвдЯТШ§жжЗНЗЈЃЈHFTЃЌDeepCoNNКЭRRNЃЉПМТЧЦфЫћаХЯЂЃЌШчЮФБОЦРТлЛђЪБађЪєадЃЌЭЈГЃЛёЕУИќКУЕФНсЙћЁЃ RRNдкMovieЪ§ОнМЏЩЯБэЯжВЛМбЃЌдвђПЩФмЪЧИУЪ§ОнМЏдкгУЛЇКЭЮяЦЗЕФађСажаОпгаНЯЯЁЪшЕФаХЯЂЁЃ ЃЈ3ЃЉRRNКЭDeepCoNNЗжБ№ЪЧCDКЭMovieЪ§ОнМЏЕФзюКУЕФаЇЙћЁЃЫќБэУїРћгУЩюЖШЩёОЭјТчЕФЗНЗЈЭЈГЃБШЦфЫћЛљзМФЃаЭБэЯжИќКУЁЃ ЃЈ4ЃЉЮвУЧЕФФЃаЭHRSMвЛжБгХгкСНИіЪ§ОнМЏЕФЫљгаЛљЯпЁЃ HRSMКЭRRNЖМЪЧПМТЧађСааХЯЂЕФЩюЖШЩёОЭјТчЃЌЕЋHRSMЕФНсЙћИќКУЃЌетБэУїЦРТлаХЯЂЪЧЖдЦРМЖЕФВЙГфЁЃЫфШЛHRSMКЭDeepCoNNЖМЪЧПМТЧЮФБОЦРТлЕФЩюЖШЩёОЭјТчЃЌЕЋЮвУЧЕФФЃаЭгЩгкРћгУСЫЪБађаХЯЂЖјБэЯжИќКУЁЃ

5 НсТл
дкБОЮФжаЃЌЮвУЧЬсГіСЫвЛжжаТЕФЪБађдЄВтФЃаЭЃЌгУгкЛљгкИіадЛЏЦРТлЕФЦРЗждЄВтЮЪЬтЁЃвдЧАЕФФЃаЭПМТЧЦРТлаХЯЂЛђЪБМфаХЯЂЃЌЕЋЪЧдкЮвУЧЬсГіЕФФЃаЭжаЭЌЪБВЖЛёСЫетСНжжаХЯЂЁЃ РћгУЩюЖШЩёОЭјТчЃЌЮвУЧЕФФЃаЭЭЈЙ§РћгУЦфЦРТлађСажаАќКЌЕФЪБађЪєадРДбЇЯАгУЛЇКЭЮяЦЗЕФЖЏЬЌЬиеїЁЃ ЪЕМЪЙЋЙВЪ§ОнМЏЕФЪЕбщНсЙћжЄУїСЫЮвУЧЬсГіЕФФЃаЭЕФгааЇадЃЌВЂжЄУївўВидкЦРТлжаЕФЪБађЪєаддкЦРЗждЄВтШЮЮёжаЦ№СЫКмДѓзїгУЁЃ
References:
[1] Bao, Y., Fang, H., Zhang, J.: Topicmf: Simultaneously exploiting ratings and re- views for recommendation. In: Proceedings of the Twenty-Eighth AAAI Conference on Arti?cial Intelligence. pp. 2ЈC8 (2014)
[2] Diao, Q., Qiu, M., Wu, C.Y., Smola, A.J., Jiang, J., Wang, C.: Jointly modeling aspects, ratings and sentiments for movie recommendation (jmars). In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 193ЈC202 (2014)
[3] Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735ЈC1780 (Nov 1997)
[4] Koren, Y., Bell, R., Volinsky, C.: Matrix factorization techniques for recommender systems. Computer 42(8), 30ЈC37 (Aug 2009)
[5] Lee, D.D., Seung, H.S.: Algorithms for non-negative matrix factorization. In: NIPS. pp. 535ЈC541 (2000)
[6] Ling, G., Lyu, M.R., King, I.: Ratings meet reviews, a combined approach to rec- ommend. In: Proceedings of the 8th ACM Conference on Recommender Systems. pp. 105ЈC112 (2014)
[7] McAuley, J., Leskovec, J.: Hidden factors and hidden topics: Understanding rat- ing dimensions with review text. In: Proceedings of the 7th ACM Conference on Recommender Systems. pp. 165ЈC172 (2013)
[8] Nair, V., Hinton, G.E.: Recti?ed linear units improve restricted boltzmann ma- chines. In: Proceedings of the 27th International Conference on International Con- ference on Machine Learning. pp. 807ЈC814 (2010)
[9] Salakhutdinov, R., Mnih, A.: Probabilistic matrix factorization. In: NIPS. pp. 1257ЈC1264 (2007)
[10] Shi, Y., Larson, M., Hanjalic, A.: Collaborative ?ltering beyond the user-item matrix: A survey of the state of the art and future challenges. ACM Comput. Surv. 47(1), 3:1ЈC3:45 (May 2014)
[11] Tan, Y., Zhang, M., Liu, Y., Ma, S.: Rating-boosted latent topics: Understanding users and items with ratings and reviews. In: IJCAI. pp. 2640ЈC2646 (2016)
[12] Wang, H., Wang, N., Yeung, D.Y.: Collaborative deep learning for recommender systems. In: Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 1235ЈC1244 (2015)
[13] Wu, C.Y., Ahmed, A., Beutel, A., Smola, A.J., Jing, H.: Recurrent recommender networks. In: WSDM. pp. 495ЈC503 (2017)
[14] Zheng, L., Noroozi, V., Yu, P.S.: Joint deep modeling of users and items using reviews for recommendation. In: WSDM. pp. 425ЈC434 (2017)
[15] Koren, Y.: Collaborative ?ltering with temporal dynamics. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 447ЈC456 (2009)
ЗжЯэШУИќЖрШЫПДЕН 
ЭЦМідФЖС
ДЋУНЭЦМі
 @УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад
@УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ
ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
ЯрЙиаТЮХ
ПЭЛЇЖЫЯТди
ШЫУёШеБЈЩчИХПі | ЙигкШЫУёЭј | БЈЩчеаЦИ | еаЦИгЂВХ | ЙуИцЗўЮё | КЯзїМгУЫ | ЙЉИхЗўЮё | Ъ§ОнЗўЮё | ЭјеОЩљУї | ЭјеОТЩЪІ | аХЯЂБЃЛЄ | СЊЯЕЮвУЧ
ЗўЮёгЪЯфЃКkf@people.cn ЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-65363263 ОйБЈгЪЯфЃКjubao@people.cn
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170001 | діжЕЕчаХвЕЮёОгЊаэПЩжЄB1-20060139
ЙуВЅЕчЪгНкФПжЦзїОгЊаэПЩжЄЃЈЙуУНЃЉзжЕк172КХ | ЛЅСЊЭјвЉЦЗаХЯЂЗўЮёзЪИёжЄЪщЃЈОЉЃЉ-ЗЧОгЊад-2016-0098
аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0104065 | ЭјТчЮФЛЏОгЊаэПЩжЄ ОЉЭјЮФ[2020]5494-1075КХ | ЭјТчГіАцЗўЮёаэПЩжЄЃЈОЉЃЉзж121КХ | ОЉICPжЄ000006КХ | ОЉЙЋЭјАВБИ11000002000008КХ
ШЫ Уё Эј Ац ШЈ Ыљ га ЃЌЮД О Ъщ Уц Ък ШЈ Нћ жЙ ЪЙ гУ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЦРТл

-
ЙизЂ
ЮЂаХЮЂВЉПьЪж
 ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
 БЈЕРШЋЧђ ДЋВЅжаЙњ
БЈЕРШЋЧђ ДЋВЅжаЙњ
 ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
