




















數據新聞現存的問題與解決之道
——兼論人工智能的應用價值
來源:《新聞愛好者》
【摘要】依靠數據的採集、挖掘和展示所形成的數據新聞已經以其獨有的功能和價值在新聞傳播領域嶄露頭角。但是由於受大數據技術發展的限制,還存在一系列問題亟待解決。從人工智能背景下大數據方法的關鍵性改善入手,探討人工智能對於大數據技術在新聞傳播領域中的應用所能提供的關鍵性技術支撐,分析和預測數據新聞生產的三個重要環節(數據新聞、傳感器新聞和可視化新聞)的技術改善之道。
【關鍵詞】人工智能﹔大數據方法﹔數據新聞﹔數據價值挖掘
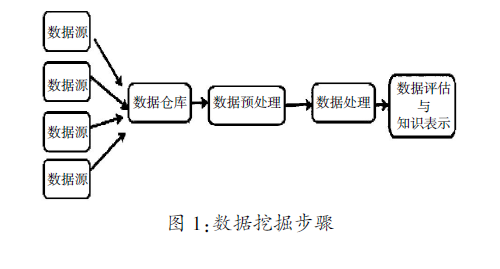
雖然,數據新聞已經在既往的實踐中有了長足的發展,但數據挖掘(Data mining)不足仍然是數據新聞發展必須面對的主要問題。數據挖掘指的是對數據庫中的數據進行探索的一個過程,是在海量數據中挖掘有效數據的重要技術。一般而言,數據挖掘在概念的層面分為三個階段:數據源數據的收集、對於數據源數據的處理以及最終的有效數據的表示。如圖1所示,數據挖掘主要通過四個步驟實現:源數據的收集階段、數據預處理階段、數據處理階段、數據評估以及知識表示階段[1]。具體來說,數據挖掘不足可以體現在以下三個方面:數據收集來源單一、數據處理能力有限和數據可視化表達程度有限。
一、現階段數據新聞的實操所存在的主要問題
(一)數據收集來源單一
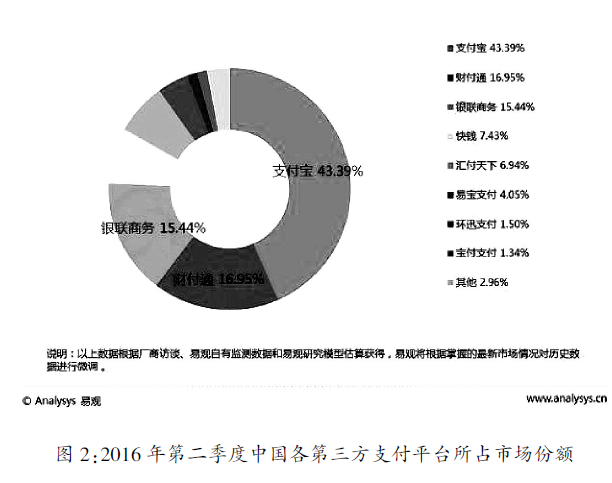
目前數據新聞面臨的首要問題就是缺乏可收集的數據信息源,或者數據庫信息過於單一,缺乏全面、結構性的數據源數據庫。從我國的情況來看,作為常用來源的商業數據庫中的數據,通常隻集中在某一個方面,其所能描述的用戶特征也只是片面和單一角度的認識。騰訊作為目前擁有最大即時通信工具的互聯網巨頭公司,掌握著大量用戶的社交關系數據,雖然通過微信線上支付(紅包)的功能,佔據了一定移動支付的市場,但比起支付寶(阿裡巴巴旗下的個人第三方支付平台)來說,騰訊對於用戶消費習慣和財務狀況的洞察和了解又遠不及后者。圖2是2016年第二季度的第三方互聯網支付市場交易份額,財付通(騰訊在線支付平台)雖然僅次於支付寶佔據了移動支付市場的第二位,但仍然無法與支付寶等量齊觀。從整體的數據庫類型的情況看是這樣,落實到具體的依靠數據挖掘實現個性化新聞生產的實踐中時,依然面對著信息來源單一的挑戰。
以今日頭條為國內個性化推送新聞的媒體為例,作為國內第一個個性新聞化推送新聞的產品類實踐者,今日頭條自2012年創建后,到2016年8月,已經擁有裝機用戶超過5.5億,日活躍人數超過6000萬。從其CEO對今日頭條有關用戶的數據信息來源的介紹來看,主要是三個方面:第一,今日頭條通過對用戶的行為,如點擊、停留、評論、轉發等數據的搜集和聚合分析,獲得用戶對新聞信息的個人喜好和需求的推算。第二,根據用戶所處的環境特征,上網環境是Wi-Fi還是付費流量、GPS所在地,是在常駐地還是旅游,是白天還是晚上等獲得用戶地理方面的數據信息。第三,基於用戶使用社交網絡賬號關聯登錄后,系統對於用戶社交圈和社交關系的分析,來得到關於用戶更清楚的社會化畫像,從職業身份或共同愛好入手計算用戶的興趣和需求。最后,系統通過把用戶行為、地理、社交三方面特征組合,利用算法綜合實現對用戶偏好和個性需要的挖掘。
但是,伴隨著個性化推送新聞的發展,也出現了“信息繭房”這種對現代人接收信息弊大於利的問題。有學者認為出現“信息繭房”的主要原因是,在互聯網時代,人們可以完全根據自己的愛好定制信息,從海量信息中隨意選擇自己關注的話題,久而久之,這種“個人日報”式的信息選擇行為會導致網絡繭房的出現。當商業信息服務利用個人定制的需求開始為個人提供個性化新聞時,人們會不自覺地失去了解不同事物的能力和接觸機會,深陷個人“信息繭房”之中。減輕“信息繭房”負面影響的方法首先是要提高算法對個人信息需求的構面了解,不但要滿足受眾顯性的,比如根據行為特征收集到的需求,還要結合其社交圈子,綜合改善個性化推送新聞對用戶需求的完整定義和把握,盡可能避免越推送越窄,越推送越偏的現象。
(二)數據處理能力有限
除了數據來源單一以外,數據新聞目前存在的第二個問題是,處理數據能力有限。而數據處理和分析能力是決定數據挖掘的關鍵環節。目前,我們所使用的數據處理工具和算法都還比較傳統,不適用大數據規模大、體量大的特點。祝建華教授說過,雖然大數據正在發生,但是我們對大數據的了解、處理能力還處在早期階段。這就勢必會影響數據新聞未來的發展。有學者認為成熟的數據處理技術涉及三個方面:存儲、提取和統計分析[2]。
目前,在存儲方面,我們計算機的存儲水平還是遠遠跟不上大數據的規模,分析數據前先要把數據讀到內存裡,而現在功能比較強大的計算機內存也遠遠滿足不了一個大型網站一天所產生的數據,這樣一來,這個過程就需要耗費大量的時間,影響數據處理速度[3]。根據2014年萬璞和王麗莎的總結,目前常見的分析數據的算法和模型有:①傳統統計方法:抽樣技術、多元統計分析和統計預測方法等。②決策樹:它利用一系列規則劃分,建立樹狀圖,用樹形結構來表示決策集合,可用於分類和預測,常用的算法有CART、CHAID、ID3、C4.5、C5.0等。③人工神經網絡:它模擬人的神經元功能,從結構上模仿生物神經網絡,經過輸入層、隱藏層、輸出層等,對數據進行調整、計算,最后得到結果,是一種通過訓練來學習的非線性預測模型,它可以完成分類、聚類、特征挖掘、回歸分析等多種數據挖掘任務。④遺傳算法:它是基於自然進化理論,在生物進化概念的基礎上設計的一種優化技術,它包括基因組合、交叉、變異和自然選擇等一系列過程,通過這些過程以達到優化的目的,是模擬基因聯合、突變、選擇等過程的一種優化技術。⑤關聯規則挖掘算法:關聯規則是描述數據之間存在關系的規則,形式為“A1ΛA2Λ…ΛAn→B1ΛB2Λ…ΛBn,一般分為兩個步驟:第一步,求出頻繁數據項集﹔第二步,用頻繁數據項集產生關聯規則。⑥最近鄰技術:這種技術通過已辨別歷史記錄的組合來辨別新的記錄,它可以用來做聚類和偏差分析[4]。
根據以上方法我們可以看出,現有的大數據分析技術都是基於計算機技術輔助統計技術實現的,除了遺傳算法和人工神經網絡外,都是經典的統計學算法,這些算法從19世紀七八十年代開始發展,到20世紀20年代初成型,距今已有80—120年的歷史[5]。雖然它們具有極高的穩定性且較為成熟,但它們是為分析普通數據設計的,對於大數據的特點來說,難免有不能契合的方面。
(三)數據可視化表達程度有限
數據挖掘的第三個環節是數據展示,即可視化表達數據處理結果。米爾科•勞倫茲於2010年在阿姆斯特丹召開的第一屆國際數據新聞圓桌會議中指出,數據新聞要以可視化的呈現數據並合成新聞故事為最后一個流程[6]。
數據可視化,在今天已經是一個固定的概念,指的是將數據信息的“量值”或“關系”等轉變為直觀的圖形。數據的可視化加工,目前主要包括將數值型、文本型的數據及其關系用視覺化手段,例如圖片、動畫等形式呈現出來[7]。
可視化新聞是隨著數據在新聞中的廣泛運用出現並發展起來的,它是以數據為核心、信息為支撐、可視化為基本載體的跨媒體新聞報道形式。可視化新聞的價值一方面取決於它的表現形式,另一方面取決於它對隱藏在宏觀、抽象數據背后的新聞故事性的展示。
然而,並不是所有的新聞事實都適合用數字或數字化的方式來表現。數據的可視化表達一方面受表達形式的局限,在告訴受眾“發生了什麼”的方面要強於告訴受眾“為什麼發生”。當數據的可視化僅限於告知事實時,可視化新聞或者數據可視化手段就隻能用於最基礎的新聞報道。像深度報道這一類的新聞,就不能很好地涉足。另一方面,即便可視化技術有所改善,也很難改變數據本身不擅長表現復雜因素和關系的特點。學者丁柏銓說過:“個人與個人或群體之間的關系多涉及政治、經濟、文化等各種因素,涉及現實中的利害關系和歷史上的恩恩怨怨。”[8]
 |
分享讓更多人看到 
推薦閱讀
傳媒推薦
 @媒體人,新聞報道別任性
@媒體人,新聞報道別任性 網站運營者 這些"紅線"不能踩!
網站運營者 這些"紅線"不能踩! 一圖縱覽中國網絡視聽行業
一圖縱覽中國網絡視聽行業
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
