




















你有什么好,我要理你?――微信软文内容特征研究【2】
四、研究方法
Ⅰ 、数据收集方法与过程
本研究分为深度访谈、预调查和正式调查三个阶段,深度访谈、预研究和正式研究,深度访谈是为了丰富微信软文内容特征的题项,而预研究是修订微信软文内容特征量表,正式研究除进一步检验内容特征量表的信度和效度以外,探索和评估这些特征(指标)对受众接受行为的影响程度。
深度访谈:本研究在文献阶段对微信软文内容特性做了梳理,但由于研究数量较少,可能遗漏了一些重要的微信软文内容特性评价指标,因此通过深度访谈对文献梳理结果做补充。本文选取了6个方便样本进行了半结构化访谈,访谈对象均为厦大新闻传播学专业硕士研究生,主要针对其最近阅读的一则微信软文广告以及平时阅读微信软文的经历,按照信息质量评价、内容特征及价值评价、情绪反应以及是否产生点赞、转发、评论的接受行为的访谈框架,探索他们阅读微信软文过程中可能感知到的内容特性。访谈结果显示“一致性”、“负面情绪”等可能是微信软文内容特性的重要指标。
预研究:在厦门大学新闻传播学院的应用统计学以及广告心理学两门课程的课间发放问卷,共发出问卷数为140份,有效问卷为136份。
正式研究:正式调研则通过“问卷星”网站发放网络问卷以及在厦门大学西门对游客进行拦截发放的方式,以便获取更多省份和地区的数据,最终共获得442份问卷,剔除无效样本后,最终有效问卷为422份,有效率为95.5%。
Ⅱ、样本情况
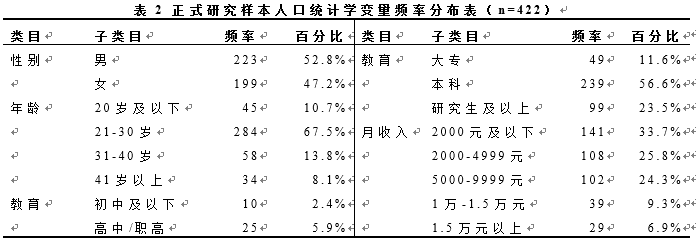
样本人口统计学情况如表2所示,样本男女比例均衡,年龄集中在40岁以下,教育程度以本科及以上为主,月收入集中在10000元以下。根据企鹅智库的2015年的报告显示:微信使用者男女比例约为1.8:1,18-35岁的中青年占比高达86.2%。 由此可见样本在性别、年龄等各变量上的占比情况较符合微信用户的人口统计学变量。
Ⅲ、问卷结构和内容
预调研问卷有三个部分:第一部分的62个题项是关于微信软文内容特性的测量;第二部分的6个项目是关于受众的接受行为的测量。参考前人的研究,采用“我打算去点击微信软文”,“我未来一段时间内可能点击并观看微信软文”,“我愿意为微信软文点赞”,“我愿意为微信软文评论”,“我愿意为微信软文转发”,“我愿意点击微信软文中的阅读原文看更多的产品信息”。(Moon kim, 2001; Taylor &Todd, 1995; 朱丹舟,2016)。
Ⅳ、数据分析方法
预调研阶段的样本用于量表提纯及探索性因子分析,以探索微信软文内容特性指标的初步结构。而正式调研的样本则用于验证性因子分析,以检验模型的拟合程度。使用SPSS21.0用于数据的描述性和探索性因子分析,使用AMOS24.0用于验证性因子分析。
五、数据分析
Ⅰ 、微信软文内容特性构成要素分析
量表提纯
首先采用项目与总分相关法进行项目分析,若题项与总分的相关不显著或较低(小于0.3),则表明测量题项与整体量表不一致,可以考虑予以删除。皮尔逊相关分析结果显示:有8个题项目与总分的皮尔逊相关未达到显著水平且相关系数均小于0.3,不符合要求。其次,采用高低组平均数差异检验法,将所有样本在预测试量表的得分总和按高低排列,以27%为割点,得分在前27%者为高分组,得分在后27%的为低分组,若高低二组被试在每题得分平均数差异的Sig值达到显著性水平,即表示这个项目能鉴别不同被试的反应程度。检验后发现有10个题项的值大于0.05,不符合要求。其中负面性与感知说服动机两个维度的量表的区分效度不高,原因可能是因为预调研受众均为厦门大学新闻传播学院在校大学生,群体较为同质化,其对于广告负面性较为敏感,广告的说服动机辨识程度较强。而在实际调研过程中的被试会更为异质化,因此对这两个维度先予以保留。删除4个题项目后,初始量表的题项从62题减为58题目。
其次,对量表进行信度检验。数据分析结果显示,初始量表的Cronbach’s α系数为0.921大于0.7,表明该量表的总体信度较高,量表整体可以接受,进一步考察各个分量表的Cronbach’s α系数以及单项-总量修正系数(CITC系数)若删除某一题项后α系数不降反而整体的信度提升,则说明该题项与其余题项的内部一致性系数较低,考虑予以删除。删除6个题项后,剩余52个项目,Cronbach’s α系数提高至0.935,除了相关性与准确性量表信度为0.666,小于0.7外,其余各个分量表信度均大于0.7,符合分量表信度要求。
探索性因子分析
经过探索性因子分析发现,KMO值为0.851>0.7,球形检验结果在0.01水平上达到显著,适合使用因子分析。进而采用主成分分析和方差极大正交旋转获得因子载荷矩阵进行分析,分析过程中删除符合以下条件之一的题项:(1)共同度小于0.5;(2)因子载荷小于0.5;(3)跨载荷超过0.4。经过多次因子分析,删去8个题项,得到具备较好区分性的因素结构。修订完成后的量表包含44个题项,总Cronbach’s α系数为0.922,各个分量表的Cronbach’s α均大于0.7,符合要求。量表最终提取出11个因子,如下表3:
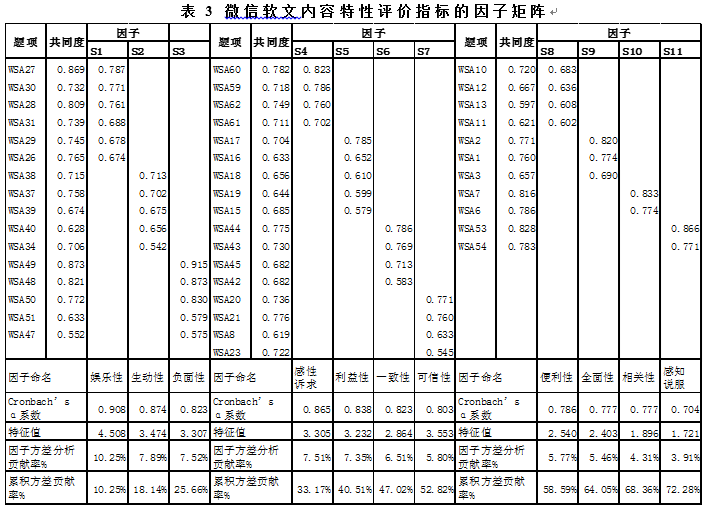
因子S1包含6个题项,表达阅读微信软文给用户带来的愉悦,享受,兴奋等体验,因此命名为“娱乐性”。因子S2包含5个题项,主要描绘微信软文内容引起人们注意并引发联想的程度,因此命名为“生动性”。因子S3包含5个题项,均为一系列描述微信软文给人带来的负面情绪的语句, 因此命名为“负面性”。因子S4包含5个题项,主要描绘微信软文给人带来的非负面情感信息, 因此命名为“感性诉求”。因子S5包含5个题项,表达微信软文对用户而言的实用价值或者给用户带来的利益, 因此命名为“利益性”。因子S6包含4个题项,主要描绘微信软文中产品信息和其他信息的一致性程度, 因此命名为“一致性”。因子S7包含4个题项,主要展示微信软文整体信息的真实可靠程度, 因此命名为“可信性”。因子S8包含4个题项,主要描绘用户通过微信软文获取产品信息的便利程度, 因此命名为“便利性”。因子S9包含3个题项,表达微信软文包含信息的完整性, 因此命名为“全面性”。因子S10包含2个题项,主要展示微信软文内容信息与受众的相关程度, 因此命名为“相关性”。因子S11包含2个题项,指的是用户阅读微信软文感知到其商业目的的程度, 因此命名为“感知说服”。
验证性因子分析
利用本研究再次进行调查所收集的422份数据样本进行验证性因子分析,探索由探索性因子分析获得的结构模型对实际观测数据的拟合程度。因本研究构念娱乐性(S1)、所涉及的测量指标较多,在进行结构方程分析的时可能会导致模型过于复杂而无法拟合,因此本文参考卞冉等人(2007)的文献,对该指标进行单维度打包,形成部分分散模型,以减少研究中所涉及的测量指标数目,使得结构方程分析结果更为可靠。最终打包形成之后的测量模型中娱乐性(S1)均包含3个测量指标。
在整体模型适配度方面,本研究采用?2/df、RMSEA、RMR、GFI、AGFI、NFI、TLI 、CFI指标来对测量模型的拟合优度进行评价,各指标的理想值如表4所示:

在信度方面,主要评估量表的整体信度和建构信度。整体信度通过Cronbach α值进行检验,该值大于0.7表明量表信度高。建构信度(Construct Reliability,CR),它主要用于评价潜在变量指标的一致性程度,建构信度越高,表示测量变量指标间存在高度的内在关联。其值在0.6以上表示潜在变量的建构信度良好。而在效度方面,CFA检验建构效度,包含收敛效度(聚合效度)与区别效度(判别效度),当满足(1)潜变量与观测变量之间的标准载荷>0.5。(2)潜变量平均方差抽取量AVE>0.5时表明该量表收敛效度良好。其次,当潜变量的AVE平方根大于该潜变量与其他变量的相关系数时,表明量表的区分效度良好。(转引自潘煜等人,2014)量表各个潜变量的信效度如表5所示:
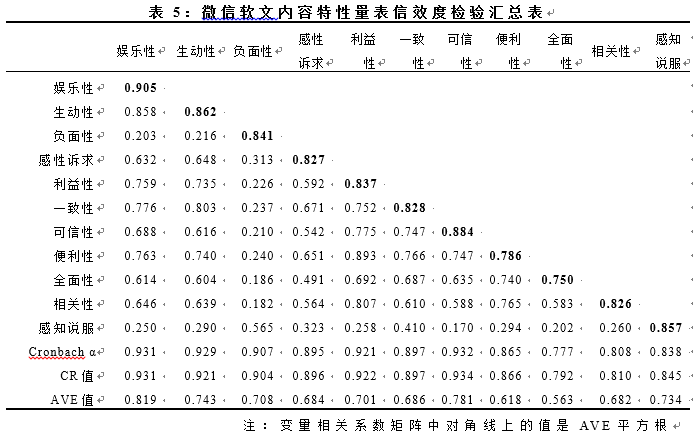
信度方面,量表整体Cronbach α值为0.965,整体可靠,且各潜变量Cronbach α值均大于0.7,符合分量表的信度要求。而在效度方面,收敛效度中,各个题项在相应的潜变量的表转化载荷均大于0.5,并且达到显著性水平,各个潜变量的 AVE值均大于0.5,表明该量表的收敛效度良好。而在区别效度中,除了利益性与便利性之间的相关系数大于利益性的AVE平方根外,其余潜变量的AVE的平方根均大于潜变量之间的相关系数, 便利性量表与利益性量表区分效度不足,需要后续的研究进一步检验。综上,量表整体信效度较好。
 |  |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
