




















基於關鍵詞的文本內容過濾算法的研究與應用【3】
4.2 基於關鍵詞的文本內容過濾模型
大部分文本內容過濾模型採用特征匹配與過濾模型,本文提出的過濾模型以從用戶行為分析模型中提取的特征關鍵詞為輸入,與數據庫中的文本特征進行比對,將相似度在某范圍內的信息篩選出來作為推薦系統的輸出。但同時需要考慮用戶閱讀審美疲勞程度,內容相似度大的新聞不應該同時推薦給讀者。例如,某讀者行為的特征關鍵詞為“十九大、黨委、博士論文、化妝品”,根據相似度篩選出的文本可能大多數為十九大相關的新聞與文章,如果單純將相似度高的文本推薦給讀者,則讀者看到的推薦則均為十九大會議內容,這樣並未體現出個性化推薦的良好效果。我們希望推薦給讀者的內容應包含各領域,因此,本文模型中對篩選出的目標數據進行聚類,每一類中提取出與用戶行為特征相似度最高的內容進行推薦,具體流程如圖4-2所示。
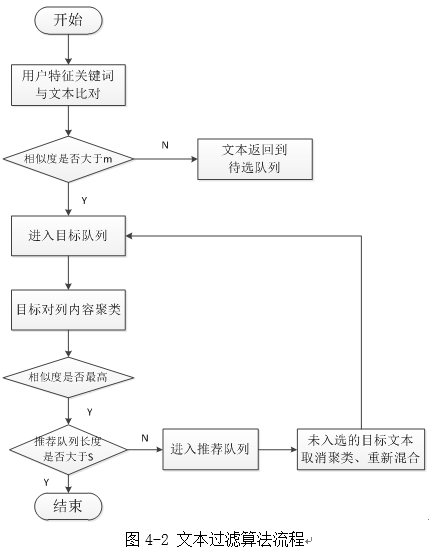
如圖4-2,本文所設計的文本內容過濾模型主要分為以下三個步驟:
(1) 特征比對:用戶特征關鍵詞組成用戶需求特征向量,提取待過濾文本特征組成文本特征向量,計算用戶需求特征向量與文本特征向量的相似度,選取相似度大於預定參數m的文本,組成目標文本隊列﹔
(2) 內容聚類:使用K-means方法對所有目標文本進行聚類分析,產生了k個簇集,每個簇集選取特征比對時相似度最高的文本,進入最終的推薦隊列,這樣一次過濾后篩選出k個可推薦文本﹔
(3) 重過濾:當預推薦文本個數s大於每次過濾所篩選出的文本個數k時,需要進行多次過濾,為減小模型的隨機性,將重過濾的起始點設在目標對列的整合上,即所有前一次或前幾次未進入推薦隊列的目標隊列文本作為新的目標文本,重新進行聚類與提取,當推薦隊列的文本數量達到預設數量s時則停止循環。
4.3 特征比對算法設計
從用戶行為分析模型中所得用戶特征關鍵詞組成用戶特征向量X,採用中文分詞機制將人民網中的新聞等類型的文本進行分詞,去停用詞后進行詞頻計算,篩選出文本關鍵詞組成文本特征向量Y,使用余弦距離sim(X,Y)計算兩個向量的相似度,計算方法如式4-1。
![]()
式4-1中X∙Y為兩個向量的積,‖X‖∙‖Y‖為兩個向量的長度乘積,余弦距離越接近於1,兩個文本越相似。為篩選出與用戶特征關鍵詞相似性較高的文本,需設置檢驗計算的閾值,閾值為0.5到1之間的一個數值,余弦相似度大於此閾值則文本進入目標序列。
4.4 目標文本內容聚類算法設計
本文選用K-means方法對目標文本進行聚類分析,聚類是一種無監督的機器學習方法,被用於模式識別、數據挖掘等領域。自下而上的K-means方法簡單、快速,其聚類的結果受初始質心與聚類數目影響,本文所涉及的場景可通過關鍵詞數量及文本類別確定聚類數目,因此本文選取K-means做目標文本的聚類分析。

本文的聚類算法計算過程如表1所示,K-means算法中的k值為聚類結果中簇集的個數,因為用戶特征關鍵詞的個數是確定的,因此直接將關鍵詞個數作為聚類簇集的個數﹔隨機選擇k個簇集的中心(即質心),用式4-1計算各文本特征向量X與質心向量Y的余弦相似度。
余弦距離越接近於1,文本與質心越相似,文本與哪個質心最相似則將此文本歸於此質心所在簇集中。
此算法的目標函數為最大化余弦距離和,如式4-2所示,當目標函數達到最優則算法停止。
![]()
經過K-means算法的聚類分析,最終得出k個文本簇集,每個簇集代表一種類型的文本,從每個簇集平均選出推薦給用戶的文本組成最終的推薦隊列。
5 總結與展望
本文提出的過濾模型是個性化推薦系統的核心,由於所選用的文本相似度計算與聚類算法具有普適性,因此該模型不僅可以應用於人民網的個性化推薦系統,還可應用在人民網的檢索系統、敏感信息過濾處理等系統。不同的使用環境設置不同的參數與閾值,能夠使此模型達到最良好的使用效果。
 |
分享讓更多人看到 
推薦閱讀
傳媒推薦
 @媒體人,新聞報道別任性
@媒體人,新聞報道別任性 網站運營者 這些"紅線"不能踩!
網站運營者 這些"紅線"不能踩! 一圖縱覽中國網絡視聽行業
一圖縱覽中國網絡視聽行業
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
