




















基於關鍵詞的文本內容過濾算法的研究與應用
摘要:本文對目前文本過濾技術進行了調研,並在此基礎上利用空間向量模型作為用戶需求模板,使用余弦距離計算文本相似度,採用K-means算法進行文本聚類分析效果優化,提出了基於關鍵詞的文本內容過濾模型,能夠為人民網用戶個性化推薦新聞、廣告、文章等信息,縮短信息檢索時間,最大程度為用戶提供其感興趣的內容,創造經濟與社會價值。
關鍵字:文本內容過濾,推薦系統,聚類,K-means算法
1 引言
人民網是以新聞為主的大型網上信息發布平台,集中了現有的電子媒體的形式創新,是互聯網上最大的中文和多語種新聞網站之一。人民網的新聞報道以權威性、及時性、多樣性和評論性為特色,報道內容包括政治、經濟、法律、新聞、科學文化及廣告等方面,內容豐富且具有權威性。
近年來,個性化推薦已成為各大主流網站的一項必不可少的服務,但與電子商務網站相比,新聞的個性化推薦水平仍存在較大差距。人民網的用戶數量巨大,某些年齡段的用戶數量甚至多於購物網站。如果能夠高效率地挖掘用戶的潛在興趣,並進行個性化的新聞與信息推薦,能夠產生巨大的社會價值。
在人民網下一步發展戰略中,新媒體融合論壇中副總編輯盧新寧等人闡述了發展方向,其強調新創新的作用及其內容生產,強調了對人民網、手機人民網、人民網客戶端、數據中心等平台的建設。基於關鍵字的文本內容過濾算法迎合了人民日報的新進展,立足於人民網為用戶個性化推送新聞、廣告等信息,可為用戶提供具有指導性的建議,也能夠為第十九次全國人民代表大會宣傳黨的路線方針、推進社會主義新聞理論創新、弘揚時代精神,為祖國歷史和民族文化作出貢獻。
本文基於關鍵字的文本過濾技術,通過用戶特征關鍵詞從海量信息中快速有效地找到用戶感興趣的新聞,重構了用戶連接,實現了用戶觀點的分享傳播,可以有效地為用戶個性化推薦新聞。採用內容過濾算法,利用其特點建立用戶之間連接,如移動客戶端、網絡交流、數據採集等,根據已有用戶已經建立的用戶感興趣實體,對實體進行相似度推薦。
2 技術背景
目前智能推薦系統的主要推薦技術包括基於規則的推薦與基於內容過濾的推薦,基於規則的推薦主要通過基礎判斷進行分流從而得出相關結論,當處理問題較為簡單,判斷規則較少的時候,系統能夠迅速處理並獲得結論,然而隨著問題的細化和問題規模的擴大,系統對於判斷將會增加處理時間,同時,也不利於系統的規則擴展和維護。在內容過濾中由於網絡中主體信息為文本,所以內容過濾研究主要針對信息文本展開。
2.1文本過濾相關技術
內容過濾系統中使用了相關的文本過濾技術。文本過濾(Text Filering)是指計算機根據用戶對信息的需求,從大量的文本流中尋找對應信息或剔除不相關信息的過程。對用戶需求的判斷和所採用方法使之與需求相適應對提升文本過濾的效果十分重要。
在國外文本過濾相關技術研究方面,Belkin和Croft提出了用戶特征過濾對文本過濾系統的影響和積極意義﹔Lam等人對個人興趣飄逸探測算法進行研究;Yang和Chute基於實例和最小平方利益的線性模型改進了文本分類器﹔Mosafa構造了智能信息過濾的多層次分解模型。國內文本過濾相關研究包括,劉永丹和曽海泉等人提出了基於語義分析的傾向性文本過濾﹔姚天順等構造了基於語義框架的中文文本過濾模型﹔程顯義和楊天明等人對語義傾向性的文本過濾進行了研究﹔黃萱菁等構建了基於向量空間模型的文本過濾系統。
文本過濾在實現技術上主要借鑒和使用自動檢索、自動分類、自動標引等信息自動處理的方法和技術。根據文本過濾對過濾內容的不同分為用戶特征過濾和安全過濾,本文針對的內容主要為用戶特征過濾。
2.1.1文本過濾過程
文本過濾有五個步驟:(1)待過濾的文本的表示(2)確定用戶需求模板:通常包括過濾特征描述、數據特征表示﹔(3)用戶需求與未過濾文本的匹配﹔(4)獲取效果匹配反饋﹔(5)根據匹配效果反饋修改需求模板,以上過程如圖2-1所示。
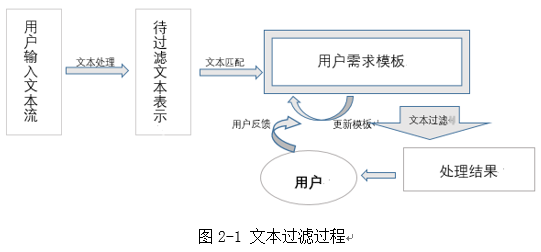
對原始的數據流進行處理得到待過濾的文本表示,利用文本匹配進行相似度計算,通過機器學習過程不斷訓練模型,以人為干預的模式進行監督不斷優化需求模板,提升過濾處理結果的精確度。
2.1.2文本過濾核心工作
文本過濾的核心工作主要針對用戶需求模板和文本匹配展開。
用戶需求模型採用的方法主要包括向量空間模型、預定義主題詞、層次概念集、規則和分類目錄等方法。復旦大學的吳立德教授和黃萱菁博士等人研究的文本過濾系統是基於向量空間模型提出的,武漢大學信息資源研究中心的張玉峰教授和蔡皎潔博士研究得到web環境下基於用戶興趣本體學習的文本過濾研究同樣基於空間向量模型,東北大學的姚天順教授和林鴻飛博士等人提出了基於示例的中文文本過濾模型,在該模型中也採用了向量空間模型。與其他用戶需求模板方法相比較,向量空間模型具有表示明確計算便捷的特點,使各種相似運算和排序成為可能。
文本匹配過程中,計算相似度是判斷文本是否符合用戶需求可以看作分類問題。常用的分類方法有:中心向量算法、朴素貝葉斯算法、支持向量機分類算法、基於KNN的文本分類算法。
(1)中心向量算法:利用向量空間模型,劃分為不同的訓練類別進行計算,將相似度高的劃分為一個類,再進行標准化處理,最后得到相似度值。設訓練集合為C,如式2-1所示。

分類的時候,對於一個新文本,在空間模型的基礎上,生成表示該文本的向量,通過對該向量與各類別特征向量的計算比較得出相似度,並將該文本劃分到與其相似度最大的類別中去。向量相似度的計算方法主要有兩種,若用x,y代表向量,xi,yi代表向量分量。
a歐幾裡德距離如式2-3所示。
![]()
dis(x,y)值表示向量與類別特征向量的距離,值越小表示距離越近,向量相似度越高。
b向量夾角如式2-4所示。
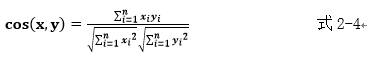
cos(x,y)值越高表示夾角越小,向量相似度越高。
中心向量算法在類與類之間相似度相差較大的時候有較好的分類效果,實際應用中,類與類之間的差異可能並不是那麼突出,並且實際數據的分布是儲存在偏差的,這樣將會導致算法判斷失誤,分類效果不好。
 |
分享讓更多人看到 
推薦閱讀
傳媒推薦
 @媒體人,新聞報道別任性
@媒體人,新聞報道別任性 網站運營者 這些"紅線"不能踩!
網站運營者 這些"紅線"不能踩! 一圖縱覽中國網絡視聽行業
一圖縱覽中國網絡視聽行業
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
