




















���ڹؼ��ʵ��ı����ݹ����㷨���о���Ӧ��
ժҪ�����Ķ�Ŀǰ�ı����˼��������˵��У����ڴ˻��������ÿռ�����ģ����Ϊ�û�����ģ�壬ʹ�����Ҿ�������ı����ƶȣ�����K-means�㷨�����ı��������Ч���Ż�������˻��ڹؼ��ʵ��ı����ݹ���ģ�ͣ��ܹ�Ϊ�������û����Ի��Ƽ����š���桢���µ���Ϣ��������Ϣ����ʱ�䣬���̶�Ϊ�û��ṩ�����Ȥ�����ݣ����쾭��������ֵ��
�ؼ��֣��ı����ݹ��ˣ��Ƽ�ϵͳ�����࣬K-means�㷨
1 ����
��������������Ϊ���Ĵ���������Ϣ����ƽ̨�����������еĵ���ý�����ʽ���£��ǻ��������������ĺͶ�����������վ֮һ�������������ű�����Ȩ���ԡ���ʱ�ԡ������Ժ�������Ϊ��ɫ���������ݰ������Ρ����á����ɡ����š���ѧ�Ļ������ȷ��棬���ݷḻ�Ҿ���Ȩ���ԡ�
�����������Ի��Ƽ��ѳ�Ϊ����������վ��һ��ز����ٵķ��������������վ��ȣ����ŵĸ��Ի��Ƽ�ˮƽ�Դ��ڽϴ��ࡣ���������û�������ijЩ����ε��û������������ڹ�����վ������ܹ���Ч�ʵ��ھ��û���DZ����Ȥ�������и��Ի�����������Ϣ�Ƽ����ܹ������������ֵ��
����������һ����չս���У���ý���ں���̳�и��ܱ༭¬�������˲����˷�չ������ǿ���´��µ����ü�������������ǿ���˶����������ֻ����������������ͻ��ˡ��������ĵ�ƽ̨�Ľ��衣���ڹؼ��ֵ��ı����ݹ����㷨ӭ���������ձ����½�չ��������������Ϊ�û����Ի��������š�������Ϣ����Ϊ�û��ṩ����ָ���ԵĽ��飬Ҳ�ܹ�Ϊ��ʮ�Ŵ�ȫ��������������������·�߷��롢�ƽ���������������۴��¡�����ʱ������Ϊ�����ʷ�������Ļ��������ס�
���Ļ��ڹؼ��ֵ��ı����˼�����ͨ���û������ؼ��ʴӺ�����Ϣ�п�����Ч���ҵ��û�����Ȥ�����ţ��ع����û����ӣ�ʵ�����û��۵�ķ���������������Ч��Ϊ�û����Ի��Ƽ����š��������ݹ����㷨���������ص㽨���û�֮�����ӣ����ƶ��ͻ��ˡ����罻�������ݲɼ��ȣ����������û��Ѿ��������û�����Ȥʵ�壬��ʵ��������ƶ��Ƽ���
2 ��������
Ŀǰ�����Ƽ�ϵͳ����Ҫ�Ƽ������������ڹ�����Ƽ���������ݹ��˵��Ƽ������ڹ�����Ƽ���Ҫͨ�������жϽ��з����Ӷ��ó���ؽ��ۣ������������Ϊ���жϹ�����ٵ�ʱ��ϵͳ�ܹ�Ѹ�ٴ�������ý��ۣ�Ȼ�����������ϸ���������ģ������ϵͳ�����жϽ������Ӵ���ʱ�䣬ͬʱ��Ҳ������ϵͳ�Ĺ�����չ��ά���������ݹ���������������������ϢΪ�ı����������ݹ����о���Ҫ�����Ϣ�ı�չ����
2.1�ı�������ؼ���
���ݹ���ϵͳ��ʹ������ص��ı����˼������ı����ˣ�Text Filering����ָ����������û�����Ϣ�����Ӵ������ı�����Ѱ�Ҷ�Ӧ��Ϣ�����������Ϣ�Ĺ��̡����û�������жϺ������÷���ʹ֮����������Ӧ�������ı����˵�Ч��ʮ����Ҫ��
�ڹ����ı�������ؼ����о����棬Belkin��Croft������û��������˶��ı�����ϵͳ��Ӱ��ͻ������壻Lam���˶Ը�����ȤƮ��̽���㷨�����о�;Yang��Chute����ʵ������Сƽ�����������ģ�Ľ����ı���������Mosafa������������Ϣ���˵Ķ��ηֽ�ģ�͡������ı���������о��������������͕���Ȫ��������˻�������������������ı����ˣ�Ҧ��˳�ȹ����˻��������ܵ������ı�����ģ�ͣ�����������������˶����������Ե��ı����˽������о�������ݼ�ȹ����˻��������ռ�ģ�͵��ı�����ϵͳ��
�ı�������ʵ�ּ�������Ҫ�����ʹ���Զ��������Զ����ࡢ�Զ���������Ϣ�Զ������ķ����ͼ����������ı����˶Թ������ݵIJ�ͬ��Ϊ�û��������˺Ͱ�ȫ���ˣ�������Ե�������ҪΪ�û��������ˡ�
2.1.1�ı����˹���
�ı�������������裺��1�������˵��ı��ı�ʾ��2��ȷ���û�����ģ�壺ͨ������������������������������ʾ����3���û�������δ�����ı���ƥ�䣻��4����ȡЧ��ƥ�䷴������5������ƥ��Ч������������ģ�壬���Ϲ�����ͼ2-1��ʾ��
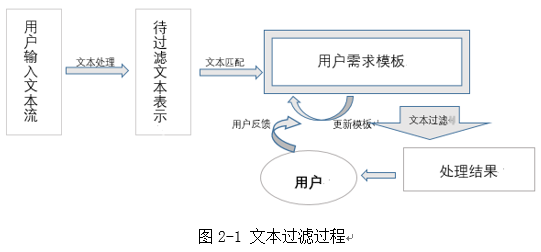
��ԭʼ�����������д����õ������˵��ı���ʾ�������ı�ƥ��������ƶȼ��㣬ͨ������ѧϰ���̲���ѵ��ģ�ͣ�����Ϊ��Ԥ��ģʽ���мල�����Ż�����ģ�壬�������˴�������ľ�ȷ�ȡ�
2.1.2�ı����˺��Ĺ���
�ı����˵ĺ��Ĺ�����Ҫ����û�����ģ����ı�ƥ��չ����
�û�����ģ�Ͳ��õķ�����Ҫ���������ռ�ģ�͡�Ԥ��������ʡ���θ��������ͷ���Ŀ¼�ȷ�����������ѧ�������½��ںͻ���ݼ��ʿ�����о����ı�����ϵͳ�ǻ��������ռ�ģ������ģ��人��ѧ��Ϣ��Դ�о����ĵ��������ںͲ��ʿ�о��õ�web�����»����û���Ȥ����ѧϰ���ı������о�ͬ�����ڿռ�����ģ��,������ѧ��Ҧ��˳���ں��ֺ�ɲ�ʿ��������˻���ʾ���������ı�����ģ�ͣ��ڸ�ģ����Ҳ�����������ռ�ģ�͡��������û�����ģ�巽����Ƚϣ������ռ�ģ�;��б�ʾ��ȷ�����ݵ��ص㣬ʹ������������������Ϊ���ܡ�
�ı�ƥ������У��������ƶ����ж��ı��Ƿ�����û�������Կ����������⡣���õķ������:���������㷨�����ر�Ҷ˹�㷨��֧�������������㷨������KNN���ı������㷨��
��1�����������㷨�����������ռ�ģ�ͣ�����Ϊ��ͬ��ѵ�������м��㣬�����ƶȸߵĻ���Ϊһ���࣬�ٽ��б������������õ����ƶ�ֵ����ѵ������ΪC����ʽ2-1��ʾ��

�����ʱ����һ�����ı����ڿռ�ģ�͵Ļ����ϣ����ɱ�ʾ���ı���������ͨ���Ը��������������������ļ���Ƚϵó����ƶȣ��������ı����ֵ��������ƶ����������ȥ���������ƶȵļ��㷽����Ҫ�����֣�����x,y����������xi��yi��������������
aŷ����¾�����ʽ2-3��ʾ��
![]()
dis��x,y��ֵ��ʾ������������������ľ��룬ֵԽС��ʾ����Խ�����������ƶ�Խ�ߡ�
b�����н���ʽ2-4��ʾ��
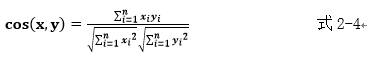
cos(x,y)ֵԽ�߱�ʾ�н�ԽС���������ƶ�Խ�ߡ�
���������㷨��������֮�����ƶ����ϴ��ʱ���нϺõķ���Ч����ʵ��Ӧ���У�������֮��IJ�����ܲ�������ôͻ��������ʵ�����ݵķֲ��Ǵ�����ƫ��ģ��������ᵼ���㷨�ж�ʧ����Ч�����á�
 |
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
