




















ЛљгкЙиМќДЪЕФЮФБОФкШнЙ§ТЫЫуЗЈ
вЛЁЂбаОПЬтФПЯжЪЕвтвх
дкЛЅСЊЭјЬсЙЉЕФКЃСПЁЂХгдгЕФаХЯЂжаЃЌКмЖрИКЯрЙиЛђепЪЧМЋЩйЯрЙиЕФаХЯЂвдВЛЭЌЕФБэЯжаЮЪНЃЌДгВЛЭЌЕФЗНУцЖдШЫШКдьГЩЖОКІЛђепИЩШХЁЃвђДЫЃЌЖдЭјТчЗУЮЪНјааБивЊЕФЁЂгааЇЕФФкШнЙ§ТЫЪЧЗЧГЃживЊЕФЁЃФЧУДЛЅСЊЭјЕФЮФБОаХЯЂЙ§ТЫММЪѕОЭЪЧдкетжжЧщПіЯТЕЎЩњЕФЁЃЮФБОФкШнЙ§ТЫЪЧжИДгКЃСПЕФwebЮФБОжаЪЖБ№ГіЯрЙижИЪ§УЛгаДяЕНдЄЦкФПБъЕФЗЧЗЈЮФБОЃЌНЋЦфЦСБЮЁЃ
БОЮФдкЖдаХЯЂЙ§ТЫЯЕЭГЕФЬхЯЕНсЙЙКЭЮФБОЙ§ТЫЕФдаЭНјаабаОПЕФЛљДЁЩЯЃЌИјГіСЫвЛИіЛљгкЯђСППеМфФЃаЭЕФЮФБОЙ§ТЫТпМФЃаЭЁЃжаЮФЮФБОЕФЬиеїГщШЁКЭБэЪОЪЧжаЮФЮФБОЙ§ТЫЛљДЁЁЃЛёШЁжаЮФЮФБОЕФБэЪОашОЙ§ЗжДЪЁЂЭЃгУДЪДІРэЁЂЬиеїЯюГщШЁКЭЬиеїЯюШЈжиМЦЫуЕШЙ§ГЬЃЌБОЮФЖдетМИИіЙ§ГЬНјааСЫЯъЯИЕФбаОПВЂЬсГіСЫвЛжжЛљгкTF*IDFЕФЬиеїШЈжиМЦЫуЗНЗЈЁЃ
етбљШЫУёЭјЕФгУЛЇдкМьЫїЬиЖЈЕФаТЮХШШЕуФкШнЪБЃЌЮвУЧПЩвдИјГіИќЮЊзМШЗЕФЃЌОЙ§ЩИбЁЕФаТЮХФкШнЁЃЬсИпгУЛЇЕФдФЖСЬхбщЁЃ
ЖўЁЂЭјТчЮФБОаХЯЂЙ§ТЫФЃаЭ
2.1 ЮФБОЙ§ТЫЕФИХФюКЭШЮЮё
ЮФБОЙ§ТЫЪзЯШвЊИљОнгУЛЇЕФашЧѓНЈСЂГѕЪМЕФгУЛЇФЃАхЃЌРћгУаТЮХЭЦМіЕФаЭЌЙ§ТЫЫуЗЈЃЌВЂЭЈЙ§ЖдгУЛЇЕФфЏРРМЧТМЃЌРДЗжЮіГіЯргІЕФжїЬтЃЌФЧУДЮвУЧШЯЮЊетаЉжїЬтОЭЪЧЖСепЙиаФЕФаТЮХШШЕуЃЌВЂЧвШЯЮЊетОЭЪЧЖСепЕФаЫШЄАЎКУЁЃгУЛЇФЃАхНЈСЂКУжЎКѓХаЖЯСїжаЕФУПвЛЮФБОЪЧЗёЗћКЯгУЛЇашЧѓЃЌВЂНЋЗћКЯгУЛЇашЧѓЕФЮФБОЬсНЛИјгУЛЇЃЌдйгЩгУЛЇЖдЙ§ТЫНсЙћНјааЦРХаЃЌИљОнЦРХаНсЙћздЪЪгІЕиаоИФгУЛЇФЃАхЃЌвдИќКУЕиЗћКЯгУЛЇЕФашЧѓЁЃ
2000ФъЕФЕкОХДЮЮФБОМьЫїЛсвщ(TREC-9)ИјГіЕФ ЮФБОЙ§ТЫШЮЮёЕФЖЈвхЮЊ:ИјЖЈвЛИіжїЬтУшЪі(МДгУЛЇашЧѓ)ЃЌНЈСЂвЛИіФмДгЮФБОСїжаздЖЏбЁ дёзюЯрЙиЮФБОЕФЙ§ТЫФЃАх(Filtering Profile)ЃЌЫцзХЮФБОСїЕФж№НЅНјШыЃЌЙ§ТЫЯЕЭГздЖЏЕФ НгЪмЛђОмОјЮФБОЃЌВЂЕУЕНЮФБОЯрЙигыЗёЕФЗДРЁаХЯЂЃЌИљОнЗДРЁаХЯЂздЪЪгІЕФаое§Й§ТЫФЃАхЁЃ TREC ЬсГіСЫЮФБОЙ§ТЫЯюФПАќРЈЕФШ§ИізгШЮЮё :ЗжСї(Routing)ЁЂХњЙ§ТЫ(Batch Filtering)ЁЂздЪЪгІЙ§ТЫ(Adaptive Filtering)ЁЃ
ЃЈ1ЃЉЗжСїзгШЮЮё
ЗжСїзгШЮЮёЕФЖЈвхЮЊ:гУЛЇашЧѓЙЬЖЈЃЌЬсЙЉЖдгІгкИУгУЛЇашЧѓЕФбЕСЗЮФБОМЏЃЌДггУЛЇашЧѓЙЙдьВщбЏгяОфРДВщбЏВтЪдЮФБОМЏЁЃ
ЃЈ2ЃЉХњЙ§ТЫзгШЮЮё
ХњЙ§ТЫзгШЮЮёКЭЗжСїзгШЮЮёКмРрЫЦЃЌЦфЖЈвхЮЊ:гУЛЇашЧѓЙЬЖЈЃЌЬсЙЉЖдгІгкИУгУЛЇашЧѓЕФбЕСЗЮФБОМЏжаЕФЯрЙиЮФБОЃЌ ЙЙдьЙ§ТЫЯЕЭГЃЌ ЖдВтЪдЮФБОМЏжаЕФУПвЛЮФБОзїГіНгЪмЛђОмОјЕФОіВпЁЃЫќКЭЗжСїзгШЮЮёЕФВЛЭЌЕудкгкЗжСїШЮЮёвЊЧѓАДЯрЫЦЖШДгДѓЕНаЁЕФЫГађМьЫїГівЛХњЮФБОЃЌЖјХњЙ§ТЫдђвЊЧѓНЋЮФБОЗжГЩЯрЙиКЭВЛЯрЙиСНРрЁЃ
ЃЈ3ЃЉздЪЪгІЙ§ТЫзгШЮЮё
ЫќЪЧTRECИјГіЕФзюживЊЕФЁЂзюНгНќецЪЕЛЗОГЕФзгШЮЮёЃЌЫќвЊЧѓНіНіДгжїЬтУшЪіГіЗЂЃЌВЛЬсЙЉЛђжЛЬсЙЉКмЩйЕФбЕСЗЮФБОЃЌж№вЛХаЖЯЪфШыЮФБОСїжаЕФЮФБОЪЧЗёЯрЙиЃЌЖдЁАНгЪмЁБЕФЮФБОЃЌФмЕУЕНгУЛЇЕФЗДРЁаХЯЂЃЌгУвдздЪЪгІЕФаое§Й§ТЫФЃАхЃЌ ЖјЁАОмОјЁБЕФЮФБОЪЧВЛЬсЙЉЗДРЁаХЯЂЕФЁЃ
2.2 ЛљгкVSMЕФжаЮФЮФБОЙ§ТЫЕФТпМФЃаЭ
2.2.1 ЮФБОЙ§ТЫжаЕФЯђСППеМфФЃаЭ
ЯђСППеМфФЃаЭздЩЯЪРМЭ 60 ФъДњФЉгЩ Salton ЕШШЫЬсГіВЂГЩЙІЕФгІгУгкжјУћЕФ SMART(System for the Manipulation and Retrieval of Text)ЯЕЭГжЎКѓЃЌИУФЃаЭМАЦфЯрЙиЕФММЪѕвбОБЛЙуЗКЕФгІгУгкЮФБОДІРэСьгђ(ЮФБОМьЫїЁЂЮФБОЗжРрЁЂЮФБОЙ§ТЫ)[51]ЁЃ дкЮФБОЙ§ТЫ СьгђЃЌ VSMМКГЩЮЊзюМђБуИпаЇЕФЮФБОБэЪОФЃаЭжЎвЛЃЌ гІгУгкЮФБОЙ§ТЫСьгђЕФVSMЕФМИИіЛљБОИХФюШчЯТЃК
ЃЈ1ЃЉЮФБОD(Document)
ЗКжИЮФБОЛђЮФБОжаЕФвЛИіЦЌЖЮ(ШчЮФБОжаЕФБъЬтЁЂеЊвЊЁЂе§ЮФЕШ)ЁЃ
ЃЈ2ЃЉЬиеїЯюti(Term)
жИГіЯждкЮФБОжаФмЙЛДњБэЮФБОаджЪЕФЛљБОгябдЕЅЮЛ(ШчзжЁЂДЪЕШ)ЃЌ вВОЭЪЧЭЈГЃЫљжИЕФЙиМќзжЃЌ етбљвЛИіЮФБОDОЭПЩвдБэЪОЮЊD(t1ЃЌ t2ЃЌЁЃЌ tn)ЃЌ ЦфжаnОЭДњБэСЫЬиеїЯюЕФЪ§СПЁЃ
ЃЈ3ЃЉЬиеїЯюШЈжиwi(Term Weight)
wiжИЬиеїЯюtiФмЙЛДњБэЮФБОDФмСІЕФДѓаЁЃЌ ЬхЯжСЫЬиеїЯюдкЮФЕЕжаЕФживЊГЬЖШЁЃетбљЮФЕЕDОЭПЩвдБэЪОЮЊвЛИівдЬиеїЯюt1ЃЌt2ЃЌЁЃЌ tnЮЊзјБъЯЕЕФnЮЌПеМфжаЕФвЛИіЯђСПD(wlЃЌw2ЃЌЁЃЌ wn)ЃЌЦфжаwlЃЌw2ЃЌЁЃЌ wnЗжБ№ДњБэЮФЕЕDЕФЬиеїЯюt1ЃЌt2ЃЌЁЃЌ tnЕФЬиеїЯюШЈжиЁЃ
ЃЈ4ЃЉЯрЫЦЖШ(Similarity)
ЮФБОЙ§ТЫжагУЛЇФЃАхD1КЭСїШыЮФЕЕD2жЎМфЕФФкШнЯрЙиГЬЖШГЃГЃгУЫќУЧжЎМфЕФЯрЫЦЖШSim(D1ЃЌD2)РДКтСПЁЃЕБгУЛЇФЃАхPКЭЮФЕЕDОљвдnЮЌПеМфжаЕФЯђСПРДБэЪОЪБЃЌПЩвдНшжњЖўЯђСПМфЕФФГжжОрРыРДБэЪОЯрЫЦЖШЁЃЯрЫЦЖШМЦЫуЙЋЪНШчЃЈЪН2-1ЃЉ:
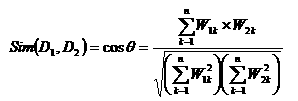
гУЛЇФЃАхPКЭСїШыЮФЕЕDСНепЕФФкЛ§дНДѓЛђепМаНЧгрЯвжЕдНДѓЫЕУїСїШыЮФЕЕгыгУЛЇФЃАхЕФЯрЫЦЖШдНИпЁЃМЦЫуЯрЫЦЖШЕФЖШСПжЕЃЌЭЌЩшЖЈЕФуажЕЯрБШНЯЃЌНЋЯрЫЦЖШаЁгкуажЕЕФЮФБОЙ§ТЫЕєЃЌНЋЯрЫЦЖШДѓгкФГвЛуажЕЕФЮФБОЬсЙЉИјгУЛЇЁЃгІгУVSMНјааЮФБОЙ§ТЫЕФгХЕудкгкЫќАбЮФБОФкШнМђЛЏЮЊЬиеїЯюМАЦфШЈжиЕФЯђСПБэЪОЃЌАб ЮФБОЙ§ТЫжагУЛЇФЃАхКЭСїШыЮФЕЕЕФЦЅХфДІРэМђЛЏЮЊгУЛЇФЃАхЯђСПКЭСїШыЮФБОЯђСПжЎМфЯрЫЦЖШЕФдЫЫуЃЌгУЪ§бЇМЦЫуЕФЗНЗЈРДНтОіздШЛгябдДІРэЮЪЬтЃЌвзгкРэНтКЭЪЕМЪВйзїЁЃвђДЫЃЌVSMдкЮФБОЙ§ТЫжаБЛЙуЗКгІгУЁЃ
2.2.2 жаЮФЮФБОЙ§ТЫЕФТпМФЃаЭ
гыгЂЮФЮФБОаХЯЂЯрБШЃЌжаЮФЮФБОаХЯЂдкзжЁЂДЪЁЂОфЁЂЦЊЕШЗНУцЖМгаздЩэЕФвЛаЉЬиЕуЃКжа ЮФЕФККзжжкЖр;жаЮФЕФДЪЖЈвхФЃК§ЁЂДЪРрКЌЛьЃЌЧаЗжБШНЯРЇФбЃЌЖјЧвОГЃГіЯжвЛДЪЖрвхЕФЯж Яѓ;жаЮФЕФОфзгОфаЭНЯЖрЃЌзщКЯаЮЪНЖрбљЃЌЗжЮіБШНЯРЇФбЃЛжаЮФЕФЦЊеТБШНЯМђНрЃЌЕЋЮФЬхжк ЖрЃЌКмФбНјаагявхЗжЮіЁЃ еыЖджаЮФЮФБОЕФетаЉЬиЕуЃЌ дкНјаажаЮФЮФБОЙ§ТЫЪБЃЌ гІИУдкгЂЮФЮФБОЙ§ТЫЕФЛљДЁЩЯдіМг вЛаЉеыЖджаЮФЬиадЕФЬиЪтДІРэЙ§ГЬЃЌ ШчжаЮФЮФБОЗжДЪЁЂ ЭЃгУДЪДІРэЁЂ ЮДЕЧТМДЪДІРэЁЂ ЮФБОЕФИХФюБъзЂЕШВНжшЁЃВЮПМаХЯЂЙ§ТЫЕФвЛАуФЃаЭЃЌНсКЯжаЮФЮФБОДІРэЕФЪЕМЪЧщПіЃЌЩшМЦЕФЛљгкWebЕФжаЮФЮФБОЙ§ТЫЕФТпМФЃаЭШчЭМ2-1ЫљЪО:
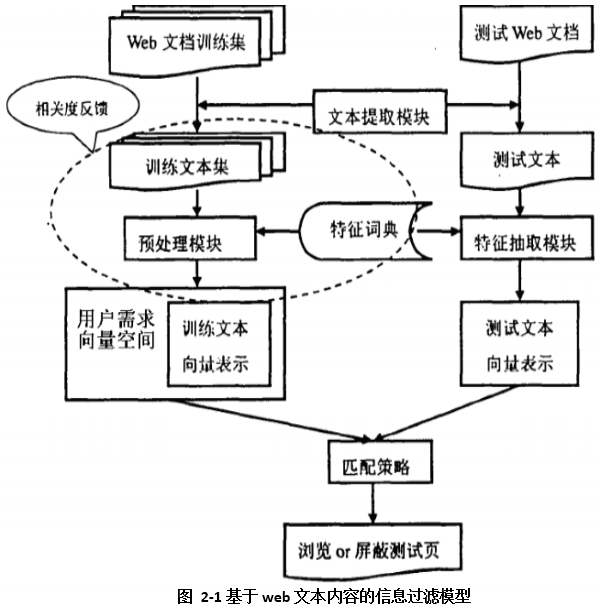
дк2-1ЛљгкWebЮФБОФкШнЕФаХЯЂЙ§ТЫТпМФЃаЭжаЃЌгУЛЇЖдЛёШЁWebЮФЕФЕЕбЕСЗМЏЃЌОЙ§ЮФБОЬсЁЂЗжДЪЁЂЙиМќзжЕФЬсШЁЁЂМЦЫуЙиМќзжШЈжиЕШвЛЯЕСаЙ§ГЬЃЌзюКѓЕУЕНвдЙиМќзжЮЊЛљДЁЕФЮФБОЯђСПМЏКЯЃЌетаЉЯђСПЕФМЏКЯОЭДњБэгУЛЇФЃаЭЁЃЖдгкВтЪдWebЮФЕЕзёбЭЌбљЕФЙ§ГЬАбWebЮФЕЕБэЪОГЩВтЪдЮФБОЯђСПЁЃ зюКѓЃЌВтЪдЮФБОЯђСПКЭбЕСЗЮФБОЯђСПАДЦЅХфВпТдНјааЦЅХфЃЌАДеевЛЖЈЕФуажЕОіЖЈЪЧЗёЙ§ТЫЁЃ
2.3гУЛЇаХЯЂЕФашЧѓФЃаЭ
дкЮФБОЙ§ТЫЯЕЭГжаЃЌгУЛЇаХЯЂашЧѓБэЪОЫљзіЕФЙЄзїЪЧдЫгУвЛЖЈЕФаХЯЂЛёШЁЗНЗЈРДЛёЕУгУ ЛЇГЄЦкЕФаХЯЂашЧѓЃЌ зМШЗЕФИјГігУЛЇаХЯЂашЧѓЕФТпМБэЪО(гУЛЇФЃАх)КЭЮяРэБэЪОЃЌ ВЂИљОнвЛ ЖЈЕФгУЛЇФЃАхгХЛЏКЭИќаТВпТдРДаоИФгУЛЇФЃАхЃЌвдИќКУЕФТњзугУЛЇашЧѓЃЌЬсИпЮФБОЙ§ТЫаЇТЪЁЃ
2.3.1 ЛёШЁгУЛЇаХЯЂашЧѓЕФЗНЪНКЭЗНЗЈ
аХЯЂЙ§ТЫЯЕЭГашвЊЭЈЙ§вЛЖЈЕФЗНЪНКЭЗНЗЈЛёЕУгУЛЇЕФаХЯЂашЧѓЁЃГЃгУЛёШЁгУЛЇаХЯЂашЧѓЕФЗНЪНЃКгУЛЇжБНгЪфШыЙиМќзжЗЈЁЂЙЬЖЈЮФЕЕМЏЦРМлЗЈЁЂЛљгкЪОР§ЮФБОЕФЗНЗЈЁЂгУЛЇааЮЊИњзйЗЈЕШЁЃ
1ЃЉгУЛЇжБНгЪфШыЙиМќзжЗЈгЩгУЛЇжБНгЪфШывЛаЉЙиМќзжЃЌвдБэДягУЛЇЕФаХЯЂашЧѓЁЃ
2ЃЉЙЬЖЈЮФЕЕМЏЦРМлЗЈЫљЮНЙЬЖЈЮФЕЕМЏ(FixedDocumentSet:FDS)ЪЧжИДгНќЫЦзмЬхЮФЕЕМЏжабЁдёзюгаДњБэадЕФ ЙЬЖЈзгМЏЃЌИУзгМЏФмЙЛГфЗжЗДгГФГвЛСьгђжаЕФИїжжгУЛЇЕФашЧѓЁЃИјЖЈвЛзщЦРМлЕШМЖЃЌШч0ЁЋ 5ЃЌШУгУЛЇАДеездМКЕФаЫШЄЖдвЛаЉЮФЕЕМЏНјааЦРМлЃЌШЛКѓИљОнЦРМлНсЙћДгетаЉЮФЕЕМЏжаЭкОђгУЛЇЕФаЫШЄЁЃ
3ЃЉЛљгкЪОР§ЮФБОЕФЗНЗЈЛљгкЪОР§ЮФБОЕФЗНЗЈЪЧЛљгкЯђСППеМфФЃаЭЕФЮФБОЙ§ТЫГЃгУЕФаХЯЂашЧѓЛёШЁЗНЗЈЁЃЫќвЊЧѓгУЛЇвдЪОР§ЮФБОЕФаЮЪНЬсГіздМКаХЯЂашЧѓЃЌЙ§ТЫЯЕЭГЭЈЙ§ЗжЮіЪОР§ЮФБОЕФДЪЛуБэДяЗНЪНЃЌГщШЁФмЙЛБэДягУЛЇаЫШЄЕФЬиеїЯюЃЌ ЙЙГЩФмЙЛБэДягУЛЇаХЯЂашЧѓЕФЛљБОЬиеїЯюМЏЃЌВЂдкЬиеїЯюМЏЕФЛљДЁЩЯаЮГЩвдЮФБОЬиеїЯђСПБэЪОЕФгУЛЇФЃАхЃЌетжжЗНЗЈФмЙЛИќгааЇЕФБэДягУЛЇЧБдкЕФаХЯЂашЧѓЁЃ
4ЃЉгУЛЇааЮЊИњзйЗЈгУЛЇааЮЊИњзйЗЈЪЧвЛжжВЩгУвўЪНЕФЗНЪНЛёШЁгУЛЇашЧѓЕФЗНЗЈЁЃгУЛЇааЮЊИњзйЗЈжївЊЭЈЙ§ИњзйгУЛЇЕФШШСДЁЂМЧТМгУЛЇОГЃЗУЮЪЕФеОЕуЛђфЏРРРњЪЗЃЌЗжЮіМЧТМгУЛЇЕФааЮЊКЭбЁдёЧуЯђЃЌвўадЕиЛёШЁЖдгУЛЇЕФашЧѓУшЪіЃЌвдШЗЖЈгУЛЇЕФаЫШЄКЭЦЋКУЁЃдкЪЕМЪжаЃЌГЃВЩгУжЧФм AgentММЪѕРДЪЕЯжгУЛЇааЮЊИњзйЁЃ
2.3.2 гУЛЇаХЯЂашЧѓФЃАхБэЪОЗНЗЈ
гУЛЇашЧѓФЃаЭЕФЙЙНЈЪЧЮФБОаХЯЂЙ§ТЫжавЛИіЛљБОЕФзгШЮЮёЁЃВЩгУвЛЖЈЕФЗНЪНКЭЗНЗЈЛёШЁ гУЛЇаХЯЂашЧѓКѓЃЌ гІИУИјГігУЛЇаХЯЂашЧѓЕФБэЪОЁЃ
гУЛЇаХЯЂашЧѓЕФБэЪОЗжЮЊТпМБэЪОКЭЮяРэ БэЪОЁЃ гУЛЇаХЯЂашЧѓЕФТпМБэЪОЪЧжИгУЛЇаХЯЂашЧѓЕФЭтВПБэЪОаЮЪНЃЌГЦЮЊгУЛЇФЃАх(User Profile)ЃЌМђГЦЮЊФЃАхЁЃ
ЛљгкЯђСППеМфФЃаЭЕФЮФБОЙ§ТЫЯЕЭГжаЃЌзюГЃгУЕФгУЛЇаХЯЂашЧѓЕФТпМБэЪОЗНЗЈЮЊЛљгкЬиеїЯюЕФБэЪОЗНЗЈЃЌМДгУвЛИіnЮЌЯђСППеМфжаЕФЬиеїЯюЯђСПРДБэЪОгУЛЇФЃАхЁЃЩшt1ЃЌt2ЃЌЁЃЌtnЮЊЙЙГЩгУЛЇФЃАхЯђСПЕФnИіЬиеїЯюЃЌw1ЃЌw2ЃЌЁЃЌwnЮЊЖдгІЬиеїЯюЕФШЈжЕЃЌдђгУЛЇФЃАхPПЩвдБэЪОЮЊЯђСП(<t1ЃЌ w1>ЃЌ<t2ЃЌw2>ЃЌЁЃЌ< tnЃЌ wn>)ЁЃ
гУЛЇФЃАхЕФБэЪОЗНЗЈЛЙгагявхЭјТчЗНЗЈЁЂВњЩњЪНЙцдђКЭЗжРрФПТМЕШЗНЗЈЁЃЧАСНжжЗНЗЈЪЪ гУгкОпгаЭЦРэЛњжЦЕФжЧФмЙ§ТЫЯЕЭГвдМАФГаЉВЩгУВМЖћФЃаЭЕФЯЕЭГЁЃВуДЮФПТМЕФгУЛЇФЃАхБэЪОЗНЗЈвРРЕгкЙЬЖЈЕФдЪМЗжРрЃЌР§ШчжјУћЫбЫїв§ЧцGoogleЁЂ InfoseekBaiduЁЂYahooЕШВЩгУЗжРрЬхЯЕЛђепЯЕЭГИљОнОпЬхСьгђВЩгУЕФЗжРрБъзМвдМАUSENETЕШЭјЩЯаТЮХзщЕФЗжРрБъзМЕШЁЃ
гУЛЇаХЯЂашЧѓЕФЮяРэБэЪОЮЊДцДЂНсЙЙЃЌгУгкУшЪідкгУЛЇаХЯЂашЧѓдкгУЛЇФЃаЭЗўЮёЦїжаЕФЪ§ОнНсЙЙЁЃ
дкЛљгкЯђСППеМфФЃаЭЕФЮФБОЙ§ТЫжаЃЌгУЛЇФЃАхЕФЮяРэБэЪОЗНЗЈГЃВЩгУЮФБОМьЫїжаЪЙгУЕФЕЙХХЫїв§НсЙЙЃЌМДгУЕЙХХЫїв§РДБэЪОгУЛЇФЃАхЁЃ
ОпЬхзіЗЈЪЧЖдгкФГИіЬиеїЯюtЃЌНЋКЌгаtЕФЫљгаФЃАхаЮГЩвЛИіЕЙХХБэ(InvertedList)ЃЌ ДгФГИіЬиеїЯюЕНЦфЫљЖдгІЕФЕЙХХБэЕФДцДЂЮЛжУЕФгГЩфЭЈЙ§НЈСЂHashБэРДЪЕЯжЃЌГЦжЎЮЊФПТМ (Directory)ЁЃ дкЕЙХХБэжавЛАуЩшСНИігђЃЌ вЛЪЧФЃАхЕФБрКХЃЌ ЖўЪЧдкИУФЃАхжаЬиеїЯюЕФШЈжиЁЃ
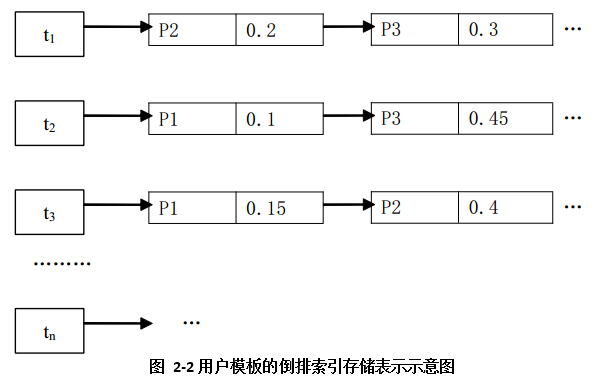
ЩшгЩЬиеїЯюt1ЃЌ t2ЃЌ t3ЃЌЃЌЁЃЌ tnЮЊЛљБОЬиеїЯюЙЙГЩЕФгУЛЇФЃАхP1ЃЌ P2ЃЌ P3ЕФЯђСПБэЪО аЮЪНЗжБ№ЮЊ:(жЛИјГіЧАШ§ИіЬиеїЯюЕФШЈжиЃЉ
P1=(<t1ЃЌ0>,< t2ЃЌ0.1>ЃЌ< t3ЃЌ0.15>ЃЌЁЃЌ<tnЃЌwn>)
P2=(<t1ЃЌ0.2>,<t2ЃЌ0.0>,< t3,0.4>ЃЌЁ,<tnЃЌwn>)
P3=(<t1ЃЌ0.3>ЃЌ<t2ЃЌ0.45>ЃЌ<t3ЃЌ0>ЃЌЁ,<tnЃЌwn>)
дђАДееЕЙХХЫїв§ЕФЗНЗЈПЩвдИјГігУЛЇФЃАхP1ЃЌ P2ЃЌ P3ЕФДцДЂБэЪОШчЭМ2-2ЫљЪО:
2.4 гУЛЇФЃАхЕФгХЛЏКЭИќаТВпТд
гУЛЇФЃАхЕФгХЛЏКЭИќаТВпТдЪЧгУЛЇаХЯЂашЧѓФЃаЭЫљвЊНтОіЕФвЛИіживЊЮЪЬтЁЃ дкЮФБОЙ§ТЫжаГЃВЩгУЯрЙиЗДРЁММЪѕРДНјаагУЛЇФЃАхЕФгХЛЏКЭИќаТ,ВЩгУЯрЙиЗДРЁММЪѕНјаагУЛЇФЃАхЕФгХЛЏКЭИќаТБЛШЯЮЊЪЧИФНјЮФБОЙ§ТЫЕФаажЎгааЇЕФЪжЖЮЁЃЯЕЭГвРОнгУЛЇЕФФЃАхЃЌНЋЦЅХфГЩ ЙІЕФЮФБОДЋЫЭИјгУЛЇЃЌгУЛЇИљОнздМКЕФХаЖЯНЋЮФБОЛЎЗжЮЊЁАЯрЙиЁБКЭЁАВЛЯрЙиЁБСНРрЃЌШЛКѓЗДРЁИјЯЕЭГ;ЯЕЭГИљОнгУЛЇЕФЗДРЁаХЯЂздЖЏгХЛЏКЭИќаТЕБЧАЕФФЃАхЁЃетЪЧвЛИіЕќДњЙ§ГЬЃЌВЛЖЯЕиаоИФЃЌжБжСДяЕНгУЛЇТњвтЕФНсЙћЁЃВЩгУЯрЙиЗДРЁММЪѕНјаагУЛЇФЃАхЕФгХЛЏКЭИќаТЕФЙ§ГЬЁЃ
ОпЬхРДНВ,ЖдгкВЩгУИХТЪФЃаЭЕФЮФБОЙ§ТЫЯЕЭГ,ЦфЯрЙиЗДРЁЙ§ГЬвРОн RobertsonКЭ Sparck-JonesЙЋЪН:
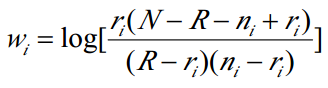
ЦфжаwiЪЧЯюtiЕФШЈжиЃЌNЪЧЙ§ТЫЮФБОЪ§ЃЌRЪЧгУЛЇШЯЖЈЕФЯрЙиЮФБОЪ§;niЪЧКЌгаЯюti ЕФЮФБОЪ§ЃЌriЪЧЯрЙиЮФБОжаКЌгаЯюtiЕФЮФБОЪ§ЁЃ
АДееЩЯЪНХХСаЯюМЦЫуШЈжиЃЌДггУЛЇШЯЖЈЕФЯрЙиЮФБОжабЁдёГіЧАnИіШЈжизюДѓЕФЯюМгШыгУЛЇФЃАхЁЃ
ЖдгкВЩгУЯђСППеМфФЃаЭЕФЮФБОЙ§ТЫЯЕЭГЃЌвЛАуВЩгУRocchioЗДРЁФЃаЭЁЃЫќБэУївЛИігааЇЕФгУЛЇФЃАхФмЙЛАДееЕќДњ(ЪН2-3)ВњЩњ:
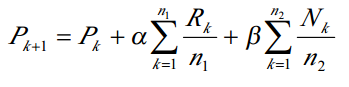
ЦфжаPk+1ЪЧаТЕФФЃАхЃЌPkЪЧОЩФЃАхЃЌRkЪЧЯрЙиЮФБОЕФЯђСПБэЪОЃЌNkЪЧВЛЯрЙиЮФБОЕФЯђСПБэЪОЃЌn1ЪЧЯрЙиЮФБОЪ§ЃЌn2ЪЧВЛЯрЙиЮФБОЪ§ЃЌІСгыІТЮЊМгШЈЯЕЭГЃЌБэЪОе§ЁЂИКЗДРЁЕФЙБЯзТЪЁЃ
 |
ЗжЯэШУИќЖрШЫПДЕН 
ЭЦМідФЖС
ДЋУНЭЦМі
 @УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад
@УНЬхШЫЃЌаТЮХБЈЕРБ№ШЮад ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ
ЭјеОдЫгЊеп етаЉ"КьЯп"ВЛФмВШЃЁ вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
вЛЭМзнРРжаЙњЭјТчЪгЬ§аавЕ
ЯрЙиаТЮХ
- AIВЛЛсЖЯОфЃПжаЮФЗжДЪаТФЃаЭАяЫќНјВН
- РюЮАЃКгпЧщЪТМўЕШМЖЦРЙРМАЛљгкгявхРэНтЪЕЯжЮФБООЋЯИЛЏЗжРр
- СНВПУХгЁЗЂаЃЭтХрбЕКЯЭЌЗЖБО ЖдЪеЭЫЗбМАЮЅдМд№ШЮзїГіЙцЖЈ
- ЦНАВеЖЛёжЧФмвНСЦЮЪД№ЙњМЪДѓШќ1ЯюЪРНчЕквЛЁЂ2ЯюЪРНчЕкЖў
- ЙўЖћБѕЦѓвЕПЊАьЪБМфгЩ5ИіЙЄзїШеЫѕжС2Иі
- ЙтУїШеБЈЃКдФЖСРэНтЬтЁАДђАмЁБдзїепЖдНЬбЇЕФЦєЗЂ
- ЛљгкЛњЦїбЇЯАЕФЯрЙиаТЮХЪТМўЭкОђ
- ЛљгкШЫУёЭјаТЮХБъЬтЕФЖЬЮФБОздЖЏЗжРрбаОП
- AIВЛЛсЖЯОфЃПжаЮФЗжДЪаТФЃаЭАяЫќНјВН
ПЭЛЇЖЫЯТди
ШЫУёШеБЈЩчИХПі | ЙигкШЫУёЭј | БЈЩчеаЦИ | еаЦИгЂВХ | ЙуИцЗўЮё | КЯзїМгУЫ | ЙЉИхЗўЮё | Ъ§ОнЗўЮё | ЭјеОЩљУї | ЭјеОТЩЪІ | аХЯЂБЃЛЄ | СЊЯЕЮвУЧ
ЗўЮёгЪЯфЃКkf@people.cn ЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-65363263 ОйБЈгЪЯфЃКjubao@people.cn
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170001 | діжЕЕчаХвЕЮёОгЊаэПЩжЄB1-20060139
ЙуВЅЕчЪгНкФПжЦзїОгЊаэПЩжЄЃЈЙуУНЃЉзжЕк172КХ | ЛЅСЊЭјвЉЦЗаХЯЂЗўЮёзЪИёжЄЪщЃЈОЉЃЉ-ЗЧОгЊад-2016-0098
аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0104065 | ЭјТчЮФЛЏОгЊаэПЩжЄ ОЉЭјЮФ[2020]5494-1075КХ | ЭјТчГіАцЗўЮёаэПЩжЄЃЈОЉЃЉзж121КХ | ОЉICPжЄ000006КХ | ОЉЙЋЭјАВБИ11000002000008КХ
ШЫ Уё Эј Ац ШЈ Ыљ га ЃЌЮД О Ъщ Уц Ък ШЈ Нћ жЙ ЪЙ гУ
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
ЦРТл

-
ЙизЂ
ЮЂаХЮЂВЉПьЪж
 ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
ЕквЛЪБМфЮЊФњЭЦЫЭШЈЭўзЪбЖ
 БЈЕРШЋЧђ ДЋВЅжаЙњ
БЈЕРШЋЧђ ДЋВЅжаЙњ
 ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
ЙизЂШЫУёЭјЃЌДЋВЅе§ФмСП
