




















���ڹؼ��ʵ��ı����ݹ����㷨���о���Ӧ�á�3��
4.2 ���ڹؼ��ʵ��ı����ݹ���ģ��
���ı����ݹ���ģ�Ͳ�������ƥ�������ģ�ͣ���������Ĺ���ģ���Դ��û���Ϊ����ģ������ȡ�������ؼ���Ϊ���룬�����ݿ��е��ı��������бȶԣ������ƶ���ij��Χ�ڵ���Ϣɸѡ������Ϊ�Ƽ�ϵͳ���������ͬʱ��Ҫ�����û��Ķ�����ƣ�ͳ̶ȣ��������ƶȴ�����Ų�Ӧ��ͬʱ�Ƽ������ߡ����磬ij������Ϊ�������ؼ���Ϊ��ʮ�Ŵ�ί����ʿ���ġ���ױƷ�����������ƶ�ɸѡ�����ı����ܴ����Ϊʮ�Ŵ���ص����������£�������������ƶȸߵ��ı��Ƽ������ߣ�����߿������Ƽ����Ϊʮ�Ŵ�������ݣ�������δ���ֳ����Ի��Ƽ�������Ч��������ϣ���Ƽ������ߵ�����Ӧ������������ˣ�����ģ���ж�ɸѡ����Ŀ�����ݽ��о��࣬ÿһ������ȡ�����û���Ϊ�������ƶ���ߵ����ݽ����Ƽ�������������ͼ4-2��ʾ��
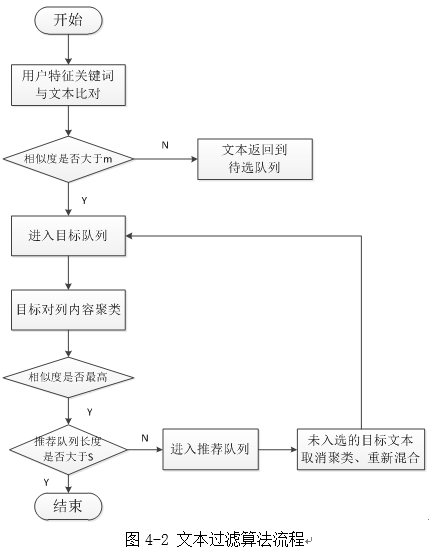
��ͼ4-2����������Ƶ��ı����ݹ���ģ����Ҫ��Ϊ�����������裺
��1�� �����ȶԣ��û������ؼ�������û�����������������ȡ�������ı���������ı����������������û����������������ı��������������ƶȣ�ѡȡ���ƶȴ���Ԥ������m���ı������Ŀ���ı����У�
��2�� ���ݾ��ࣺʹ��K-means����������Ŀ���ı����о��������������k���ؼ���ÿ���ؼ�ѡȡ�����ȶ�ʱ���ƶ���ߵ��ı����������յ��Ƽ����У�����һ�ι��˺�ɸѡ��k�����Ƽ��ı���
��3�� �ع��ˣ���Ԥ�Ƽ��ı�����s����ÿ�ι�����ɸѡ�����ı�����kʱ����Ҫ���ж�ι��ˣ�Ϊ��Сģ�͵�����ԣ����ع��˵���ʼ������Ŀ����е������ϣ�������ǰһ�λ�ǰ����δ�����Ƽ����е�Ŀ������ı���Ϊ�µ�Ŀ���ı������½��о�������ȡ�����Ƽ����е��ı������ﵽԤ������sʱ��ֹͣѭ����
4.3 �����ȶ��㷨���
���û���Ϊ����ģ���������û������ؼ�������û���������X���������ķִʻ��ƽ��������е����ŵ����͵��ı����зִʣ�ȥͣ�ôʺ���д�Ƶ���㣬ɸѡ���ı��ؼ�������ı���������Y��ʹ�����Ҿ���sim(X,Y)�����������������ƶȣ����㷽����ʽ4-1��
![]()
ʽ4-1��X?YΪ���������Ļ�����X��?��Y��Ϊ���������ij��ȳ˻������Ҿ���Խ�ӽ���1�������ı�Խ���ơ�Ϊɸѡ�����û������ؼ��������Խϸߵ��ı��������ü���������ֵ����ֵΪ0.5��1֮���һ����ֵ���������ƶȴ��ڴ���ֵ���ı�����Ŀ�����С�
4.4 Ŀ���ı����ݾ����㷨���
����ѡ��K-means������Ŀ���ı����о��������������һ���ල�Ļ���ѧϰ������������ģʽʶ�������ھ���������¶��ϵ�K-means���������٣������Ľ���ܳ�ʼ�����������ĿӰ�죬�������漰�ij�����ͨ���ؼ����������ı����ȷ��������Ŀ����˱���ѡȡK-means��Ŀ���ı��ľ��������

���ĵľ����㷨����������1��ʾ��K-means�㷨�е�kֵΪ�������дؼ��ĸ�������Ϊ�û������ؼ��ʵĸ�����ȷ���ģ����ֱ�ӽ��ؼ��ʸ�����Ϊ����ؼ��ĸ��������ѡ��k���ؼ������ģ������ģ�����ʽ4-1������ı���������X����������Y���������ƶȡ�
���Ҿ���Խ�ӽ���1���ı�������Խ���ƣ��ı����ĸ��������������ı����ڴ��������ڴؼ��С�
���㷨��Ŀ�꺯��Ϊ������Ҿ���ͣ���ʽ4-2��ʾ����Ŀ�꺯���ﵽ�������㷨ֹͣ��
![]()
����K-means�㷨�ľ�����������յó�k���ı��ؼ���ÿ���ؼ�����һ�����͵��ı�����ÿ���ؼ�ƽ��ѡ���Ƽ����û����ı�������յ��Ƽ����С�
5 �ܽ���չ��
��������Ĺ���ģ���Ǹ��Ի��Ƽ�ϵͳ�ĺ��ģ�������ѡ�õ��ı����ƶȼ���������㷨���������ԣ���˸�ģ�Ͳ�������Ӧ�����������ĸ��Ի��Ƽ�ϵͳ������Ӧ�����������ļ���ϵͳ��������Ϣ���˴�����ϵͳ����ͬ��ʹ�û������ò�ͬ�IJ�������ֵ���ܹ�ʹ��ģ�ʹﵽ�����õ�ʹ��Ч����
 |
�����ø����˿��� 
�Ƽ��Ķ�
��ý�Ƽ�
 @ý���ˣ����ű���������
@ý���ˣ����ű��������� ��վ��Ӫ�� ��Щ"����"���ܲȣ�
��վ��Ӫ�� ��Щ"����"���ܲȣ� һͼ�����й�����������ҵ
һͼ�����й�����������ҵ
�������
�����ձ���ſ� | ���������� | ������Ƹ | ��ƸӢ�� | ������ | �������� | ������� | ���ݷ��� | ��վ���� | ��վ��ʦ | ��Ϣ���� | ��ϵ����
�������䣺kf@people.cn Υ���Ͳ�����Ϣ�ٱ��绰��010-65363263 �ٱ����䣺jubao@people.cn
������������Ϣ��������֤10120170001 | ��ֵ����ҵ��Ӫ����֤B1-20060139
�㲥���ӽ�Ŀ������Ӫ����֤����ý���ֵ�172�� | ������ҩƷ��Ϣ�����ʸ�֤�飨����-�Ǿ�Ӫ��-2016-0098
��Ϣ���紫��������Ŀ����֤0104065 | �����Ļ���Ӫ����֤ ������[2020]5494-1075�� | ��������������֤��������121�� | ��ICP֤000006�� | ����������11000002000008��
�� �� �� �� Ȩ �� �� ��δ �� �� �� �� Ȩ �� ֹ ʹ ��
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
����

-
��ע
��������
 ��һʱ��Ϊ������Ȩ����Ѷ
��һʱ��Ϊ������Ȩ����Ѷ
 ����ȫ�� �����й�
����ȫ�� �����й�
 ��ע������������������
��ע������������������
