




















新媒体时代下新闻传播“五力模型”的构建及可视化实现【3】
3 新闻传播五力模型算法模型
3.1同一新闻事件的判断
一般会出现新闻转载和新闻的后续报道,所以需要进行两种方向的判断。首先,如果两篇文档全部一致的话,可以确定为转载。否则进行相似性判断。对于新闻内容可以先进行预处理,进行中文分词和除去停用词。然后识别命名实体,然后把各个关键词用TF-IDF进行处理,对于命名实体使用权值进行加强。然后选取n个权值比较大的词生成网页的特征向量,如果两个网页的特征向量出现相同词数量大于一定值,则判断两个网页为同一新闻事件的网页。判断为同一新闻事件的网页后,需要提取关键数据:新闻的内容、新闻发布网站、新闻网页源码、新闻的评论内容。
3.2传播力的算法模型
本文将传播力的算法模型设置如下:
传播力=传播范围+传播持续时间+传播速度+目标群体覆盖率
其中传播范围、传播速度按照上文描述进行计算,且值域为[0,1]。目标群体覆盖率为同一新闻事件发布及转载的媒体传播力排行榜数据值之和,其中新闻网站来源的传播力为:利用传播力排行榜表格中的数据,排名前10的传播力数值设为11;排名10-20的传播力数值设置为10;20-30设置为9,以此类推。排行榜不存在的按照1处理;发布媒体为微信的则为微指数公众号总阅读数排名,具体规则同上。
考虑到数据的获取能力,计算传播范围时采用新闻网站、微信、微博数据,计算新闻事件占当天新闻比重。传播持续时间计算新闻事件在媒体中出现累积的天数。传播速度计算如下:

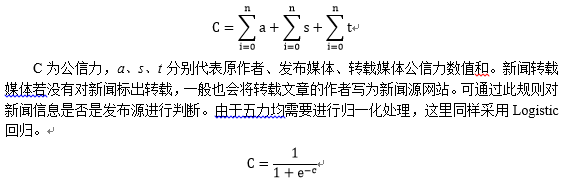
3.3公信力的算法模型
公信力指新闻媒体自身在长期的新闻传播实践过程中所形成并累积的、赢得社会和广大受众普遍信任的程度或能力,包括了信息创造者、发布和转发的媒介平台三部分。由于公信力包含了主观和客观的对媒体和作者的评价,所以这里以权威网站的排名作为信息。
3.4说服力的算法模型
说服力中关键词的确定需要综合以下几个方面考虑:
1:使用TF-IDF计算出每个词的权值,权值越大的词越关键。
2:按照词性进行分类,一般人名、地名、机构名较容易成为关键词,所以对这几类词赋予较高的权重。

根据以上几个方面综合计算之后确定出最佳关键词,然后统计该关键词在每日关于该新闻时间的新闻中总的出现次数为A,即为词频。
关于报道说明性信息量的计算方面,对于关于该新闻事件的报道对于完全相同的只取其中一篇,然后统计各个报道的网页源码,识别其中html中图片和视频标签的个数来统计其内容的丰富程度。最后对其数量进行加总,为S。
关于舆论导向的计算方面,截止到当日24:00,针对同一新闻事件相关的新闻报道的网络评论进行评论情感分析,计算具有明确倾向的评论分类情况,与目标期望进行匹配。
3.5号召力的算法模型
同上文所述,先对新闻稿件进行判断,如果属于同一新闻事件的就计入统计。当天的总的网页数量即为转发数,为z。评论数为当天各个网站下关于此新闻事件评论的数量的总和。搜索数量为当天的百度和微博关于该新闻事件关键词的搜索数量的加和,设为s。
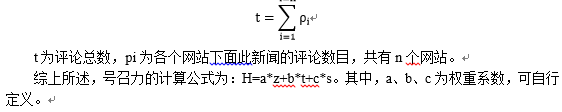
3.6影响力的算法模型
新闻影响力(E)由五种基本指标动态决定。该五种指标分别为:新闻源网站的转载率r、所处版面特征值p、发布时段特征值s、新闻标题特征值t和新闻认可率z。
其中,转载率r为所转载媒体的影响力值乘以相应权重决定。

4 新闻五力模型指标体系实验及结果
4.1 实验数据集
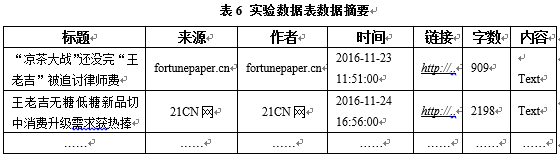
本文按照不同新闻源(新闻网站、贴吧、微信、微博)连续获取了一个月内一对竞品(王老吉和加多宝)的新闻资讯,获取的实验数据列表见表6。
4.2 实验结果
对文本内容进行去重和无用数据清洗后,将新闻内容按照新闻五力模型指标体系进行了标注和计算,得到了以下结果。
4.2.1传播力
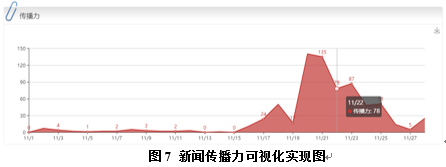
如图7所示,传播力以折线图表示,以天为单位反映了一个月内传播力的变化。节点上显示当天传播力的数值。鼠标悬浮在节点上可以看到详细信息。折线图显示了一个新闻事件随时间的传播力变化,可以看到当事件发生初期传播范围较小,随后在某个时间内突然增加,随后慢慢减小。
 |  |
分享让更多人看到 
推荐阅读
传媒推荐
 @媒体人,新闻报道别任性
@媒体人,新闻报道别任性 网站运营者 这些"红线"不能踩!
网站运营者 这些"红线"不能踩! 一图纵览中国网络视听行业
一图纵览中国网络视听行业
相关新闻
人民日报社概况 | 关于人民网 | 报社招聘 | 招聘英才 | 广告服务 | 合作加盟 | 供稿服务 | 数据服务 | 网站声明 | 网站律师 | 信息保护 | 联系我们
服务邮箱:kf@people.cn 违法和不良信息举报电话:010-65363263 举报邮箱:jubao@people.cn
互联网新闻信息服务许可证10120170001 | 增值电信业务经营许可证B1-20060139
广播电视节目制作经营许可证(广媒)字第172号 | 互联网药品信息服务资格证书(京)-非经营性-2016-0098
信息网络传播视听节目许可证0104065 | 网络文化经营许可证 京网文[2020]5494-1075号 | 网络出版服务许可证(京)字121号 | 京ICP证000006号 | 京公网安备11000002000008号
人 民 网 版 权 所 有 ,未 经 书 面 授 权 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
评论

-
关注
微信微博快手
 第一时间为您推送权威资讯
第一时间为您推送权威资讯
 报道全球 传播中国
报道全球 传播中国
 关注人民网,传播正能量
关注人民网,传播正能量
