




















���ڹؼ��ʵ��ı����ݹ����㷨���о���Ӧ�á�2��
��2�����ر�Ҷ˹�㷨��NB�������ݱ�Ҷ˹���������ݲ��Լ��и�������ڸ�������еĸ��ʣ��ٸ��ݲ����ı�������ֵ�Ʋ�����һ���࣬�����ı������鵽�������ķ�����ȥ���ù۵�Ļ���ǰ���ǣ��ı�������ֵ��������ģ���������������ܹ���ָ�����̶Ƚ��ͷ���ĸ����ԡ�

�������ѵ��������ȷ���ַ�������Լ�����ֵ�ĸ����������������ѡ����ȷ��ȫ��ģ�ͬʱ������Ȩ�ص�Ӱ�죬���ر�Ҷ˹�㷨����Ϊ������ʱ�ܴﵽ��õķ���Ч����һ�㣬���ʲ������ܶȺ��������Ի�ȡ�ģ���˸��㷨��Ҫͨ��ͳ�ƻ��߲��Խ����������ͷ�����ѵ������Ӧ���У��÷���������Ϊ�Ƚϱ�����У��������
��3��֧�������������㷨����һ�ֻ��ڶ������ģ�͵��㷨��֧����������ѧϰ����Ϊ����������ʽ��Ϊһ��������ι滮�����⣬Ҳ�ȼ������ĺ�ҳ��ʱ��������С�����⡣֧��������ѧϰ�������������ɼ�������ģ�ͣ����Կ�֧��������������֧����������������֧����������
�����˼���ǽ���һ�����ž��߳�ƽ�棬ʹ��ƽ����������������������֮��ľ�����Ӷ��Է��������ṩ�����õķ�������������һ����ά����������ϵͳ�������һ����ƽ�沢�����ƶ������������з��࣬�����Ͻ���ѵ����ֱ�����е�λ��ƽ�����ࡣ��һϵ�еı任��ͨ��������ʵ��ڻ��������˺��������еģ��任�õ�����������ƽ����ܶ����SVM�ڱ�֤���ྫ�ȵ�ͬʱ��Ѱ�Ҿ�����Щƽ���������ƽ�棬�õ����ŷ��ࡣSVM�Ļ���˼����ͼ2-2��ʾ��
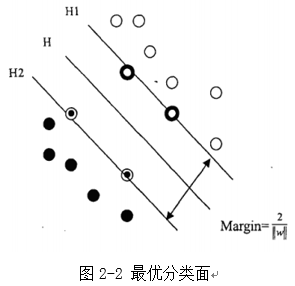
ͼ2-2�У�������H�����ڵĺڵ�Ͱ�������ֿ�����ͺڵ��о��������H����ĵ㹹��ƽ����H����H1��H2�����ɵľ���Ϊ����������ʾΪ2/(||w||)����������ֵ���ʱ���ڵķ����߳�Ϊ���ŷ����ߡ�

SVM�ʺ�С�������ķ��࣬�ر����ı����࣬�ڷ����Ժ�άģʽʶ���б��ֳ��������ơ������㷨��ȱ���������ܽ���������⡣
��4������KNN���ı������㷨����ģʽʶ��Dz�����������Ҫ�ķ���֮һ��
����Ҫ˼��Ϊ���ڸ������ı����У�ѡȡ�������/Ԥ�����ݵ������Ƶ�k��ѵ�����ݣ�ͨ������k�����ݵĽ�����߷�����ȡƽ����ȡ�����ȷ����õ�������/Ԥ�����ݵĽ�����߷����ţ������жϳ��������ı����������
KNN�㷨�ڻ��������ռ�ģ���У�ÿ���ı���Ϊһ��nά������ͨ���������ı���ѵ���ı�֮��ľ��룬ͨ�����ϵĹ���֣����յõ�k�����࣬���ı��ķ�����ݸ��ı������������������KNN�㷨������Ҷ˹���ࡢ֧���������ȷ������ѵ��������ѵ����KNNֻ�ǽ�ѵ�������������ڷ���/Ԥ��ʱ�轫������/Ԥ��������ѵ�����ݱȽ�����
�������ı������㷨��ȣ�KNN�㷨���м��������Ч���õ��ص㡣
2.2�ı������о���̬
����ǿ�ı��ı���ضȣ����õ�����û���Ȥ�����ܽ�ͣ���ڹؼ�����ͽṹ����Ҫ���ø�������ƴ������ʵ���壬�������û���ͼ���人��ѧ��Ϣ��Դ�о��е���������������û���Ȥ����������ñ���ѧϰ���������Ļ��ڱ����û����û�ģ�ͣ������ھ��û���Ȥ���������������Ƿ���Ĺ�ϵ������Ȥ��ֵ��
�ڴ���������ѧ�������ѧϵ�ֺ������Ļ��ڻ��ģʽ���ı�����ģ���в�����Э�����ˣ��û�����Ȥ�Ȳ������������������Լ���ģ��ģ�壬ͬʱ��Ӱ�����������û�����ɺ������˹��̣�����Ӱ��ǿ�ȡ�������һ���ԣ����������Ȩ���Ժ�һ���Զ�����Ȩ���Զ�������2-8��ʾ��

3 ��������ս
������������ص㣬���Ի��Ƽ�ϵͳ�������Ӧ�þ��������ѵ�����ս��
��1�� �û��ؼ���Ϊ���ʱ�����ڵ����ؼ��ʽ���ƥ�������������Ƽ�һ���ؼ��ʶ�Ӧ�Ķ�ƪ���£�������û�����ƣ�ͺ;뵡��
��2�� �����ı����ƶȷ�ʽ�ж��֣���ŷʽ���롢���Ҿ���ȣ�������ѡ������˽���ľ�ȷ�ԣ�
��3�� �Ƽ�ϵͳ��Ӧ�ó�����Ҫ�����ʹ�ã��������������г�������θ��ݳ���ѡ���Ƽ�ϵͳʹ�������һ����ѵ㡣
4 ģ�����
4.1 ���Ի��Ƽ�ϵͳ
��������Ƶ��ı����ݹ���ģ��Ϊ���Ի��Ƽ�ϵͳ����Ҫ�м���̣��Ƽ�ϵͳ�ṹ��ͼ4-1��ʾ��
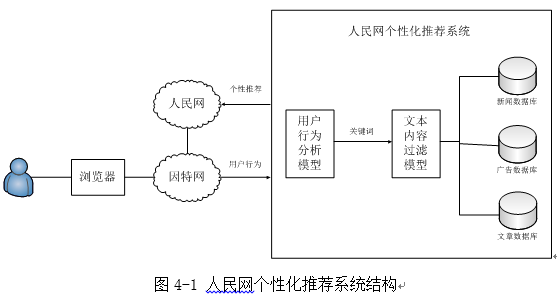
�û�ͨ������������ҳ���Ƽ�ϵͳ���û��������������Ϊ����ȡ�ؼ��ʣ������û���������������˶�ƪ��ʮ�Ŵ���ص����ű������Ƽ�ϵͳͨ���û���Ϊ����ģ����ȡ����ʮ�Ŵ������ߡ��ȹؼ��ʣ���Щ�ؼ�����Ϊ�ı����ݹ���ģ�͵����룬���š���漰���µ����ݿ��е��ı���Ϣͨ�������㷨����������ȡ�����ƶ�ƥ������ˣ����������Ƽ������б���������ҳ���û���������������ijЩ����е����ݱ��Ϊ��Ϊ�û�˽�˶��Ƶ�ר�����ݡ�
���Ի��Ƽ�ϵͳ��Ҫ�����û���Ϊ����ģ�����ı����ݹ���ģ�ͣ��������ؽ����ı����ݹ���ģ���еĹؼ�������
 |  |
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
